Monitoring Windows servers on pure MS SQL, and how I secretly implemented it
Once, in a galaxy far far away, there was a firm that had long grown up from a startup, but which still remained fairly compact and efficient. The company hosted (on its hardware) hundreds of Windows-servers, and it had to be monitored. Even before I came to it, the NetIQ system was chosen as the solution.
I was instructed to set up NetIQ, and the one who did it before me did not say a single word about it. Printed I soon realized why. Steve Jobs is probably spinning in his grave, looking at a similar interface:
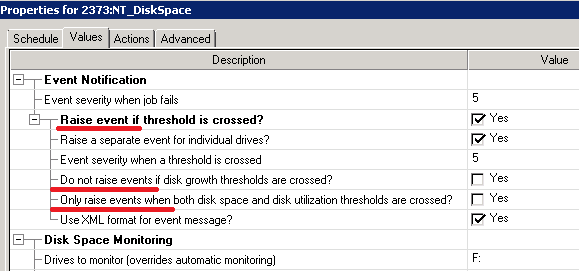
In one line, the logic of the "bird" is positive (Raise event). In another negative (Do not raise event). How I work with “Only raise events when” with a different set of checkmarks is only experimentally understood (and I have already forgotten).
However, NetIQ’s much worse feature was its fragility. Her agent, which was installed on each server, was significantly more vulnerable than Windows itself. Little memory? Agent flew out. CPU 100%? Agent not responding. There are 0 bytes left on the disk - what would you think? To send a message, the agent must first form it on disk, as a file ... Well, you understand.
Nevertheless, with this, something like living, until this company was bought by the company even more. When a monster eats up a tiny company, this company dissolves like a drop in the sea. In our case, by ourselves, by IT standards, we were only slightly smaller than those who bought us, and it was immediately obvious that the merger process would be very difficult. So complicated that for some time we were not touched at all and internally all processes remained the same. This state was similar to the moment when the One Ring fell on the lava, but had not yet begun to melt:

Meanwhile, I upgraded NetIQ from version 7 to 8 and further to 9, when our problems started. NetIQ monitored a few things: the availability of the server itself, memory, CPU, disk, and most importantly, services. If our samopisny services were in “Automatic”, then they had to work. That this should not be:

These events in most cases stopped monitoring NetIQ. After a week of experiments and a week of working with support, we found out that “this is not a bug, this is a feature” and that an alert is created only with a certain exit code. And our services sometimes fell with any codes.
It took a lot of time and it was late to roll back. As you understand, finding that our critical infrastructure is not monitored, we immediately ... uh ... did not do anything. Because by this time, the “dissolution” of our company in a large part entered the active phase, and it looked like this:
Distant rumblings of thunder, screams, and lightning flew to me, and it looked so that the fate of the world was being decided, and I climbed with some petty technical problem ... And I could not sleep, knowing that our monitoring was half blind.
Realizing that there was nowhere to wait for help, I decided to quickly write a service scanner that would bypass all the servers and send a letter, if something went wrong, as NetIQ did. You probably think I used Powershell? Not. If you have a hammer in your hands, then all around are nails, and if you are DBA and have worked with SQL from version 6.0, then ... A little excerpt from the code so that you understand what is at stake:
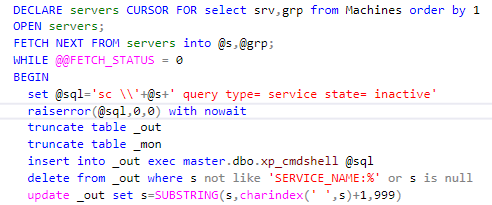
I did it in a few hours. Over the next few days, an audit of messages, parameters and other goodies appeared. After reading about the WMIC team, I could not stop. Then a couple of weeks in a daze. I woke up when everything that we used in NetIQ was rewritten and worked with a bang.
The functionality was not just copied - I realized all my fantasies, everything that I would like from such a system. LOWDISK - you also get a graph of how free disk space has behaved lately - is it normal growth or something went wrong. Little memory - that's the graph, and the list of processes and how much they occupy, and for w3wp.exe we will also finish the name of the application pool, smart reminders and much more. By the way, the system was able to independently take a list of servers from VMware. One quick glance at the subjects of the alerts in the telephone was enough to understand what was going on:

Modern programmers are so accustomed to thinking abstractly that they cannot write a monitoring system other than “we run a set of abstract monitoring scripts for the server, and we don’t care what is inside,” while monitoring each state — disk, memory, CPU, services — in its own way. are unique. Implementing this "abstract", you do the same poorly for each case, and this is what happens: (This is a screenshot from the email from SCOM. Surely done strictly according to the statement of work)

The great advantage of the new system was that it was agentless, respectively, there were no problems with the installation of the agent, its downfalls - there simply was nothing to fall. The system was simple and reliable as a hammer.
The next few months I came to work in the morning, stood in front of my brainchild, like an artist in front of a canvas and put a couple of strokes, making it even more perfect. Since I had no deadlines, technical debt was kept to a minimum. At some point, I still forced myself to stop.
NetIQ was still working, but everyone liked the new type of alerts, and gradually I transferred everyone to alerts from the new system, without turning off, however, the old one. In the meantime, the “meltdown” process has entered its final stage:

Well, the tale was supposed to end. I myself was surprised that I could have so much fun in a large bureaucratic company. After a month of preparation, I was told that after a week everything, we extinguish NetIQ, we are switching to SCOM. I turned off NetIQ (I confess, I hated him so much that I was very pleased) and waited for SCOM. But at the appointed time he was not. It was not a week later, and a month later.
SCOM appeared only after six months - someone forgot how many servers we have and how many licenses are needed for SCOM. For six months, so many systems began to depend on my system, which began to lead and inventory, metrics, and much more, that the second quietly remained unofficial. For auditors, there is SCOM, and everything that is really useful is in the second system.
Sometimes managers at different levels wondered - where did these automated emails go from? Recently, I described a story to them in detail, which I set out in this article, and they laughed merrily. Although it is still sometimes funny to me myself, as in a big bureaucratic company, one can sip many things with “sly”. And it's nice to just pee code, like in the good old days.
I was instructed to set up NetIQ, and the one who did it before me did not say a single word about it. Printed I soon realized why. Steve Jobs is probably spinning in his grave, looking at a similar interface:
In one line, the logic of the "bird" is positive (Raise event). In another negative (Do not raise event). How I work with “Only raise events when” with a different set of checkmarks is only experimentally understood (and I have already forgotten).
However, NetIQ’s much worse feature was its fragility. Her agent, which was installed on each server, was significantly more vulnerable than Windows itself. Little memory? Agent flew out. CPU 100%? Agent not responding. There are 0 bytes left on the disk - what would you think? To send a message, the agent must first form it on disk, as a file ... Well, you understand.
Nevertheless, with this, something like living, until this company was bought by the company even more. When a monster eats up a tiny company, this company dissolves like a drop in the sea. In our case, by ourselves, by IT standards, we were only slightly smaller than those who bought us, and it was immediately obvious that the merger process would be very difficult. So complicated that for some time we were not touched at all and internally all processes remained the same. This state was similar to the moment when the One Ring fell on the lava, but had not yet begun to melt:
Meanwhile, I upgraded NetIQ from version 7 to 8 and further to 9, when our problems started. NetIQ monitored a few things: the availability of the server itself, memory, CPU, disk, and most importantly, services. If our samopisny services were in “Automatic”, then they had to work. That this should not be:
These events in most cases stopped monitoring NetIQ. After a week of experiments and a week of working with support, we found out that “this is not a bug, this is a feature” and that an alert is created only with a certain exit code. And our services sometimes fell with any codes.
It took a lot of time and it was late to roll back. As you understand, finding that our critical infrastructure is not monitored, we immediately ... uh ... did not do anything. Because by this time, the “dissolution” of our company in a large part entered the active phase, and it looked like this:
Distant rumblings of thunder, screams, and lightning flew to me, and it looked so that the fate of the world was being decided, and I climbed with some petty technical problem ... And I could not sleep, knowing that our monitoring was half blind.
Realizing that there was nowhere to wait for help, I decided to quickly write a service scanner that would bypass all the servers and send a letter, if something went wrong, as NetIQ did. You probably think I used Powershell? Not. If you have a hammer in your hands, then all around are nails, and if you are DBA and have worked with SQL from version 6.0, then ... A little excerpt from the code so that you understand what is at stake:
I did it in a few hours. Over the next few days, an audit of messages, parameters and other goodies appeared. After reading about the WMIC team, I could not stop. Then a couple of weeks in a daze. I woke up when everything that we used in NetIQ was rewritten and worked with a bang.
The functionality was not just copied - I realized all my fantasies, everything that I would like from such a system. LOWDISK - you also get a graph of how free disk space has behaved lately - is it normal growth or something went wrong. Little memory - that's the graph, and the list of processes and how much they occupy, and for w3wp.exe we will also finish the name of the application pool, smart reminders and much more. By the way, the system was able to independently take a list of servers from VMware. One quick glance at the subjects of the alerts in the telephone was enough to understand what was going on:
Modern programmers are so accustomed to thinking abstractly that they cannot write a monitoring system other than “we run a set of abstract monitoring scripts for the server, and we don’t care what is inside,” while monitoring each state — disk, memory, CPU, services — in its own way. are unique. Implementing this "abstract", you do the same poorly for each case, and this is what happens: (This is a screenshot from the email from SCOM. Surely done strictly according to the statement of work)
The great advantage of the new system was that it was agentless, respectively, there were no problems with the installation of the agent, its downfalls - there simply was nothing to fall. The system was simple and reliable as a hammer.
The next few months I came to work in the morning, stood in front of my brainchild, like an artist in front of a canvas and put a couple of strokes, making it even more perfect. Since I had no deadlines, technical debt was kept to a minimum. At some point, I still forced myself to stop.
NetIQ was still working, but everyone liked the new type of alerts, and gradually I transferred everyone to alerts from the new system, without turning off, however, the old one. In the meantime, the “meltdown” process has entered its final stage:
Well, the tale was supposed to end. I myself was surprised that I could have so much fun in a large bureaucratic company. After a month of preparation, I was told that after a week everything, we extinguish NetIQ, we are switching to SCOM. I turned off NetIQ (I confess, I hated him so much that I was very pleased) and waited for SCOM. But at the appointed time he was not. It was not a week later, and a month later.
SCOM appeared only after six months - someone forgot how many servers we have and how many licenses are needed for SCOM. For six months, so many systems began to depend on my system, which began to lead and inventory, metrics, and much more, that the second quietly remained unofficial. For auditors, there is SCOM, and everything that is really useful is in the second system.
Sometimes managers at different levels wondered - where did these automated emails go from? Recently, I described a story to them in detail, which I set out in this article, and they laughed merrily. Although it is still sometimes funny to me myself, as in a big bureaucratic company, one can sip many things with “sly”. And it's nice to just pee code, like in the good old days.