CephFS vs GlusterFS
Being an infrastructure engineer in the cloud platform development team , I had the opportunity to work with many distributed storage systems, including those listed in the header. It seems that there is an understanding of their strengths and weaknesses, and I will try to share with you my thoughts on this matter. So to say, let's see who hash is longer.

Disclaimer: Earlier in this blog you could see articles about GlusterFS. I have nothing to do with these articles. This is the author's blog of our cloud project team and each of its members can tell their own story. The author of those articles is the engineer of our exploitation group and he has his own tasks and his own experience, which he shared. Please take this into account if you suddenly see a difference of opinion. I take this opportunity to convey the best regards to the author of those articles!
What will be discussed
Let's talk about file systems that can be built on the basis of GlusterFS and CephFS. We will discuss the architecture of these two systems, we will look at them from different angles, and in the end I even dare to draw any conclusions. Other Ceph features, such as RBD and RGW, will not be affected.
Terminology
To make the article complete and understandable to everyone, let's look at the basic terminology of both systems:
Terminology Ceph:
RADOS (Reliable Autonomic Distributed Object Store) is a self-contained object storage that is the basis of the Ceph project.
CephFS , RBD (RADOS Block Device), RGW (RADOS Gateway) are high-level Gadgets to RADOS, which provide end users with various interfaces to RADOS.
Specifically, CephFS provides a POSIX-compatible file system interface. In fact, CephFS data is stored in RADOS.
OSD (Object Storage Daemon) is a process serving a separate disk / object storage in a RADOS cluster.
RADOS Pool(pool) - several OSD, united by a common set of rules, such as, for example, replication policy. From the point of view of data hierarchy, a pool is a directory or a separate (flat, no subdirectories) namespace for objects.
PG (Placement Group) - I will introduce the concept of PG later, in context, for a better understanding.
Since RADOS is the foundation on which CephFS is built, I will often speak about it and this will automatically apply to CephFS.
GlusterFS terminology (hereinafter gl):
Brick is a process serving a separate disk, analogous to OSD in RADOS terminology.
Volume - the volume in which bricks are combined. The volume is an analogue of the pool in RADOS, it also has a certain replication topology between bricks.
Data distribution
To make it clearer, consider a simple example that can be implemented by both systems.
The setup that will be used as an example:
- 2 servers (S1, S2) with 3 disks of equal volume (sda, sdb, sdc) in each;
- volume / pool with replication 2.
Both systems need at least 3 servers for normal operation. But we close our eyes to this, as this is just an example for an article.
In the case of gl, this will be a Distributed-Replicated volume consisting of 3 replication groups:

Each replication group is two bricks on different servers.
In fact, it turns out a volume that combines three RAID-1.
When you mount it, get the desired file system and start writing files to it, you will find that each file you write falls into one of these replication groups entirely. DHT (Distributed Hash Tables)
deals with the distribution of files among these Distributed Groups , which is essentially a hash function (we will return to it later).
On the "scheme" it will look like this:
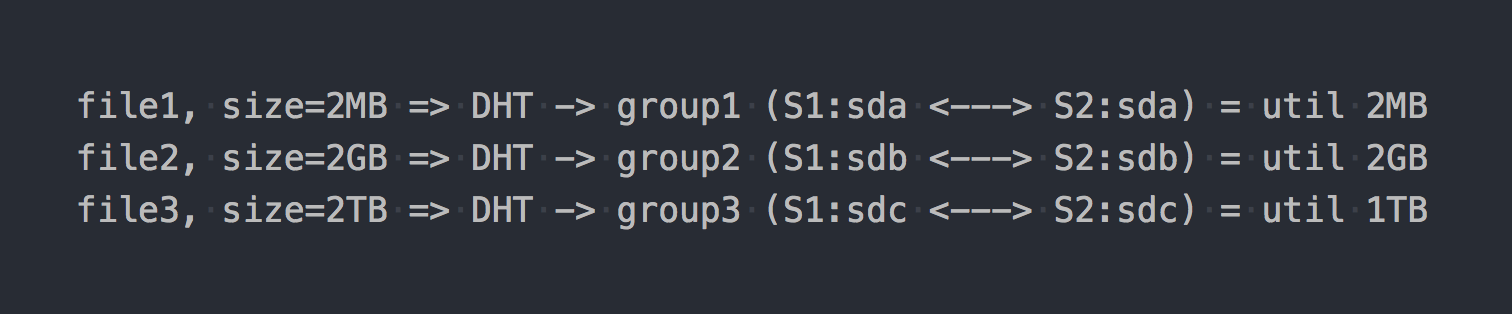
As if the first architectural features already appear:
- space in groups is unevenly utilized, it depends on file sizes;
- when writing one IO file goes only to one group, the rest are idle;
- you cannot get the IO of the entire volume when writing a single file;
- if there is not enough space in the group to write the file, you will get an error, the file will not be recorded and will not be redistributed to another group.
If you use other types of volumes, for example, Distributed-Striped-Replicated or even Dispersed (Erasure Coding), only the mechanics of data distribution within one group will change fundamentally. DHT will also lay out the files entirely in these groups, and in the end we will get all the same problems. Yes, if the volume will consist of only one group, or if you have all the files of approximately the same size, then there will be no problem. But we are talking about normal systems, for hundreds of terabytes of data, including files of different sizes, so we believe that there is a problem.
Now let's take a look at CephFS. RADOS, mentioned above, enters the scene. In RADOS, each disk is serviced by a separate process - OSD. Based on our setup, we only get 6 of these, 3 on each server. Next, we need to create a pool for the data and set the number of PG and the factor of data replication in this pool - in our case 2.
Suppose we created a pool with 8 PG. These PGs will be roughly evenly distributed across the OSD:
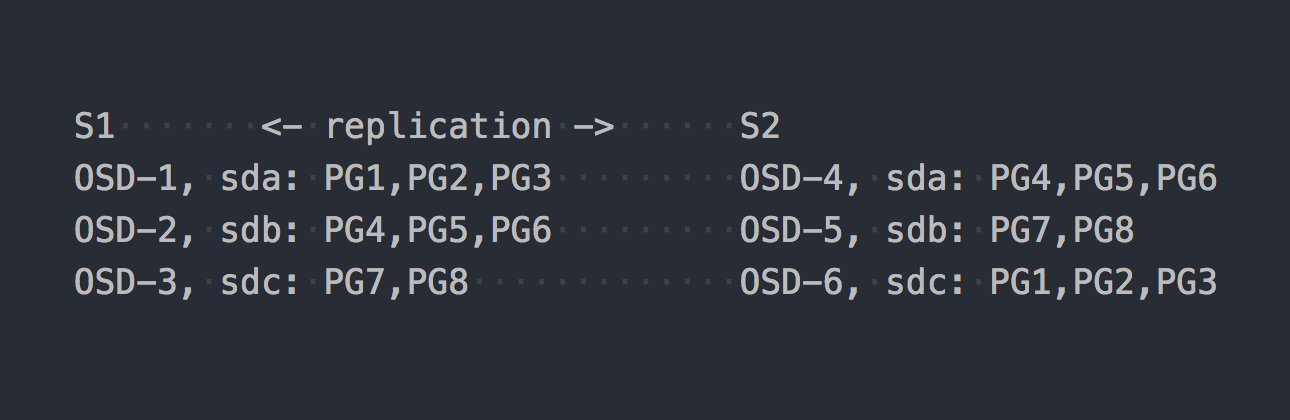
It's time to clarify that PG is a logical group that combines a certain number of objects. Since we specified the fact of replication 2, each PG has a replica on some other OSD on a different server (by default). For example, PG1, which is on OSD-1 on server S1, has a twin on S2 on OSD-6. In each pair of PG (or three, if replication 3) there is a PRIMARY PG, which is recorded. For example, PRIMARY for PG4 is on S1, but PRIMARY for PG3 is on S2.
Now that you know how RADOS works, we can go on to write files to our new pool. Although RADOS is a full-fledged storage, it is not possible to mount it as a file system or use it as a block device. To write data directly to it, you need to use a special utility or library.
We will write the same three files as in the example above:
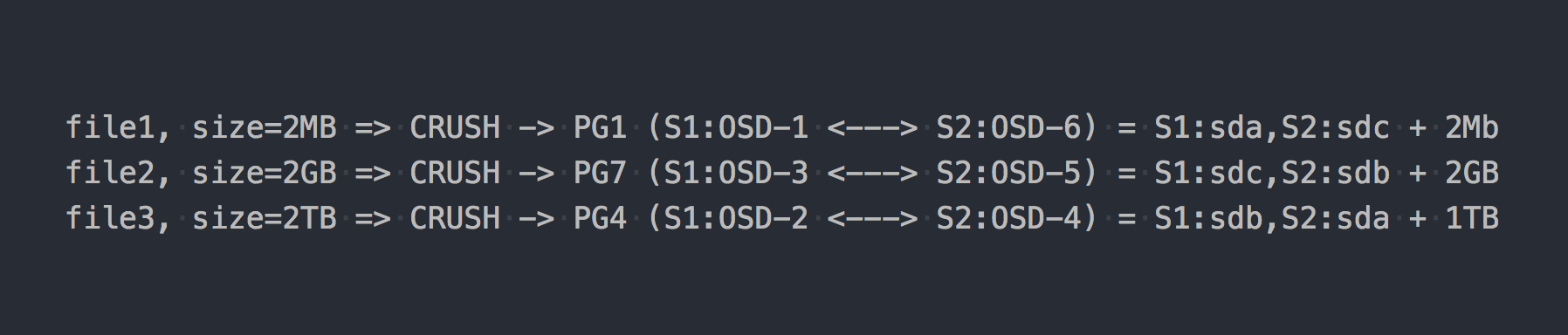
In the case of RADOS, everything became somehow more complicated, agree.
Here in the chain appeared CRUSH (Controlled Replication Under Scalable Hashing). CRUSH is an algorithm that keeps RADOS (we will return to it later). In this particular case, with the help of this algorithm, it is determined where the file should be written to which PG. Here CRUSH performs the same function as DHT in gl. As a result of this pseudo-random distribution of files on PG, we got all the same problems as gl, only on a more complex scheme.
But I deliberately kept silent about one important point. Almost no one uses RADOS in its pure form. For convenient work with RADOS, the following layers were developed: RBD, CephFS, RGW, which I have already mentioned.
All these translators (RADOS-clients) provide a different client interface, but they are similar in their work with RADOS. The most important similarity is that all data passing through them is cut into pieces and put into RADOS as separate RADOS objects. By default, official clients cut the input stream into 4MB chunks. For RBD, the stripe size can be set when creating the volume. In the case of CephFS, this is an attribute (xattr) of a file and can be managed at the level of individual files or as a whole for all files in a directory. Well, the RGW also has a corresponding parameter.
Now suppose that we have hoisted the CephFS over the RADOS pool, which figured in the last example. Currently considered systems are completely equal and provide an identical file access interface.
If we again write our test files to the new CephFS, we find a completely different, almost even distribution of data on the OSD. For example, file2 of 2GB size will be divided into 512 pieces, which will be distributed over different PGs and, as a result, across different OSDs almost evenly, and this practically solves the problems described above with data distribution.
In our example, only 8 PG are used, although it is recommended to have ~ 100 PG on one OSD. And the pools for CephFS need 2. You also need a few service daemons for the work of RADOS in principle. Do not think that everything is so simple, I omit a lot of things on purpose, so as not to depart from the essence.
So now CephFS seems more interesting, right? But I kept silent about another important point, this time about gl. Gl also has a mechanism for cutting files into pieces and running these pieces through DHT. The so-called sharding ( Sharding ).
Five minutes of history
On April 21, 2016, the CephFS team is considered stable.
It is now all left and right screaming about CephFS! And 3-4 years ago, using it would be at least a dubious decision. We were looking for other solutions, and gl with the architecture described above was no good. But we believed in him more than in CephFS, and waited for sharding, which was prepared for the exit.
And here he is day X:
June 4, 2015 - GlusterFS 3.7 open software-defined storage software has been announced today.
3.7 - the first version of gl, which announced shardirng as an experimental feature. They had almost a year before the stable release of CephFS, to gain a foothold on the pedestal ...
So, sharding means. Like everything in gl, this is implemented in a separate translator (translator), which stood above the DHT (also translator) on the stack. Since it is higher than DHT, at the entrance DHT receives ready-made shards and distributes them into replication groups as regular files. Sharding is enabled at the level of a separate volume. The shard's size can be set, by default - 4MB, as with Ceph gadgets.
When I conducted the first tests I was delighted! I told everyone that gl is now a top thing and now we'll live! With sharding turned on, the recording of one file goes in parallel to different replication groups. The decompression that follows the "On-Write" compression can be incremental to shard level. In the presence of a cache-media, here too, everything becomes good and individual shards are moved to the cache, and not the entire files. In general, I was elated, because it seemed that he got his hands on a very cool tool.
It remained to wait for the first bugfixes and the status of "ready for production". But everything turned out to be not so rosy ... In order not to stretch the article with a list of critical bugs related to sharding, which occasionally arose in the following versions, I can only say that the latest "major issue" with the following description:
Expanding a gluster volume that is sharpened may cause file corruption. If you are using bold and rebalance, then you’re getting access to your images.
was closed in release 3.13.2, January 20, 2018 ... or maybe this is not the last one?
Comments to one of our articles about this, so to speak, firsthand.
RedHat in its documentation for the current RedHat Gluster Storage 3.4 notes that the only sharding case they support is storage for VM disks.
There is no need for any further information on how to use your storage device. This is a case in which it provides significant performance improvements over the previous implementations.
I do not know why such a restriction, but you see, it is alarming.
Now I'm gonna get you here
Both systems use a hash function to pseudo-randomly distribute data across disks.
With RADOS, it looks like this:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun
# e.g. pool id=5 => pg = 5.1f
OSD = crush_hash_based_on_jenkins(PG)
# e.g. pg=5.1f => OSD = 12 Gl uses the so-called consistent hashing . Each brick gets a "range within a 32-bit hash space". That is, all bricks share the entire linear address hash space among themselves without intersecting ranges or holes. The client runs the file name through the hash function, and then determines which hash range the received hash falls into. This selects a brick. If there are several bricks in the replication group, they all have the same hash range. Like that:
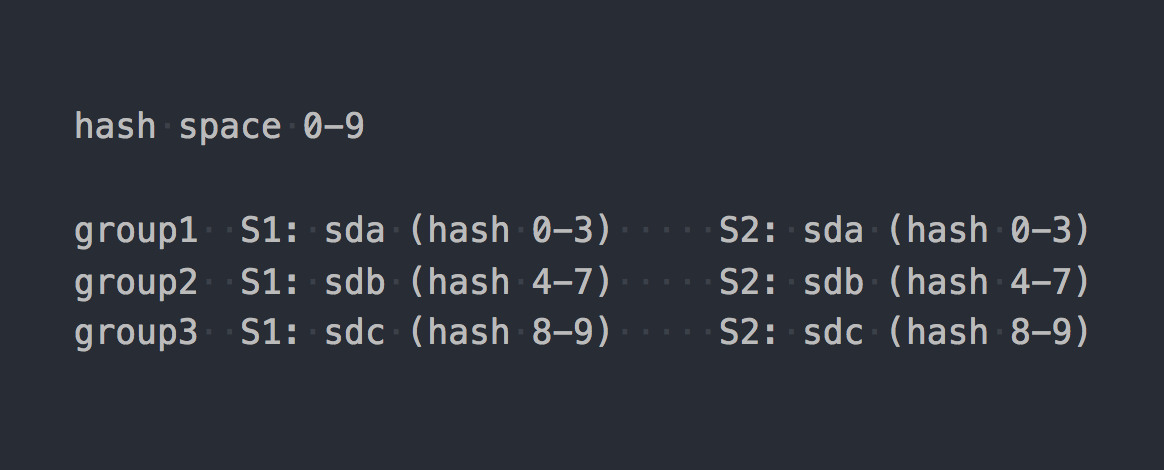
If we bring to a certain logical form the work of the two systems, then we’ll get something like this:
file -> HASH -> placement_unitwhere placement_unit in the case of RADOS is a PG, and in the case of gl it is a group of replications from several brick'ov.
So, the hash function means that it distributes, distributes files and suddenly it turns out that one placement_unit is utilized more than another. Such is the fundamental feature of systems with hash distribution. And we are faced with a quite ordinary task - to unbalance the data.
Gl is able to rebelance, but because of the above described architecture with hash ranges, you can run rebelance as many times as you like, but no hash range (and, as a result, data) will move from place. The only criterion for redistributing hash ranges is a change in the capacity of the volume. And you have one option left - add bricks. And if we are talking about a replication volume, then we have to add a whole replication group, that is, two new bricks in our setup. After expanding the volume, you can run rebelance - the hash ranges will be redistributed taking into account the new group and the data will be distributed. When a replication group is deleted, hash ranges are automatically distributed.
RADOS has a car of possibilities here. In an article on Ceph, I complained a lot about the concept of PG, but here, comparing with gl, of course, RADOS on horseback. Each OSD has its own weight, usually it is based on the size of the disk. In turn, PGs are distributed by OSD depending on the weight of the latter. Everything, then we simply change the weight of the OSD up or down and the PG (along with the data) starts to move to other OSDs. Also, each OSD has an additional adjustment weight, which allows balancing data between the disks of one server. All this is laid in CRUSH. The main profit is that it is not necessary to expand the capacity of the pool in order to unbalance better data. And it is not necessary to add disks in groups, you can add only one OSD and a part of PG will be transferred to it.
Yes, it is possible that when creating a pool, you did not create enough PGs and it turned out that each of the PGs is quite large in volume, and wherever they move, the imbalance will persist. In this case, you can increase the number of PG, and they are split into smaller ones. Yes, if the cluster is crammed with data, then it hurts, but the main thing in our comparison is that there is such a possibility. Now only an increase in the number of PGs is allowed and with this you need to be careful, but in the next version of Ceph - Nautilus there will be support for reducing the number of PGs (pg merging).
Data replication
Our test pool and volume have a replication factor of 2. It is interesting that the systems under consideration use different approaches to achieve this number of replicas.
In the case of RADOS, the write scheme looks like this:
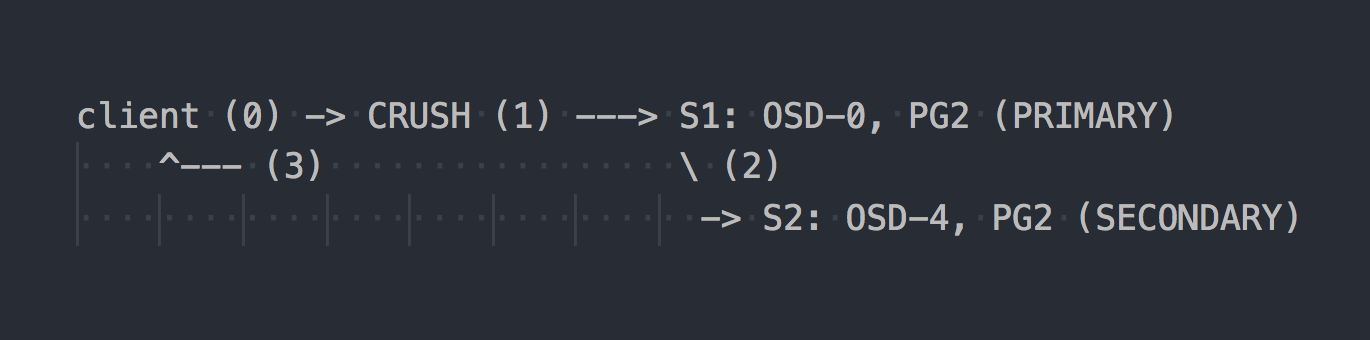
The client knows the topology of the entire cluster, uses CRUSH (step 0) to select a specific PG for writing, writes to PRIMARY PG on OSD-0 (step 1), then OSD-0 synchronously replicates data to SECONDARY PG (step 2), and only after successful / unsuccessful step 2, OSD confirms / does not confirm the operation to the client (step 3). Data replication between two OSDs is transparent to the client. OSD in general can use a separate “cluster”, faster network for data replication.
If triple replication is configured, it is also performed synchronously with PRIMARY OSD into two SECONDARY, transparent to the client ... well, just that the letensee is higher.
Gl works differently:
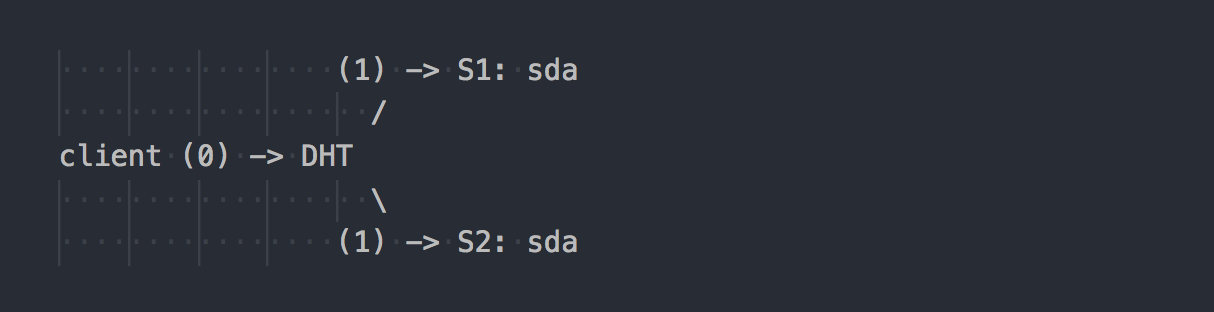
The client knows the volume topology, uses DHT (step 0) to determine the desired brick, then writes to it (step 1). Everything is simple and clear. But here we remember that all bricks in the replication group have the same hash range. And this insignificant feature makes the whole holiday. The client writes in parallel to all the bricks that have a suitable hash range.
In our case, with double replication, the client performs parallel double-entry on two different bricks. With triple replication, triple recording will be performed, respectively, and 1MB of data will turn roughly into 3MB of network traffic from the client towards the gl servers. Agree, the concepts of the systems are perpendicular.
In such a scheme, more work is entrusted to the gl client, and, as a result, he needs more CPU, and I already said about the network.
AFP translator (Automatic File Replication) - A client-side xlator that performs synchronous replication. Replicates writes to all bricks of the replica → Uses a transaction model.
If it is necessary to synchronize the replicas in the group (healing), for example, after the temporary unavailability of one brick, the gl demons do it themselves using the AFP built into them, transparently to clients and without their participation.
It is interesting that if you work not through the native gl client, but write via the built-in NFS server in gl, you will get the same behavior as RADOS. In this case, AFP will be used in gl demons to replicate data without client participation. But the built-in NFS is zadricable in gl v4 and, if you want this behavior, it is recommended to use NFS-Ganesha.
By the way, because of so different behavior when using NFS and the native client, you can see completely different performance indicators.
Do you have the same cluster, only "on the knee"?
I often see on the Internet discussions of any knee-up setups, where a cluster for data is built from what is at hand. In this case, a solution based on RADOS can give you more freedom when choosing disks. In RADOS, you can add disks of almost any size. Each disk will have a weight corresponding to its size (usually), and the data will be distributed over the disks almost in proportion to their weight. In the case of gl, in the volumes with replication there is no concept of "separate disks". Disks are added in pairs with double replication or triples with triple. If in the same replication group there will be disks of different sizes, then you will fall into place on the smallest disk in the group and you will not utilize the capacity of large disks. In such a scheme, gl will assume that the capacity of one replication group is equal to the capacity of the smallest disk in the group, which is logical. In this case, it is allowed to have replication groups consisting of disks of different sizes — groups of different sizes. Larger groups can receive a larger hash range relative to other groups and, as a result, take more data.
We live with Ceph for the fifth year. We started with disks of the same size, now we introduce more capacious ones. With Ceph, you can remove the disk and put in its place another larger or slightly smaller one without any architectural difficulties. With gl, everything is more complicated - I took out a 2 TB disk - put the same one, be kind. Well, or withdraw the entire group as a whole, which is not very good, agree.
Failure handling
We have already got acquainted a little with the architecture of the two solutions and now we can talk about how to live with it and what features there are at maintenance.
Suppose we have refused sda on S1 - a common thing.
In the case of gl:
- a copy of the data on the remaining live disk in the group is not automatically redistributed to other groups;
- until the disk is replaced, only one copy of the data will remain;
- when replacing a failed disk with a new one, replication is performed from a healthy disk to a new one (1 on 1).
This is similar to multi-RAID-1 shelf maintenance. Yes, with triple replication, if one disk fails, not one copy will remain, but two, but still this approach has serious drawbacks, and I will show them with a good example with RADOS.
Suppose we have failed sda on S1 (OSD-0) - the usual thing:
- PGs that were on OSD-0 will be automatically remapped to other OSDs after 10 minutes (by default). In our example on OSD 1 and 2. If there were more servers, then a greater number of OSDs.
- PGs that store the second, surviving copy of the data will automatically replicate them to those OSDs to which the recovered PGs are transferred. It turns out many-to-many replication, not one-to-one replication like gl.
- With the introduction of a new disk instead of a broken one on a new OSD, some PGs will be mapped in accordance with its weight and data from other OSDs will be gradually redistributed.
I think the architectural advantages of RADOS to explain it makes no sense. You can not jerk when you receive a letter that the disc failed. And when you come to work in the morning, you will find that all the missing copies have already been restored on dozens of other OSDs or in the process. On large clusters, where hundreds of PGs are spread over a heap of disks, data recovery of one OSD can take place at speeds that are much greater than the speed of one disk due to the fact that dozens of OSD are involved (read and write). Well, about the load distribution, too, do not forget.
Scaling
In this context, I, perhaps, will give a pedestal gl. In an article on Ceph, I already wrote about some of the challenges of scaling RADOS related to the concept of PG. If the increase in PG as the cluster grows can still be experienced, then how to deal with Ceph MDS is not clear. CephFS runs on top of RADOS and uses a separate pool for metadata and a special process, the ceph metadata server (MDS), to maintain the file system metadata and coordinate all operations with the file system. I'm not saying that the presence of MDS puts an end to the scalability of CephFS, no, especially since it is allowed to run several MDS in active-active mode. I just want to point out that gl is architecturally devoid of all this. It has no PG counterpart, nothing like MDS. Gl really scales well by simply adding replication groups, almost linearly.
Back in the pre-CephFS times, we designed a solution for petabytes of data and looked at gl. Then we had doubts about the gl scalability and we figured it out through the mailing list. Here is one of the answers (Q: my question):
I am using 60 servers each has 26x8TB disks total 1560 disk 16 + 4 EC volume with 9PB of usable space.
Q: Do you use libgfapi or FUSE or NFS on the client side?
I use FUSE and I have nearly 1000 clients.
Q: How many files do you have in your volume?
Q: Files are more big or small?
I have over 1M files and% 13 of which is used which makes average file size 1GB.
Minimum / Maximum file size is 100MB / 2GB. Every day 10-20TB.
Q: How fast does "ls" work)?
Metadata operations are slow as you expect. I try not to put more than 2-3K files in a directory. I rarely do metadata operations.
Rename files
Back to the hash functions. We figured out how specific files are routed to specific disks, and now the question becomes relevant, and what will happen when renaming files?
After all, if we change the file name, then the hash from its name will also change, and therefore the place of this file on another disk (in a different hash range) or on another PG / OSD in the case of RADOS. Yes, we think correctly, and here the two systems are all perpendicular again.
In the case of gl, when a file is renamed, the new name is passed through the hash function, a new brick is defined and a special link to the old brick is created on it, where the file remains to lie. Topchik, right? In order for the data to actually move to a new location, and the client does not make an extra click on the link, you need to do a rebelance.
But RADOS does not have a method for renaming objects because of the need for their subsequent movement. For renaming, it is proposed to use honest copying, which leads to the simultaneous movement of an object. And CephFS, which runs on top of RADOS, has a trump card in the sleeve in the form of a pool with metadata and MDS. Changing the file name does not affect the contents of the file in the data pool.
Replication 2.5
Gl has one very cool opportunity that I would like to mention separately. Everyone understands that replication 2 is not a reliable configuration, but nevertheless it periodically takes place and is quite reasonable. To protect against split-brain in such schemes and to ensure consistency of the data, gl allows you to build volumes with a replica 2 and an additional arbiter. The arbiter is applicable when replicating 3 or more. This is the same brick in the group as the other two, only it actually creates only a file structure from files and directories. Files on such a brick have zero size, but their extended file system attributes (extended attributes) are maintained in a synchronized state with full-size files in the same replica. I think the idea is clear. I think this is a cool opportunity.
The only point ... the size of the place in the replication group is determined by the size of the smallest brick, and this means that the arbiter needs to slip the disk at least the same size as the rest in the group. To do this, it is recommended to create thin (thin) LV dummy, large size, so as not to use a real disk.
And what about clients?
The native API of the two systems is implemented as libgfapi (gl) and libcephfs (CephFS) libraries. Binding for popular languages too. In general, with libraries, everything is about equally good. The ubiquitous NFS-Ganesha supports both libraries as FSAL, which is also the norm. Qemu also supports the native gl API via libgfapi.
But fio (Flexible I / O Tester) has long and successfully supported libgfapi, but libcephfs does not support it. This is plus gl, because using fio is very nice to test gl "directly". Only by working from userspace via libgfapi will you get all that gl from gl.
But if we are talking about the POSIX file system and how to mount it, then gl can only be offered by the FUSE client, and the CephFS implementation in the upstream kernel. It is clear that in the kernel module it is possible to fancy such that FUSE will show the best performance. But in practice, FUSE is always an overhead on context switches. I personally have often seen FUSE bend over a two-socket server with CS alone.
Linus once said:
Userspace filesystem? The problem is right there. Always has been. But who are just misguided.
The developers of gl on the contrary believe that FUSE is cool. They say that it gives more flexibility and unties from versions of the kernel. As for me, they use FUSE, because gl is not about speed. Somehow it is written - well, it is normal, and it’s really strange to bother with the implementation in the kernel.
Performance
There will be no comparisons).
It is too complicated. Even on an identical setup too difficult to conduct an objective test. In any case, there is someone in the comments, who will give 100,500 parameters that "speed up" one of the systems and say that the tests are bullshit. Therefore, if interested, test it yourself, please.
Conclusion
RADOS and CephFS, in particular, is a more complex solution both in understanding, in tuning, and in accompanying.
But personally, I like the architecture of RADOS and CephFS working on top like more than GlusterFS. More pens (PG, OSD weight, CRUSH hierarchy, etc.), CephFS metadata increases the complexity, but gives more flexibility and makes this solution more efficient, in my opinion.
Ceph is much better suited for modern SDS criteria and seems to me more promising. But this is my opinion, what do you think?