MIT course "Computer Systems Security". Lecture 18: "Private Internet Browsing", part 1
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Controlling hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 Part 2/ Part 3
Lecture 4: "Privilege Separation" Part 1 / Part 2 / Part 3
Lecture 5: "Where Security System Errors Come From" Part 1 / Part 2
Lecture 6: "Capabilities" Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
Lecture 8: “Network Security Model” Part 1 / Part 2 / Part 3
Lecture 9: “Web Application Security” Part 1 // Part 3
Lecture 10: “Symbolic execution” Part 1 / Part 2 / Part 3
Lecture 11: “Ur / Web programming language” Part 1 / Part 2 / Part 3
Lecture 12: “Network security” Part 1 / Part 2 / Part 3
Lecture 13: “Network Protocols” Part 1 / Part 2 / Part 3
Lecture 14: “SSL and HTTPS” Part 1 / Part 2 / Part 3
Lecture 15: “Medical Software” Part 1 / Part 2/ Part 3
Lecture 16: "Attacks through the side channel" Part 1 / Part 2 / Part 3
Lecture 17: "User Authentication" Part 1 / Part 2 / Part 3
Lecture 18: "Private Internet Browsing" Part 1 / Part 2 / Part 3
So let's get started. Welcome to another fascinating lecture on security and why the world is so terrible. So, today we will talk about private browsing modes, about how many of you probably have a lot of personal experience. What is the purpose of private viewing? What do security researchers say about privacy?
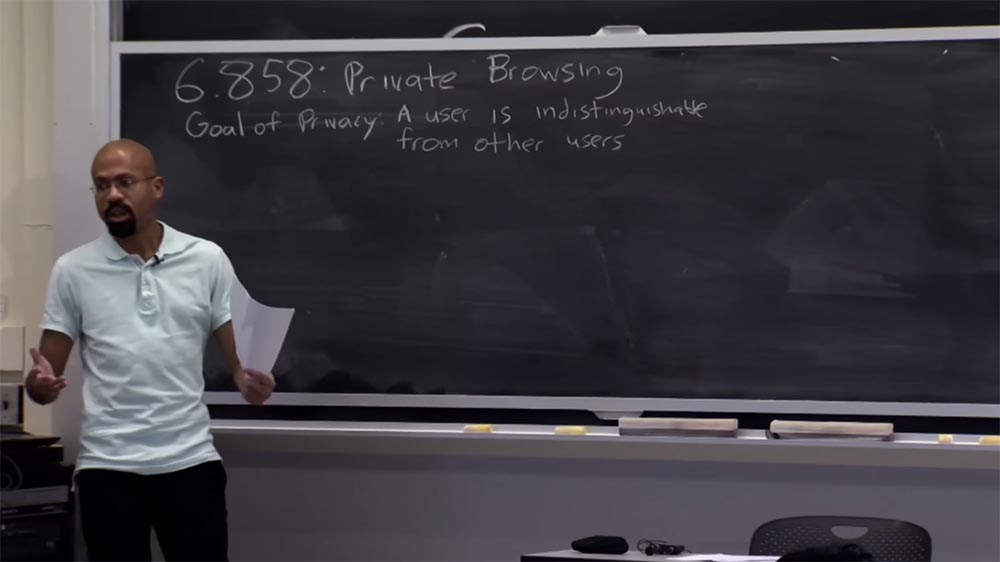
In a general sense, they talk about the following goal: any particular user should be no different from a heap of other users. In particular, the activity of this user when browsing the Internet should not look compromising in terms of the activity of other users. So, as I mentioned, today we’ll talk about privacy in the particular context of private Internet browsing.
In fact, there is no formal definition of what private browsing means. There are several reasons for this. One of them is that web applications are very, very complex things. They are constantly added new features, such as audio, video content and other such things. As a result, what browsers should be is a “moving target.” Therefore, the concept of what browsers can do is rather vague, as a result of which it is not always clear exactly what information about a particular user can leak into open access.
In the end, what happens in practice, as in many other things, the very existence and tasks of browsers are determined by the standards of life. Thus, various browser manufacturers will implement various functions, especially with regard to private browsing. Other developers see the results of competitors and update their own browser, so that the goals and objectives of the browser are constantly changing.

As users rely more and more on private browsing, they end up finding a lot of confidentiality errors, which I will cover in a minute. In a global sense, private viewing can be seen as an ambitious goal. But as society improves, some aspects of private viewing become better and some aspects get worse.
So what do we mean by private browsing the Internet? It is rather difficult to determine, but the lecture article tries to formalize this question in two specific ways. First of all, it tells about a local hacker in a private network - a person who will take possession of your computer after you finish a private browsing. And this person wants to find out which sites you visited in the mode of private viewing.
The article also talks about Internet intruders who control the sites you visit. This attacker may try to find out that you are a particular person, John or Jane, and not some impersonal user about whom the website cannot provide any information. Therefore, we will examine in detail each of these attacks. Suffice it to say that if an attacker can simultaneously organize both of these attacks, both local and Internet attacks, this will greatly enhance his ability to reveal your identity.
For example, a local attacker who may know your IP address is able to find out if this particular IP address is in the site logs. So from a security point of view, it is very useful to consider these local and web attacks, first individually and then in a combined form.
Let's consider the first type of attacker - a local attacker. Suppose that this hacker will control the user's computer after the completion of a network communication session. I mean that the private browsing is complete, the user has stopped using the browser and is not at the computer. After that, the hacker takes the computer under control and tries to find out what happened before that. Therefore, the goal of security is to prevent the attacker from understanding which websites the user has visited during a private browsing.
An important reason why we consider an attack after the completion of an Internet activity session is as follows. If we assume that an attacker can control the computer before private viewing, then the game is over, because in this case the hacker can install a keyboard interceptor, violate the integrity of the browser or the operating system itself. So we will not pay attention to such an attacker. Please note that for the same reason we are not trying to ensure user privacy after the attacker controlled his computer, because by taking control of the computer, the hacker will be able to do with it what he wants, at least to install the same keyboard interceptor. So in principle, as soon as the user leaves the computer,
Here you can imagine another goal that you want to achieve - to try to hide from the attacker that the user generally uses the private viewing mode.

The lecture article says that it is very difficult. This property is often referred to as “plausible negation.” For example, your boss comes to you after a private viewing session and says: “Have you looked at the site mylittlepony.com?”, And you answer, no, that you, I definitely did not go there! And I, of course, did not use the private browsing mode to hide the fact that I was browsing mylittlepony.com. So, as I have already said, it is difficult to ensure a property of plausible denial, later I will give specific reasons. So we will mainly consider only a local attacker.
We could think about the question of how the constant state of the client side contributes to leaks during a private viewing session? By constancy, I mean that some data will be stored on a local hard drive, local SSD or something similar.

So, what operating conditions of the system are fraught with data leaks, if we were not careful enough in private viewing? First of all, this is the accessibility state of such components of JavaScript as cookies and DOM storage. Another thing that people worry about when browsing privately is browser cache. After all, you do not want anyone to find in the internal cache some images or HTML files from websites that you want to hide from other people.
Another important thing is the history of the sites you have visited. You can spoil the relationship with another person when he enters the browser, starts typing something in the address bar and embarrassedly interrupts what has been started, since the history of your views automatically tells him something extremely indecent. This is one of the reasons why you don’t want this information to be leaked outside of your private browsing session.
You can also think about view configuration states and things like client certificates and bookmarking pages. You may have visited a certain site, and the browser suggests that you save your passwords in the configuration file for viewing this site, and you do not want them to be leaked.
The fifth is the uploaded files. This is interesting because an explicit user action is required to download the file. You may use the downloaded file during private browsing when opening the browser, but it is also possible that you use the downloaded file after you finish working with the browser outside the private browsing mode. We will talk about this a little later.
And finally, in the private browsing mode, you can install new plug-ins or browser extensions. This is another type of condition, the leakage of which is beyond the limits of private viewing is undesirable.

Thus, current view modes typically attempt to prevent data leakage during the first, second, and third private browsing session state. That is, there should be no possibility of cookies being leaked or DOM data. Anything you put into the cache during a private browsing session should be removed. You should not keep a history of visited URLs.
As a rule, the data of the fourth, fifth and sixth state of the private viewing mode can leak out of the session. There are beneficial and harmful reasons why this may be the case. We will see later that if we allow leakage of one thing, it will radically increase the surface of the threat of leakage of all private information. Therefore, it is quite difficult to argue about exactly which security properties are intended for a private viewing mode.
The next thing we’ll talk about very briefly is network activity during private browsing. The interesting thing about this is that even if we envisage the protection of all these 6 states, not allowing information leaks to occur, the very fact that you issue network packets upon connection is proof of what you have done. Imagine that when you want to go to foo.com, your computer should issue a DNS request for foo.com. So even if you do not leave any traces of activity of the six above-mentioned states, there will still be records in the local DNS cache that you tried to contact the host foo.com. It is very interesting. You might think that browsers might somehow try to clear the DNS cache after completing a private browsing session, but in practice it’s hard to do, because many systems require administrative rights for this. There is a contradiction here, because, most likely, you do not want the browser to have root rights, as we have seen that browsers are not unreliable enough. In addition, the DNS cache clear commands are designed for the activity of a specific user; they do not clear the entire cache, what would you like for a private browsing mode. You will need “surgical” accuracy to get rid of just mentioning visiting foo.com and other sites in private browsing mode, without affecting other things. In practice, dealing with this is quite difficult. In addition, the DNS cache clear commands are designed for the activity of a specific user; they do not clear the entire cache, what would you like for a private browsing mode. You will need “surgical” accuracy to get rid of just mentioning visiting foo.com and other sites in private browsing mode, without affecting other things. In practice, dealing with this is quite difficult. In addition, the DNS cache clear commands are designed for the activity of a specific user; they do not clear the entire cache, what would you like for a private browsing mode. You will need “surgical” accuracy to get rid of just mentioning visiting foo.com and other sites in private browsing mode, without affecting other things. In practice, dealing with this is quite difficult.
And one more tricky thing that the article mentions is the artifacts of RAM, or RAM. Here the basic idea is that in the private browsing mode, a private browser should store something in memory. Even if the private viewing mode does not require direct writing data to a disk or reading data from a disk, the browser provides the RAM. For example, the tab you are viewing may remain in the paging file, and this information may be reflected in the laptop's hibernation file. Thus, if this state is reflected in the persistent storage, then after the private browsing session is over, the attacker can find in the paging file JavaScrip or HTML code that is reflected on the disk.
We will have a small demonstration of how this can work. On the screen you see the private browsing tab, from which I am going to visit the site of the PDOS programming group of the computer science laboratory of our institute CSAIL.
 \
\ Next, I'm going to use this fun team called gcore, to store the picture of this open PDOS page.
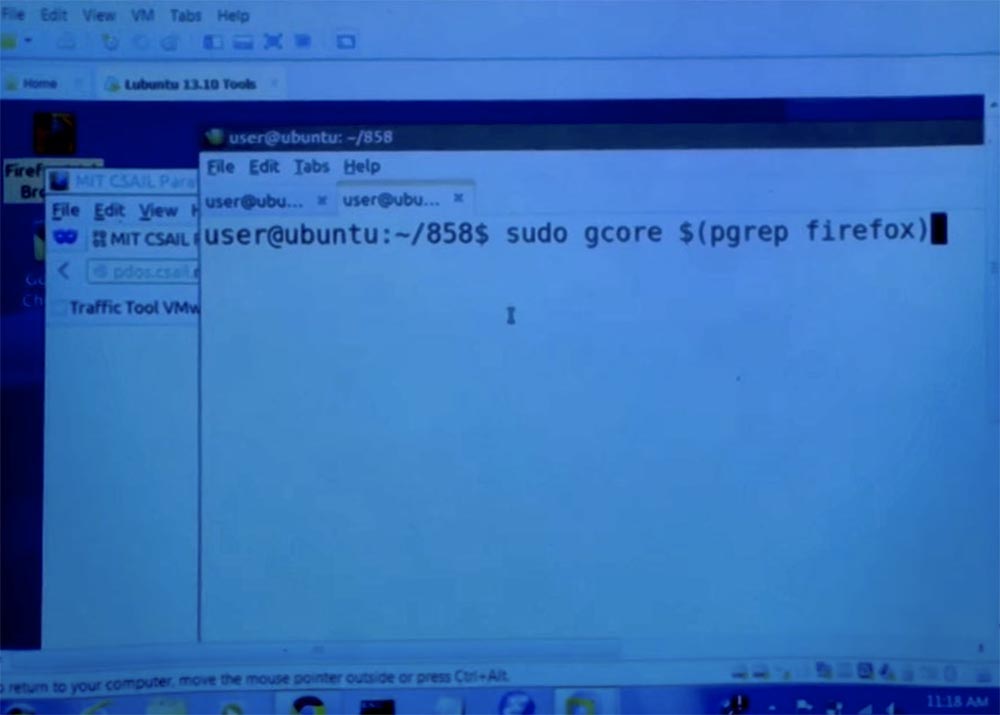
Then I use a bit of magic to make my terminal take a snapshot of memory, sometimes it takes a little time.
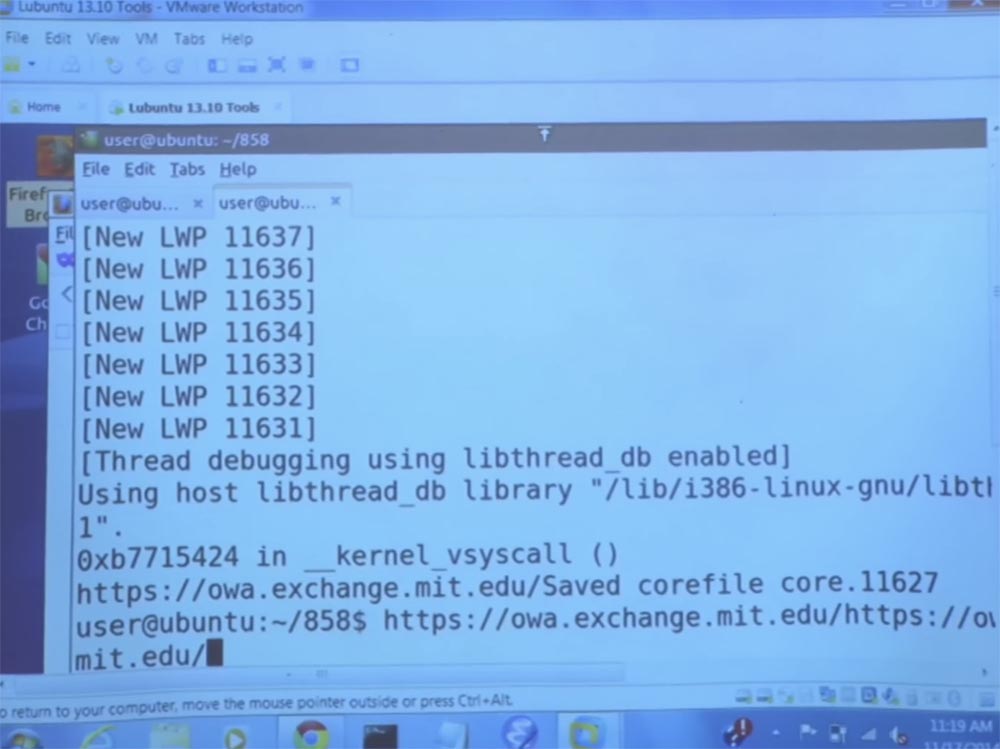
This is what happens - here the main image file of this private viewer is generated. Now we are going to look inside this image and see if we can find any references to pdos.

Interestingly, we see a bunch of instances of pdos strings with different prefixes in this memory image for private browsing.

If we look further, we will see things like full URLs and HTML codes.

The point is that if we were able to find all this in the memory of the page, that is, some data on this page was placed in the paging file on the disk, then the attacker could easily run these lines. He can do what I just did with the file on this page and try to find out which sites you visited in private view. It's clear?
In principle, the problem here is that the private browsing mode does not attempt to “confuse” RAM or somehow encrypt it. This seems like a pretty fundamental thing, because at some point a processor must perform a task based on open text data. Therefore, this circumstance can be a big problem. Anyone have any questions?
Student:this is exactly what I do not expect from my browser, because browsers must ensure the privacy of private browsing. For example, if you make any purchases, your friend who sat behind your computer will not be able to view them. Could you tell us a little about what guarantees the authors of the article give and whether they describe in the article what can be changed in the browsers to ensure such confidentiality?
Professor:Yes. This is very interesting. There is one thing that you can pay attention to - when you open a private browsing tab, as a rule, a text message appears in front of you: “welcome to incognito mode”. This mode will help you not to leave traces, if several users are working on the computer, and your friend, who has sat down behind you at the computer, will not be able to get acquainted with the history of your views, cookies and form data. However, the “incognito” mode will not help if someone with a rubber truncheon stands behind your back and is going to “knock out” you as soon as you enter the site.
Therefore, manufacturers themselves avoid specifying guarantees regarding the confidentiality of data when using their browsers.
In fact, after the Snowden incident, many browsers changed this pop-up message, because they wanted to actually make it clear to the user that they could not protect him from the interference of such forces as the NSA or something like that.
In short, what guarantees do they provide? In practice, they only provide the vulnerability that you just mentioned. That is, the one who cannot see now what you are doing can then see what you were doing. We assume that a non-professional cannot run lines in the paging file or do something similar. However, there are two problems. One of the problems is that browsers are so complex that they often do not even protect against the actions of non-professionals.
I can give you a personal example. Several times, when I saw on the page funny advertising banners “Huffington Post”, like, “look how touchingly these puppies help other puppies to go down the stairs!”, I sometimes caught up on such weakness and clicked on them. But since I didn’t want people to find out about my weakness, I sometimes did it in private viewing mode. However, it happened that sometimes the URLs of these advertisements leaked into the history of URLs in a normal, public browser mode for which this material was not intended. Thus, one of the problems is that sometimes these browsers do not provide protection against attacks by non-professionals.
Secondly, I think that there are a lot of people who, especially after the story of Snowden, would like from the private viewing mode a stronger privacy protection. They would like to protect against the attack of artifacts of RAM, even if they can not technically correctly formulate their desire.
Therefore, one of the things I did while studying at this institute was research in the area of enhancing protection in private browsing mode, so that we can talk about it. You will find out that all professors can talk endlessly about their research, so if you want to talk about it within three hours, just send me a request and we will arrange it. So what I’m shown only shows ... do you have a question?
Student:Yes, about RAM, because I am not familiar with how it works. Why can't the browser, at the end of the session, simply ask the OS to clear the portions of memory it used?
Professor: we'll get to this topic in a couple of minutes. But you are absolutely right. In a global sense, it is possible to imagine that the OS, after the completion of the process, looked through all the pages involved and wrote zeros into them. You can also imagine that the browser would fix all pages in memory so that they would not be cleared at all. There are some solutions that can do this, and in a second I will answer you.
So, this was an example of how data from RAM can get to disk through a paging file. But note that the lifetime of the data is a more serious problem than it seems in the context of private viewing. You can imagine that any programs that deal with, say, cryptographic keys or user passwords will have this problem. Each time you enter a program password, the memory page that contains this password can always be reflected on the disk.
Let me show you another example. Consider a fairly simple program called memclear. You see on the screen that we simply read the secret text file, and then forever “go to sleep”.

So what does the read_secret command do? It will read a certain file, print the contents of this file, and then clear the buffer that was used to store this secret information.
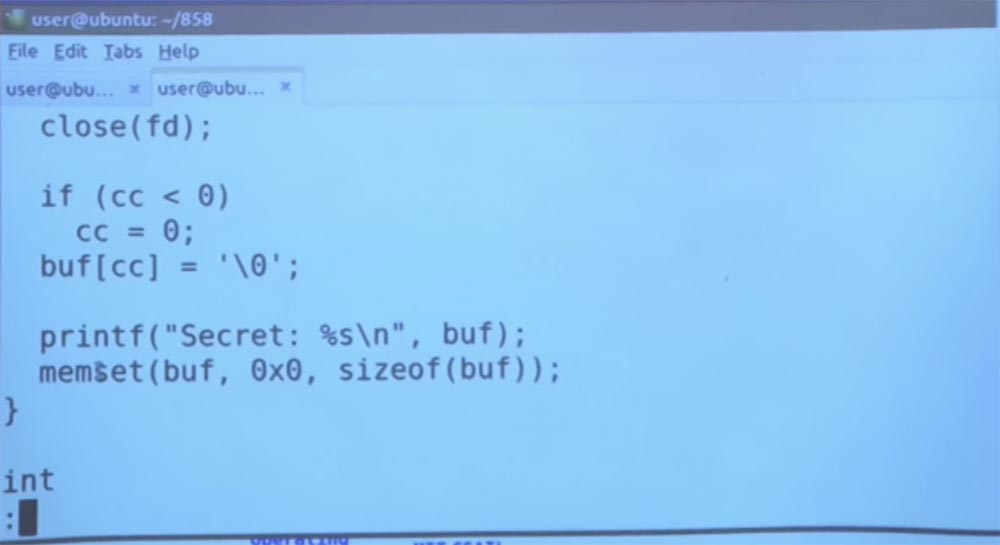
So back to your problem. You can imagine that the browser, for example, will try to simply use the memset command in order to reset all secrets that are found only in the private viewing mode. If we look at our secret file, we will see that there is nothing interesting in it, it simply says: “my secrets are in the file”.
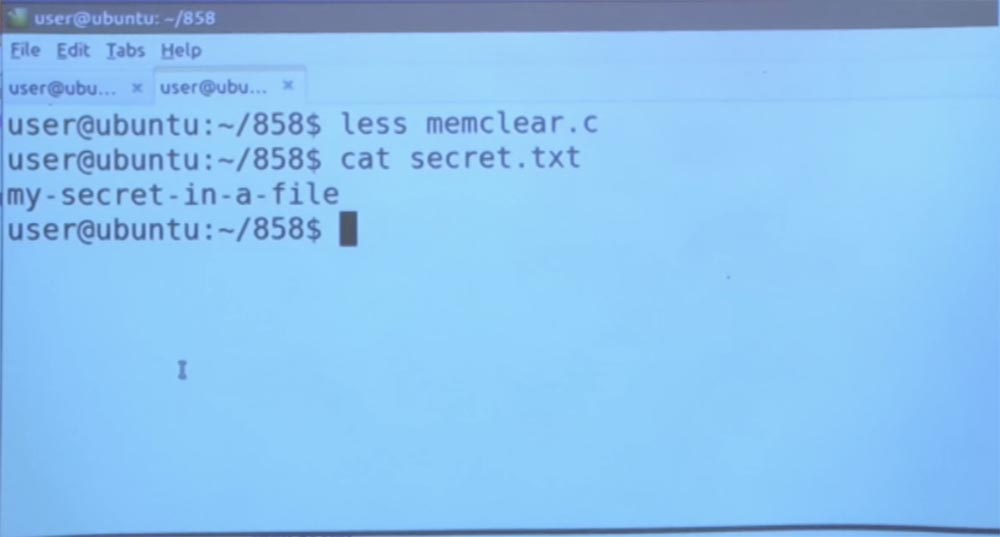
Then, if you run the program in the background, what will it do? As I said, it will simply print the contents of this file.
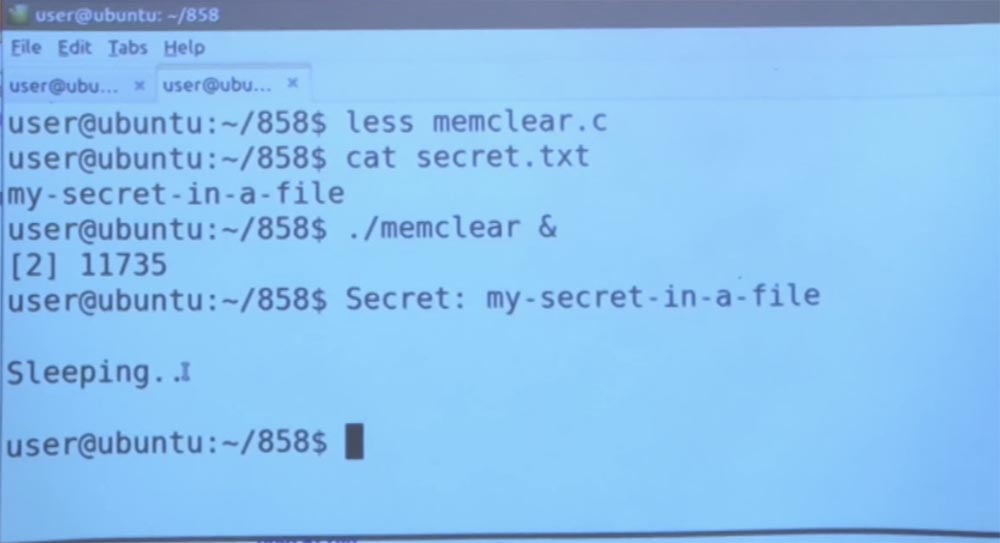
As I said, she just printed it out. She read this file, printed the contents of this “secret”, cleared the memory buffer that was used for printing, and went into sleep mode. If we use this fun gcore command again, we can get a memory dump of the memclear program that is running in memory right now.

Next, find the line that we need, and execute the grep command for our secret.

So, if you look at the memory image of this running program, we will find instances of the name of the file that was read, as well as some prefixes of the contents of the line of this file, despite the fact that we erased the buffer in the program itself. Can you tell why this happened? It seems very, very strange.
If you think about how data input / output works, then this looks like sample layers. By that time, when the contents of this file falls into the program, it has already passed, let's say, the kernel memory, the standard C library for I / O, because this library performs buffering, and so on. Ultimately, what happens is that even if you applied memset to the application's visible buffer, there are still instances of secret data located in various places throughout the system, and this program only considers the user mode of this application. So, probably, the data is still around, maybe in the input / output buffers of the kernel or something like that.

So back to your question. If you want to do what they call a security distribution, you cannot simply rely on application-level mechanisms, because there may be other places in the system where this data resides. What are these places? For example, data may be in process memory, where there are such things as a heap and a stack. Therefore, when we performed memset inside the memclear program, we basically tried to solve this particular problem. And we found out that this is necessary, but not enough to clear all instances of this secret from memory. So where else do the memory artifacts live? They can be in all types of files, in backup copies, SQL databases.
If at some point the application takes something in the RAM and writes it to one of these things, then I repeat once again, the attacker may be able to restore it after taking control of the disk.
As I mentioned, kernel memory can be another common place to store RAM artifacts, because, again, applications typically perform multi-level I / O, in which each piece of data passes through several parts of the stack. Consider, for example, data transmission over a network. First, the data must flow into some kind of network buffer, probably inside the kernel. Then they, probably, pass through the buffers of the standard library of the C language and only after that go to the user part, that is, to the application written by the developer. So this can be a big problem.
You can also think of freed memory pages as a source of data leakage. Imagine that your application allocates a bunch of memory, using, say, the malloc function or whatnot. Then this process dies, and the kernel starts another process, without resetting the physical RAM pages. It may happen that when this new process starts, it can simply go through all these physical pages of RAM, use a lot of memory and just do the same strange thing - see if there is anything interesting there. And then the attacker who initiated this process will be able to get your secrets.
There are many ways to leak information from the kernel. You can also think of input / output buffers for devices such as the keyboard and mouse. There are just a bunch of different factors that can lead to data leakage through the kernel.
How can an attacker try to get this information? In some cases, it is as easy as reading a paging file. You can read the hibernation file and just see what is there. Some file formats embed various versions. For example, Microsoft Word uses for work the principle that a single Word file actually contains versions of old data fragments. Therefore, if you could access this Word file, you could simply view all previous versions of the document using different formats.
As I noted a couple of minutes ago, security sharing is also a problem, because it cannot support a full stack. For example, in older versions of the Linux kernel, when you create a directory, the final directory, you can filter to a depth of 4 kilobytes of kernel memory. Only Zeus knows what is in these memories. And this is because Linux actually does not reset the memory of the kernel that was allocated, released, and then allocated again for something else.
So, as I mentioned earlier - if the kernel does not reset the pages that are provided to the process in user mode, you can leak user secrets from the same types of memory pages.
The situation is different with SSD. Most of them provide logging. In other words, when you send a record to the SSD, you do not overwrite the data directly, but actually write it to the log. And when part of the data becomes invalid, it becomes impossible to request them.

So in this case, you as a user are not lucky, because if you wrote a bunch of data that was not in demand with the SSD, then the attacker can look at this equipment and say: “great, I understand the format of this magazine, and although technically this data may be invalid, I can still recover them. "
Therefore, in a global sense, you may have a problem with stolen or discarded hard drives. Because if you do not use encryption, in more cases you can simply take the disk found in the garbage, deal with the physical layers of memory and recover the data.
Anyway, with these artifacts of RAM, there are many problems associated with the fact that the data is somehow “stuck” in permanent storage and may later become available to the attacker.
So how can we fix these problems with the lifetime of the data? We have already discussed one solution, which is to reset the memory after you have completed the process. So whenever you release something, you simply write a bunch of zeros or some random things to essentially hide the old data from someone who may come after you.
27:05 min.
Course MIT "Computer Systems Security". Lecture 18: "Private Internet Browsing", part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?