You Don't Know Node: A Brief Overview of Key Features
- Transfer

Remark from the author
This article is new, but it is not about new features. It is about core, that is, about the platform and the fact that many who simply use grunt or webpack may not suspect, so say about fundamentals.
Read in more detail: rumkin
comments : habrahabr.ru/company/mailru/blog/283228/#comment_8890604 Aiditz comments : habrahabr.ru/company/mailru/blog/283228/#comment_8890476 Suvitruf comments : habrahabr.ru/company/mailru/blog / 283228 / # comment_8890430
The idea for this post was inspired by a series of books by Kyle Simpson, “ You Don't Know JavaScript .” They are a good start to learning the basics of this language. And Node is almost the same JavaScript, with the exception of small differences, which I will discuss in this article. All the code below can be downloaded from the repository , from the folder
code. Why bother with Node at all? Node is JavaScript, and JavaScript is used almost everywhere! The world would be better if the majority of developers master Node perfectly. The better the application, the better life!
This article is a realistic look at the most interesting core features of Node. Key points of the article:
- Event loop: refreshing a key concept to implement non-blocking I / O.
- Global object and process: how to get more information.
- Event emitters: Intensive introduction to event-based pattern
- Streams and buffers: an efficient way to work with data
- Clusters: fork processes like a pro
- Asynchronous Error Handling: AsyncWrap, Domain, and uncaughtException
- Add-ons in C ++: making your own developments in the kernel and writing your own add-ons in C ++
Event loop
Let's start with the event loop that underlies Node.
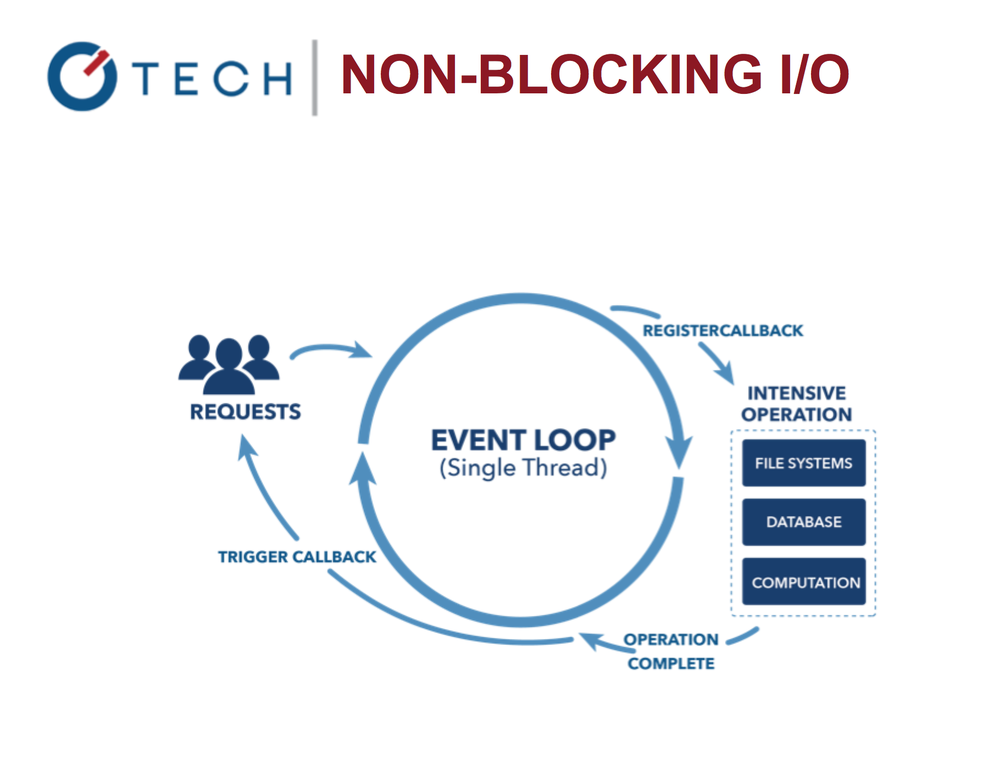
Non-blocking I / O in Node.js
The loop allows us to work with other tasks in parallel with performing I / O. Compare Nginx and Apache. It is thanks to the event loop that Node is very fast and efficient, because blocking I / O is not cheap!
Take a look at this simple example of a deferred function
printlnin Java:System.out.println("Step: 1");
System.out.println("Step: 2");
Thread.sleep(1000);
System.out.println("Step: 3");
This is comparable (though not quite) to the Node code:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
}, 1000)
console.log('Step: 2')
This is not the same. Start thinking in terms of asynchronous operation. The output of the Node script is 1, 2, 3; but if after “Step 2” we had more expressions, then they would be executed first, and then callback functions
setTimeout. Take a look at this snippet:console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
console.log('Step 5')
}, 1000);
console.log('Step: 2')
console.log('Step 4')
The result of his work will be the order of 1, 2, 4, 3, 5. The reason is that he
setTimeoutputs his callback in future periods of the event cycle. One can perceive the cycle of events as an endless cycle like
for … while. He stops only when there is nothing more to do, neither now nor in the future. 
Blocking I / O operations: multi-threaded Java
Event loop allows the system to work more efficiently, the application can do something else while waiting for the completion of expensive I / O operations.
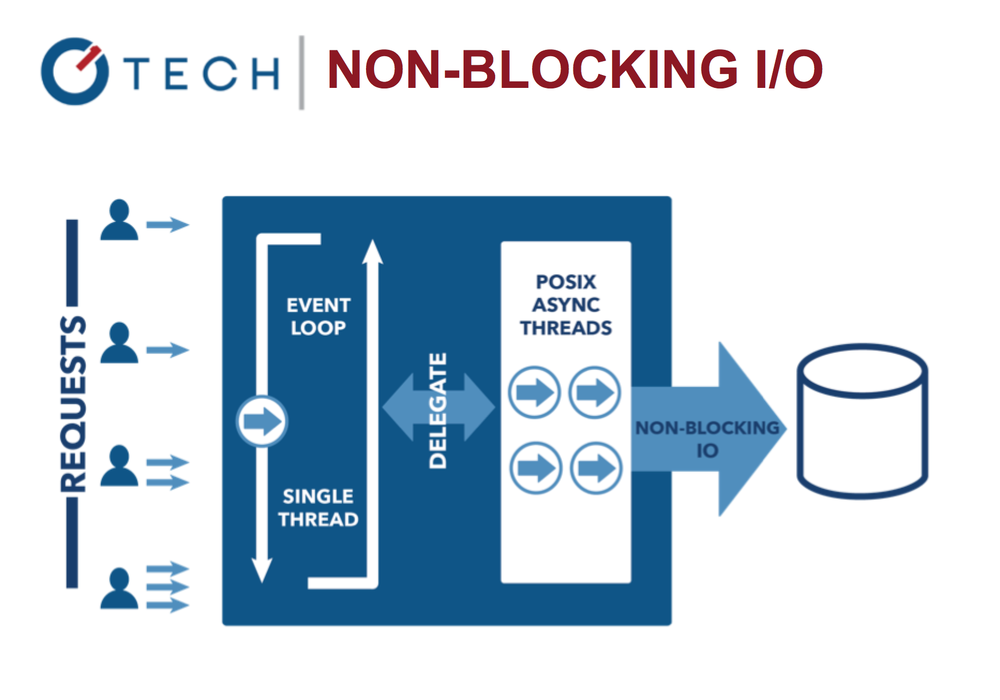
Non-Blocking I / O in Node.js
This contrasts with the more common concurrency model, which involves operating system threads. The thread-based networking model is quite inefficient and very difficult to use. Moreover, Node users may not be afraid of completely blocking processes - there are no locks here.
By the way, in Node.js you can still write blocking code. Take a look at this simple snippet:
console.log('Step: 1')
var start = Date.now()
for (var i = 1; i<1000000000; i++) {
// This will take 100-1000ms depending on your machine
}
var end = Date.now()
console.log('Step: 2')
console.log(end-start)
Of course, usually in our code there are no empty loops. When using other people's modules, it can be more difficult to detect synchronous, which means blocking code. For example, the main module
fs(file system) comes with two sets of methods. Each pair does the same thing, but in different ways. Blocking methods in the module fshave the word in the names Sync:var fs = require('fs')
var contents = fs.readFileSync('accounts.txt','utf8')
console.log(contents)
console.log('Hello Ruby\n')
var contents = fs.readFileSync('ips.txt','utf8')
console.log(contents)
console.log('Hello Node!')
The result of executing this code is completely predictable even for beginners in Node / JavaScript:
data1->Hello Ruby->data2->Hello NODE!
But everything changes when we switch to asynchronous methods. Here is an example of non-blocking code:
var fs = require('fs');
var contents = fs.readFile('accounts.txt','utf8', function(err,contents){
console.log(contents);
});
console.log('Hello Python\n');
var contents = fs.readFile('ips.txt','utf8', function(err,contents){
console.log(contents);
});
console.log("Hello Node!");
contentsare displayed last because their execution takes some time, they are also in callbacks. The event loop will go to them after reading the file:Hello Python->Hello Node->data1->data2
In general, the event loop and non-blocking I / O operations are very powerful things, but you have to write asynchronous code, which many are not used to.
Global object
When developers switch from browser-based JavaScript or another language to Node.js, they have the following questions:
- Where to store passwords?
- How to create global variables (node in Node
window)? - How to access CLI input, OS, platform, memory, versions, etc.?
To do this, there is a global object that has certain properties. Here is some of them:
global.process: process, system, environment information (you can refer to CLI input data, environment variables with passwords, memory, etc.)global.__filename: the name of the file and the path to the currently executing script in which this expression is located.global.__dirname: full path to the currently executing script.global.module: An object to export code that creates a module from this file.global.require(): method for importing modules, JSON files and folders.
There are also common suspects - methods from browser JavaScript:
global.console()global.setInterval()global.setTimeout()
Each of the global properties can be accessed using either a name typed in capital letters
GLOBALor no name at all, simply by writing processinstead global.process.Process
The process object deserves a separate chapter because it contains a ton of information. Here are some of its properties:
process.pid: The process ID of this Node instance.process.versions: different versions of Node, V8 and other componentsprocess.arch: system architectureprocess.argv: CLI argumentsprocess.env: environment variables
Some methods:
process.uptime(): gets work timeprocess.memoryUsage(): gets the amount of memory consumedprocess.cwd(): Gets the current working folder. Not to be confusedс __dirname, independent of the place from which the process was started.process.exit(): exits the current process. For example, you can pass the code 0 or 1.process.on(): attaches to an event, for example, `on ('uncaughtException')
Difficult question: who likes and who understands the essence of callbacks?
Someone is so "in love" with them that he created http://callbackhell.com . If this term is not familiar to you, then here is an illustration:
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
The callback hell is hard to read, and mistakes can easily be made here. So how do we divide into modules and organize asynchronous code, if not using callbacks, which are not very convenient for scaling from a development point of view.
Event emitters
Event emitters are used to deal with the hell of callbacks, or the pyramid of doom . With their help, you can implement asynchronous code using events.
In short, an event emitter is a trigger for an event that anyone can listen to. In Node.js, for each event, a string name is assigned to which a callback can be hung by the emitter.
What are emitters for:
- In Node, events are processed using the observer pattern.
- An event (or subject) tracks all functions associated with it.
- These functions — observers — are executed when this event is activated.
To use emitters, you need to import the module and create an instance of the object:
var events = require('events')
var emitter = new events.EventEmitter()
Next, you can attach event receivers and activate / send events:
emitter.on('knock', function() {
console.log('Who\'s there?')
})
emitter.on('knock', function() {
console.log('Go away!')
})
emitter.emit('knock')
Let's
EventEmitterdo something useful with the help of inheriting it from him. Let's say you regularly need to implement some class - monthly, weekly or every day. This class must be flexible enough so that other developers can customize the final result. In other words, at the end of your work, any person should be able to put some kind of logic in the class. This diagram shows how we, using inheritance from the event module, create
Joband then use the event receiver doneto change the behavior of the class Job: 
Event emitters in Node.js: “observer” template
The class will
Jobretain its properties, but at the same time will receive events. At the end of the process, we only need to fire the event done:// job.js
var util = require('util')
var Job = function Job() {
var job = this
// ...
job.process = function() {
// ...
job.emit('done', { completedOn: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter)
module.exports = Job
In conclusion, we change the behavior
Job. Once it sends done, then we can attach the event receiver:// weekly.js
var Job = require('./job.js')
var job = new Job()
job.on('done', function(details){
console.log('Job was completed at', details.completedOn)
job.removeAllListeners()
})
job.process()
Emitters have other possibilities:
emitter.listeners(eventName): Forms a list of all recipients for this event.emitter.once(eventName, listener): attaches a one-time event receiver.emitter.removeListener(eventName, listener): Deletes the event receiver.
Node uses an event pattern everywhere, especially in the main modules. So if you use events correctly, you will save a lot of time.
Streams
When working with large amounts of data in Node there are several problems. Performance may be low, and the buffer size is limited to approximately 1 GB. In addition, how to work in an endless resource that was created with the expectation that it will never end? In these situations, streams will help us.
Streams in Node are an abstraction, denoting the continuous splitting of data into fragments. In other words, you do not need to wait until the resource is fully loaded. The diagram shows a standard approach to buffering:
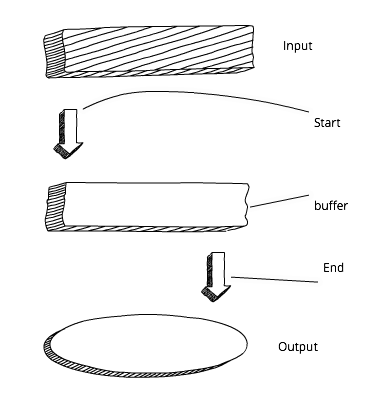
The approach to buffering in Node.js
Before we start processing the data and / or output it, we have to wait until the buffer is fully loaded. Now compare this with the stream scheme. In this case, we can immediately start processing the data and / or output it as soon as we get the first chunk:
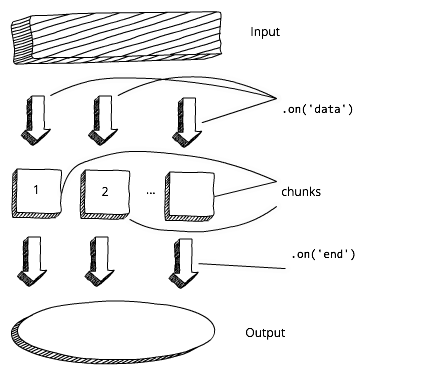
Streaming approach in Node.js
There are four types of streams in Node:
- Readable: You can read from them.
- Writable: you can write to them.
- Duplex (duplex): you can write and read.
- Transforms: they can be used to transform data.
Virtually, streams are used everywhere in Node. The most popular stream implementations:
- HTTP requests and responses.
- Standard input / output operations.
- Reading from and writing to files.
To provide an observer pattern, streams — events — inherit from the event emitter object. We can use this to implement streams.
Readable Stream Example
An example
process.stdinis the standard input stream. It contains data that enters the application. This is usually keyboard information used to start the process. To read data from
stdinevents, dataand are used end. Callback events dataas an argument will have chunk:process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})
Then it is
chunkfed to the program as input. This event can be activated several times, depending on the total amount of incoming information. The completion of the stream must be signaled by an event end. Please note:
stdinby default it is paused, from which it must be deduced before reading data from it. Readable streams have a synchronously working interface
read(). At the end of the stream, it returns chunkor null. We can take advantage of this behavior by setting the condition in the whileconstruct null !== (chunk = readable.read()):var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})
Ideally, we would like to write asynchronous code in Node as often as possible in order to avoid thread blocking. But thanks to the small size of the chunks, you don’t have to worry about the synchronous
readable.read()blocking of the thread.Example of a recorded stream
An example
process.stdoutis the standard output stream. It contains data that leaves the application. You can write to stream using the operation write.process.stdout.write('A simple message\n')
The data recorded in the standard output stream is displayed on the command line, as if we had used it
console.log().Pipe
Node has an alternative to the above events - a method
pipe(). The following example reads data from a file, compresses it using GZip, and writes the result to a file:var r = fs.createReadStream('file.txt')
var z = zlib.createGzip()
var w = fs.createWriteStream('file.txt.gz')
r.pipe(z).pipe(w)
Readable.pipe()It takes a data stream and passes through all the streams, so we can create chains from methods pipe(). So when using streams you can use events or pipe.
HTTP streams
Most of us use Node to create web applications: traditional (server-side) or based on the REST API (client-side). What about HTTP requests? Can they be streamed? Definitely!
Requests and responses are read and written streams inherited from event emitters. You can attach the event receiver
dataand receive it chunkin its callback, which can be immediately converted without waiting for the entire response. In the following example, we concatenate bodyand parse it into callback events end:const http = require('http')
var server = http.createServer( (req, res) => {
var body = ''
req.setEncoding('utf8')
req.on('data', (chunk) => {
body += chunk
})
req.on('end', () => {
var data = JSON.parse(body)
res.write(typeof data)
res.end()
})
})
server.listen(1337)
Please note: according to ES6,
()=>{}is the new syntax for anonymous functions, and constis a new operator. If you are not already familiar with the features and syntax of ES6 / ES2015, then you can study the Top 10 article on ES6 properties that every busy JavaScript developer should know about . Let's now use Express.js to make our server less divorced from real life. Let's take a huge image (about 8 MB) and two sets of Express routes
/streamand /non-stream. server-stream.js:
app.get('/non-stream', function(req, res) {
var file = fs.readFile(largeImagePath, function(error, data){
res.end(data)
})
})
app.get('/stream', function(req, res) {
var stream = fs.createReadStream(largeImagePath)
stream.pipe(res)
})
I also have an alternative implementation
/stream2with events, and a synchronous implementation /non-stream2. They do the same thing, but they use a different syntax and style. In this case, synchronous methods are faster because we send only one request, and not several competing ones. You can run this code through the terminal:
$ node server-stream
Now open in Chrome http: // localhost: 3000 / stream and http: // localhost: 3000 / non-stream . Pay attention to the headings in the Network tab in the developer tools, comparing
X-Response-Time. In my case, /streamthey /stream2differed by orders of magnitude: 300 ms. and 3-5 sec. You may have other meanings, but the idea is clear: in the case of /streamusers / clients, they will start receiving data earlier. Streaming in Node is a very powerful tool! You can learn how to manage stream resources well by becoming an expert in this field in your team. With npm, you can install Stream Streambook and stream-adventure :
$ sudo npm install -g stream-adventure
$ stream-adventure
Buffers
What types can we use for binary data? If you remember, in the JavaScript browser there is no binary data type, but in Node there is. This is called a buffer. It is a global object, so there is no need to import it as a module.
You can use one of these expressions to create a binary type:
new Buffer(size)new Buffer(array)new Buffer(buffer)new Buffer(str[, encoding])
A complete list of methods and encodings is available in the buffer documentation . The most commonly used encoding
utf8. Usually the contents of the buffer look like an abracadabra, so in order for it to be readable to a person, you first need to convert it to a string representation with
toString(). Create a buffer with the alphabet using a loop for:let buf = new Buffer(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97 // 97 is ASCII a
}
If you do not convert the buffer to a string representation, it will look like an array of numbers:
console.log(buf) // We carry out the conversion:
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz
If we need only a part of the string (sub string), then the method takes the initial number and the final position of the desired segment:
buf.toString('ascii', 0, 5) // outputs: abcde
buf.toString('utf8', 0, 5) // outputs: abcde
buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcde
Do you remember
fs? By default, the value is dataalso a buffer:fs.readFile('/etc/passwd', function (err, data) {
if (err) return console.error(err)
console.log(data)
});
data acts as a buffer when working with files.Clusters
Opponents of Node often argue that it can scale because it has only one thread. However, with the help of the main module
cluster(you do not need to install it, this is part of the platform) we can use all processor resources on any machine. In other words, thanks to clusters, we can scale Node applications vertically. The code is very simple: we import the module, create one master and several workers. Usually create one process for each CPU, but this is not an unshakable rule. You can do as many processes as you wish, but from a certain point in time, productivity growth will stop, according to the law of decreasing profitability.
The master and employee code is in one file. An employee can listen on the same port by sending events to the master. The wizard can listen to events, and restart clusters if necessary. For the master is used
cluster.isMaster(), for the employee - cluster.isWorker(). Most of the server code will be located in worker ( isWorker()).// cluster.js
var cluster = require('cluster')
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
// ваш серверный код
})
In this example, my server issues process IDs, so you can observe how different workers handle different requests. It looks like a load balancer, but this is only an impression, because the load will not be distributed evenly. For example, by PID you will see how one of the processes can handle much more requests.
To see how different employees serve different requests, use
loadtestthe Node-based load test tool :- Install
loadtestwithnpm: $ npm install -g loadtest - Run
code/cluster.jsusing node ($ node cluster.js); let the server continue to work. - Start in new window Load testing:
$ loadtest http://localhost:3000 -t 20 -c 10. - Analyze the results from the server terminal and from the terminal
loadtest. - At the end of testing in the server terminal, press Ctrl + C. You will see different PIDs.
In a team, a
loadtestpiece -t 20 -c 10means that 10 competitive requests will be completed in no more than 20 seconds. A cluster is part of the core, and this is almost its only advantage. When your project is ready for deployment, you may need to use a more advanced process manager. A good choice would be:
strong-cluster-control(https://github.com/strongloop/strong-cluster-control) or$ slc runpm2(https://github.com/Unitech/pm2)
pm2
Let's look at the tool
pm2, as this is one of the best ways to scale your Node application vertically. In addition, it pm2improves productivity at the production stage. Advantages
pm2:- Load balancer and a number of other useful features.
- Lack of downtime during reboot, that is, it works constantly.
- Good test coverage.
The documentation can be found at https://github.com/Unitech/pm2 and http://pm2.keymetrics.io .
An example of using pm2 is the express server
server.js. It’s good that there is no boilerplate code isMaster(), because you don’t have to modify the source code, as we did in the case of cluster. Here it is enough to log pidand save statistics on them.var express = require('express')
var port = 3000
global.stats = {}
console.log('worker (%s) is now listening to http://localhost:%s',
process.pid, port)
var app = express()
app.get('*', function(req, res) {
if (!global.stats[process.pid]) global.stats[process.pid] = 1
else global.stats[process.pid] += 1;
var l ='cluser '
+ process.pid
+ ' responded \n';
console.log(l, global.stats)
res.status(200).send(l)
})
app.listen(port)
To run this example, enter
pm2 start server.js. You can multiply instances / processes by entering the required number ( -i 0means that there should be as many processes as the CPU, in my case there are 4). To save the log to a file, use the option -l log.txt:$ pm2 start server.js -i 0 -l ./log.txt
The nice thing is that pm2 is running in the background. To view the currently executing processes, enter:
$ pm2 list
Now use
loadtesthow we did in example c cluster. In a new window, do:$ loadtest http://localhost:3000 -t 20 -c 10
You may have different results, but my
log.txtdistribution turned out to be more or less uniform:cluser 67415 responded
{ '67415': 4078 }
cluser 67430 responded
{ '67430': 4155 }
cluser 67404 responded
{ '67404': 4075 }
cluser 67403 responded
{ '67403': 4054 }
Compare Spawn, Fork, and Exec
In the example, a
cluter.jsNode server was used to create a new instance fork(). But I must say that to run an external process from Node.js three ways: spawn(), fork()and exec(). Moreover, they are all taken from the main module child_process. The difference between these three methods is as follows:require('child_process').spawn(): used for large amounts of data; supports streams; can be applied with any teams; does not create a new instance of V8.require('child_process').fork(): creates a new instance of V8 and instances of workers; only works with Node.js scripts (commandnode).require('child_process').exec(): inconvenient for large amounts of data, because it uses a buffer; works asynchronously to simultaneously receive all the data in a callback; can be applied with any team, not onlynode.
Look at the following example: we execute
node program.js, but you can run any other commands or scripts - bash, Python, Ruby, etc. If you need to pass additional arguments to the command, simply put them as arguments to the array, which is the parameter spawn(). The data will go to the event handler dataas stream:var fs = require('fs')
var process = require('child_process')
var p = process.spawn('node', 'program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
From the point of view of the command
node program.js, this datais the standard way of output, for example, to the terminal. The syntax is
fork()almost similar to the syntax of the method spawn(), with one exception: the command is not needed here, because it fork()assumes that all processes are related to Node.js:var fs = require('fs')
var process = require('child_process')
var p = process.fork('program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
Finally
exec(). This method differs from the previous ones in that it does not use an event template, but a single callback. Inside it there is error, standard output and standard error parameters:var fs = require('fs')
var process = require('child_process')
var p = process.exec('node program.js', function (error, stdout, stderr) {
if (error) console.log(error.code)
})
The difference between
errorand stderrlies in the fact that we get the first from exec()(say, program.jsaccess denied), and the second from the error output of the command you started (for example, program.jscould not connect to the database).Asynchronous Error Handling
For error handling, Node.js and almost all other programming languages are used
try/catch. With synchronous errors, this design works great.try {
throw new Error('Fail!')
} catch (e) {
console.log('Custom Error: ' + e.message)
}
Modules and functions throw errors, and then we catch them. This is how Java and synchronous Node work. But in Node.js, it is best to write asynchronous code so as not to block thread.
Thanks to the cycle of events, the system can delegate and apply a schedule for code that must be executed in the future, upon completion of resource-intensive I / O tasks. But here we have a problem with asynchronous errors, because the context of the error is lost.
For example, it
setTimeout()works asynchronously, deferring a callback call for the future. An asynchronous function that makes an HTTP request, reads from a database or writes to a file will behave similarly:try {
setTimeout(function () {
throw new Error('Fail!')
}, Math.round(Math.random()*100))
} catch (e) {
console.log('Custom Error: ' + e.message)
}
When a callback is executed and the application crashes, it is no longer here
try/catch. Of course, you can put another construct in the callback try/catchthat will catch the error, but this is a bad solution. All of these annoying asynchronous errors are more difficult to catch and debug. For asynchronous code is try/catchnot the best option. So the application crashed. What shall we do with this? You have already seen that most callbacks have an argument
error. In each case, you need to check and pull it out: reject the callback chain or display an error message to the user. if (error) return callback(error)
// or
if (error) return console.error(error)
Another good way to handle asynchronous errors is as follows:
- We listen to all error messages (on error).
- We are listening
uncaughtException. - Use
domain(somewhat outdated) or AsyncWrap . - We log and track.
- Notify (optional).
- Exit and restart the process.
on ('error')
Listen to events
on('error')generated by most of the core objects in Node.js, in particular http. It also errorgenerates everything, inherits from, or instantiates Express.js, LoopBack, Sails, Hapi, etc., because these frameworks expand http.js
server.on('error', function (err) {
console.error(err)
console.error(err)
process.exit(1)
})
uncaughtException
Always listen
uncaughtExceptionin the facility process! uncaughtException- This is a very crude error handling mechanism. If the error is not processed, then your application - and therefore Node.js - is in an undefined state. An unhandled exception means your application - and by extension Node.js itself - is in an undefined state. If you resume work blindly, anything can happen.
process.on('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
})
or
process.addListener('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
Domain
It
domainhas nothing to do with network domains in a browser. This is the core Node.js module for handling asynchronous errors. It maintains the context in which asynchronous code is implemented. Standard approach: create a copy domainand put the error code inside the callback run():var domain = require('domain').create()
domain.on('error', function(error){
console.log(error)
})
domain.run(function(){
throw new Error('Failed!')
})
Starting with version 4.0,
domainit is considered obsolete, so Node developers will probably separate it from the platform. But to date, there is no alternative to the Node core domain. In addition, thanks to serious support and widespread use, it domainwill exist as a separate npm module, so you can easily switch from the main module to npm. So domainwe don’t say goodbye. Let's make an asynchronous error using the same
setTimeout():// domain-async.js:
var d = require('domain').create()
d.on('error', function(e) {
console.log('Custom Error: ' + e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, Math.round(Math.random()*100))
});
The code will not fall! From the
domainevent handler errorwe get, we get a beautiful “Custom Error” message, not a typical stack trace for Node.Addons in C ++
The popularity of Node among developers of hardware, IoT, drones, robots, and smart gadgets is that it allows you to play with lower-level C / C ++ code. How can you write your C / C ++ binders?
This is the last of the main features in this article. Most newcomers to Node have no idea that here you can write your own add-ons in C ++! It is so simple that we will write an add-on from scratch right now.
First, create a file
hello.cc, at the beginning of which we will place several template imports. Then we define a method that returns a string and exports itself.#include
namespace demo {
using v8::FunctionCallbackInfo;
using v8::HandleScope;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); // String
}
void init(Local