How to degrade the performance of your application - typical mistakes of developers
- Transfer
Performance is considered one of the most important non-functional application requirements. If you are reading this article, you are probably using an application, such as a web browser or a program for reading documents, and you understand how great the value of performance is. In this article, I’ll talk about application performance and the three developers ’mistakes that make it impossible to achieve high application performance.

It doesn't matter what your programming experience is: you may have just graduated from high school or have many years of experience, but when you need to develop a program, you will most likely try to find code that has already been developed earlier. Of course, it is desirable that this code be in the same programming language that you are going to use.
There is nothing wrong. This approach often leads to faster development. On the other hand, in doing so, you will lose the opportunity to learn something new. Using this approach, it is extremely rare to find time to properly analyze the code and understand not only the algorithm, but also the internal work of each line of code.
This is one example of a situation where we, the developers, are going the wrong way. However, there are many such ways. For example, when I was younger and just starting to get acquainted with software development, I tried to imitate my boss in everything: everything that he did seemed to me impeccable and certainly correct. When I needed to do something, I watched the boss do the same, and tried to repeat all his actions as accurately as possible. It has repeatedly happened that I just did not understand why his approach works, but is it really important? The main thing is that everything works!
There is a type of developers who will work as hard as possible to solve the task assigned to them. As a rule, they look for ready-made components, components, blocks, put all these pieces together, and you're done! Mission accomplished! Such developers rarely take the time to study and understand the found code fragments, and do not at all care about such "minor" things as scalability, ease of maintenance or performance.
Another scenario is possible in which they will not understand exactly how each component of the program works: if the developers have never encountered problems. If you are using a technology for the first time and you are having difficulty, then you will study this technology in detail and eventually find out how it works.
Let's look at a few examples that will help us understand the difference between understanding technology and its normal use. Since I am mainly involved in the development of .NET * -based web solutions, we’ll talk about this.
Consider the following code example. Everything is simple. The code just updates the style of one element in the DOM. The problem (now in modern browsers this problem is not so relevant, but it is quite suitable for illustrating my thought) is that the code bypasses the DOM tree three times. If the code is repeated, and the document is quite large and complex at the same time, application performance will noticeably decrease.

To fix such a problem is quite simple. Have a look at the following code example. Before working with an object in the myField variable , a direct link is held. The new code is more compact, it is more convenient to read and understand, and it works faster because the DOM tree is accessed only once.

Consider another example. This example is taken from here .
The following figure shows two equivalent code fragments. Each of them creates a list with 1000 li elements . The code on the right adds an id attribute to each li element , and the code on the left adds a class attribute to each li element .

As you can see, the second part of the code fragment simply refers to each of the thousands of li elements created . I measured the speed in Internet Explorer * 10 and Chrome * 48: the average execution time of the code shown on the left was 57 ms, and the execution time of the code shown on the right was only 9 ms, significantly less. The difference is huge, despite the fact that in this case it is caused only by different ways of accessing elements.
This example should be taken very carefully. In this example, there are still a lot of interesting points for analysis, for example, the order of checking selectors (here this is the order from right to left). If you use jQuery *, then read about the DOM context. See here for general CSS selector performance principles .
A final example is JavaScript code. This example is more related to memory, but it helps to understand how everything really works. Excessive memory consumption in browsers will lead to reduced performance.
The following figure shows two different ways to create an object with two properties and one method. On the left, the class constructor adds two properties to the object, and an additional method is added through the class prototype. On the right, the constructor immediately adds both properties and the method.
After creating such an object, thousands of objects are created using these two methods. If you compare the amount of memory used by these objects, you will notice a difference in the use of the Shallow Size and Retained Size memory areas in Chrome. The prototype approach uses about 20% less memory (20 KB compared to 24 KB) in the Shallow Size area and 66% less in the Retained Memory area (20 KB compared to 60 KB).
For more information on Shallow Size and Retained Size, see here .
You can create objects, knowing how to use the right technology. By understanding how a technology works, you can optimize applications in terms of memory management and performance.

In preparation for my speech at the conference on the topic under discussion, I decided to prepare an example with server code. I decided to use LINQ * because LINQ is widely used in the .NET world for new developments and has significant potential for increasing productivity.
Consider the following common scenario. The following figure shows two functionally equivalent code fragments. The purpose of the code is to create a list of all departments and all courses for each department in the school. In the code called Select N + 1, we display a list of all departments, and for each department a list of courses. This means that if there are 100 branches, we will need 1 + 100 calls to the database.

This problem can be solved in another way. One simple approach is shown in the code snippet on the right side. When using the Include method (in this case I will use a hard-coded string for ease of understanding) there will be only one call to the database, and this single call will immediately issue all departments and courses. In this case, when executing the second foreach loop, all Courses collections for each department will already be in memory.
Thus, you can increase productivity by hundreds of times by simply avoiding the Select N + 1 approach.
Consider a less obvious example. In the figure below, the whole difference between the two pieces of code lies in the data type of the destination list on the second line. Here you may wonder: does the type of destination data affect anything? If you study the operation of this technology, you will understand: the type of destination data actually determines the moment at which the query to the database is performed. And from this, in turn, depends on the moment of applying filters of each request.
In Code # 1, where an IEnumerable data type is expected, the query is executed immediately before Take Employee (10) is executed . This means that if there are 1000 employees, they will all be obtained from the database, after which 10 will be selected.

In Code # 2, the query is executed after Take Employee (10) is executed . In this case, only 10 records are retrieved from the database. The following article explains in detail the differences when using different types of collections.
In SQL, you need to learn a lot of features in order to achieve the highest database performance. Working with SQL Server is not easy: you need to understand how the data is used, which tables are most often requested, and which fields.
Nevertheless, to increase productivity, a number of general principles can be applied, for example:
For brevity, I will not give specific examples, but these principles can be used, analyzed and optimized.
So, how do we developers need to change our mindset to avoid the No. 1 erroneous approach?
I have been developing on .NET since version 1.0. I know in great detail all the features of web forms, as well as many .NET client libraries (I changed some of them myself). When I learned about the release of Model View Controller (MVC), I didn’t want to use it: “We don’t need it.”
As a matter of fact, this list can be continued rather long. I mean a list of things that I did not like at first and which I often and confidently use now. This is just one example of a situation where developers are inclined to favor some technical solutions and avoid others, which makes it difficult to achieve higher productivity.
I often hear discussions about either LINQ binding to objects in the Entity Framework, or SQL stored procedures when querying data. People are so used to using one or the other solution that they try to use them everywhere.
Another factor affecting the preferences of developers (the predominant choice of some technologies and the rejection of others) is a personal attitude to open source software. Developers often choose not the solution that is best suited to the current situation, but the one that is more consistent with their philosophy of life.
Sometimes external factors (for example, tight deadlines) force us to make suboptimal decisions. It takes time to choose the best technology: you need to read, try, compare and draw conclusions. When developing a new product or a new version of an existing product, it often happens that we are already late: “The deadline is yesterday.” Two obvious solutions to this situation are: requesting extra time or working overtime for self-education.
How do we developers need to change our mindset to avoid the No. 2 erroneous approach.
So, we made a lot of efforts and created the best application. It's time to move on to its deployment. We have all tested. Everything works perfectly on our machines. All 10 testers were completely satisfied with the application itself and its performance.
Therefore, now certainly no problems can arise, everything is in perfect order?
By no means, everything may be completely out of order!
Have you asked yourself the following questions?
I understand that not all of these issues relate directly to infrastructure, but everything has its time. As a rule, the final actual conditions in which our application will work differ from the conditions on the servers at an intermediate stage.
Let's look at a few possible factors that may affect the performance of our application. Suppose users are located in different countries of the world. Perhaps the application will work very quickly, without any complaints from users in the United States, but users from Malaysia will complain about the low speed.
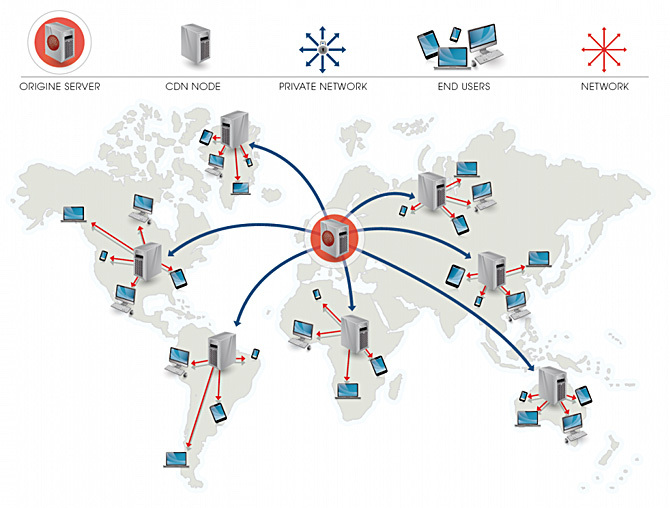
There are many ways to solve such problems. For example, you can use data distribution networks (CDNs) and place static files on them. After that, loading pages for users located in different places will be faster. What I'm talking about is shown in the following figure.
Another situation is possible: suppose that applications run on servers that simultaneously run SQL Server and the web server. In this case, two server systems with intensive CPU load are running on the same physical server. How to solve this problem? If we are talking about a .NET application on an Internet Information Services (IIS) server, we can use processor matching. Processor matching is the binding of one process to one or more specific CPU cores of a computer.
For example, suppose a computer with four processors runs SQL Server and the IIS Web server.

If you let the operating system decide which CPU will be used for SQL Server and which for IIS, resources can be allocated differently. It is possible that each processor load will be assigned two processors.

And it is possible that all four processors will be allocated only to one load.

In this case, a deadlock may occur: IIS can serve too many queries and take all four processors, while some queries may require access to SQL, which in this case will be impossible. In practice, such a scenario is unlikely, but it perfectly illustrates my point.
Another possible situation: one process will not work all the time on the same CPU. Context switching will often occur. Frequent switching of the context will lead to a decrease in the performance of the server itself, and then of applications running on this server.
One way to solve this problem is to use “processor matching” for IIS and SQL. In this case, we decide how many processors are needed for SQL Server, and how many - for IIS. To do this, configure the settings in the "Processor Compliance" section in the CPU category in IIS and the "compliance mask" in the SQL Server database. Both of these cases are shown below.

You can continue this topic with other infrastructure features related to improving productivity, such as when using web farms.
How do we developers need to change our mindset to avoid the No. 3 erroneous approach?
You have nothing to reproach yourself with. Not everything depends on you. Indeed, there is no time. All families, all hobbies, everyone needs to relax.
But it’s important to understand that good work is not only about writing good code. We all at some time used some or all of the erroneous approaches described.
Here's how to avoid them.
Mistake Approach # 1. Insufficient understanding of development technologies
It doesn't matter what your programming experience is: you may have just graduated from high school or have many years of experience, but when you need to develop a program, you will most likely try to find code that has already been developed earlier. Of course, it is desirable that this code be in the same programming language that you are going to use.
There is nothing wrong. This approach often leads to faster development. On the other hand, in doing so, you will lose the opportunity to learn something new. Using this approach, it is extremely rare to find time to properly analyze the code and understand not only the algorithm, but also the internal work of each line of code.
This is one example of a situation where we, the developers, are going the wrong way. However, there are many such ways. For example, when I was younger and just starting to get acquainted with software development, I tried to imitate my boss in everything: everything that he did seemed to me impeccable and certainly correct. When I needed to do something, I watched the boss do the same, and tried to repeat all his actions as accurately as possible. It has repeatedly happened that I just did not understand why his approach works, but is it really important? The main thing is that everything works!
There is a type of developers who will work as hard as possible to solve the task assigned to them. As a rule, they look for ready-made components, components, blocks, put all these pieces together, and you're done! Mission accomplished! Such developers rarely take the time to study and understand the found code fragments, and do not at all care about such "minor" things as scalability, ease of maintenance or performance.
Another scenario is possible in which they will not understand exactly how each component of the program works: if the developers have never encountered problems. If you are using a technology for the first time and you are having difficulty, then you will study this technology in detail and eventually find out how it works.
Let's look at a few examples that will help us understand the difference between understanding technology and its normal use. Since I am mainly involved in the development of .NET * -based web solutions, we’ll talk about this.
▍JavaScript * and DOM
Consider the following code example. Everything is simple. The code just updates the style of one element in the DOM. The problem (now in modern browsers this problem is not so relevant, but it is quite suitable for illustrating my thought) is that the code bypasses the DOM tree three times. If the code is repeated, and the document is quite large and complex at the same time, application performance will noticeably decrease.
To fix such a problem is quite simple. Have a look at the following code example. Before working with an object in the myField variable , a direct link is held. The new code is more compact, it is more convenient to read and understand, and it works faster because the DOM tree is accessed only once.
Consider another example. This example is taken from here .
The following figure shows two equivalent code fragments. Each of them creates a list with 1000 li elements . The code on the right adds an id attribute to each li element , and the code on the left adds a class attribute to each li element .
As you can see, the second part of the code fragment simply refers to each of the thousands of li elements created . I measured the speed in Internet Explorer * 10 and Chrome * 48: the average execution time of the code shown on the left was 57 ms, and the execution time of the code shown on the right was only 9 ms, significantly less. The difference is huge, despite the fact that in this case it is caused only by different ways of accessing elements.
This example should be taken very carefully. In this example, there are still a lot of interesting points for analysis, for example, the order of checking selectors (here this is the order from right to left). If you use jQuery *, then read about the DOM context. See here for general CSS selector performance principles .
A final example is JavaScript code. This example is more related to memory, but it helps to understand how everything really works. Excessive memory consumption in browsers will lead to reduced performance.
The following figure shows two different ways to create an object with two properties and one method. On the left, the class constructor adds two properties to the object, and an additional method is added through the class prototype. On the right, the constructor immediately adds both properties and the method.
After creating such an object, thousands of objects are created using these two methods. If you compare the amount of memory used by these objects, you will notice a difference in the use of the Shallow Size and Retained Size memory areas in Chrome. The prototype approach uses about 20% less memory (20 KB compared to 24 KB) in the Shallow Size area and 66% less in the Retained Memory area (20 KB compared to 60 KB).
For more information on Shallow Size and Retained Size, see here .
You can create objects, knowing how to use the right technology. By understanding how a technology works, you can optimize applications in terms of memory management and performance.
▍LINQ
In preparation for my speech at the conference on the topic under discussion, I decided to prepare an example with server code. I decided to use LINQ * because LINQ is widely used in the .NET world for new developments and has significant potential for increasing productivity.
Consider the following common scenario. The following figure shows two functionally equivalent code fragments. The purpose of the code is to create a list of all departments and all courses for each department in the school. In the code called Select N + 1, we display a list of all departments, and for each department a list of courses. This means that if there are 100 branches, we will need 1 + 100 calls to the database.
This problem can be solved in another way. One simple approach is shown in the code snippet on the right side. When using the Include method (in this case I will use a hard-coded string for ease of understanding) there will be only one call to the database, and this single call will immediately issue all departments and courses. In this case, when executing the second foreach loop, all Courses collections for each department will already be in memory.
Thus, you can increase productivity by hundreds of times by simply avoiding the Select N + 1 approach.
Consider a less obvious example. In the figure below, the whole difference between the two pieces of code lies in the data type of the destination list on the second line. Here you may wonder: does the type of destination data affect anything? If you study the operation of this technology, you will understand: the type of destination data actually determines the moment at which the query to the database is performed. And from this, in turn, depends on the moment of applying filters of each request.
In Code # 1, where an IEnumerable data type is expected, the query is executed immediately before Take Employee (10) is executed . This means that if there are 1000 employees, they will all be obtained from the database, after which 10 will be selected.
In Code # 2, the query is executed after Take Employee (10) is executed . In this case, only 10 records are retrieved from the database. The following article explains in detail the differences when using different types of collections.
▍SQL Server
In SQL, you need to learn a lot of features in order to achieve the highest database performance. Working with SQL Server is not easy: you need to understand how the data is used, which tables are most often requested, and which fields.
Nevertheless, to increase productivity, a number of general principles can be applied, for example:
- cluster or non-cluster indexes;
- The correct order of JOIN instructions
- Understanding when to use #temp tables and variable tables
- the use of views or indexed views;
- use of precompiled instructions.
For brevity, I will not give specific examples, but these principles can be used, analyzed and optimized.
▍Changing thinking
So, how do we developers need to change our mindset to avoid the No. 1 erroneous approach?
- Stop thinking: “I am an interface developer” or “I am an internal code developer.” You may be an engineer, you specialize in one particular area, but do not use this specialization to isolate yourself from studies in other areas.
- Stop thinking: "Let a specialist do it, because he will succeed faster." In the modern world, flexibility is in use, we must be multifunctional resources, we must study areas in which our knowledge is insufficient.
- Stop telling yourself: “I don’t understand this.” Of course, if it were simple, then everyone would have long become specialists. Feel free to spend time reading, consulting and studying. This is not easy, but sooner or later it will pay off.
- Stop saying, "I have no time." This objection I can understand. This often happens. But once a colleague at Intel said: "If you are really interested in something, then there will be time for this." I’m writing this article, for example, on Saturday at midnight!
Erroneous approach No. 2. Preference for certain technologies
I have been developing on .NET since version 1.0. I know in great detail all the features of web forms, as well as many .NET client libraries (I changed some of them myself). When I learned about the release of Model View Controller (MVC), I didn’t want to use it: “We don’t need it.”
As a matter of fact, this list can be continued rather long. I mean a list of things that I did not like at first and which I often and confidently use now. This is just one example of a situation where developers are inclined to favor some technical solutions and avoid others, which makes it difficult to achieve higher productivity.
I often hear discussions about either LINQ binding to objects in the Entity Framework, or SQL stored procedures when querying data. People are so used to using one or the other solution that they try to use them everywhere.
Another factor affecting the preferences of developers (the predominant choice of some technologies and the rejection of others) is a personal attitude to open source software. Developers often choose not the solution that is best suited to the current situation, but the one that is more consistent with their philosophy of life.
Sometimes external factors (for example, tight deadlines) force us to make suboptimal decisions. It takes time to choose the best technology: you need to read, try, compare and draw conclusions. When developing a new product or a new version of an existing product, it often happens that we are already late: “The deadline is yesterday.” Two obvious solutions to this situation are: requesting extra time or working overtime for self-education.
▍Changing thinking
How do we developers need to change our mindset to avoid the No. 2 erroneous approach.
- Stop saying: “This method always worked,” “We always did just that,” etc. You need to know and use other options, especially if these options are better in some way.
- Do not try to use the wrong solutions! It happens that developers stubbornly try to apply some specific technology that does not and cannot give the desired results. Developers spend a lot of time and effort, nevertheless trying to somehow finalize this technology, adjust it to the result, without considering other options. Such an ungrateful process can be called an “attempt to pull an owl onto the globe”: it is the desire to use any effort to adapt the existing inappropriate solution instead of focusing on the problem and finding another, more elegant and quick solution.
- "Not yet". Of course, we always do not have enough time to learn new things. This objection I can understand.
Mistake # 3: Lack of understanding of application infrastructure
So, we made a lot of efforts and created the best application. It's time to move on to its deployment. We have all tested. Everything works perfectly on our machines. All 10 testers were completely satisfied with the application itself and its performance.
Therefore, now certainly no problems can arise, everything is in perfect order?
By no means, everything may be completely out of order!
Have you asked yourself the following questions?
- Is the app suitable for work in a load balanced environment?
- The application will be hosted in the cloud, where there will be many instances of this application?
- How many other applications run on the machine for which my application is intended?
- What other programs are running on this server? SQL Server? Reporting Services? Any SharePoint * extensions?
- Where are the end users located? Are they distributed all over the world?
- How many users will my application have over the next five years?
I understand that not all of these issues relate directly to infrastructure, but everything has its time. As a rule, the final actual conditions in which our application will work differ from the conditions on the servers at an intermediate stage.
Let's look at a few possible factors that may affect the performance of our application. Suppose users are located in different countries of the world. Perhaps the application will work very quickly, without any complaints from users in the United States, but users from Malaysia will complain about the low speed.
There are many ways to solve such problems. For example, you can use data distribution networks (CDNs) and place static files on them. After that, loading pages for users located in different places will be faster. What I'm talking about is shown in the following figure.
Another situation is possible: suppose that applications run on servers that simultaneously run SQL Server and the web server. In this case, two server systems with intensive CPU load are running on the same physical server. How to solve this problem? If we are talking about a .NET application on an Internet Information Services (IIS) server, we can use processor matching. Processor matching is the binding of one process to one or more specific CPU cores of a computer.
For example, suppose a computer with four processors runs SQL Server and the IIS Web server.
If you let the operating system decide which CPU will be used for SQL Server and which for IIS, resources can be allocated differently. It is possible that each processor load will be assigned two processors.
And it is possible that all four processors will be allocated only to one load.
In this case, a deadlock may occur: IIS can serve too many queries and take all four processors, while some queries may require access to SQL, which in this case will be impossible. In practice, such a scenario is unlikely, but it perfectly illustrates my point.
Another possible situation: one process will not work all the time on the same CPU. Context switching will often occur. Frequent switching of the context will lead to a decrease in the performance of the server itself, and then of applications running on this server.
One way to solve this problem is to use “processor matching” for IIS and SQL. In this case, we decide how many processors are needed for SQL Server, and how many - for IIS. To do this, configure the settings in the "Processor Compliance" section in the CPU category in IIS and the "compliance mask" in the SQL Server database. Both of these cases are shown below.
| CPU | |
|---|---|
| Limit (percent) | 0 |
| Restriction action | No action |
| Limit period (minutes) | 5 |
| CPU matching allowed | False |
| CPU matching mask | 4294967295 |
| Processor Compliance Mask (64-bit) | 4294967295 |
You can continue this topic with other infrastructure features related to improving productivity, such as when using web farms.
▍Changing thinking
How do we developers need to change our mindset to avoid the No. 3 erroneous approach?
- Stop thinking: "This is not my job." We engineers must strive to broaden our horizons to provide customers with the best possible solution.
- "Not yet". Of course, we always have no time. This is the most common circumstance. Allocation of time is what distinguishes a successful, experienced, outstanding professional.
▍ Do not make excuses!
You have nothing to reproach yourself with. Not everything depends on you. Indeed, there is no time. All families, all hobbies, everyone needs to relax.
But it’s important to understand that good work is not only about writing good code. We all at some time used some or all of the erroneous approaches described.
Here's how to avoid them.
- Take time, if necessary - with a margin. When you are asked to evaluate the time needed to work on a project, be sure to allocate time for research and testing, for preparing conclusions and making decisions.
- Try to create a personal testing application at the same time. In this application, you can try different solutions before their implementation (or refusal to implement them) in the developed application. We all make mistakes sometimes.
- Find people who already own the right technology and try programming together. Work with a specialist who understands the infrastructure when he will deploy the application. This time will be well spent.
- Avoid stack overflows! Most of my problems have already been resolved. If you simply copy the answers without analyzing them, you will end up with an incomplete solution.
- Do not consider yourself a narrow specialist, do not limit your capabilities. Of course, if you manage to become an expert in any field, this is great, but you should be able to keep the conversation up to date even if the conversation concerns areas in which you are not yet an expert.
- Help others! This is perhaps one of the best ways to learn. If you help others solve their problems, then in the end you will save your own time, because you will already know what to do if you encounter similar problems.
see also
about the author
Alexander García is a computer engineer from the Intel Corporation in Costa Rica. He has 14 years of professional software development experience. Alexander's area of interest is very diverse - from software development practices and program security to productivity, data mining and related fields. Currently, Alexander has a master's degree in computer science.
For more information on compiler optimization, see our optimization notice.
For more information on compiler optimization, see our optimization notice.