Hadoop performance comparison on DAS and Isilon
- Transfer

I already wrote about how, using Isilon, you can create data lakes that can simultaneously serve multiple clusters with different versions of Hadoop. In that publication, I mentioned that in many cases, systems running on Isilon are faster than traditional clusters that use DAS storage. This was later confirmed by IDC by running various Hadoop benchmarks on the corresponding clusters. And this time I want to consider the reasons for the higher performance of Isilon clusters, as well as how it changes depending on the distribution of data and balancing within the clusters.
Test environment
- Cloudera Hadoop CDH5 distribution kit.
- A DAS cluster of 7 nodes (one master, six workers), with eight 300 Gb ten-thousand drives.
- An Isilon cluster of 4 x410 nodes, each equipped with 57 TB of disks and 3.2 TB of SSD connected via 10 GBE.
You can find other details in the report .
NFS access
First of all, IDC tested reading and writing with NFS access. As expected, Isilon showed MUCH better results even with four nodes.
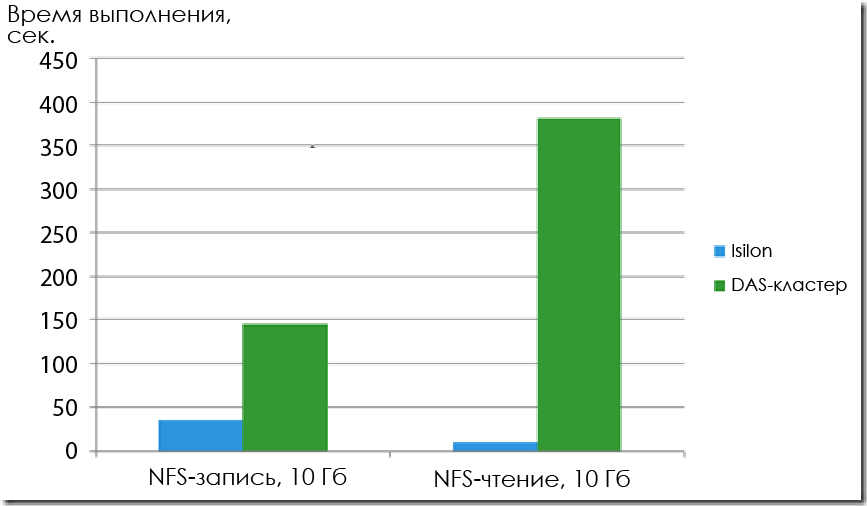
Duration of copying a file of 10 GB (the length of the block is not specified, but most likely it is 1 MB or more).
According to the record, Isilon was 4.2 times faster. This is especially important if it is important if you want to receive data through NFS. And in terms of read speed, productivity is 37 times higher.
Hadoop Workload
During testing using standard Hadoop benchmarks, three types of workload were compared:
- Sequential recording using TeraGen
- Sequential Write / Read with TeraSort
- Sequential reading with TeraValidate

Runtime with three different types of load: TeraGen, TeraSort and TeraValidate.
When recording, Isilon's performance was 2.6 times higher, and on the other two types - 1.5 times higher. Specific results are presented in the table:
| Isilon | Hadoop das | |
|---|---|---|
| Teragen | 1681 Mb / s | 605 Mb / s |
| TeraSort | 642 Mb / s | 416 Mb / s |
| Teravalidate | 2832 Mb / s | 1828 Mb / s |
Performance of Isilon and DAS clusters with the same configuration of computing nodes (rounded).
The data speaks for itself. Let us now see how OneFS managed to achieve such a performance advantage over the DAS cluster.
Reading files on Isilon
Although I / O operations are distributed across all nodes in a DAS cluster, each individual 64-megabyte block is served by only one node. At the same time, in Isilon, the workload is divided between nodes in smaller portions. The read operation consists of the following steps:
- The compute node requests HDFS metadata from the Name Node service, which runs on all Isilon nodes (without SPoF).
- The service returns the IP addresses and block numbers of each of the three nodes in the same rack as the computing node. This increases the efficiency of the locality of the rack.
- A computing node requests reading a 64-megabyte HDFS block from the Data Node service, which runs on the first node in the received list.
- The requested node, via the internal Infiniband network, collects all 128-kilobyte Isilon blocks that make up the required 64-megabyte HDFS block. If these blocks are no longer in the second level cache, then they are read from the disks. This is a fundamental difference from the DAS cluster, in which the entire 64 MB block is read from a single node. In other words, in the Isilon cluster, the I / O operation is serviced by a much larger number of disks and processors than in the DAS cluster.
- The requested node returns a full HDFS block to the computing node.
Writing files to Isilon
When the client wants to write the file to the cluster, then the node to which the client is connected is engaged in the reception and processing of the file.
- The node creates a file recording plan, including FEC calculation (in terms of volume, this is much more economical compared to a DAS cluster in which three copies of each block are usually created to ensure data safety).
- The data blocks assigned to this node are recorded in its NVRAM. The presence of NVRAM cards is one of Isilon's advantages; they cannot be used in DAS clusters.
- Data blocks assigned to other nodes are first transferred via the Infiniband network to the second level caches of these nodes, and from there to NVRAM.
- As soon as the corresponding data and FEC blocks are loaded into the NVRAM of all nodes, the client receives a confirmation of the successful recording. This means that you can not expect to write data to disks while all I / O operations are buffered in NVRAM.
- Data blocks are stored in second level caches of each node in case read requests are received.
- Then the data is written to discs.
The myth of the importance of disk locality for Hadoop performance
Sometimes we encounter objections from admins claiming that disk locality is important for Hadoop's high performance. But you need to remember that initially Hadoop was designed to work in slow networks with a star topology, which are characterized by a bandwidth of 1 Gbit / s. In such conditions, it remains only to strive to carry out all the I / O operations within a specific server (disk locality).
A number of facts suggest that disk locality is not related to Hadoop performance:
I. Fast networks have become the standard.
- Today, a single non-blocking 10-gigabit switch port (full duplex up to 2500 Mb / s) has a higher throughput than a typical 12-disk disk subsystem (360 - Mb / s).
- There is no longer any need to maintain data locality to ensure a satisfactory level of I / O.
- Isilon provides rack-mount locality rather than disk locality, which reduces Ethernet traffic between racks.
This illustration shows the route of I / O operations. Obviously, the bottleneck is the drives, not the network (if it is a 10 GBE network).

The route of the I / O operation in the DAS architecture. Even if you double the number of disks, they will still remain a bottleneck. So the locality of drives in most cases does not affect performance.
II. Disk locality is lost in the following typical situations:
- In a DAS cluster with block replication, all nodes perform the maximum number of tasks. This is extremely characteristic of highly loaded clusters!
- Incoming files are compressed using non-splittable codecs like gzip.
- “ An analysis of Hadoop tasks on Facebook proves the difficulty of achieving disk locality: only 34% of the tasks are executed on the same node where the input data is stored.”
- Disk locality provides a very low latency for I / O, but it has very little value when performing batch jobs like MapReduce.
III. Data Replication for Performance
- In heavily loaded traditional clusters, a high degree of replication can be useful when working with files that are often used in multiple simultaneous tasks. This is required to ensure data locality and high parallel reading speed.
- Isilon does not require a high degree of replication because:
- No data locality needed.
- Read operations are distributed across many nodes with a globally coherent cache, which provides very high parallel read speeds.
Other Technologies Affecting Isilon's Performance
OneFS is a very mature product that has been improved for over ten years in terms of high performance and low latency with multi-protocol access. You can find a lot of information about this on the net. I will mention only key points:
- All write operations are buffered using backup NVRAM, which provides very high performance.
- OneFS uses a first-level cache, a globally coherent second-level cache, and third-level caches on SSDs to speed reading.
- You can configure access patterns for the entire cluster, for the pool, or even at the folder level. This allows you to optimize and balance the pre-fetching procedure. Templates can be random, parallel or streaming.
- Work with metadata is accelerated using the third-level cache, or is configured separately. OneFS stores all metadata on the SSD.
Finally
Isilon is a horizontally-scaled NAS with a distributed file system designed for heavy workloads like Hadoop. HDFS is implemented as a protocol and Name Node and Data Node services, access to which is provided on all nodes. Performance testing by IDC showed a 2.5-fold advantage of the Isilon cluster over the DAS cluster. Due to advances in network technology, disk locality does not affect the operation of Hadoop on an Isilon system. In addition to performance, Isilon also has a number of other advantages, such as more efficient use of disk space and various features specific to corporate storages. Moreover, compute nodes and storage nodes can be scaled independently of each other.