Analysis of the incident on October 21 at GitHub
- Transfer
Fatal 43 seconds that caused the daily degradation of the service
Last week, an incident occurred in GitHub , which led to the degradation of the service for 24 hours and 11 minutes. The incident did not affect the entire platform, but only a few internal systems, which led to the display of outdated and inconsistent information. Ultimately, user data was not lost, but manual reconciliation of a few seconds of writing to the database is still performed. Throughout most of the crash, GitHub also could not handle web scams, create and publish GitHub Pages sites.
All of us at GitHub would like to sincerely apologize for the problems that all of you have had. We are aware of your trust in GitHub and are proud to build resilient systems that support the high availability of our platform. With this incident, we let you down and deeply regret. Although we cannot undo the problems due to the degradation of the GitHub platform for a long time, we can explain the causes of the incident, talk about lessons learned and measures that will allow the company to better protect against such failures in the future.
Most custom GitHub services run in our own data centers . The data center topology is designed to provide a reliable and extensible boundary network in front of several regional data centers that provide computing systems and data storage systems. Despite the levels of redundancy embedded in the physical and logical components of the project, it is still possible that sites will not be able to interact with each other for some time.
On October 21, at 22:52 UTC, scheduled repairs to replace faulty 100G optical equipment led to a loss of communication between the network hub on the East Coast (US East Coast) and the main data center on the East Coast. The connection between them was restored after 43 seconds, but this short shutdown caused a chain of events that led to 24 hours and 11 minutes of service degradation.
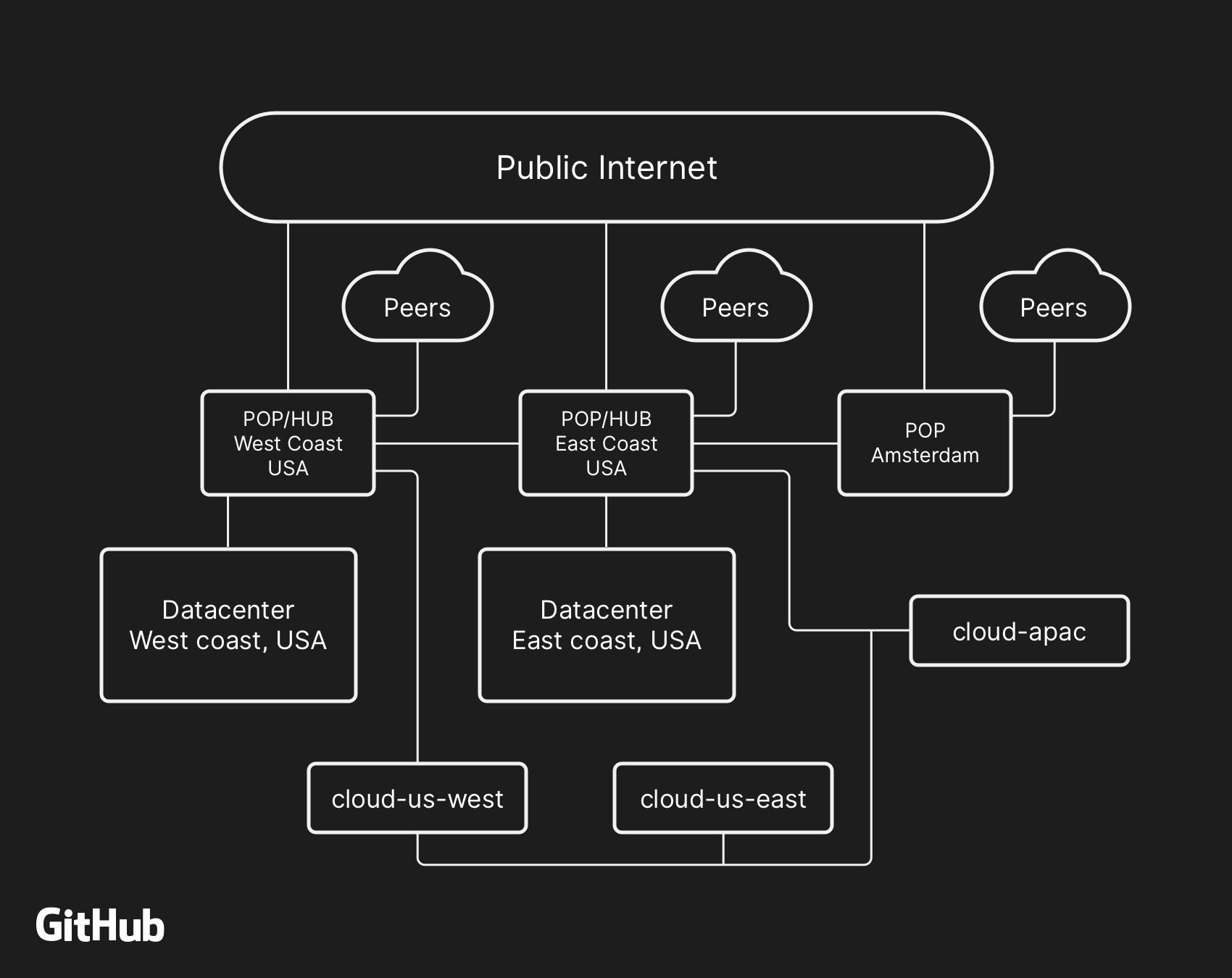
High-level GitHub network architecture, including two physical data centers, 3 POPs and cloud storage in several regions connected via peering
In the past, we discussed how to use MySQL to store GitHub metadata , as well as our approach to ensuring high availability for MySQL. GitHub manages several MySQL clusters ranging in size from hundreds of gigabytes to almost five terabytes. Each cluster has dozens of read replicas for storing metadata other than Git, so our applications provide pull-requests, issues, authentication, background processing, and additional functions outside of the Git object store. Different data in different parts of the application is stored in different clusters using functional segmentation.
To improve performance on a large scale, applications send records to the appropriate primary server for each cluster, but in most cases delegate read requests to a subset of replica servers. We use Orchestratorfor managing MySQL cluster topologies and automatic failover. During this process, the Orchestrator considers a number of variables and is built on top of Raft for consistency. Orchestrator can potentially implement topologies that applications do not support, so you need to monitor your Orchestrator configuration for application-level expectations.
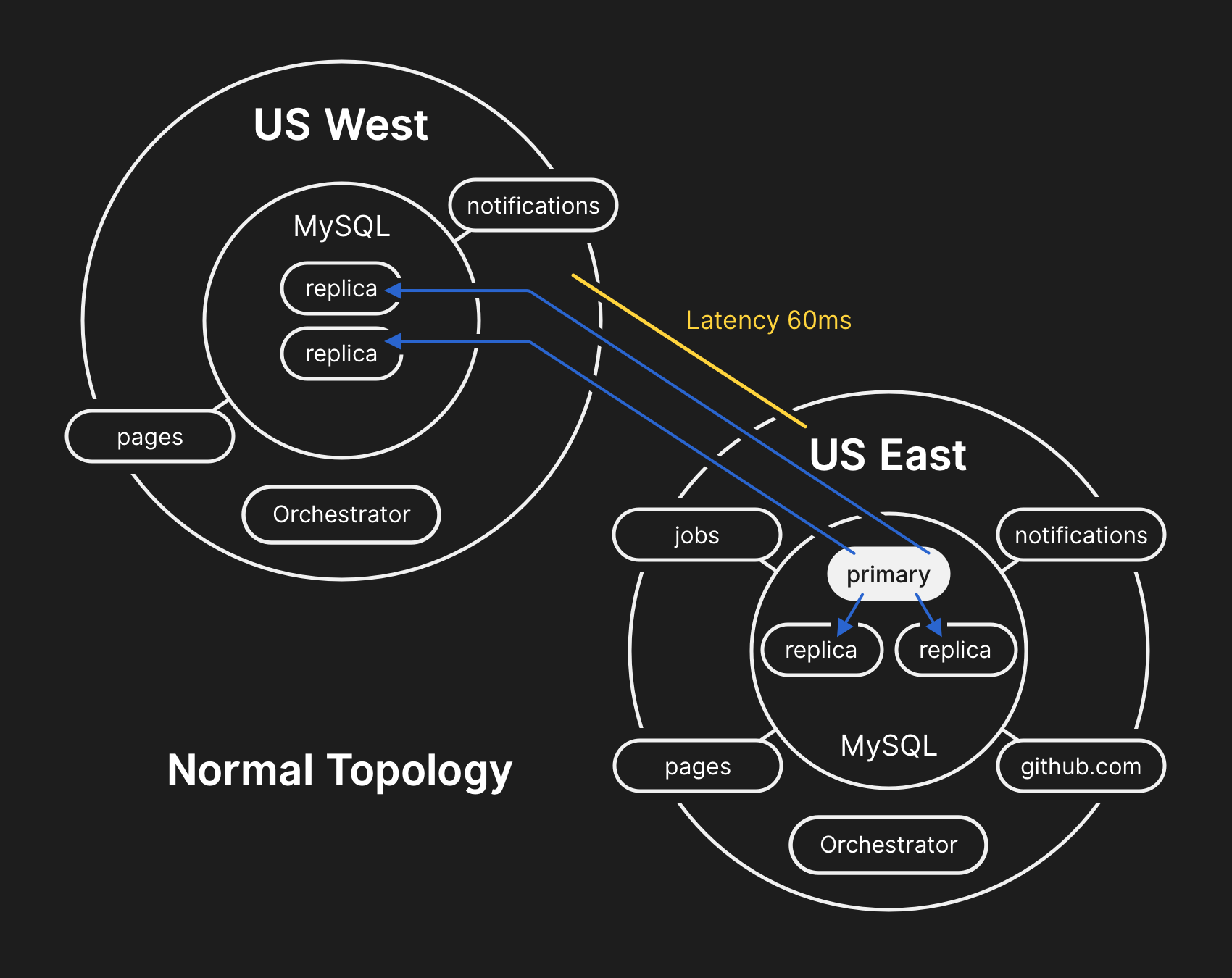
In a conventional topology, all applications perform reading locally with low latency.
During the aforementioned Orchestrator network split, the main data center began the process of de-selecting a guide according to the consensus algorithm Raft. The West Coast data center and Orchestrator public cloud nodes on the East Coast were able to reach a consensus - and they began working off the failure of clusters to send records to the western data center. Orchestrator began to create a database cluster topology in the West. After the connection was restored, the applications immediately sent traffic by writing to the new main servers in US West.
On the database servers in the eastern data center there were records for a short period that were not replicated to the western data center. Since the database clusters in both data centers now contained records that were not in another data center, we could not safely return the primary server back to the eastern data center.
Our internal monitoring systems have begun to generate alerts indicating numerous system failures. At this time, several engineers responded and worked on sorting incoming notifications. By 23:02, the engineers of the first response group determined that the topologies for numerous database clusters are in an unexpected state. When requesting the API Orchestrator, the database replication topology was displayed, containing only servers from the western data center.
At this point, the response team decided to manually block the internal deployment tools in order to prevent additional changes. At 23:09 the group established a yellow site health status . This action automatically assigned the situation the status of an active incident and sent a warning to the incident coordinator. At 23:11 the coordinator joined the work and after two minutes decided to change the status to red .
At that time, it was clear that the problem affected several DB clusters. To work attracted additional developers from the engineering database. They began to investigate the current state, to determine what actions need to be taken to manually configure the US East Coast database as the primary one for each cluster and rebuild the replication topology. This was not easy, because by this time the western database cluster had been taking entries from the application level for almost 40 minutes. In addition, in the eastern cluster, there were several seconds of records that were not replicated to the west and did not allow the new records to replicate back to the east.
Protecting the confidentiality and integrity of user data is GitHub's highest priority. Therefore, we decided that more than 30 minutes of data recorded in the western data center, leave us only one solution to the situation in order to save this data: transfer forward (failing-forward). However, applications in the east, which depend on writing information to the Western MySQL cluster, are currently unable to cope with the additional delay due to the transfer of most of their database calls back and forth. This decision will lead to the fact that our service will become unsuitable for many users. We believe that the long-term degradation of service quality was worth it to ensure the consistency of our users' data.
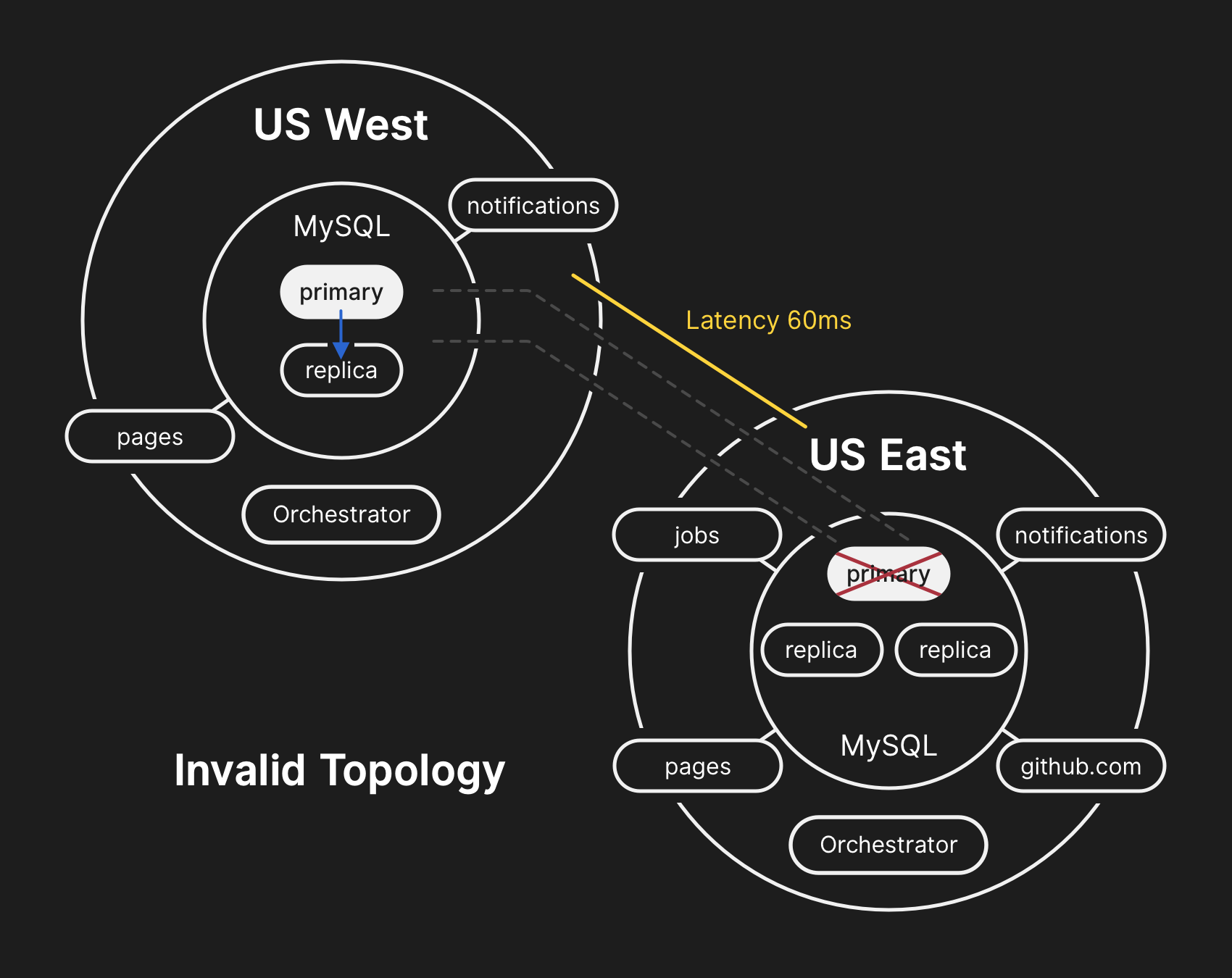
In the wrong topology, replication from West to East is impaired, and applications cannot read data from current replicas, because they depend on low latency to maintain transaction performance
Queries about the state of database clusters showed that it is necessary to stop the execution of tasks that write push-type metadata. We made a choice and deliberately went to a partial degradation of the service, pausing web builds and assembling GitHub Pages, so as not to jeopardize the data that we have already received from users. In other words, the strategy was to prioritize: data integrity instead of website usability and quick recovery.
Engineers from the response team began to develop a plan for eliminating data inconsistencies and launched a failover procedure for MySQL. The plan was to restore the files from the backup, synchronize the replicas at both sites, return to the stable service topology, and then resume the processing of jobs in the queue. We updated the status to let users know that we are going to perform managed failover on the internal storage system.
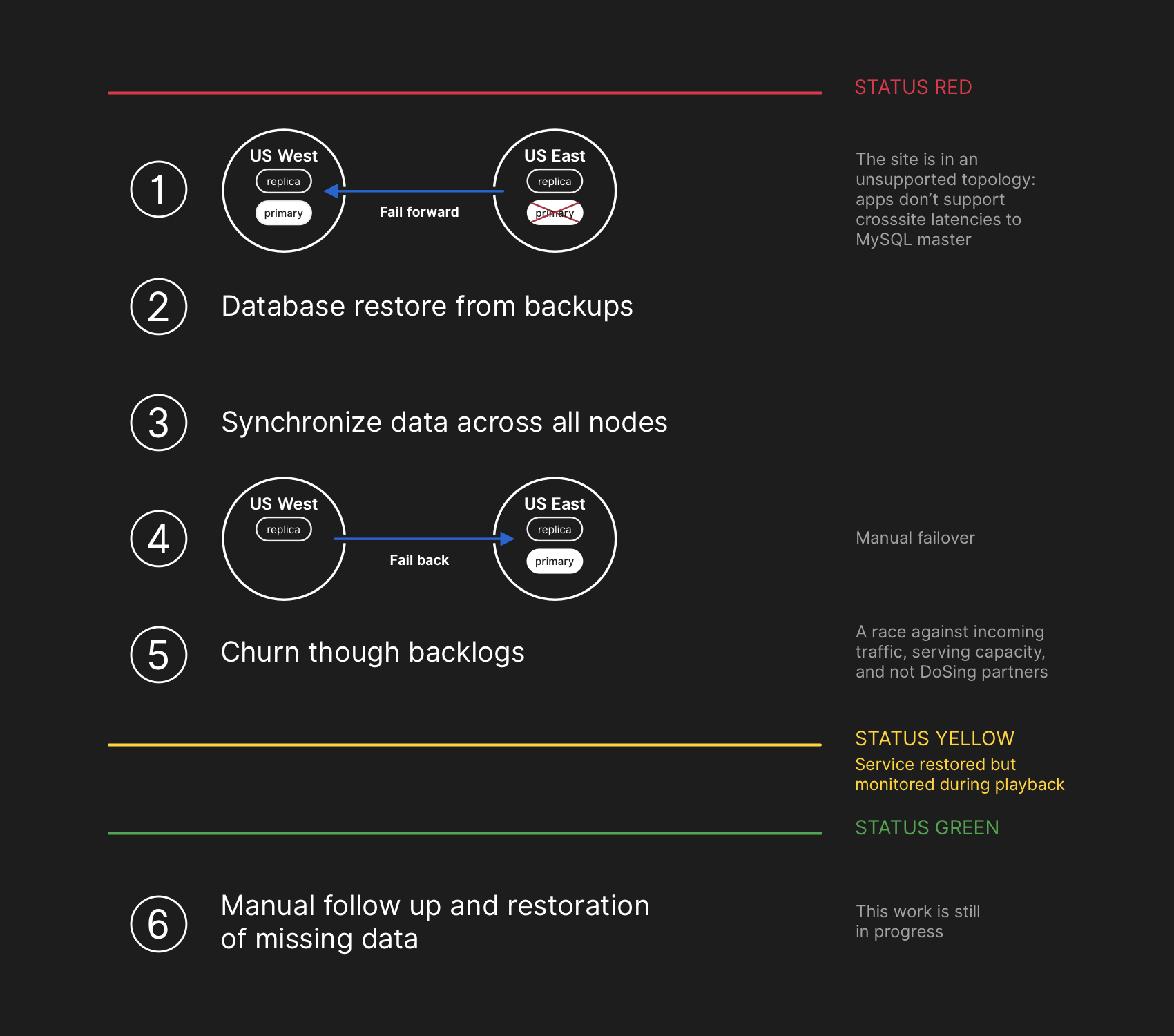
The recovery plan assumed the transfer forward, recovery from backups, synchronization, roll back and working off the delay, before returning to the green status
Although MySQL backups are made every four hours and stored for many years, but they lie in a remote cloud storage blob objects. Recovery of several terabytes from backup took several hours. For a long time there was a transfer of data from the remote backup service. Most of the time was spent on the process of unpacking, checking the checksum, preparing and uploading large backup files to freshly prepared MySQL servers. This procedure is tested daily, so everyone was well aware of how long the recovery would take. However, before this incident, we never had to completely rebuild the entire cluster from a backup. Other strategies have always worked, such as deferred replicas.
By this time, the backup process was initiated for all affected MySQL clusters, and engineers were tracking progress. At the same time, several groups of engineers studied ways to speed up the transfer and recovery without further degradation of the site or the risk of data damage.
Several clusters in the eastern data center completed the restoration from backups and began to replicate new data with the West Coast. This slowed down the loading of pages that performed the write operation across the entire country, but reading the pages from these clusters of the database returned actual results if the read request was sent to the just replica. Other larger database clusters continued to recover.
Our teams have identified a recovery method directly from the West Coast to overcome bandwidth limitations caused by booting from external storage. It has become almost 100% clear that the recovery will complete successfully, and the time to create a healthy replication topology depends on how long the catch-up replication takes. This estimate was linearly interpolated based on the available replication telemetry, and the status page was updated to set the wait at two hours as the estimated recovery time.
GitHub posted an informational blog post . We ourselves use GitHub Pages, and all the assemblies paused a few hours ago, so the publication required extra effort. Sorry for the delay. We intended to send this message much earlier and in the future we will ensure the publication of updates in the conditions of such restrictions.
All primary databases are again transferred to the East. This led to the site becoming much more responsive, since the records were now sent to the database server located in the same physical data center as our application layer. Although this significantly increased performance, there are still dozens of database reading replicas that lagged behind the main copy for several hours. These deferred replicas caused users to see inconsistent data when interacting with our services. We distribute the read load across a large pool of read replicas, and every request to our services has a good chance of getting into the read replica with a delay of several hours.
In fact, the time to catch a lagging replica is reduced exponentially rather than linearly. When users in the US and Europe woke up, the recovery process took longer than expected due to the increased load on the records in the database clusters.
We were approaching the peak load on GitHub.com. The response team discussed how to proceed. It was clear that the lag of replication to a consistent state is increasing, not decreasing. Earlier, we started preparing additional MySQL read replicas in the East Coast public cloud. As soon as they became available, it became easier to distribute the flow of read requests among several servers. Reducing the average load on replica reads accelerated replication.
After synchronization of the replicas, we returned to the original topology, eliminating the problems of delay and availability. As part of a conscious decision to prioritize data integrity over quickly correcting the situation, we retained the red status of the site when we began to process the accumulated data.
During the recovery phase, it was necessary to balance the increased load associated with the lag, potentially overloading our ecosystem partners with notifications and returning to one hundred percent efficiency as soon as possible. More than five million hook events and 80 thousand requests for building web pages remained in the queue.
When we re-enabled the processing of this data, we processed about 200,000 useful tasks with webheads, which exceeded the internal TTL and were discarded. Upon learning of this, we stopped processing and launched an increase in TTL.
To avoid further reducing the reliability of our status updates, we left the degradation status until we finish processing the accumulated amount of data and make sure that the services have clearly returned to the normal level of performance.
All incomplete webhuk events and Pages assemblies are processed, and the integrity and proper operation of all systems is confirmed. Site status updated to green .
During recovery, we fixed MySQL binary logs with records in the main data center that were not replicated to the west. The total number of such records is relatively small. For example, in one of the busiest clusters, there are only 954 entries in those seconds. We are currently analyzing these logs and determining which records can be automatically reconciled and which will require user assistance. Several teams participate in this work, and our analysis has already determined the category of records that the user then repeated - and they were successfully preserved. As stated in this analysis, our main goal is to preserve the integrity and accuracy of the data you store on GitHub.
Trying to convey important information to you during the incident, we made several public assessments of the recovery time based on the processing speed of the accumulated data. In retrospect, our estimates did not take into account all variables. We apologize for the confusion and will strive to provide more accurate information in the future.
In the course of this analysis, a number of technical measures were identified. The analysis continues; the list may be updated.
This incident greatly influenced our idea of the reliability of the site. We have learned that tightening operational control or improving response time are insufficient guarantees of reliability in such a complex system of services as ours. To support these efforts, we will also begin the systematic practice of verifying failure scenarios before they occur in reality. This work includes intentional troubleshooting and the use of chaos engineering tools.
We know how you rely on GitHub in your projects and business. We more than anyone care about the availability of our service and the safety of your data. The analysis of this incident will continue to find an opportunity to serve you better and to justify your trust.
Last week, an incident occurred in GitHub , which led to the degradation of the service for 24 hours and 11 minutes. The incident did not affect the entire platform, but only a few internal systems, which led to the display of outdated and inconsistent information. Ultimately, user data was not lost, but manual reconciliation of a few seconds of writing to the database is still performed. Throughout most of the crash, GitHub also could not handle web scams, create and publish GitHub Pages sites.
All of us at GitHub would like to sincerely apologize for the problems that all of you have had. We are aware of your trust in GitHub and are proud to build resilient systems that support the high availability of our platform. With this incident, we let you down and deeply regret. Although we cannot undo the problems due to the degradation of the GitHub platform for a long time, we can explain the causes of the incident, talk about lessons learned and measures that will allow the company to better protect against such failures in the future.
Prehistory
Most custom GitHub services run in our own data centers . The data center topology is designed to provide a reliable and extensible boundary network in front of several regional data centers that provide computing systems and data storage systems. Despite the levels of redundancy embedded in the physical and logical components of the project, it is still possible that sites will not be able to interact with each other for some time.
On October 21, at 22:52 UTC, scheduled repairs to replace faulty 100G optical equipment led to a loss of communication between the network hub on the East Coast (US East Coast) and the main data center on the East Coast. The connection between them was restored after 43 seconds, but this short shutdown caused a chain of events that led to 24 hours and 11 minutes of service degradation.
High-level GitHub network architecture, including two physical data centers, 3 POPs and cloud storage in several regions connected via peering
In the past, we discussed how to use MySQL to store GitHub metadata , as well as our approach to ensuring high availability for MySQL. GitHub manages several MySQL clusters ranging in size from hundreds of gigabytes to almost five terabytes. Each cluster has dozens of read replicas for storing metadata other than Git, so our applications provide pull-requests, issues, authentication, background processing, and additional functions outside of the Git object store. Different data in different parts of the application is stored in different clusters using functional segmentation.
To improve performance on a large scale, applications send records to the appropriate primary server for each cluster, but in most cases delegate read requests to a subset of replica servers. We use Orchestratorfor managing MySQL cluster topologies and automatic failover. During this process, the Orchestrator considers a number of variables and is built on top of Raft for consistency. Orchestrator can potentially implement topologies that applications do not support, so you need to monitor your Orchestrator configuration for application-level expectations.
In a conventional topology, all applications perform reading locally with low latency.
Chronicle of the incident
10/21/2018 22:52 UTC
During the aforementioned Orchestrator network split, the main data center began the process of de-selecting a guide according to the consensus algorithm Raft. The West Coast data center and Orchestrator public cloud nodes on the East Coast were able to reach a consensus - and they began working off the failure of clusters to send records to the western data center. Orchestrator began to create a database cluster topology in the West. After the connection was restored, the applications immediately sent traffic by writing to the new main servers in US West.
On the database servers in the eastern data center there were records for a short period that were not replicated to the western data center. Since the database clusters in both data centers now contained records that were not in another data center, we could not safely return the primary server back to the eastern data center.
10.21.2018, 22:54 UTC
Our internal monitoring systems have begun to generate alerts indicating numerous system failures. At this time, several engineers responded and worked on sorting incoming notifications. By 23:02, the engineers of the first response group determined that the topologies for numerous database clusters are in an unexpected state. When requesting the API Orchestrator, the database replication topology was displayed, containing only servers from the western data center.
10.21.2018 23:07 UTC
At this point, the response team decided to manually block the internal deployment tools in order to prevent additional changes. At 23:09 the group established a yellow site health status . This action automatically assigned the situation the status of an active incident and sent a warning to the incident coordinator. At 23:11 the coordinator joined the work and after two minutes decided to change the status to red .
10/21/2018 23:13 UTC
At that time, it was clear that the problem affected several DB clusters. To work attracted additional developers from the engineering database. They began to investigate the current state, to determine what actions need to be taken to manually configure the US East Coast database as the primary one for each cluster and rebuild the replication topology. This was not easy, because by this time the western database cluster had been taking entries from the application level for almost 40 minutes. In addition, in the eastern cluster, there were several seconds of records that were not replicated to the west and did not allow the new records to replicate back to the east.
Protecting the confidentiality and integrity of user data is GitHub's highest priority. Therefore, we decided that more than 30 minutes of data recorded in the western data center, leave us only one solution to the situation in order to save this data: transfer forward (failing-forward). However, applications in the east, which depend on writing information to the Western MySQL cluster, are currently unable to cope with the additional delay due to the transfer of most of their database calls back and forth. This decision will lead to the fact that our service will become unsuitable for many users. We believe that the long-term degradation of service quality was worth it to ensure the consistency of our users' data.
In the wrong topology, replication from West to East is impaired, and applications cannot read data from current replicas, because they depend on low latency to maintain transaction performance
10/21/2018 23:19 UTC
Queries about the state of database clusters showed that it is necessary to stop the execution of tasks that write push-type metadata. We made a choice and deliberately went to a partial degradation of the service, pausing web builds and assembling GitHub Pages, so as not to jeopardize the data that we have already received from users. In other words, the strategy was to prioritize: data integrity instead of website usability and quick recovery.
10.22.2018, 00:05 UTC
Engineers from the response team began to develop a plan for eliminating data inconsistencies and launched a failover procedure for MySQL. The plan was to restore the files from the backup, synchronize the replicas at both sites, return to the stable service topology, and then resume the processing of jobs in the queue. We updated the status to let users know that we are going to perform managed failover on the internal storage system.
The recovery plan assumed the transfer forward, recovery from backups, synchronization, roll back and working off the delay, before returning to the green status
Although MySQL backups are made every four hours and stored for many years, but they lie in a remote cloud storage blob objects. Recovery of several terabytes from backup took several hours. For a long time there was a transfer of data from the remote backup service. Most of the time was spent on the process of unpacking, checking the checksum, preparing and uploading large backup files to freshly prepared MySQL servers. This procedure is tested daily, so everyone was well aware of how long the recovery would take. However, before this incident, we never had to completely rebuild the entire cluster from a backup. Other strategies have always worked, such as deferred replicas.
10.22.2018, 00:41 UTC
By this time, the backup process was initiated for all affected MySQL clusters, and engineers were tracking progress. At the same time, several groups of engineers studied ways to speed up the transfer and recovery without further degradation of the site or the risk of data damage.
10.22.2018 06:51 UTC
Several clusters in the eastern data center completed the restoration from backups and began to replicate new data with the West Coast. This slowed down the loading of pages that performed the write operation across the entire country, but reading the pages from these clusters of the database returned actual results if the read request was sent to the just replica. Other larger database clusters continued to recover.
Our teams have identified a recovery method directly from the West Coast to overcome bandwidth limitations caused by booting from external storage. It has become almost 100% clear that the recovery will complete successfully, and the time to create a healthy replication topology depends on how long the catch-up replication takes. This estimate was linearly interpolated based on the available replication telemetry, and the status page was updated to set the wait at two hours as the estimated recovery time.
10.22.2018 07:46 UTC
GitHub posted an informational blog post . We ourselves use GitHub Pages, and all the assemblies paused a few hours ago, so the publication required extra effort. Sorry for the delay. We intended to send this message much earlier and in the future we will ensure the publication of updates in the conditions of such restrictions.
10.22.2018, 11:12 UTC
All primary databases are again transferred to the East. This led to the site becoming much more responsive, since the records were now sent to the database server located in the same physical data center as our application layer. Although this significantly increased performance, there are still dozens of database reading replicas that lagged behind the main copy for several hours. These deferred replicas caused users to see inconsistent data when interacting with our services. We distribute the read load across a large pool of read replicas, and every request to our services has a good chance of getting into the read replica with a delay of several hours.
In fact, the time to catch a lagging replica is reduced exponentially rather than linearly. When users in the US and Europe woke up, the recovery process took longer than expected due to the increased load on the records in the database clusters.
10.22.2018 13:15 UTC
We were approaching the peak load on GitHub.com. The response team discussed how to proceed. It was clear that the lag of replication to a consistent state is increasing, not decreasing. Earlier, we started preparing additional MySQL read replicas in the East Coast public cloud. As soon as they became available, it became easier to distribute the flow of read requests among several servers. Reducing the average load on replica reads accelerated replication.
10.22.2018, 16:24 UTC
After synchronization of the replicas, we returned to the original topology, eliminating the problems of delay and availability. As part of a conscious decision to prioritize data integrity over quickly correcting the situation, we retained the red status of the site when we began to process the accumulated data.
10/22/2018 4:45 pm UTC
During the recovery phase, it was necessary to balance the increased load associated with the lag, potentially overloading our ecosystem partners with notifications and returning to one hundred percent efficiency as soon as possible. More than five million hook events and 80 thousand requests for building web pages remained in the queue.
When we re-enabled the processing of this data, we processed about 200,000 useful tasks with webheads, which exceeded the internal TTL and were discarded. Upon learning of this, we stopped processing and launched an increase in TTL.
To avoid further reducing the reliability of our status updates, we left the degradation status until we finish processing the accumulated amount of data and make sure that the services have clearly returned to the normal level of performance.
10.22.2018, 23:03 UTC
All incomplete webhuk events and Pages assemblies are processed, and the integrity and proper operation of all systems is confirmed. Site status updated to green .
Next steps
Correction of data inconsistencies
During recovery, we fixed MySQL binary logs with records in the main data center that were not replicated to the west. The total number of such records is relatively small. For example, in one of the busiest clusters, there are only 954 entries in those seconds. We are currently analyzing these logs and determining which records can be automatically reconciled and which will require user assistance. Several teams participate in this work, and our analysis has already determined the category of records that the user then repeated - and they were successfully preserved. As stated in this analysis, our main goal is to preserve the integrity and accuracy of the data you store on GitHub.
Communication
Trying to convey important information to you during the incident, we made several public assessments of the recovery time based on the processing speed of the accumulated data. In retrospect, our estimates did not take into account all variables. We apologize for the confusion and will strive to provide more accurate information in the future.
Technical measures
In the course of this analysis, a number of technical measures were identified. The analysis continues; the list may be updated.
- Adjust Orchestrator configuration to prevent primary databases from moving out of the region. Orchestrator worked according to the settings, although the application level did not support this topology change. The choice of a leader within a region is usually safe, but the sudden appearance of a delay due to the transfer of traffic across the continent was the main cause of this incident. This is an emergent, new behavior of the system, because before we did not encounter the internal section of the network of this scale.
- We have accelerated the migration to the new status reporting system, which will provide a more suitable platform for discussing active incidents with clearer and clearer wording. Although many parts of GitHub were available throughout the entire incident, we could only select green, yellow, and red statuses for the entire site. We admit that it does not give an exact picture: what works and what does not. The new system will display the various components of the platform so that you know the status of each service.
- A few weeks before this incident, we launched a corporate-wide engineering initiative to support the maintenance of GitHub traffic from several data centers according to the active / active / active architecture. The objective of this project is to support N + 1 redundancy at the data center level in order to withstand the failure of a single data center without external intervention. This is a lot of work and will take some time, but we believe that several well-connected data centers in different regions will provide a good compromise. The last incident pushed this initiative even more.
- We will take a more active position in checking our assumptions. GitHub is growing rapidly and has accumulated a considerable amount of complexity over the past decade. It is becoming increasingly difficult to capture and convey to the new generation of employees the historical context of compromises and decisions taken.
Organizational measures
This incident greatly influenced our idea of the reliability of the site. We have learned that tightening operational control or improving response time are insufficient guarantees of reliability in such a complex system of services as ours. To support these efforts, we will also begin the systematic practice of verifying failure scenarios before they occur in reality. This work includes intentional troubleshooting and the use of chaos engineering tools.
Conclusion
We know how you rely on GitHub in your projects and business. We more than anyone care about the availability of our service and the safety of your data. The analysis of this incident will continue to find an opportunity to serve you better and to justify your trust.