Garage Deep Learning - Two Networks

This is the second article in a series about the definition of a smile by facial expression.
Deep learning in the garage - Brotherhood of data
Deep learning in the garage - Two networks
Deep learning in the garage - Returning smiles
Calibration
So, with the classifier, sorted out, but you probably already noticed that sky-high 99% somehow do not look very impressive during the combat test for detection. So I noticed. It is additionally seen that in the last two examples there is a very small step in the movement of windows, this will not work in life. In the present, real launch, the step is expected to look more like a picture for the first network, and there you can clearly see the unpleasant fact: no matter how well the network looks for faces, the windows will be poorly aligned to faces. And reducing the pitch is clearly not a suitable solution to this problem for production.
Well, I thought. We found the windows, but we did not find the exact windows, but as if shifted. How would you move them back so that your face is in the center? Naturally, automatically. Well, and since I got busy with networks, I decided to "restore" windows as well with the network.
My first thought was to predict three numbers by the network: how many pixels need to be shifted by x and y and by what constant the window is enlarged (reduced). It turns out, regression. But then I immediately felt that something was wrong, as many as three regressions needed to be done! Yes, two of them are discrete. Moreover, they are limited by the step the window moves in the original image, because there is no point in moving the window far: there was another window! The last nail in the coffin of this idea was a couple of independent articles, which argued that regression is much worse than classification is solved by modern network methods, and that it is much less stable.
So, it was decided to reduce the regression problem to the classification problem, which turned out to be more than possible, given that I need to pull the window very little. For these purposes, I assembled a dataset in which I took selected individuals from the original dataset, shifted them to nine (including none) different sides and increased / decreased five different coefficients (including one). Total, received 45 classes.
The astute reader should be horrified here: the classes turned out to be very strongly connected with each other! The result of such a classification may have little to do with reality.
To calm internal mathematics, I made three points:
- In essence, network training is simply the search for a minimum loss function. It is not necessary to interpret it as a classification.
- We do not classify anything, in fact, we emulate regression! Together with the awareness of the first point, this allows us not to focus on formal correctness.
- That damn works!
Since we do not classify but emulate regression, we cannot just take the best class and assume that it is correct. Therefore, I take the class distribution that the network gives for each window, delete the very unlikely ones (<2.2%, which is 1/45, which means that the probability is less than random), and for the remaining classes I summarize their shifts with the probabilities as coefficients and I get a kind of regression in such a small non-basis (there would be a basis if the classes were independent, but well, not a basis at all :) .
Total, I introduced a second calibration network into the system. She gave out the distribution by classes, on the basis of which I calibrated the windows, hoping that the faces would be aligned in the center of the windows.
Let's try to train this network:
def build_net12_cal(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 12, 12), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=16, filter_size=(3, 3), nolin=relu)
network = max_pool(network)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=128, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=45, nolin=linear)
return networkAnd here is an algorithm for calculating the displacement:
def get_calibration():
classes = np.array([(dx1, dy1, ds1), (dx2, d2, ds2), ...], dtype=theano.config.floatX) # ds -- это изменение scale
min_cal_prob = 1.0 / len(classes)
cals = calibration_net(*frames) > min_cal_prob # вернет вероятности калибрационных классов для каждого окна, обрезанные по нижнему порогу
(dx, dy, ds) = (classes * cals.T).sum(axis=0) / cals.sum(axis=1) # первая сумма -- по всем окнам, вторая сумма -- по классам для каждого окна. Она была бы всегда равна единице, если бы не было отсечения строкой выше
return dx, dy, dsAnd it works!

To the left are the initial windows from the detection network (small), to the right they are, but calibrated. It can be seen that the windows begin to group in explicit clusters. Additionally, this helps to filter duplicates more efficiently, since windows belonging to the same face intersect with a larger area and it becomes easier to understand that one of them needs to be filtered. It also allows you to reduce the number of windows in production by increasing the step of sliding the window on the image.
At the same time, here are the results of training of small calibration:
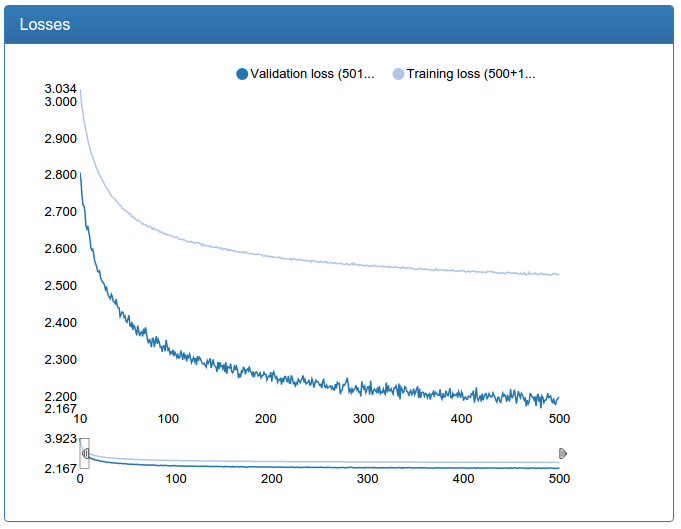

and large calibration:
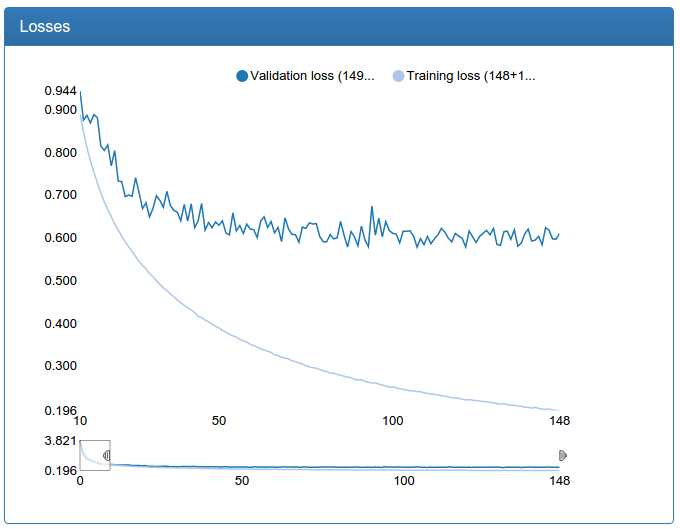
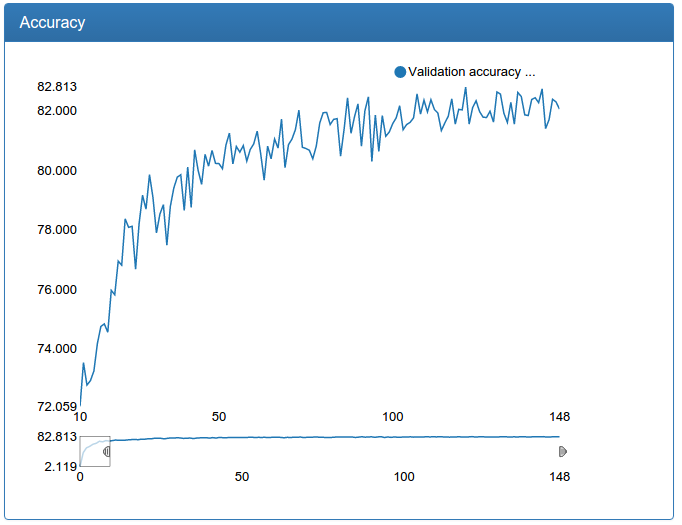
and here is the large calibration network itself:
def build_net48_cal(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 48, 48), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = max_pool(network)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.3), num_units=256, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.3), num_units=45, nolin=linear)
return networkThese graphs should be skeptical, because we need not classification, but regression. But empirical testing with a glance shows that a calibration trained in this way fulfills its purpose well.
I also note that for calibration, the initial data set is 45 times larger than for classification (45 classes for each person), but on the other hand, it could not be supplemented in the manner described above simply by setting the problem. So, sausages, especially a large network, pretty much.
Optimization II
Back to the detection. Experiments have shown that a small network does not provide the desired quality, so you need to learn a large one. But the big problem is that even on a powerful GPU for a very long time to classify thousands of windows that are obtained from one photo. Such a system would simply be impossible to implement. In the current version, there is great potential for optimizations by tricky tricks, but I decided that they are not scalable enough and that the problem should be solved qualitatively, and not cunningly optimizing the flops. And here’s the solution, before your eyes! A small network with 12x12 input, one convolution, one pooling and a classifier on top! It works very quickly, especially considering that you can run the classification on the GPU in parallel for all windows - it turns out almost instantly.
Ensemble
One Ensemble to bring them all and in the darkness bind them.
So, it was decided to use not one classification and one calibration, but a whole ensemble of networks. First, there will be a weak classification, then a weak calibration, then the filtering of calibrated windows, which presumably indicate one face, and then only on these remaining windows to run a strong classification and then a strong calibration.
Later, practice showed that it was still rather slow, so I made the ensemble as many as three levels: in the middle between the two, an “average” classification was inserted, followed by an “average” calibration and then filtering. In such a combination, the system works fast enough that there is a real opportunity to use it in production if you make some engineering efforts and implement some tricks, just to reduce flops and increase parallelism.
Total we get the algorithm:
- We find all the windows.
- We check the first detection network.
- Those that caught fire are calibrated with the first calibration network.
- Filter the intersecting windows.
- We check the second detection network.
- Those that caught fire, calibrate the second calibration network.
- Filter the intersecting windows.
- We check the third detection network.
- Those that caught fire, calibrate the third calibration network.
- Filter the intersecting windows.
Batch windows
If you take steps two through seven for each window separately, it takes quite a long time: constant switching from the CPU to the GPU, defective parallelism utilization on the video card, and who knows what else. Therefore, it was decided to make pipelined logic that could work not only with individual windows, but with batches of arbitrary size. To do this, it was decided to turn each stage into a generator, and put a code between each stage, which also works as a generator, but not windows, but batches and buffers the results of the previous stage and, if a predetermined number of results are accumulated (or the end), gives the collected batches further.
This system not bad (30 percent) accelerated the processing during detection.
Moar data!
As I noted in a previous article above, a large detection network learns with a creak: constant sharp jumps, and chatters it. And it’s not a matter of learning speed, as anyone who is familiar with learning networks would think first! The fact is that there is still little data. The problem is indicated - you can look for a solution! And it was found right there: the Labeled Faces in the Wild dataset.
The combined dataset from FDDB, LFW and my personal refills was almost three times the original. What came of it? Less words, more pictures!
A small network is noticeably more stable, converges faster and the result is better:
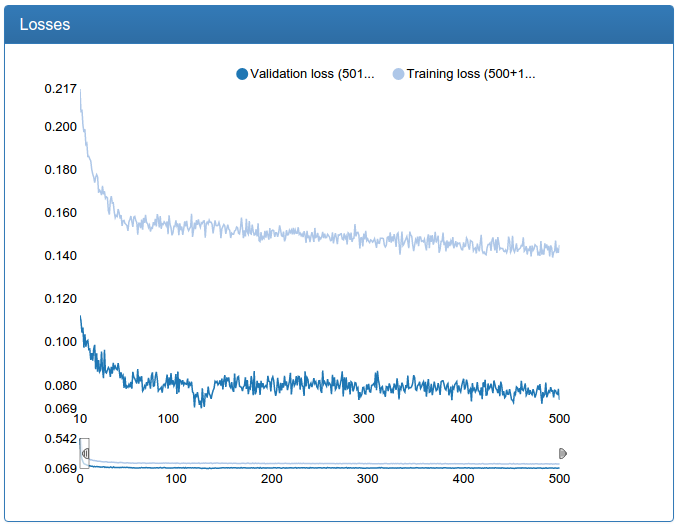
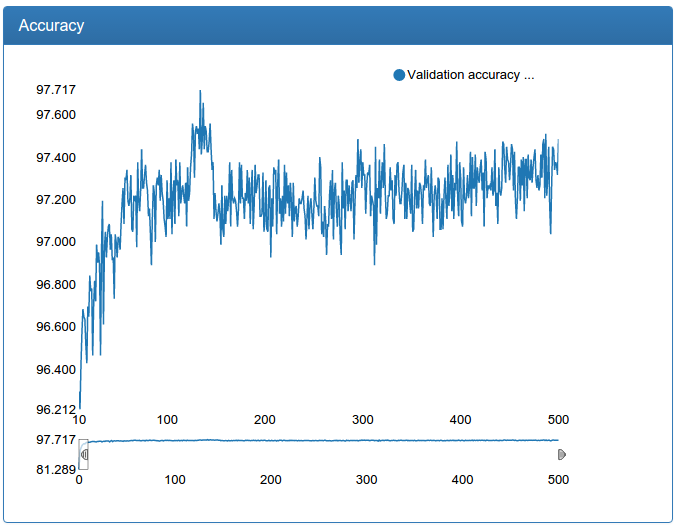

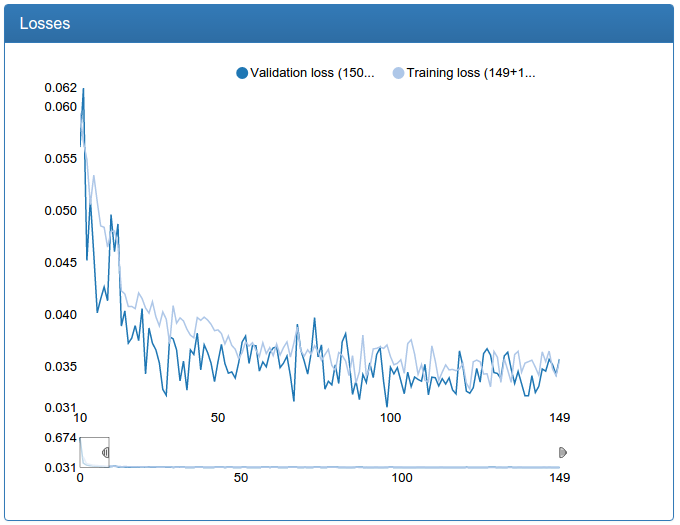
A large network is also noticeably more stable, surges disappeared, converges faster, the result is suddenly, a little worse, but 0.17% seems to me an acceptable error:
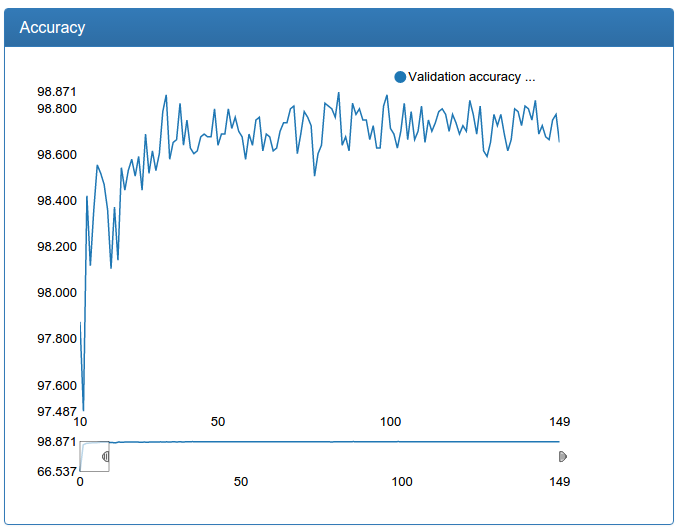

Additionally, such an increase in the amount of data allowed us to further increase the large model for detection:

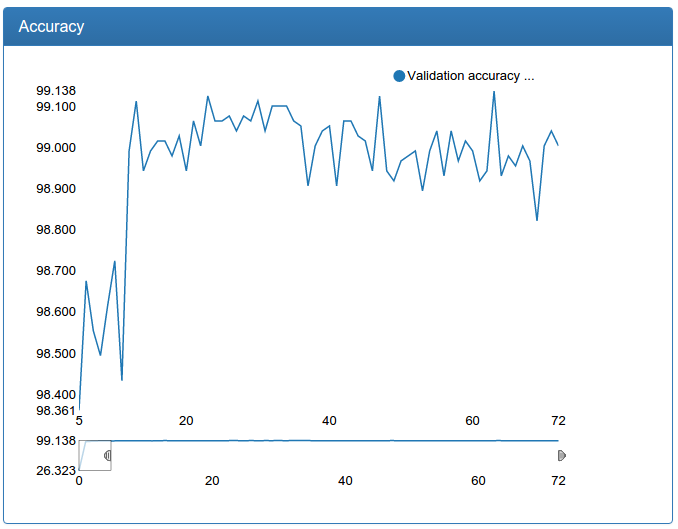

We see that the model converges even faster, to an even better result and is very stable.
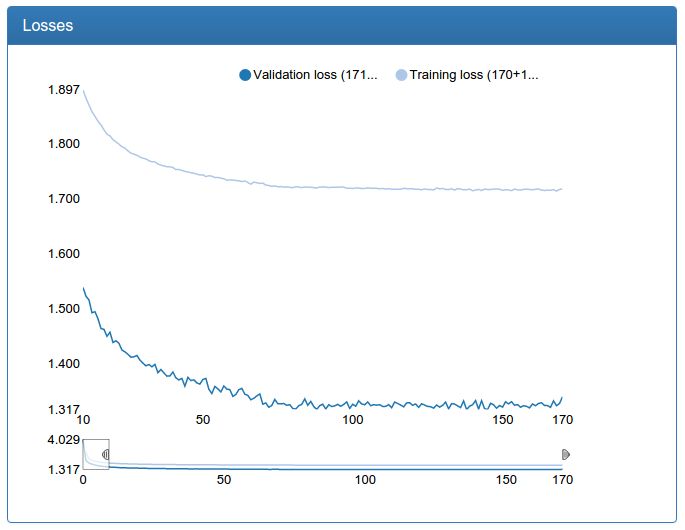
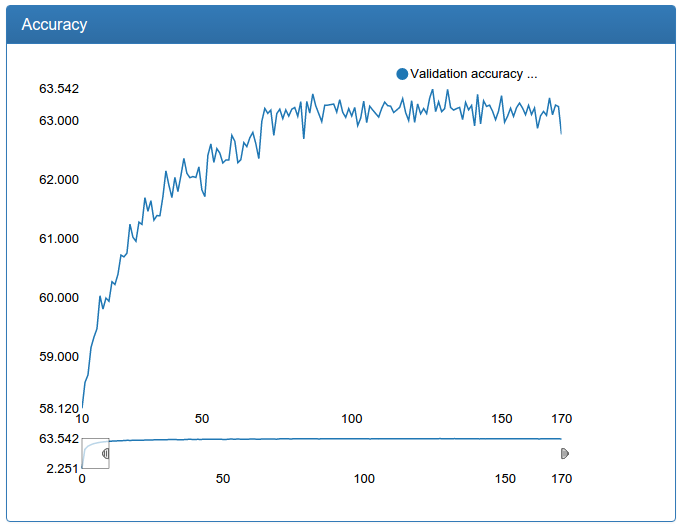
At the same time, I re-trained and calibration networks with more data.
Small calibration:
and large calibration:
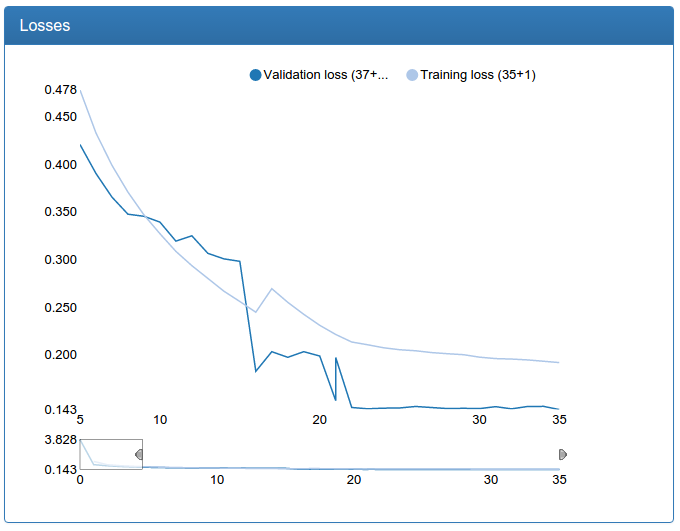
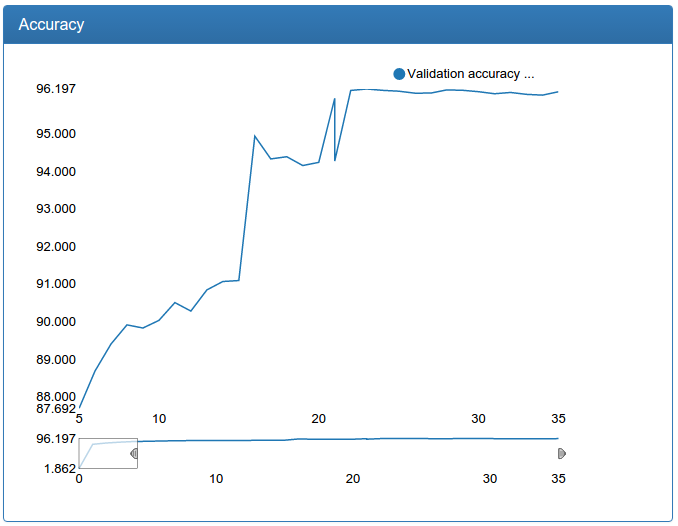
In contrast to the detection network, here you can see a dramatic improvement. This is because the original training set is not augmented and the original network suffers greatly from lack of data, as the network suffered for detection before augmentation.
Detection ready
Image illustrating the entire pipeline (classification-1, calibration-1, filtering, classification-2, calibration-2, filtering, classification-3, calibration-3, filtering, global filtering, faces from the training set are marked in white):

Success!
Multi-resolution
By this moment, those of you who are following the trends have probably already thought that the dinosaur is using techniques from ancient times (4 years ago :), where are the cool new tricks? And here they are!
On the open spaces of arxiv.org an interesting idea was taken up: let's count feature cards in the convolution layers at different resolutions: it’s commonplace to make networks several inputs: NxN, (N / 2) x (N / 2), (N / 4) x (N / 4) as many as you want! And serve the same square, only in different ways reduced.
Then, for the final classifier, all cards are concatenated and, as it were, can look at different resolutions.
It was on the left, on the right it became (measured on the very middle network):
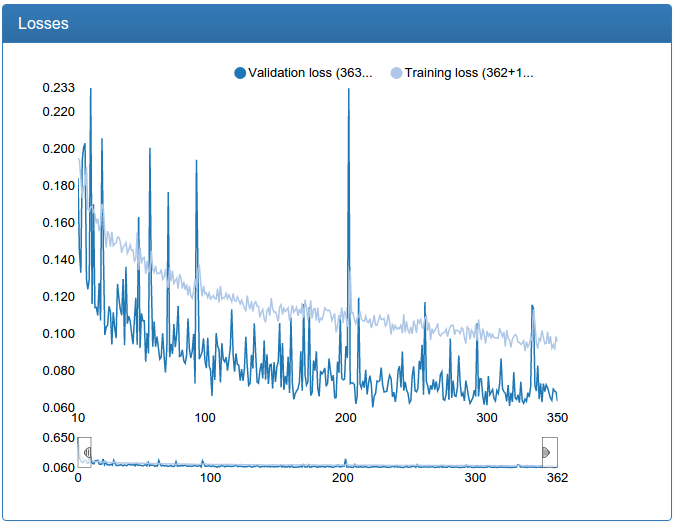
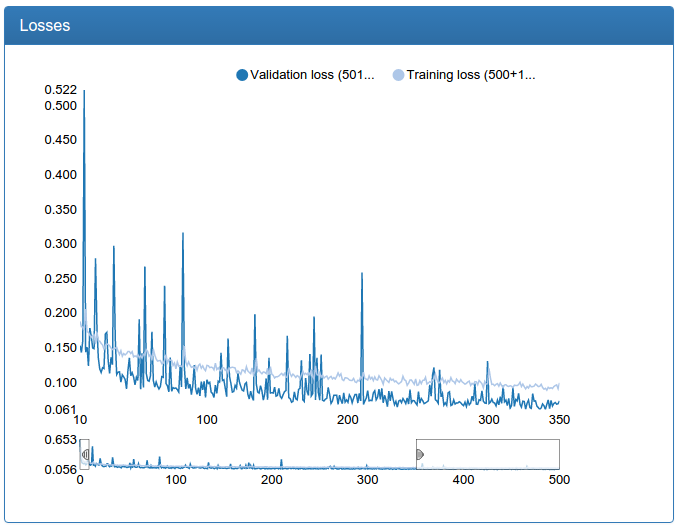
It can be seen that in my case, a network with several resolutions converges faster and hangs a little less. Nevertheless, I rejected the idea as not working, since the small and medium networks should not be super accurate, and instead of multi-permissions, I simply increased the large one with even greater success.
Batch normalization
Batch normalization is a network regularization technique. The idea is that each input layer takes the result of the previous layer, which can contain almost any tensor, the coordinates of which are supposedly somehow distributed. And it would be very convenient for a layer if it were fed to the input tensors with coordinates from a fixed distribution, one for all layers, then it would not have to learn a transformation that is invariant to the distribution parameters of the input data. Well, okay, let's insert some calculation between all layers, which optimally normalizes the outputs of the previous layer, which reduces the pressure on the next layer and gives it the opportunity to do its job better.
This technique helped me a lot: it allowed me to reduce the probability of a dropout while maintaining the same model quality. Reducing the probability of a dropout in turn leads to faster network convergence (and more retraining if you do this without normalizing the batch). Actually, literally on all the graphs you see the result: the networks quickly converge to 90% of the final quality. Before the normalization of batches, the fall in the error was much more gentle (unfortunately, the results were not preserved, since then there was no DeepEvent).
Inceptron
Of course, I could not resist fiddling with modern architectures and tried to train Inceptron for face classification (not GoogLeNet, but a much smaller network). Unfortunately, this model cannot be correctly made in Theano: the library does not support zero-padding of arbitrary size, so I had to tear one of the branches of the Inception-module, namely the right one in this picture:
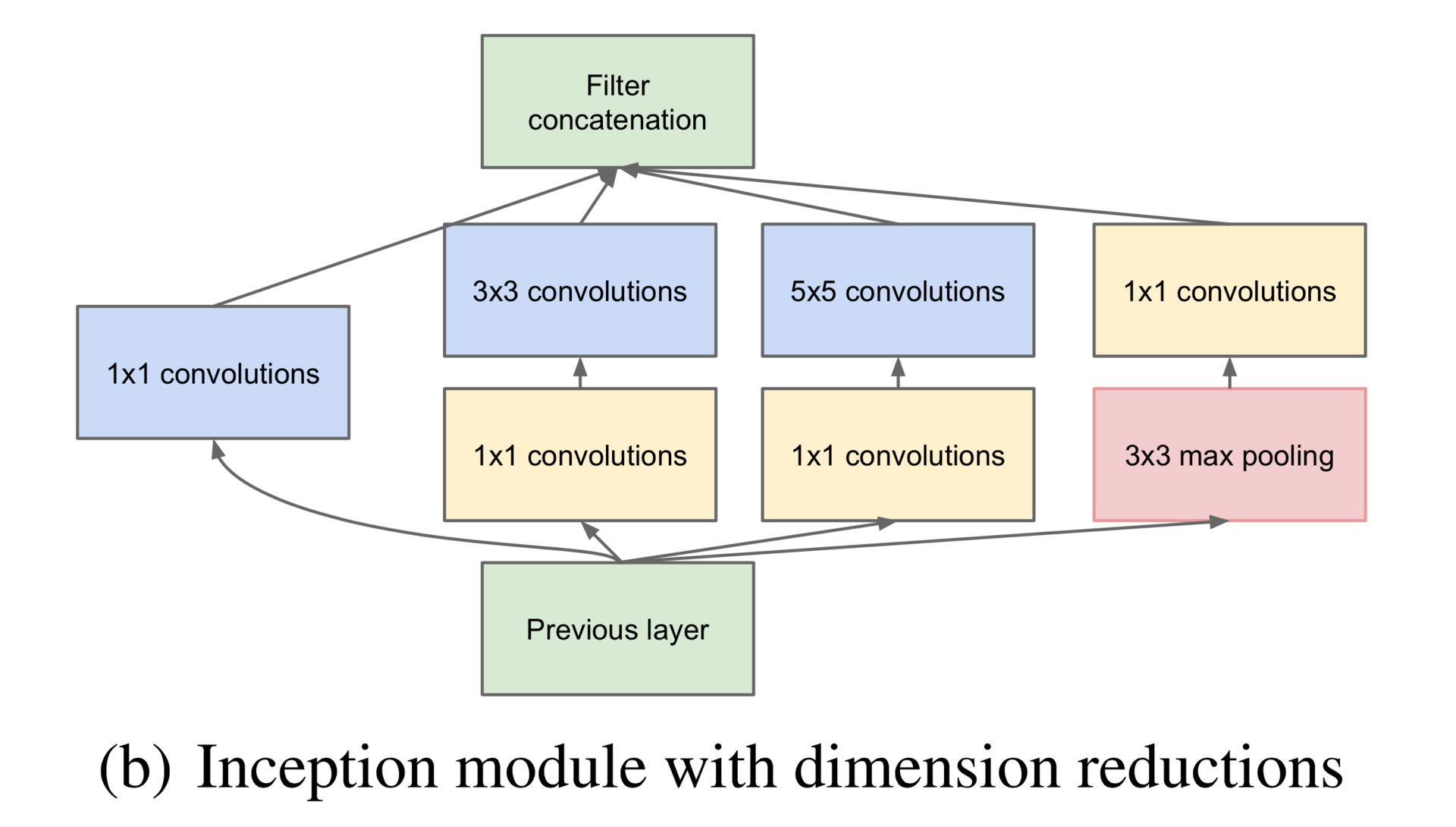
Additionally, I only had three inception-modules each on the other, and not seven, as in GoogLeNet, there were no preliminary exits, and there were no usual revolution-pulling layers at the beginning. \
def build_net64_inceptron(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 64, 64), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
b1 = conv(network, num_filters=32, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=48, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=64, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=8, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=16, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
b1 = conv(network, num_filters=64, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=64, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=96, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=16, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=48, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
b1 = conv(network, num_filters=96, filter_size=(1, 1), nolin=relu)
b2 = conv(network, num_filters=48, filter_size=(1, 1), nolin=relu)
b2 = conv(b2, num_filters=104, filter_size=(3, 3), nolin=relu)
b3 = conv(network, num_filters=8, filter_size=(1, 1), nolin=relu)
b3 = conv(b3, num_filters=24, filter_size=(5, 5), nolin=relu)
network = lasagne.layers.ConcatLayer([b1, b2, b3], axis=1)
network = max_pool(network, pad=(1, 1))
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=256, nolin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=2, nolin=linear)
return networkAnd I even did it!
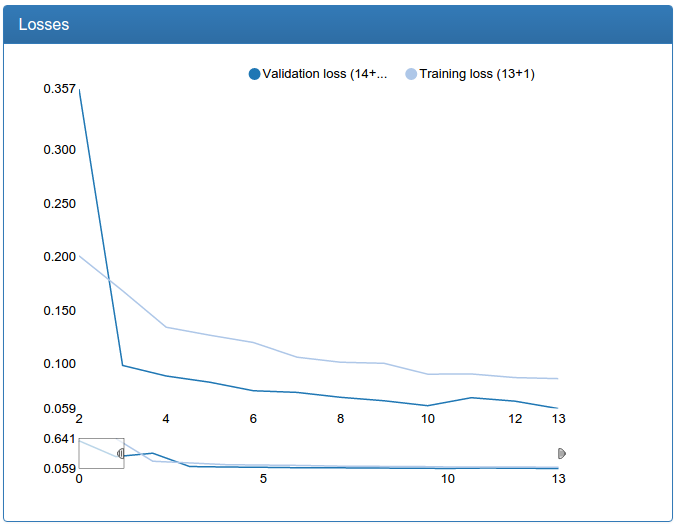

The result is one percent worse than the usual convolution network, which I trained earlier, but also worthy! However, when I tried to train the same network, but out of four inception modules, it stably scattered. I have the feeling that this architecture (at least with my modifications) is very moody. In addition, batch normalization, for some reason, steadily turned this network into a complete split. Here I suspect a semi-artisanal implementation of batch normalization for Lasagne, but in general all this made me postpone Inceptron to a brighter future with Tensorflow.
By the way, Tensorflow!
Of course, I tried it too! I tried out this fashionable technology on the same day when it came out with great hopes and admiration for Google, our savior! But no, he did not live up to expectations. The declared automatic use of several GPUs is not even mentioned: you need to place operations on different cards with your hands; It worked only with the last kuda, which I then could not install on the server, had a hard-coded version of libc and did not start on another server, and it was also assembled manually using blaze, which does not work in docker containers. In short, some disappointments, although the model of working with him is very good!
Tensorboard was also a disappointment. I don’t want to go into details, but I didn’t like everything and I started developing my monitoring called DeepEvent, the screenshots from which you saw in the article.
In the next series:
Emoticons, a ready-made system, results and, finally, pretty girls!