Microservice Design Patterns
- Transfer
Hello, Habr!
In the near future, read the post about the Russian translation of the long-awaited book " Creating Microservices " by Sam Newman, which has already gone to the stores. In the meantime, we suggest reading a translation of an article by Arun Gupta, whose author describes the most interesting design patterns applicable in microservice architecture.
The main characteristics of microservice applications are described in the article " Microservices, Monoliths and NoOps". These characteristics are functional decomposition or subject-oriented design, clearly defined interfaces, an explicitly published interface, the principle of sole responsibility and potential multilingualism. Each service is completely autonomous and fully stacked. Accordingly, a change in the implementation of one service does not affect the others, and the exchange of information occurs through well-defined interfaces.This application has a number of advantages, but they are not given for free , but require serious work related to NoOp s.
But suppose you imagine the scale of this work, at least partially, that you really want to create such an application and see what happens. What to do? What will be the architecture of such an application?
Are there design patterns that optimize the interaction of microservices?

To create a high-quality microservice architecture, you must clearly separate the functions in your application and team. This way you can achieve weak binding (REST interfaces) and strong adhesion (many services can be combined together, defining higher-level services or applications).
Creating “verbs” (eg Checkout) or “nouns” (Product) as part of an application is one of the effective ways to decompose existing code. For example, product, catalog and checkout can be implemented as three separate microservices, and then interact with each other, providing full functionality of the basket of orders.
Functional decomposition provides flexibility, scalability and other things, but our task is to create an application. So, if the individual microservices are identical, how can they be combined to implement the functionality of the application?
This will be discussed in the article
Aggregator Pattern. The
first and perhaps the most common design pattern when working with microservices is the “aggregator”.
In its simplest form, an aggregator is a regular web page that invokes many services to implement the functionality required in the application. Since all services (Service A, Service B and Service C) are provided using a lightweight REST mechanism, the web page can extract data and process / display it as needed. If you need some kind of processing, for example, applying business logic to the data received from individual services, then for this you can have a CDI component that transforms the data so that it can be displayed on a web page.
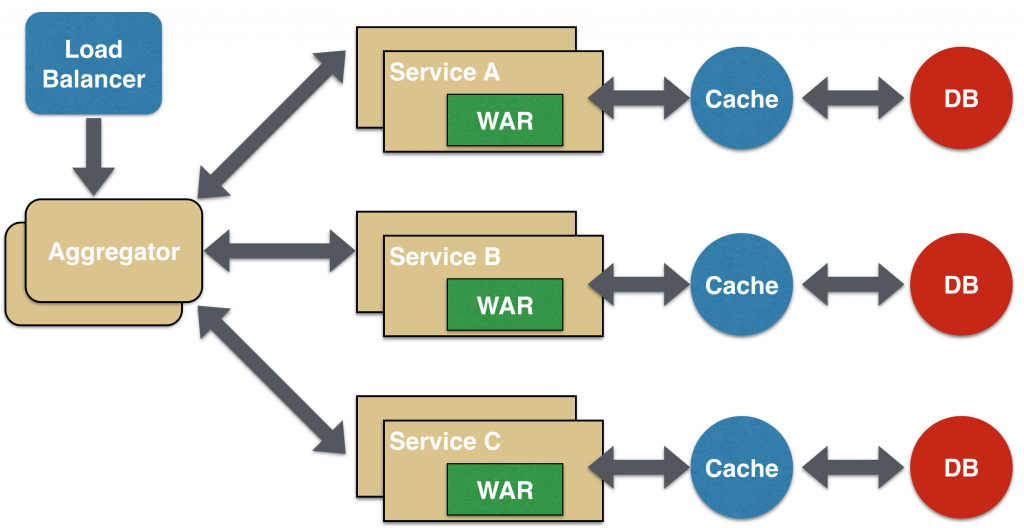
The aggregator can also be used in cases where you do not need to display anything, but only a higher-level composite microservice that other services can consume is needed. In this case, the aggregator simply collects data from all individual microservices, applies business logic to them, and then publishes the microservice as a REST endpoint. In this case, if necessary, it can be consumed by other services that need it.
This pattern follows the DRY principle. If there are many services that should access services A, B, and C, it is recommended to abstract this logic into a composite microservice and aggregate it as a separate service. The advantage of abstracting at this level is that individual services, say A, B, and C, can evolve independently, and the composite microservice will continue to execute business logic.
Please note: each individual microservice (optional) has its own cache levels and databases. If the aggregator is a composite microservice, then it can have such levels.
The aggregator can also be independently scaled both horizontally and vertically. That is, if it is a web page, then additional web servers can be screwed to it, and if it is a composite microservice using Java EE, then additional instances of WildFly are screwed to it, which can satisfy growing needs.
Mediator pattern (Proxy)
The mediator pattern when working with microservices is a variant of the aggregator. In this case, aggregation should occur on the client, but depending on business requirements, an additional microservice may be called up.

Like an aggregator, a mediator can independently scale horizontally and vertically. This may be needed in a situation where each individual service should not be provided to the consumer, but run through the interface.
The intermediary can be formal (dumb), in which case it simply delegates the request to one of the services. It can also be intelligent (smart), in which case the data before being sent to the client undergo some kind of transformation. For example, the presentation layer for various devices can be encapsulated in an intelligent intermediary.
Chain Design Pattern (Chained)
The microservice design pattern “Chain” provides a single consolidated response to the request. In this case, service A receives a request from the client, communicates with service B, which, in turn, can contact service C. All these services will most likely exchange synchronous request / response messages via HTTP.
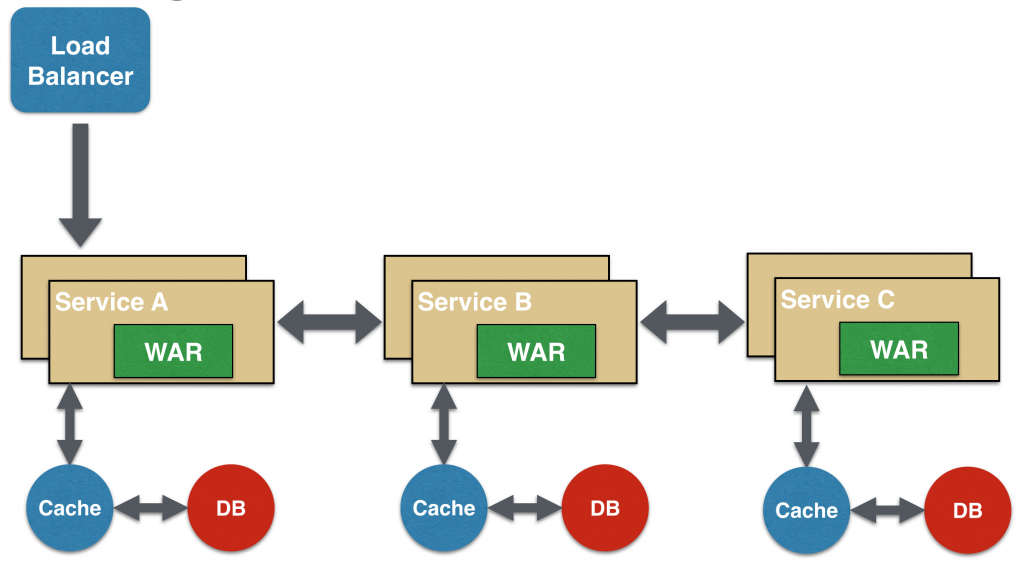
It is most important to remember that the client is blocked until the entire communication chain of requests and responses is completed, i.e. Service <-> Service B and Service B <-> Service C. A request from Service B to Service C may look completely different than from Service A to Service B. Similarly, the response from Service B to Service A can be fundamentally different from the response from Service C to Service B. This is most important in all cases where the business value of several services is combined.
It’s also important to understand that you shouldn’t make the chain too long. This is critical because the chain is synchronous in nature, and the longer it is, the longer the client will have to wait, especially if the response is to display the web page. There are ways to get around this blocking mechanism of requests and responses, and they are discussed in the following pattern.
A chain consisting of a single microservice is called a single chain. Subsequently, it can be expanded.
Design Pattern “Branch”
The microservice design pattern “Vetka” extends the “Aggregator” pattern and provides simultaneous processing of responses from two chains of microservices, which can be mutually exclusive. This pattern can also be used to call different chains, or the same chain - depending on your needs.

Service A, whether it be a web page or a composite microservice, can compete in two different chains - in which case it will resemble an aggregator. In another case, service A can only call one chain, depending on what request it receives from the client.
Such a mechanism can be configured by implementing JAX-RS endpoint routing, in which case the configuration should be dynamic.
Shared Data Pattern
One of the principles of microservice design is autonomy. This means that the service is full-stack and controls all components - user interface, middleware, persistence, transactions. In this case, the service can be multilingual and solve every problem with the most suitable tools. For example, if you can use the NoSQL data warehouse if necessary, then it’s better to do just that, rather than hammering this information into the SQL database.
However, a typical problem, especially when refactoring an existing monolithic application, is related to database normalization - so that each microservice has a strictly defined amount of information, no more, no less. Even if the monolithic application uses only the SQL database, its denormalization leads to duplication of data, and possibly to inconsistency. At the transition stage, in some applications it can be very useful to apply the “Shared Data” pattern.
In this pattern, several microservices can work on a chain and share cache and database stores. This is only advisable if there is a strong connection between the two services. Some may see this as antipattern, but in some business situations, such a pattern is really appropriate. It would definitely be antipattern in an application that was originally created as microservice.

In addition, it can be considered as an intermediate stage that must be overcome until the microservices become fully autonomous.
Asynchronous Messaging Pattern
Despite the prevalence and comprehensibility of the REST pattern, it has an important limitation, namely: it is synchronous and, therefore, blocking. It is possible to provide asynchrony, but this is done differently in each application. Therefore, some microservice architectures may use message queues rather than a request / response REST model.
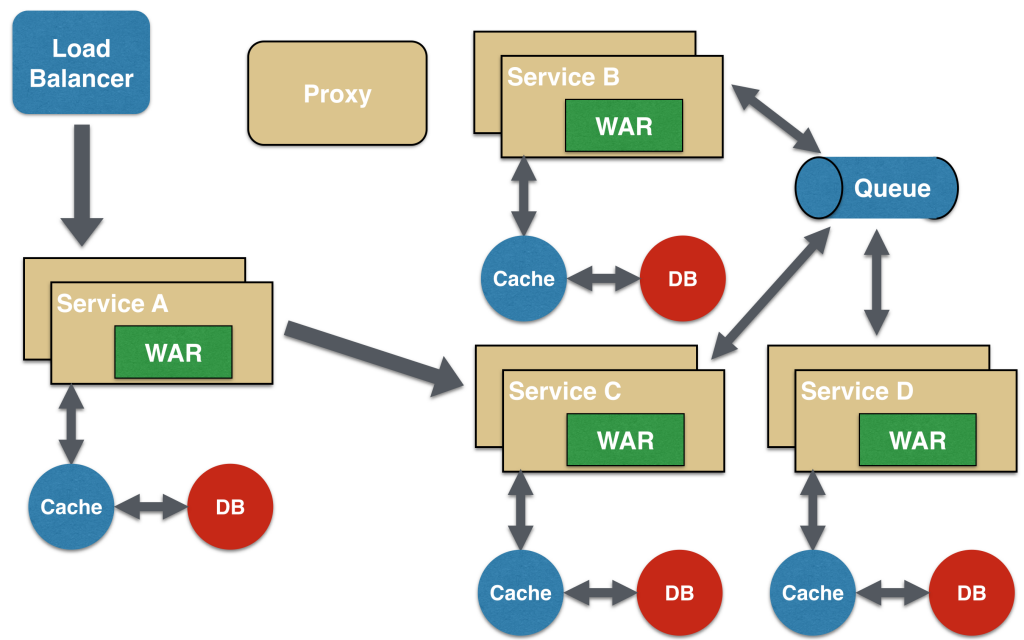
In this pattern, service A can synchronously call service C, which will then asynchronously communicate with services B and B using a shared message queue. Communication Service A -> Service C can be asynchronous, say, using web sockets; this achieves the desired scalability.
The combination of the REST request / response model and the publisher / subscriber messaging can also be used to achieve the goals.
I also recommend reading the Coupling vs Autonomy in Microservices article , which describes which communication patterns are convenient to use with microservices.
In the near future, read the post about the Russian translation of the long-awaited book " Creating Microservices " by Sam Newman, which has already gone to the stores. In the meantime, we suggest reading a translation of an article by Arun Gupta, whose author describes the most interesting design patterns applicable in microservice architecture.
The main characteristics of microservice applications are described in the article " Microservices, Monoliths and NoOps". These characteristics are functional decomposition or subject-oriented design, clearly defined interfaces, an explicitly published interface, the principle of sole responsibility and potential multilingualism. Each service is completely autonomous and fully stacked. Accordingly, a change in the implementation of one service does not affect the others, and the exchange of information occurs through well-defined interfaces.This application has a number of advantages, but they are not given for free , but require serious work related to NoOp s.
But suppose you imagine the scale of this work, at least partially, that you really want to create such an application and see what happens. What to do? What will be the architecture of such an application?
Are there design patterns that optimize the interaction of microservices?
To create a high-quality microservice architecture, you must clearly separate the functions in your application and team. This way you can achieve weak binding (REST interfaces) and strong adhesion (many services can be combined together, defining higher-level services or applications).
Creating “verbs” (eg Checkout) or “nouns” (Product) as part of an application is one of the effective ways to decompose existing code. For example, product, catalog and checkout can be implemented as three separate microservices, and then interact with each other, providing full functionality of the basket of orders.
Functional decomposition provides flexibility, scalability and other things, but our task is to create an application. So, if the individual microservices are identical, how can they be combined to implement the functionality of the application?
This will be discussed in the article
Aggregator Pattern. The
first and perhaps the most common design pattern when working with microservices is the “aggregator”.
In its simplest form, an aggregator is a regular web page that invokes many services to implement the functionality required in the application. Since all services (Service A, Service B and Service C) are provided using a lightweight REST mechanism, the web page can extract data and process / display it as needed. If you need some kind of processing, for example, applying business logic to the data received from individual services, then for this you can have a CDI component that transforms the data so that it can be displayed on a web page.
The aggregator can also be used in cases where you do not need to display anything, but only a higher-level composite microservice that other services can consume is needed. In this case, the aggregator simply collects data from all individual microservices, applies business logic to them, and then publishes the microservice as a REST endpoint. In this case, if necessary, it can be consumed by other services that need it.
This pattern follows the DRY principle. If there are many services that should access services A, B, and C, it is recommended to abstract this logic into a composite microservice and aggregate it as a separate service. The advantage of abstracting at this level is that individual services, say A, B, and C, can evolve independently, and the composite microservice will continue to execute business logic.
Please note: each individual microservice (optional) has its own cache levels and databases. If the aggregator is a composite microservice, then it can have such levels.
The aggregator can also be independently scaled both horizontally and vertically. That is, if it is a web page, then additional web servers can be screwed to it, and if it is a composite microservice using Java EE, then additional instances of WildFly are screwed to it, which can satisfy growing needs.
Mediator pattern (Proxy)
The mediator pattern when working with microservices is a variant of the aggregator. In this case, aggregation should occur on the client, but depending on business requirements, an additional microservice may be called up.
Like an aggregator, a mediator can independently scale horizontally and vertically. This may be needed in a situation where each individual service should not be provided to the consumer, but run through the interface.
The intermediary can be formal (dumb), in which case it simply delegates the request to one of the services. It can also be intelligent (smart), in which case the data before being sent to the client undergo some kind of transformation. For example, the presentation layer for various devices can be encapsulated in an intelligent intermediary.
Chain Design Pattern (Chained)
The microservice design pattern “Chain” provides a single consolidated response to the request. In this case, service A receives a request from the client, communicates with service B, which, in turn, can contact service C. All these services will most likely exchange synchronous request / response messages via HTTP.
It is most important to remember that the client is blocked until the entire communication chain of requests and responses is completed, i.e. Service <-> Service B and Service B <-> Service C. A request from Service B to Service C may look completely different than from Service A to Service B. Similarly, the response from Service B to Service A can be fundamentally different from the response from Service C to Service B. This is most important in all cases where the business value of several services is combined.
It’s also important to understand that you shouldn’t make the chain too long. This is critical because the chain is synchronous in nature, and the longer it is, the longer the client will have to wait, especially if the response is to display the web page. There are ways to get around this blocking mechanism of requests and responses, and they are discussed in the following pattern.
A chain consisting of a single microservice is called a single chain. Subsequently, it can be expanded.
Design Pattern “Branch”
The microservice design pattern “Vetka” extends the “Aggregator” pattern and provides simultaneous processing of responses from two chains of microservices, which can be mutually exclusive. This pattern can also be used to call different chains, or the same chain - depending on your needs.
Service A, whether it be a web page or a composite microservice, can compete in two different chains - in which case it will resemble an aggregator. In another case, service A can only call one chain, depending on what request it receives from the client.
Such a mechanism can be configured by implementing JAX-RS endpoint routing, in which case the configuration should be dynamic.
Shared Data Pattern
One of the principles of microservice design is autonomy. This means that the service is full-stack and controls all components - user interface, middleware, persistence, transactions. In this case, the service can be multilingual and solve every problem with the most suitable tools. For example, if you can use the NoSQL data warehouse if necessary, then it’s better to do just that, rather than hammering this information into the SQL database.
However, a typical problem, especially when refactoring an existing monolithic application, is related to database normalization - so that each microservice has a strictly defined amount of information, no more, no less. Even if the monolithic application uses only the SQL database, its denormalization leads to duplication of data, and possibly to inconsistency. At the transition stage, in some applications it can be very useful to apply the “Shared Data” pattern.
In this pattern, several microservices can work on a chain and share cache and database stores. This is only advisable if there is a strong connection between the two services. Some may see this as antipattern, but in some business situations, such a pattern is really appropriate. It would definitely be antipattern in an application that was originally created as microservice.
In addition, it can be considered as an intermediate stage that must be overcome until the microservices become fully autonomous.
Asynchronous Messaging Pattern
Despite the prevalence and comprehensibility of the REST pattern, it has an important limitation, namely: it is synchronous and, therefore, blocking. It is possible to provide asynchrony, but this is done differently in each application. Therefore, some microservice architectures may use message queues rather than a request / response REST model.
In this pattern, service A can synchronously call service C, which will then asynchronously communicate with services B and B using a shared message queue. Communication Service A -> Service C can be asynchronous, say, using web sockets; this achieves the desired scalability.
The combination of the REST request / response model and the publisher / subscriber messaging can also be used to achieve the goals.
I also recommend reading the Coupling vs Autonomy in Microservices article , which describes which communication patterns are convenient to use with microservices.