Curiosity and procrastination in machine learning
- Transfer
Reinforcement learning (RL) is one of the most promising machine learning techniques that is currently being actively developed. Here the AI agent receives a positive reward for the correct actions, and a negative reward for the wrong ones. This method of carrot and stick is simple and universal. With it, DeepMind taught the DQN algorithm to play the old Atari video games, and AlphaGoZero the ancient Go game. So OpenAI taught the OpenAI-Five algorithm to play the modern Dota video game, and Google taught robotic hands to grab new objects . Despite the success of RL, there are still many problems that reduce the effectiveness of this technique.
RL algorithms are hard to work.in an environment where the agent rarely receives feedback. But this is typical of the real world. As an example, imagine searching for your favorite cheese in a large maze, like a supermarket. You are looking for and looking for a department with cheeses, but you can’t find it. If at every step you get neither a “carrot” nor a “carrot”, then it is impossible to say whether you are moving in the right direction. In the absence of a reward, what keeps you from roaming around forever? Nothing, except perhaps your curiosity. It motivates to go to the grocery department, which looks unfamiliar.
The scientific work "Episodic curiosity through attainability" is the result of collaboration between the Google Brain team , DeepMind and the Swiss Technical School of Zurich . We offer a new episodic memory-based RL reward model. She looks like a curiosity that allows you to explore the environment. Since the agent must not only study the environment, but also solve the original problem, our model adds a bonus to the initial sparse reward. The combined reward is no longer sparse, which allows standard RL algorithms to learn from it. Thus, our method of curiosity extends the set of problems solved with the help of RL.

Episodic curiosity through attainability: observational data is added to memory, the reward is calculated based on how far the current observation is from similar observations in memory. The agent receives a greater reward for observations that are not yet represented in the memory.
The main idea of the method is to store the observations of the environmental agent in episodic memory, and also to reward the agent for viewing observations that are not yet represented in memory. “Lack of memory” is the definition of novelty in our method. The search for such observations means the search for a stranger. Such a desire to search for a stranger will lead the AI agent to new locations, thereby preventing him from wandering around in a circle, and ultimately help him stumble upon a target. As we will discuss later, our formulation can keep an agent from undesirable behavior, which some other formulations are subject to. Much to our surprise, this behavior has some similarities with what a non-expert would call “procrastination.”
Although in the past there have been many attempts to formulate curiosity [1] [2] [3] [4] , in this article we will focus on one natural and very popular approach: curiosity through surprise based on prediction. This technique is described in a recent article, “Surveying the environment with the help of curiosity by predicting under independent control” (usually referred to as ICM). To illustrate the connection of surprise with curiosity, we again use the analogy of finding cheese in a supermarket.
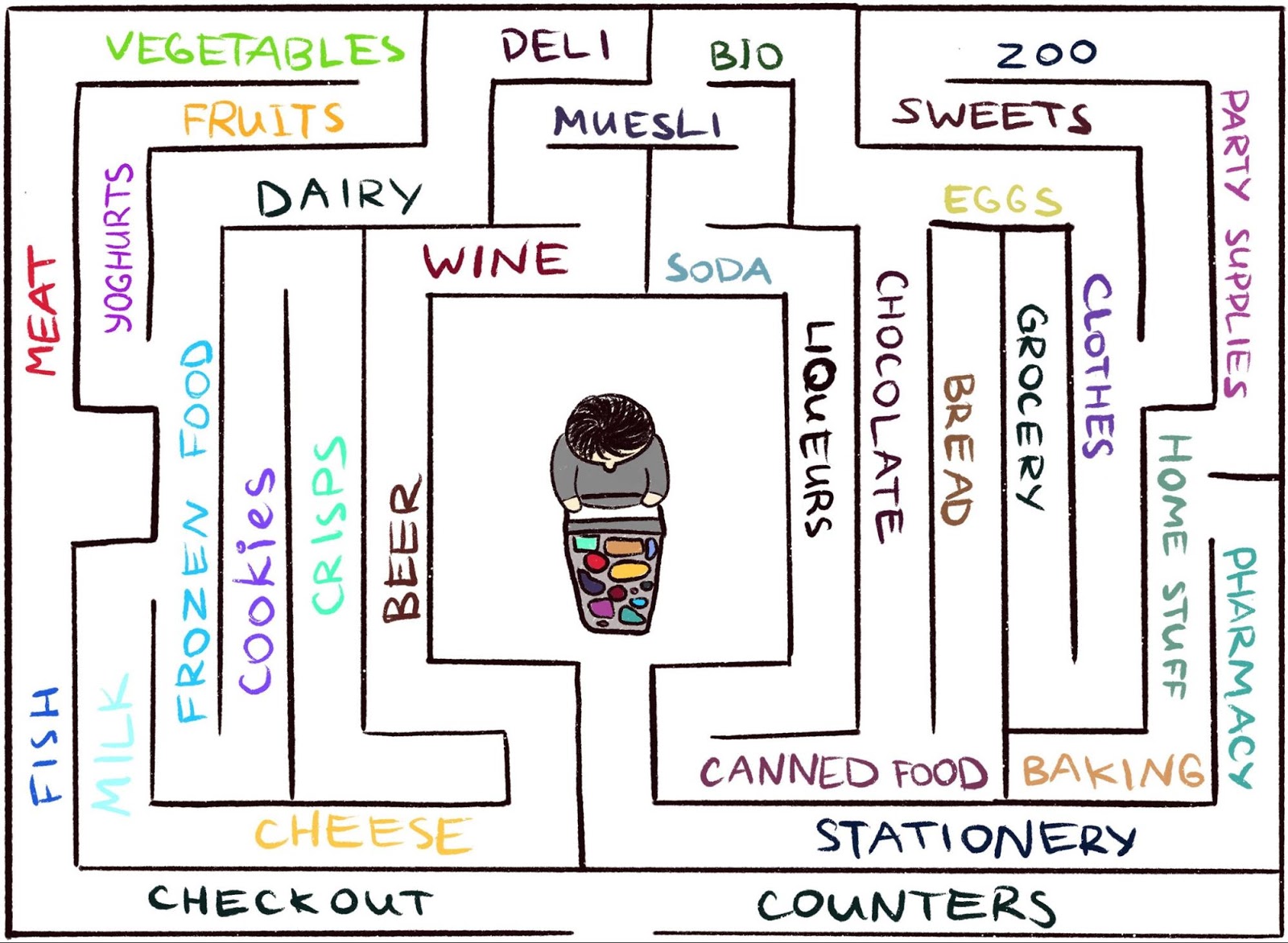
Illustration of Indira Pasko , under license CC BY-NC-ND 4.0
Wandering around the store, you are trying to predict the future ("Now I am in the meat department, so I think that the department around the corner is the fish department, they are usually near this supermarket chain" ). If the prediction is wrong, you are surprised ( "In fact, the vegetables department is here. I did not expect it!" ) - and thus you get a reward. This increases the motivation in the future to look around the corner again, exploring new places just to check that your expectations correspond to reality (and, perhaps, stumble upon cheese).
Similarly, the ICM method builds a predictive model of the dynamics of the world and gives the agent a reward if the model fails to make good predictions - a marker of surprise or novelty. Please note that exploring new places is not directly articulated in ICM curiosity. For ICM, visiting them is only a way to get more “surprises” and thus maximize the total reward. As it turns out, in some environments there may be other ways to cause surprise, which leads to unexpected results.

An agent with a curiosity system based on surprise hangs when meeting a TV. Animation from Deepak Patac 's video , used under license CC BY 2.0
In the article “Large-scale study of curiosity-based learning,” the authors of the ICM method, together with OpenAI researchers, show the hidden danger of maximizing surprise: agents can learn to indulge in procrastination instead of doing something useful for the task. To understand why this is so, consider a thought experiment, which the authors call the "television noise problem." Here the agent is placed in a labyrinth with the task of finding a very useful item (such as “cheese” in our example). The environment has a TV, and the agent has a remote control. There is a limited number of channels (on each individual program), and each press on the remote switches the TV to a random channel. How will the agent act in such an environment?
If curiosity is formed on the basis of surprise, then changing channels will give more reward, since every change is unpredictable and unexpected. It is important to note that even after a cyclic review of all available channels, random selection of the channel ensures that every new change will still be unexpected - the agent makes a prediction that he will show TV after switching the channel, and most likely the forecast will be wrong, which will cause surprise. It is important to note that even if the agent has already seen every program on every channel, the change is still unpredictable. Because of this, the agent, instead of looking for a very useful item, will eventually remain in front of the TV - it looks like a procrastination. How to change the wording of curiosity to prevent such behavior?
In the article “Episodic curiosity through attainability,” we explore the episodic curiosity model based on memory, which is less prone to receiving instant pleasures. Why is that? If we take the example above, after a while the channel is switched all the programs will eventually end up in memory. Thus, the TV will lose its attractiveness: even if the order of appearance of programs on the screen is random and unpredictable, they are all in memory! This is the main difference from the method based on surprise: our method does not even try to predict the future, it is difficult (or even impossible) to predict it. Instead, the agent studies the past and checks whether there are observations in the memory, likecurrent. Thus, our agent is not inclined to instant pleasures, which are given by “television noise”. The agent will have to go and explore the world outside of TV to get more rewards.
But how do we decide whether the agent sees the same thing that is stored in memory? Checking the exact match is meaningless: in a real environment, an agent rarely sees the same thing twice. For example, even if the agent returns to the same room, he will still see this room from a different angle.
Instead of checking the exact match, we use a deep neural network.who is trained to measure how similar the two experiences are. To train this network, we must guess how closely the observations occurred. The proximity in time is a good indicator of whether two observations should be considered part of the same thing. Such training leads to a general concept of novelty through attainability, which is illustrated below.

Reach graph determines novelty. In practice, this graph is not available - so we train the neural network approximator to estimate the number of steps between observations.
To compare the performance of different approaches to the description of curiosity, we tested them in two visually rich 3D environments: ViZDoom and DMLab. Under these conditions, the agent was assigned various tasks, such as finding a target in a maze, collecting good objects and evading bad ones. In the DMLab environment, the agent is equipped by default with a fantastic gadget like a laser, but if the gadget is not needed for a specific task, the agent can not use it freely. Interestingly, the ICM agent on the basis of surprise actually used the laser very often, even if it was useless to complete the task! As in the case of TV, instead of searching for a valuable object in the maze, he chose to spend time shooting at the walls, because it gave a lot of reward in the form of surprise. Theoretically, the result of firing on the walls should be predictable, but in practice it is too difficult to predict. This probably requires a deeper knowledge of physics than is available to the standard AI agent.

Based on surprise, an ICM agent continually burns into a wall instead of exploring a labyrinth
. Unlike him, our agent has mastered sensible environmental behavior. This happened because he is not trying to predict the result of his actions, but rather looking for observations that are “farther” from those that are in episodic memory. In other words, the agent implicitly pursues goals that require more effort than a simple shot at the wall.

Our method demonstrates reasonable behavior in environmental studies.
It is interesting to observe how our approach to remuneration punishes an agent running in a circle, because after completing the first round the agent does not encounter new observations and thus does not receive any reward:

The visualization of the reward: red corresponds to a negative reward, Green to a positive one. From left to right: a map with awards, a map with locations in memory, a first-person view
At the same time, our method contributes to a good exploration of the environment:

The visualization of the reward: red corresponds to a negative reward, Green to a positive one. From left to right: an award-winning map, a map with locations in memory, a first-person view.
We hope that our work contributes to a new wave of research that goes beyond the scope of astonishment to teach agents more intelligent behavior. For an in-depth analysis of our method, please take a look at the preprint of scientific work .
This project is the result of a collaboration between the Google Brain team, DeepMind and the Swiss Technical School of Zurich. The main research team: Nikolay Savinov, Anton Raichuk, Raphael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillicrap and Sylvain Zheli. We wanted to thank Olivier Pietkina, Carlos Riquelme, Charles Blundell and Sergei Levine for discussing this document. We are grateful to Indira Pasco for helping with the illustrations.
[1] “Study of the environment on the basis of calculation with models of neural density” , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remi Muñoz
[2] “Study of the environment on the basis of calculation for in-depth training with reinforcement” , Khaoran Tan, Rein Huthuft, Davis Foote, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Tours, Peter Abbel
[3] “Teaching without a teacher how to locate goals for internally motivated research” , Alexander Pere, Sebastien Forestier, Olivier Sego, Pierre-Yves Udeyeh
[4] “VIME: Intelligence with Maximizing Information Changes,” Rein Huthuf t, Xi Chen, Yan Duan, John Shulman, Philippe de Turk, Peter Abbel
RL algorithms are hard to work.in an environment where the agent rarely receives feedback. But this is typical of the real world. As an example, imagine searching for your favorite cheese in a large maze, like a supermarket. You are looking for and looking for a department with cheeses, but you can’t find it. If at every step you get neither a “carrot” nor a “carrot”, then it is impossible to say whether you are moving in the right direction. In the absence of a reward, what keeps you from roaming around forever? Nothing, except perhaps your curiosity. It motivates to go to the grocery department, which looks unfamiliar.
The scientific work "Episodic curiosity through attainability" is the result of collaboration between the Google Brain team , DeepMind and the Swiss Technical School of Zurich . We offer a new episodic memory-based RL reward model. She looks like a curiosity that allows you to explore the environment. Since the agent must not only study the environment, but also solve the original problem, our model adds a bonus to the initial sparse reward. The combined reward is no longer sparse, which allows standard RL algorithms to learn from it. Thus, our method of curiosity extends the set of problems solved with the help of RL.
Episodic curiosity through attainability: observational data is added to memory, the reward is calculated based on how far the current observation is from similar observations in memory. The agent receives a greater reward for observations that are not yet represented in the memory.
The main idea of the method is to store the observations of the environmental agent in episodic memory, and also to reward the agent for viewing observations that are not yet represented in memory. “Lack of memory” is the definition of novelty in our method. The search for such observations means the search for a stranger. Such a desire to search for a stranger will lead the AI agent to new locations, thereby preventing him from wandering around in a circle, and ultimately help him stumble upon a target. As we will discuss later, our formulation can keep an agent from undesirable behavior, which some other formulations are subject to. Much to our surprise, this behavior has some similarities with what a non-expert would call “procrastination.”
Previous curiosity wording
Although in the past there have been many attempts to formulate curiosity [1] [2] [3] [4] , in this article we will focus on one natural and very popular approach: curiosity through surprise based on prediction. This technique is described in a recent article, “Surveying the environment with the help of curiosity by predicting under independent control” (usually referred to as ICM). To illustrate the connection of surprise with curiosity, we again use the analogy of finding cheese in a supermarket.
Illustration of Indira Pasko , under license CC BY-NC-ND 4.0
Wandering around the store, you are trying to predict the future ("Now I am in the meat department, so I think that the department around the corner is the fish department, they are usually near this supermarket chain" ). If the prediction is wrong, you are surprised ( "In fact, the vegetables department is here. I did not expect it!" ) - and thus you get a reward. This increases the motivation in the future to look around the corner again, exploring new places just to check that your expectations correspond to reality (and, perhaps, stumble upon cheese).
Similarly, the ICM method builds a predictive model of the dynamics of the world and gives the agent a reward if the model fails to make good predictions - a marker of surprise or novelty. Please note that exploring new places is not directly articulated in ICM curiosity. For ICM, visiting them is only a way to get more “surprises” and thus maximize the total reward. As it turns out, in some environments there may be other ways to cause surprise, which leads to unexpected results.
An agent with a curiosity system based on surprise hangs when meeting a TV. Animation from Deepak Patac 's video , used under license CC BY 2.0
The danger of "procrastination"
In the article “Large-scale study of curiosity-based learning,” the authors of the ICM method, together with OpenAI researchers, show the hidden danger of maximizing surprise: agents can learn to indulge in procrastination instead of doing something useful for the task. To understand why this is so, consider a thought experiment, which the authors call the "television noise problem." Here the agent is placed in a labyrinth with the task of finding a very useful item (such as “cheese” in our example). The environment has a TV, and the agent has a remote control. There is a limited number of channels (on each individual program), and each press on the remote switches the TV to a random channel. How will the agent act in such an environment?
If curiosity is formed on the basis of surprise, then changing channels will give more reward, since every change is unpredictable and unexpected. It is important to note that even after a cyclic review of all available channels, random selection of the channel ensures that every new change will still be unexpected - the agent makes a prediction that he will show TV after switching the channel, and most likely the forecast will be wrong, which will cause surprise. It is important to note that even if the agent has already seen every program on every channel, the change is still unpredictable. Because of this, the agent, instead of looking for a very useful item, will eventually remain in front of the TV - it looks like a procrastination. How to change the wording of curiosity to prevent such behavior?
Episodic curiosity
In the article “Episodic curiosity through attainability,” we explore the episodic curiosity model based on memory, which is less prone to receiving instant pleasures. Why is that? If we take the example above, after a while the channel is switched all the programs will eventually end up in memory. Thus, the TV will lose its attractiveness: even if the order of appearance of programs on the screen is random and unpredictable, they are all in memory! This is the main difference from the method based on surprise: our method does not even try to predict the future, it is difficult (or even impossible) to predict it. Instead, the agent studies the past and checks whether there are observations in the memory, likecurrent. Thus, our agent is not inclined to instant pleasures, which are given by “television noise”. The agent will have to go and explore the world outside of TV to get more rewards.
But how do we decide whether the agent sees the same thing that is stored in memory? Checking the exact match is meaningless: in a real environment, an agent rarely sees the same thing twice. For example, even if the agent returns to the same room, he will still see this room from a different angle.
Instead of checking the exact match, we use a deep neural network.who is trained to measure how similar the two experiences are. To train this network, we must guess how closely the observations occurred. The proximity in time is a good indicator of whether two observations should be considered part of the same thing. Such training leads to a general concept of novelty through attainability, which is illustrated below.
Reach graph determines novelty. In practice, this graph is not available - so we train the neural network approximator to estimate the number of steps between observations.
Experimental Results
To compare the performance of different approaches to the description of curiosity, we tested them in two visually rich 3D environments: ViZDoom and DMLab. Under these conditions, the agent was assigned various tasks, such as finding a target in a maze, collecting good objects and evading bad ones. In the DMLab environment, the agent is equipped by default with a fantastic gadget like a laser, but if the gadget is not needed for a specific task, the agent can not use it freely. Interestingly, the ICM agent on the basis of surprise actually used the laser very often, even if it was useless to complete the task! As in the case of TV, instead of searching for a valuable object in the maze, he chose to spend time shooting at the walls, because it gave a lot of reward in the form of surprise. Theoretically, the result of firing on the walls should be predictable, but in practice it is too difficult to predict. This probably requires a deeper knowledge of physics than is available to the standard AI agent.
Based on surprise, an ICM agent continually burns into a wall instead of exploring a labyrinth
. Unlike him, our agent has mastered sensible environmental behavior. This happened because he is not trying to predict the result of his actions, but rather looking for observations that are “farther” from those that are in episodic memory. In other words, the agent implicitly pursues goals that require more effort than a simple shot at the wall.
Our method demonstrates reasonable behavior in environmental studies.
It is interesting to observe how our approach to remuneration punishes an agent running in a circle, because after completing the first round the agent does not encounter new observations and thus does not receive any reward:
The visualization of the reward: red corresponds to a negative reward, Green to a positive one. From left to right: a map with awards, a map with locations in memory, a first-person view
At the same time, our method contributes to a good exploration of the environment:
The visualization of the reward: red corresponds to a negative reward, Green to a positive one. From left to right: an award-winning map, a map with locations in memory, a first-person view.
We hope that our work contributes to a new wave of research that goes beyond the scope of astonishment to teach agents more intelligent behavior. For an in-depth analysis of our method, please take a look at the preprint of scientific work .
Thanks:
This project is the result of a collaboration between the Google Brain team, DeepMind and the Swiss Technical School of Zurich. The main research team: Nikolay Savinov, Anton Raichuk, Raphael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillicrap and Sylvain Zheli. We wanted to thank Olivier Pietkina, Carlos Riquelme, Charles Blundell and Sergei Levine for discussing this document. We are grateful to Indira Pasco for helping with the illustrations.
References to the literature:
[1] “Study of the environment on the basis of calculation with models of neural density” , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remi Muñoz
[2] “Study of the environment on the basis of calculation for in-depth training with reinforcement” , Khaoran Tan, Rein Huthuft, Davis Foote, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Tours, Peter Abbel
[3] “Teaching without a teacher how to locate goals for internally motivated research” , Alexander Pere, Sebastien Forestier, Olivier Sego, Pierre-Yves Udeyeh
[4] “VIME: Intelligence with Maximizing Information Changes,” Rein Huthuf t, Xi Chen, Yan Duan, John Shulman, Philippe de Turk, Peter Abbel