Is Postgres NoSQL better than MongoDB?
- Transfer
In general, relational database management systems have been conceived as a “one-size-fits-all solution for storing and receiving data" for decades. But the growing need for scalability and new application requirements have created new challenges for traditional RDBMS management systems, including some dissatisfaction with the one-size-fits-all approach in a number of scalable applications.
The answer to this was a new generation of lightweight, high-performance databases designed to challenge the dominance of relational databases.
The big reason for the NoSQL movement was the fact that different implementations of web, enterprise, and cloud applications have different requirements for their databases.
Example: For bulky sites like eBay, Amazon, Twitter, or Facebook, scalability and high availability are key requirements that cannot be compromised. For these applications, even the smallest disconnection can have significant financial implications and affect customer confidence.
Thus, a ready-made database solution often has to solve not only transactional integrity issues, but moreover, higher data volumes, increased data speed and performance, and a growing variety of formats. New technologies have emerged that specialize in optimizing for one or two of the above aspects, sacrificing others. Postgres with JSON takes a more holistic approach to user needs, successfully solving most NoSQL workloads.
The smart approach of the new technology relies on a close assessment of your needs, with the tools available to meet those needs. The table below compares the characteristics of a non-relational document-oriented database (such as MongoDB) and the characteristics of a Postgres relational / document-oriented database to help you find the right solution for your needs.
Source: EnterpriseDB website.
A document in MongoDB is automatically provided with the _id field if it is not present. When you want to get this document, you can use _id - it behaves exactly like the primary key in relational databases. PostgreSQL stores data in table fields, MongoDB stores it in the form of JSON documents. On the one hand, MongoDB looks like a great solution, since you can have all the different data from multiple tables in PostgreSQL in one JSON document. This flexibility is achieved by the absence of restrictions on the data structure, which can be really attractive at first and really terrifying on a large database in which some records have incorrect values, or empty fields.
PostgreSQL 9.3 comes complete with excellent functionality that allows you to turn it into a NoSQL database, with full transaction support and storage of JSON documents with restrictions on data fields.
I will show how to do this using a very simple example of the Employees table. Each employee has a name, description, a certain id number and salary.
PostgreSQL version
A simple table in PostgreSQL might look like this:
This table allows us to add employees like this:
Alas, the above table allows you to add empty rows without some important values:
This can be avoided by adding restrictions to the database. Suppose we always want to have a non-empty unique name, non-empty description, not a negative salary. Such a constrained table would look:
Now, all operations, such as adding, or updating a record that contradict one of these restrictions, will fall off with an error. Let's check:
NoSQL version
In MongoDB, the entry from the table above will look like the following JSON document:
similarly, in PostgreSQL we can save this record as a row in the emp table:
This works as in most non-relational databases, no checks, no errors with bad fields. As a result, you can transform the data as you want, problems begin when your application expects that the salary is a number, but in fact it is either a line or it is completely absent.
Checking JSON
In PostgreSQL 9.2 there is a good data type for these purposes, it is called JSON. This type can only store the correct JSON, before converting to this type, a validation check is performed.
Let's change the description of the table to:
We can add some valid JSON to this table:
This will work, but adding invalid JSONa will fail:
The formatting problem can be difficult to notice (I added a comma to the last line, JSON doesn't like it).
Checking the fields
So, we have a solution that looks almost like the first pure PostgreSQL solution: we have data that is being checked. This does not mean that the data makes sense. Let's add validations to validate the data. PostgreSQL 9.3 has a new powerful feature for managing JSON objects. There are certain operators for the JSON type that will give you easy access to fields and values. I will only use the " - >> " operator , but you can find more information in the Postgres documentation .
In addition, I need to check the types of fields, including the id field. This is what Postgres simply checks for due to the definition of data types. I will use a different syntax for checks, since I want to give it a name. It will be much easier to search for a problem in a specific field, and not throughout a huge JSON document.
A table with restrictions will look like this:
The operator " - >> " allows me to retrieve a value from the desired JSON field, to check whether it exists and its validity.
Let's add JSON without a description:
There is one more problem. The name and id fields must be unique. This is easily achieved as follows:
Now, if you try to add a JSON document to the database whose id is already in the database, the following error will appear:
Performance
PostgreSQL copes with the most demanding requests of the largest insurance companies, banks, brokers, government agencies, and defense contractors in the world today, as well as managed for many years. PostgreSQL's performance improvements are continuous with the annual release of versions, and include improvements for its unstructured data types as well.
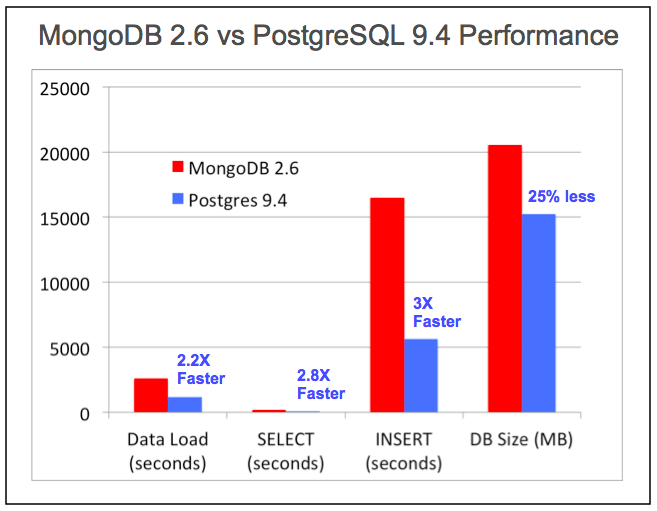
Source: EnterpriseDB White Paper: Using Postgres NoSQL Features
To test PostgreSQL NoSQL performance yourself , download pg_nosql_benchmark from GitHub.
The answer to this was a new generation of lightweight, high-performance databases designed to challenge the dominance of relational databases.
The big reason for the NoSQL movement was the fact that different implementations of web, enterprise, and cloud applications have different requirements for their databases.
Example: For bulky sites like eBay, Amazon, Twitter, or Facebook, scalability and high availability are key requirements that cannot be compromised. For these applications, even the smallest disconnection can have significant financial implications and affect customer confidence.
Thus, a ready-made database solution often has to solve not only transactional integrity issues, but moreover, higher data volumes, increased data speed and performance, and a growing variety of formats. New technologies have emerged that specialize in optimizing for one or two of the above aspects, sacrificing others. Postgres with JSON takes a more holistic approach to user needs, successfully solving most NoSQL workloads.
Comparison of document-oriented / relational databases
The smart approach of the new technology relies on a close assessment of your needs, with the tools available to meet those needs. The table below compares the characteristics of a non-relational document-oriented database (such as MongoDB) and the characteristics of a Postgres relational / document-oriented database to help you find the right solution for your needs.
| Features | Mongodb | PostgreSQL |
| Start of Open Source Development | 2009 | 1995 |
| Scheme | Dynamic | Static and dynamic |
| Hierarchical Data Support | Yes | Yes (since 2012) |
| Key-event data support | Yes | Yes (since 2006) |
| Support for relational data / normalized form storage | Not | Yes |
| Data limitations | Not | Yes |
| Data federation and foreign keys | Not | Yes |
| Powerful query language | Not | Yes |
| Transaction Support and Competitive Access Management with Multiple Versions | Not | Yes |
| Atomic Transactions | Inside the document | Throughout the base |
| Supported Web Development Languages | JavaScript, Python, Ruby, and others ... | JavaScript, Python, Ruby, and others ... |
| Support for common data formats | JSON (Document), Key-Value, XML | JSON (Document), Key-Value, XML |
| Spatial data support | Yes | Yes |
| The easiest way to scale | Horizontal scaling | Vertical Scaling |
| Sharding | Plain | Complicated |
| Server side programming | Not | Many procedural languages such as Python, JavaScript, C, C ++, Tcl, Perl and many, many others |
| Easy integration with other data sources | Not | External data collectors from Oracle, MySQL, MongoDB, CouchDB, Redis, Neo4j, Twitter, LDAP, File, Hadoop and others ... |
| Business logic | Distributed by client applications | Centralized with triggers and stored procedures, or distributed across client applications |
| Learning Resource Availability | Difficult to find | Easy to find |
| Primary use | Big data (billions of records) with lots of concurrent updates where data integrity and consistency are not required. | Transactional and operational applications, the benefits of which are in a normalized form, associations, data restrictions and transaction support. |
Source: EnterpriseDB website.
A document in MongoDB is automatically provided with the _id field if it is not present. When you want to get this document, you can use _id - it behaves exactly like the primary key in relational databases. PostgreSQL stores data in table fields, MongoDB stores it in the form of JSON documents. On the one hand, MongoDB looks like a great solution, since you can have all the different data from multiple tables in PostgreSQL in one JSON document. This flexibility is achieved by the absence of restrictions on the data structure, which can be really attractive at first and really terrifying on a large database in which some records have incorrect values, or empty fields.
PostgreSQL 9.3 comes complete with excellent functionality that allows you to turn it into a NoSQL database, with full transaction support and storage of JSON documents with restrictions on data fields.
Simple example
I will show how to do this using a very simple example of the Employees table. Each employee has a name, description, a certain id number and salary.
PostgreSQL version
A simple table in PostgreSQL might look like this:
CREATETABLE emp (
idSERIAL PRIMARY KEY,
nameTEXT,
description TEXT,
salary DECIMAL(10,2)
);
This table allows us to add employees like this:
INSERTINTO emp (name, description, salary) VALUES ('raju', ' HR', 25000.00);
Alas, the above table allows you to add empty rows without some important values:
INSERTINTO emp (name, description, salary) VALUES (null, -34, 'sdad');
This can be avoided by adding restrictions to the database. Suppose we always want to have a non-empty unique name, non-empty description, not a negative salary. Such a constrained table would look:
CREATETABLE emp (
idSERIAL PRIMARY KEY,
nameTEXTUNIQUENOTNULL,
description TEXTNOTNULL,
salary DECIMAL(10,2) NOTNULL,
CHECK (length(name) > 0),
CHECK (description ISNOTNULLANDlength(description) > 0),
CHECK (salary >= 0.0)
);
Now, all operations, such as adding, or updating a record that contradict one of these restrictions, will fall off with an error. Let's check:
INSERTINTO emp (name, description, salary) VALUES ('raju', 'HR', 25000.00);
--INSERT 0 1INSERTINTO emp (name, description, salary) VALUES ('raju', 'HR', -1);
--ERROR: new row for relation "emp" violates check constraint "emp_salary_check"--DETAIL: Failing row contains (2, raju, HR, -1).NoSQL version
In MongoDB, the entry from the table above will look like the following JSON document:
{
"id": 1,
"name": "raju",
"description": "HR,
"salary": 25000.00
}
similarly, in PostgreSQL we can save this record as a row in the emp table:
CREATETABLE emp (
dataTEXT
);
This works as in most non-relational databases, no checks, no errors with bad fields. As a result, you can transform the data as you want, problems begin when your application expects that the salary is a number, but in fact it is either a line or it is completely absent.
Checking JSON
In PostgreSQL 9.2 there is a good data type for these purposes, it is called JSON. This type can only store the correct JSON, before converting to this type, a validation check is performed.
Let's change the description of the table to:
CREATETABLE emp (
dataJSON
);
We can add some valid JSON to this table:
INSERTINTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"salary": 25000.00
}');
--INSERT 0 1SELECT * FROM emp;
{ +
"id": 1, +
"name": "raju", +
"description": "HR",+
"salary": 25000.00 +
}
--(1 row)This will work, but adding invalid JSONa will fail:
INSERTINTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"price": 25000.00,
}');
--ERROR: invalid input syntax for type jsonThe formatting problem can be difficult to notice (I added a comma to the last line, JSON doesn't like it).
Checking the fields
So, we have a solution that looks almost like the first pure PostgreSQL solution: we have data that is being checked. This does not mean that the data makes sense. Let's add validations to validate the data. PostgreSQL 9.3 has a new powerful feature for managing JSON objects. There are certain operators for the JSON type that will give you easy access to fields and values. I will only use the " - >> " operator , but you can find more information in the Postgres documentation .
In addition, I need to check the types of fields, including the id field. This is what Postgres simply checks for due to the definition of data types. I will use a different syntax for checks, since I want to give it a name. It will be much easier to search for a problem in a specific field, and not throughout a huge JSON document.
A table with restrictions will look like this:
CREATETABLE emp (
dataJSON,
CONSTRAINT validate_id CHECK ((data->>'id')::integer >= 1AND (data->>'id') ISNOTNULL ),
CONSTRAINT validate_name CHECK (length(data->>'name') > 0AND (data->>'name') ISNOTNULL )
);
The operator " - >> " allows me to retrieve a value from the desired JSON field, to check whether it exists and its validity.
Let's add JSON without a description:
INSERTINTO emp(data) VALUES('{
"id": 1,
"name": "",
"salary": 1.0
}');
--ERROR: new row for relation "emp" violates check constraint "validate_name"There is one more problem. The name and id fields must be unique. This is easily achieved as follows:
CREATEUNIQUEINDEX ui_emp_id ON emp((data->>'id'));
CREATEUNIQUEINDEX ui_emp_name ON emp((data->>'name'));
Now, if you try to add a JSON document to the database whose id is already in the database, the following error will appear:
--ERROR: duplicate key value violates unique constraint "ui_emp_id"--DETAIL: Key ((data ->> 'id'::text))=(1) already exists.--ERROR: current transaction is aborted, commands ignored until end of transaction blockPerformance
PostgreSQL copes with the most demanding requests of the largest insurance companies, banks, brokers, government agencies, and defense contractors in the world today, as well as managed for many years. PostgreSQL's performance improvements are continuous with the annual release of versions, and include improvements for its unstructured data types as well.
Source: EnterpriseDB White Paper: Using Postgres NoSQL Features
To test PostgreSQL NoSQL performance yourself , download pg_nosql_benchmark from GitHub.