DDD, Hexagonal, Onion, Clean, CQRS ... how I put it all together
- Transfer

This article is part of the Software Architecture Chronicle , a series of articles on software architecture. In them I write about what I learned about software architecture, what I think about it and how I use knowledge. The content of this article may make more sense if you read the previous articles in the series.
After graduation, I started working as a high school teacher, but a few years ago I quit my job and went to software developers for a full-time job.
Since then, I have always felt that I need to recover “lost” time and learn as much as possible, as quickly as possible. Therefore, I began to take a little interest in experiments, read a lot and write, paying special attention to software design and architecture. That is why I write these articles to help me learn.
In the last articles I talked about many concepts and principles that I learned, and a little about how I talk about them. But I imagine them as fragments of one big puzzle.
This article is about how I put together all these fragments. I think I should give them a name, so I’ll call them explicit architecture . In addition, all these concepts are “tested in combat” and are used in production on highly reliable platforms. One of them is a SaaS e-commerce platform with thousands of online stores around the world, the other is a marketplace operating in two countries with a message bus that processes more than 20 million messages per month.
- Fundamental system blocks
- Instruments
- Connecting tools and delivery mechanisms to the application core
- Application core organization
- Components
- Control flow
Fundamental system blocks
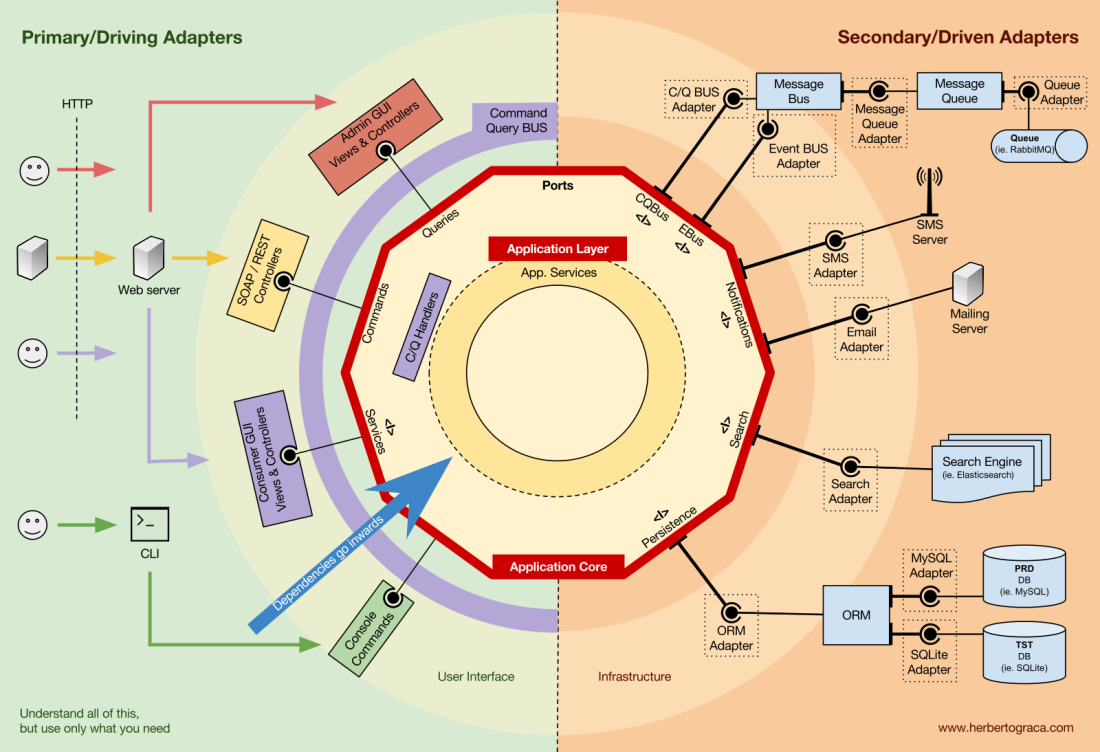
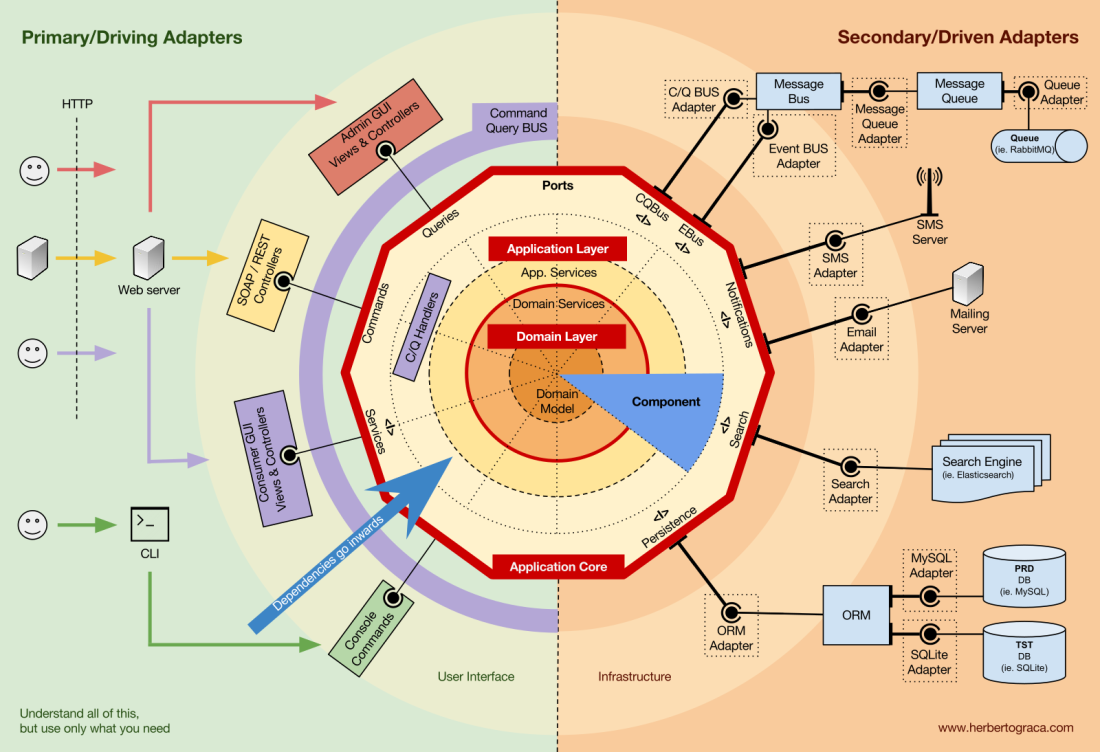
Let's start with the fact that we recall the architecture of EBI and Ports & Adapters . Both of them clearly separate the internal and external application code, as well as adapters for connecting the internal and external code.
In addition, the Ports & Adapters architecture explicitly defines three fundamental blocks of code in the system:
- That allows you to run the user interface , regardless of its type.
- System business logic or application core . It is used by UI for making real transactions.
- Infrastructure code that connects the core of our application with tools such as a database, search engine, or third-party APIs.
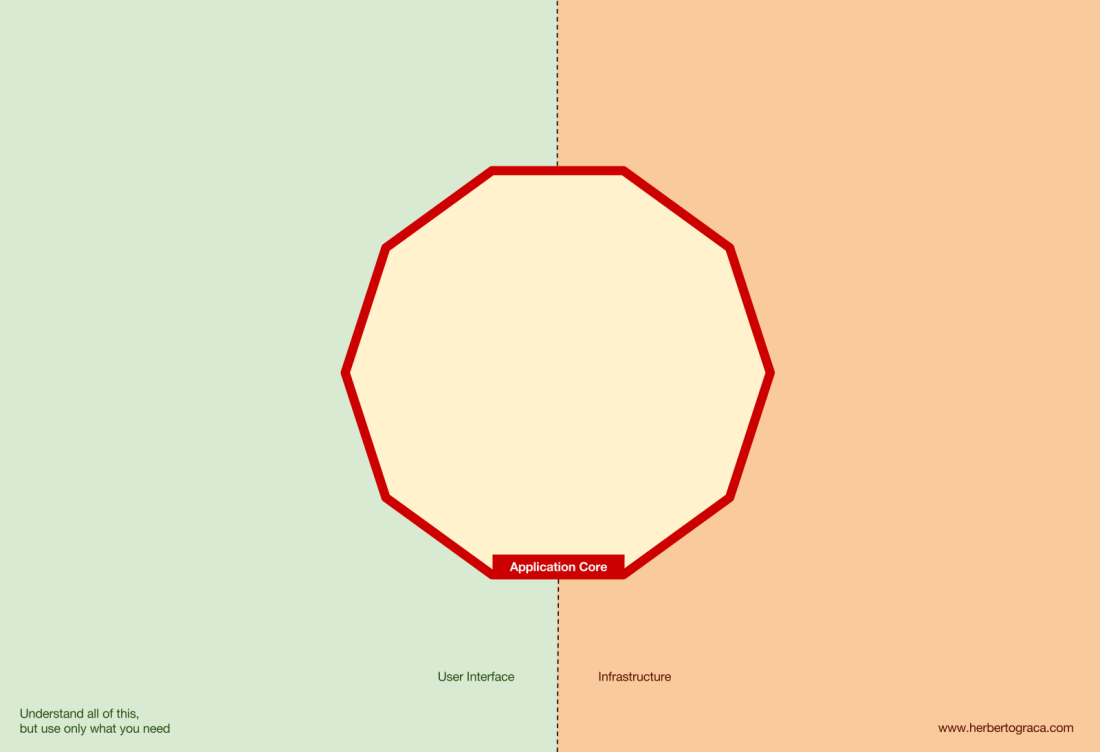
The core of the application is the most important thing to think about. This code allows you to perform real actions in the system, that is, this is our application. Multiple user interfaces can work with it (progressive web application, mobile application, CLI, API, etc.), everything is performed on one core.
As you can imagine, a typical execution flow comes from the code in the UI through the application core to the infrastructure code, back to the application core, and finally the answer is delivered to the UI.

Instruments
Far from the most important kernel code, there are more tools that the application uses. For example, the database engine, search engine, web server, and CLI console (although the latter two are also delivery mechanisms). It seems strange to include the CLI console in the same thematic section as the DBMS, because they have a different purpose. But in fact, both are tools used by the application. The key difference is that the CLI console and the web server tell the application to do something , the database engine, on the contrary, receives commands from the application . This is a very important distinction, because it greatly influences the way we write code to connect these tools to the application core.
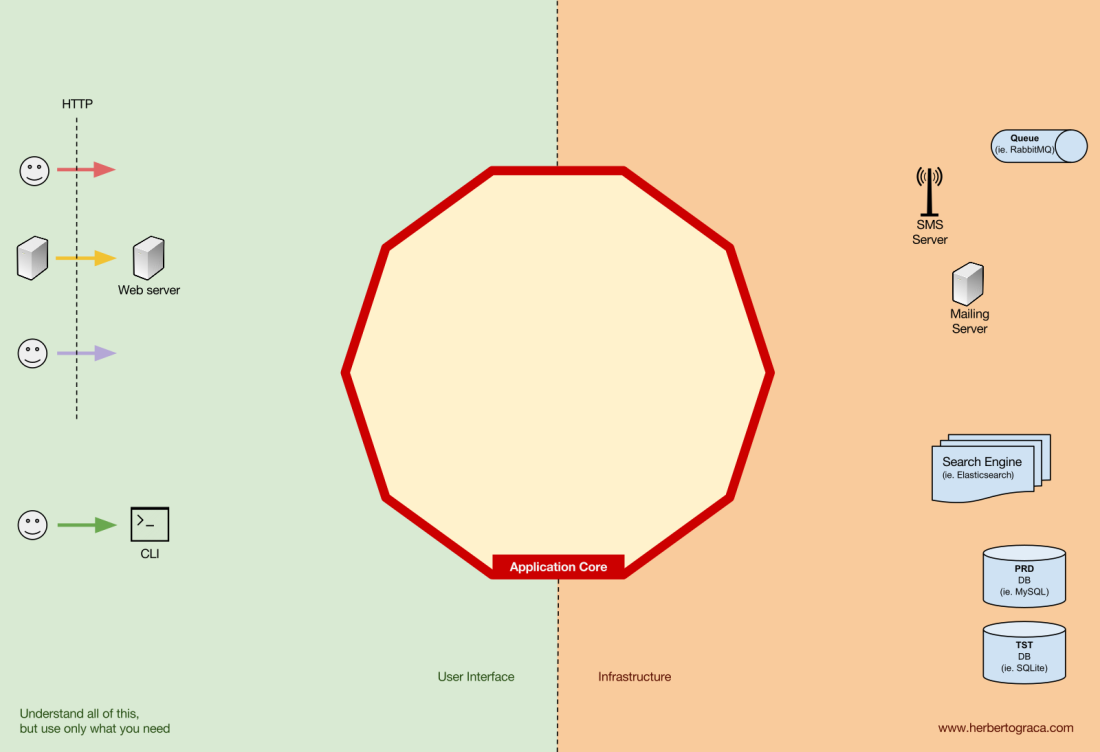
Connecting tools and delivery mechanisms to the application core
The blocks of code connecting the tools to the application kernel are called adapters ( Ports & Adapters architecture ). They allow business logic to interact with a specific tool, and vice versa.
Adapters that tell an application to do something are called primary or control adapters , while adapters that tell an application something to do are called secondary or managed adapters .
Ports
However, these adapters are not created by chance, but in order to correspond to a specific entry point into the application kernel, a port . A port is nothing more than a specification of how a tool can use the core of an application or vice versa. In most languages and in the simplest form, this port will be an interface, but in fact it can be composed of several interfaces and DTO.
It is important to note that the ports (interfaces) are inside the business logic , and the adapters are outside. For this pattern to work properly, it is extremely important to create ports in accordance with the needs of the application core, and not just simulate the tools API.
Basic or Control Adapters
Basic or control adapters wrap around the port and use it to tell the application kernel what to do. They convert all the data from the delivery mechanism into method calls in the application core. In other words, our control adapters are controllers or console commands; they are embedded in their constructor with some object whose class implements the interface (port) that the controller or console command requires. In a more specific example, the port may be a service interface or a repository interface that is required by the controller. The specific implementation of the service, repository, or request is then implemented and used in the controller.
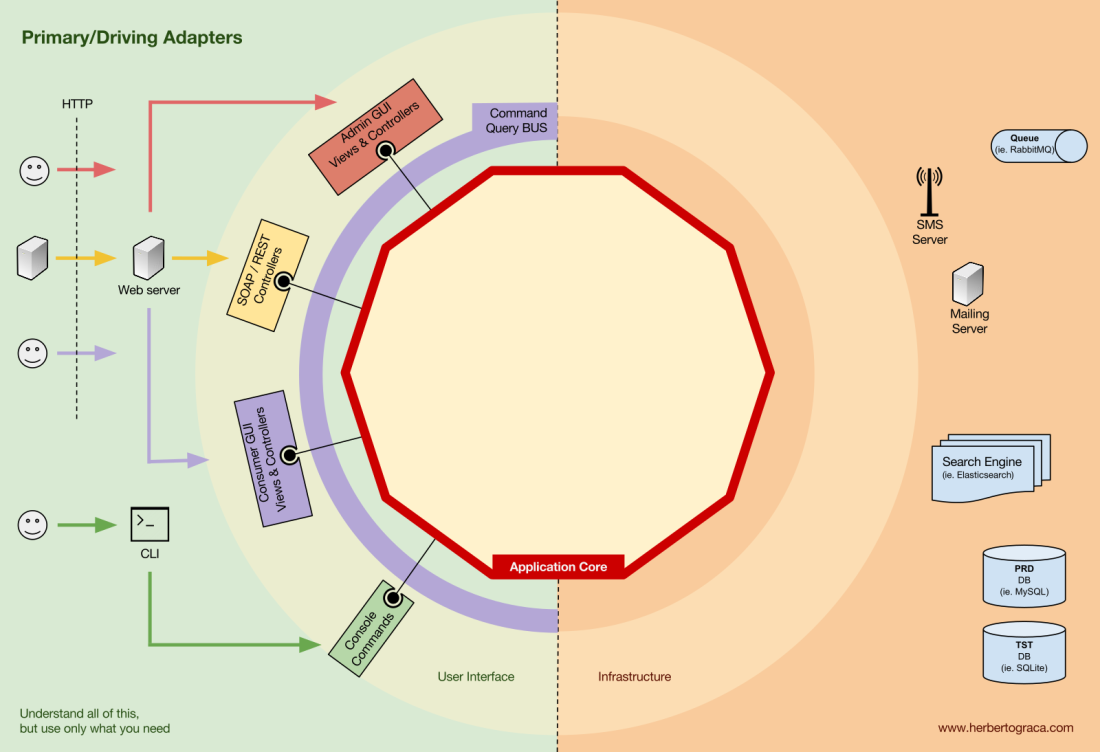
In addition, a port can be a command bus or a query bus interface. In this case, a specific implementation of a command or request bus is entered into the controller, which then creates a command or request and sends it to the appropriate bus.
Secondary or managed adapters
Unlike control adapters, which are wrapped around a port, managed adapters implement the port, interface, and then are entered into the application kernel where the port is required (with an indication of the type). For example, we have a native application that needs to save data. We create a persistence-interface with a method of saving an array of data and a method of deleting a row in a table by its ID. From now on, wherever the application has to save or delete data, we will require in the constructor an object that implements the persistence interface that we defined.

Now we create an adapter specific to MySQL that will implement this interface. It will have methods to save the array and delete the row in the table, and we will enter it wherever a persistence interface is required.
If at some point we decide to change the database provider, for example, to PostgreSQL or MongoDB, we just need to create a new adapter that implements the PostgreSQL-specific persistence interface and implement the new adapter instead of the old one.
Inversion of control
A characteristic feature of this template is that the adapters depend on the specific tool and the specific port (by implementing the interface). But our business logic depends only on the port (interface), which is designed to meet the needs of business logic and does not depend on the specific adapter or tool. This means that dependencies are directed to the center, that is, there is an inversion of the principle of control at the architectural level . Although again, it is extremely important that the ports are created in accordance with the needs of the application core, and not just imitated the tools API .
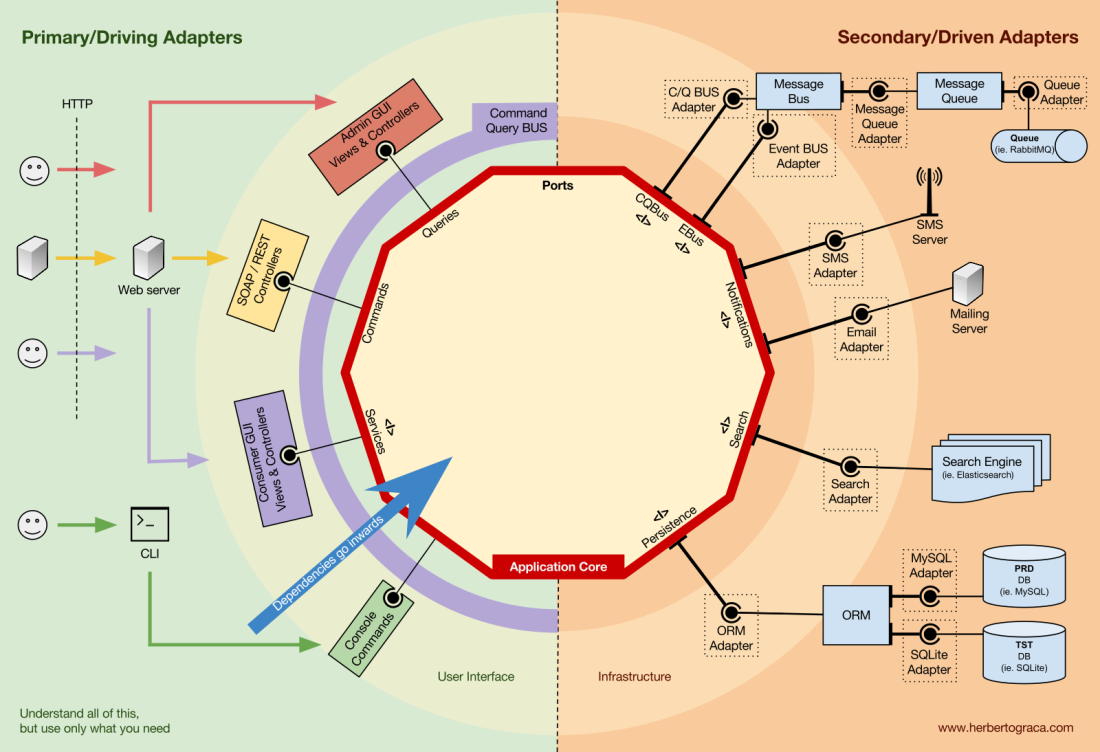
Application core organization
The Onion architecture picks up DDD layers and incorporates them into the ports and adapters architecture . These levels are designed to bring some order into the business logic, the inner part of the “hexagon” of ports and adapters. As before, the direction of dependencies is towards the center.
Application Level (Application Level)
Use cases are processes that can be run in the kernel with one or more user interfaces. For example, in a CMS there may be one UI for regular users, another independent UI for CMS administrators, another CLI and a web API. These UIs (applications) can initiate unique or common use cases.
Use cases are defined at the application level - the first level of DDD and Onion architecture.
This layer contains application services (and their interfaces) as first-class objects, and also contains port and adapter interfaces (ports), which include ORM interfaces, search engine interfaces, messaging interfaces, etc. In the case where we use command bus and / or query bus, at this level are the appropriate command and query handlers.
Application services and / or command handlers contain the logic for deploying a use case, a business process. As a rule, their role is as follows:
- use the repository to search for one or more entities;
- ask these entities to perform some domain logic;
- and use the repository to re-save entities, effectively saving changes to the data.
Command handlers can be used in two ways:
- They may contain logic to execute a use case;
- They can be used as simple parts of a connection in our architecture that receive a command and simply call logic that exists in the application service.
Which approach to use depends on the context, for example:
- We already have application services and are now adding a command bus?
- Does the command bus allow you to specify a class / method as a handler, or do you need to extend or implement existing classes or interfaces?
This level also contains the initiation of application events , which are some result of a use case. These events trigger logic, which is a side effect of a use case, such as sending emails, notifying third-party APIs, sending push notifications, or even launching another use case belonging to another component of the application.
Domain Level
Further inside there is a domain level. Objects at this level contain data and logic for managing this data, which are specific for the domain itself and do not depend on the business processes that run this logic. They are independent and completely unaware of the application layer.
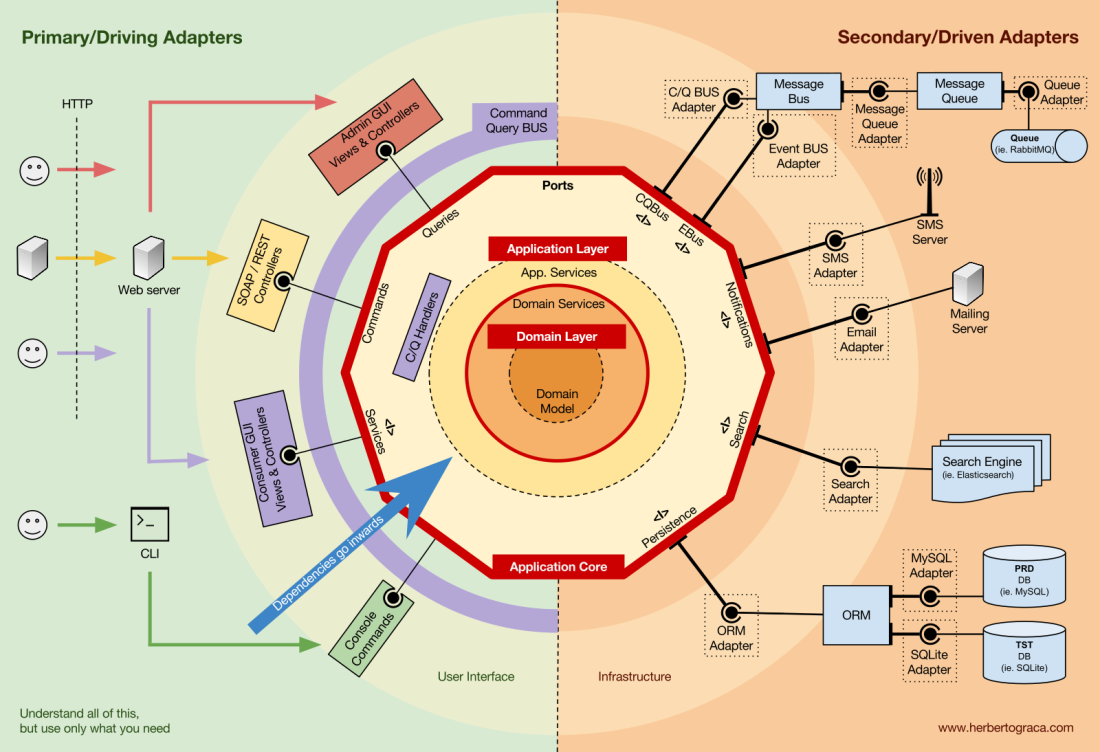
Domain Services
As I mentioned above, the application service role:
- use the repository to search for one or more entities;
- ask these entities to perform some domain logic;
- and use the repository to re-save entities, effectively saving changes to the data.
But sometimes we encounter some domain logic, which includes different entities of the same or different types, and this domain logic does not belong to the entities, that is, the logic is not their direct responsibility.
Therefore, our first reaction may be to place this logic outside the entities in the application service. However, this means that in other cases the domain logic will not be reused: the domain logic must remain outside the application level!
The solution is to create a domain service, the role of which is to get a set of entities and execute some business logic on them. The domain service belongs to the domain level and therefore does not know anything about classes at the application level, such as application services or repositories. On the other hand, it can use other domain services and, of course, domain model objects.
Domain Model
In the center is the domain model. It does not depend on anything outside this circle and contains business objects representing something in the domain. Examples of such objects are, first of all, entities, as well as value-object (value objects), enums, and any objects used in the domain model.
Domain events also live in the domain model. When a particular data set is changed, these events are triggered, which contain new values of the changed properties. These events are ideal, for example, for use in an event sourcing module.
Components
So far, we have isolated the code by layers, but this is too detailed isolation of the code. It is equally important to look at the picture with a more general view. We are talking about the separation of code by subdomains and related contexts in accordance with the ideas of Robert Martin, expressed in the screaming architecture [that is, the architecture should “shout” about the application itself, and not about what frameworks it uses - approx. trans.]. Here they talk about the organization of packages by function or by component, not by layers, and Simon Brown explained this quite well in the article “Component packages and testing in accordance with the architecture” in his blog: I am a supporter of organizing packages by components and I want to change Simon Brown's diagram as follows:
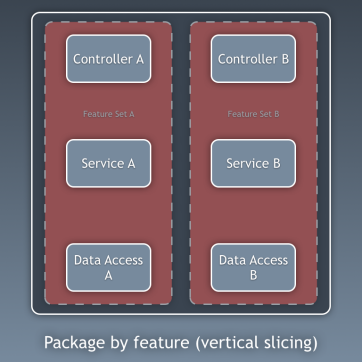
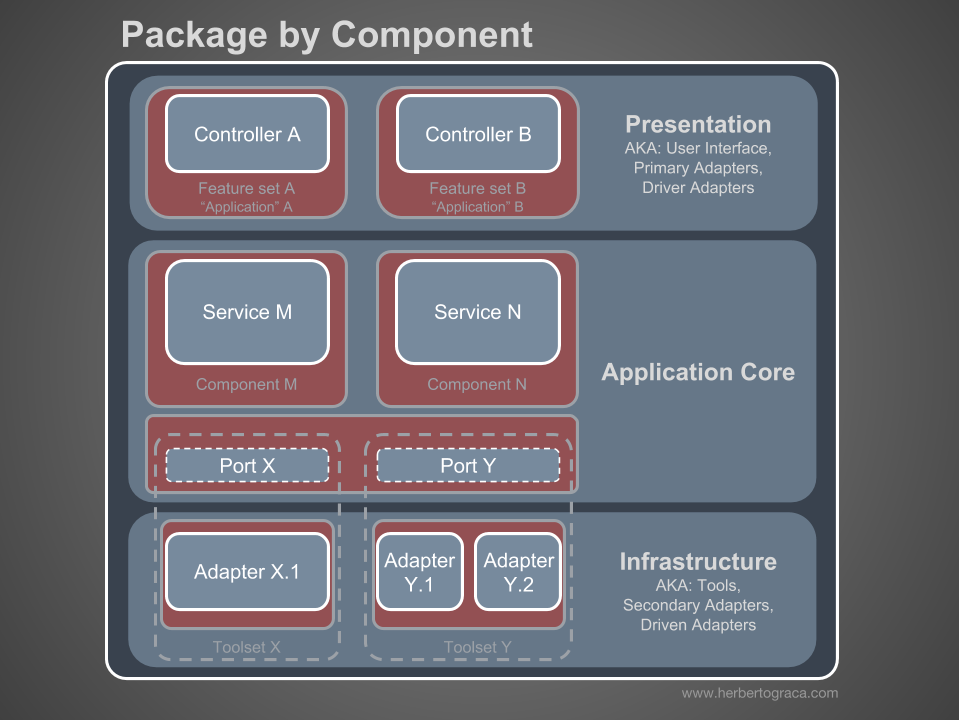
These sections of the code are pass-through for all layers described earlier, and these are components of our application. Examples of components are billing, user, verification, or account, but they are always associated with a domain. Restricted contexts, such as authorization and / or authentication, should be treated as external tools for which we create an adapter and hide behind a port.
Separation of components
Just as in fine-grained code units (classes, interfaces, treit, mixins, etc.), large units (components) benefit from weak coupling and tight connectivity.
To separate classes, we use dependency injection, introducing dependencies into the class, rather than creating them inside the class, as well as dependency inversion, making the class dependent on abstractions (interfaces and / or abstract classes) instead of concrete classes. This means that the dependent class knows nothing about the specific class that it will use, it does not have a reference to the full name of the classes on which it depends.
Similarly, in a fully decoupled component, each component knows nothing about any other component. In other words, it has no reference to any fine-grained block of code from another component, even the interface! This means that dependency injection and dependency inversion are not enough to separate the components, we need some kind of architectural design. Events, common core, eventual consistency, and even a discovery service may be needed!
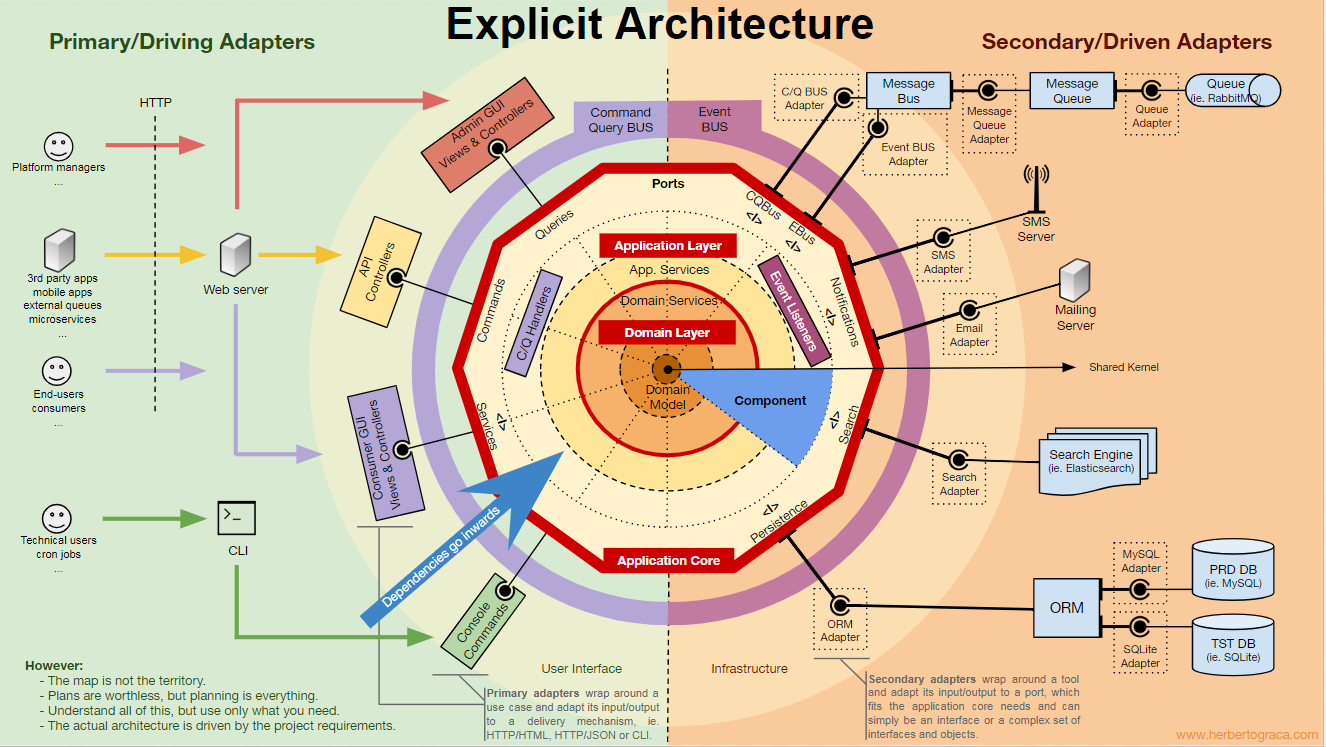
Triggering logic in other components
When one of our components (component B) has to do something whenever something else happens in another component (component A), we cannot simply make a direct call from component A to the class / method of component B, because then A will be associated with B.
However, we can use the event dispatcher to send an application event that will be delivered to any component that listens on it, including B, and the event listener in B will trigger the desired action. This means that component A will depend on the event dispatcher, but will be separated from component B.
However, if the event itself “lives” in A, this means that B knows about A and is associated with it. To remove this dependency, we can create a library with a set of application core functionality that will be shared among all components — a common core.. This means that both components will depend on a common core, but will be separated from each other. The common kernel contains functionality, such as application and domain events, but it can also contain specification objects and everything that makes sense to share. However, it should be the minimum size, because any changes in the common core will affect all components of the application. In addition, if we have a polyglot system, say, an ecosystem of microservices in different languages, then the common core should not depend on the language so that all components understand it. For example, instead of a common kernel with an event class, it would contain a description of the event (that is, the name, properties, perhaps even methods, although they would be more useful in the specification object) in a universal language like JSON,
This approach works in both monolithic and distributed applications, such as microservice ecosystems. But if events can only be delivered asynchronously, then this approach is not sufficient for contexts where the launch logic in other components should work immediately! Here, component A will need to make a direct HTTP call to component B. In this case, in order to disconnect the components, we need a discovery service. Component A will ask her where to send the request to initiate the desired action. Alternatively, make a request to the discovery service, which will forward it to the appropriate service and eventually return a response to the initiator of the request. This approach links components to the discovery service, but does not link them to each other.
Retrieving data from other components
As I see it, a component is not allowed to change data that it does not “own”, but it can request and use any data.
Shared Data Warehouse for Components
If a component must use data belonging to another component (for example, the billing component must use the client's name that belongs to the accounts component), then it contains the request object to the data storage. That is, the billing component can be aware of any data set, but must use “other people's” data read-only.
Separate data storage for a component
In this case, the same pattern applies, but the data storage level becomes more difficult. The presence of components with their own data storage means that each data warehouse contains:
- The data set that the component owns and can change, making it the only source of truth;
- A data set that is a copy of the data of other components that it cannot change by itself, but they are necessary for the functionality of the component. This data must be updated whenever it changes in the owner component.
Each component will create a local copy of the data it needs from other components, which will be used as needed. When data changes in the component to which it belongs, this owner component triggers a domain event that carries data changes. Components containing a copy of this data will listen to this domain event and update their local copy accordingly.
Control flow
As I said above, the control flow goes from the user to the application core, to the infrastructure tools, then back to the application core - and back to the user. But how exactly do classes work together? Who depends on whom? How do we make them?
As Uncle Bob in his article on Clean Architecture, I will try to explain the flow of control of UMLish schemes ...
No command / query bus
If we do not use the command bus, the controllers will depend either on the application service or on the Query object.
[Addition 18.11.2017] I completely missed the DTO, which I use to return data from the request, so now I added it. Thank MorphineAdministered , which have a space. In the diagram above, we use the interface for the application service, although we can say that it is not really needed, because the application service is part of our application code. But we do not want to change the implementation, although we can conduct a full refactoring.

The Query object contains an optimized query that simply returns some raw data that will be shown to the user. This data is returned to the DTO, which is embedded in the ViewModel. This ViewModel can have some kind of View logic and will be used to populate the View.
On the other hand, the application service contains the logic of use cases, which works when we want to do something in the system, and not just view some data. The application service depends on repositories that return entities that contain the logic that needs to be initiated. It may also depend on the domain service to coordinate the domain process in several entities, but this is a rare case.
After analyzing the use case, the application service can notify the entire system that the use case has occurred, then it will still depend on the event dispatcher to trigger the event.
It is interesting to note that we place interfaces both on the persistence engine and on repositories. This may seem redundant, but they serve different purposes:
- The persistence interface is an abstraction layer over ORM, so that we can change the ORM without changes in the application core.
- The interface repository is an abstraction over by persistence-engine. Suppose we want to switch from MySQL to MongoDB. In this case, the persistence-interface may remain the same, and if we want to continue to use the same the ORM, even keeping the adapter will remain the same. However, the query language is completely different, so we can create a new repository that uses the same mechanism of conservation, implement the same repository interfaces, but build queries using MongoDB query language instead of SQL.
Bus commands / requests
In case our application uses a command / query bus, the diagram remains almost the same, except that the controller now depends on the bus, as well as on commands or queries. An instance of a command or request is created here and passed to the bus, which will find the appropriate handler to receive and process the command.
In the diagram below, the command handler uses the application service. But this is not always necessary, because in most cases the handler will contain all the logic of the use case. We only need to extract the logic from the handler to a separate application service if you need to reuse the same logic in another handler.
[Addition 18.11.2017] I completely missed the DTO, which I use to return data from the request, so now I added it. thankMorphineAdministered , which has a space. You may have noticed that there are no dependencies between the bus, the command, the request and the handlers. In fact, they do not need to know about each other in order to ensure good separation. The way to direct a bus to a specific handler to process a command or request is configured in a simple configuration. In both cases, all arrows — dependencies that intersect the core of the application — point inward. As explained earlier, this is a fundamental rule of the Ports & Adapters architecture, Onion architecture and Clean architecture.
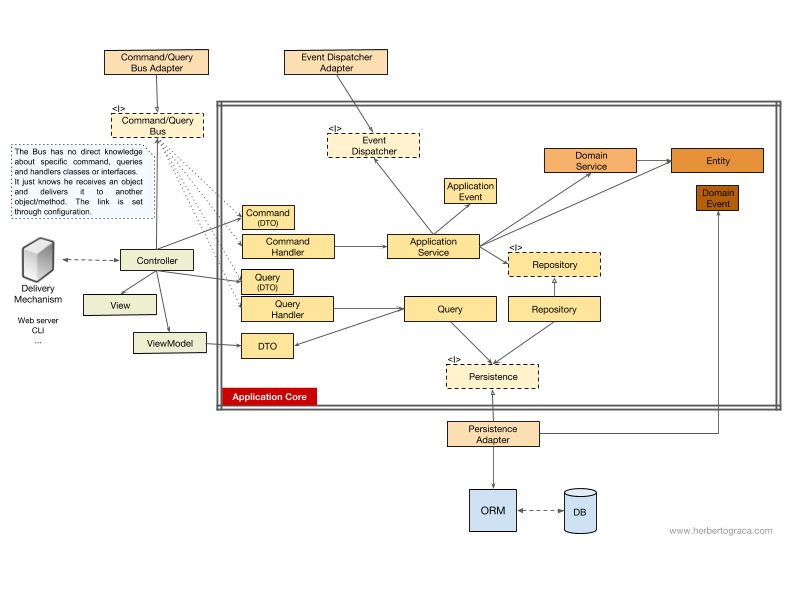

Conclusion
As always, the goal is to get a disconnected code base with high connectivity, in which you can easily, quickly and safely make any changes.
Plans are useless, but planning is everything. - Eisenhower
This infographic is a concept map. Knowing and understanding all these concepts helps you plan a healthy architecture and a workable application.
But:
The map is not a territory. - Alfred Korzybsky
In other words, these are just recommendations! An application is a territory, a reality, a specific use case, where you need to apply our knowledge, and it determines what the real architecture will look like!
We need to understand all these patterns, but also always need to think and understand what our application needs, how far we can go for the sake of disconnection and connectivity. This decision depends on many factors, starting with the functional requirements of the project, to the development time of the application, its service life, the experience of the development team, and so on.
That's how I imagine all this for myself.
These ideas are discussed in more detail in the following article: “More than just concentric layers . ”