Detection of web attacks using autoencoder Seq2Seq
Detection of attacks has been an important task in information security for decades. The first known examples of the implementation of IDS refer to the early 1980s.
A few decades later, a whole industry of attack detection tools was formed. Currently, there are various types of products, such as IDS, IPS, WAF, firewalls, most of which offer detection of rule-based attacks. The idea of using anomaly detection techniques to detect attacks based on production statistics does not seem as realistic as in the past. Or is it? ..
Detection of anomalies in web applications
The first firewalls specifically designed to detect attacks on web applications began to appear on the market in the early 1990s. Since then, both attack methods and defense mechanisms have changed significantly, and attackers can be one step ahead at any time.
Currently, most WAFs attempt to detect attacks as follows: there are some mechanisms based on rules that are built into the reverse proxy server. The most striking example is mod_security, a WAF module for the Apache web server, which was developed in 2002. Detection of attacks using rules has several disadvantages; for example, the rules cannot detect zero-day attacks, while the same attacks can be easily detected by an expert, and this is not surprising, since the human brain does not work at all like a set of regular expressions.
From the point of view of WAF, attacks can be divided into those that we can detect by the sequence of requests, and those where only one HTTP request (response) is enough to solve. Our research focuses on detecting the latest type of attacks — SQL Injection, Cross Site Scripting, XML External Entities Injection, Path Traversal, OS Commanding, Object Injection, etc.
But first, let's check ourselves.
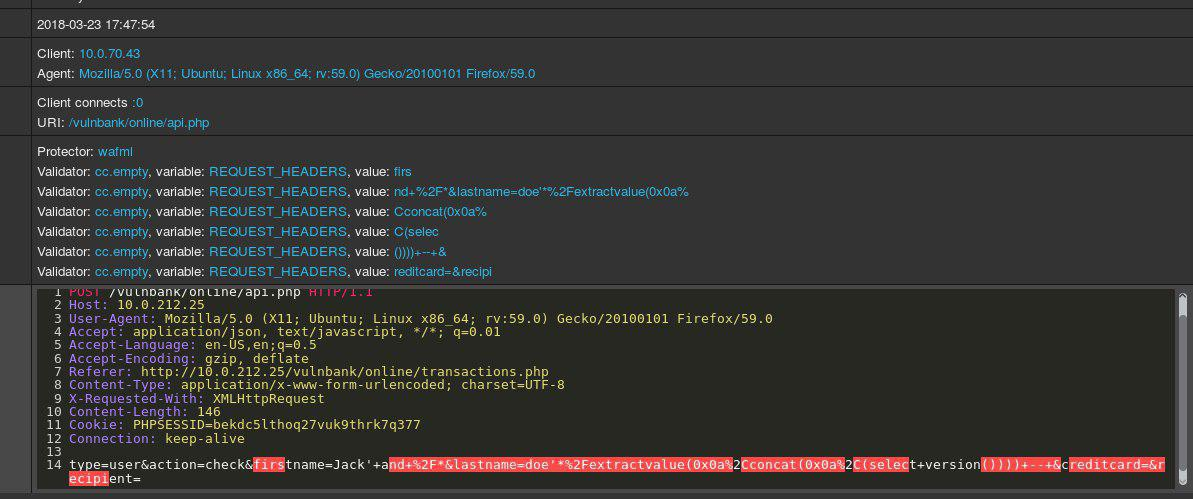
What will the expert think when he sees the following requests?
Take a look at an example of an HTTP request to applications:
If you were given the task of detecting malicious requests to an application, you most likely would like to watch the normal behavior of users for a while. By examining requests to multiple application endpoints, you can get a general overview of the structure and functions of non-dangerous requests.
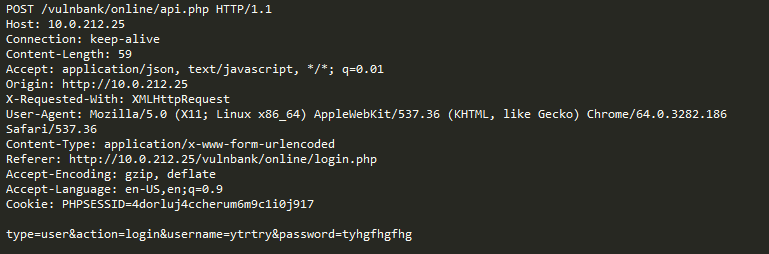
Now you get the following query for analysis:

Immediately striking that there is something wrong. It will take some time to understand what is really there, and once you determine the part of the query that seems abnormal, you can start thinking about what kind of attack this is. In essence, our goal is to make our “AI for detecting attacks” work in the same way — to resemble human thinking.
The unclear point is that some traffic, which at first glance looks malicious, may be normal for a certain website.
For example, let's consider the following queries:
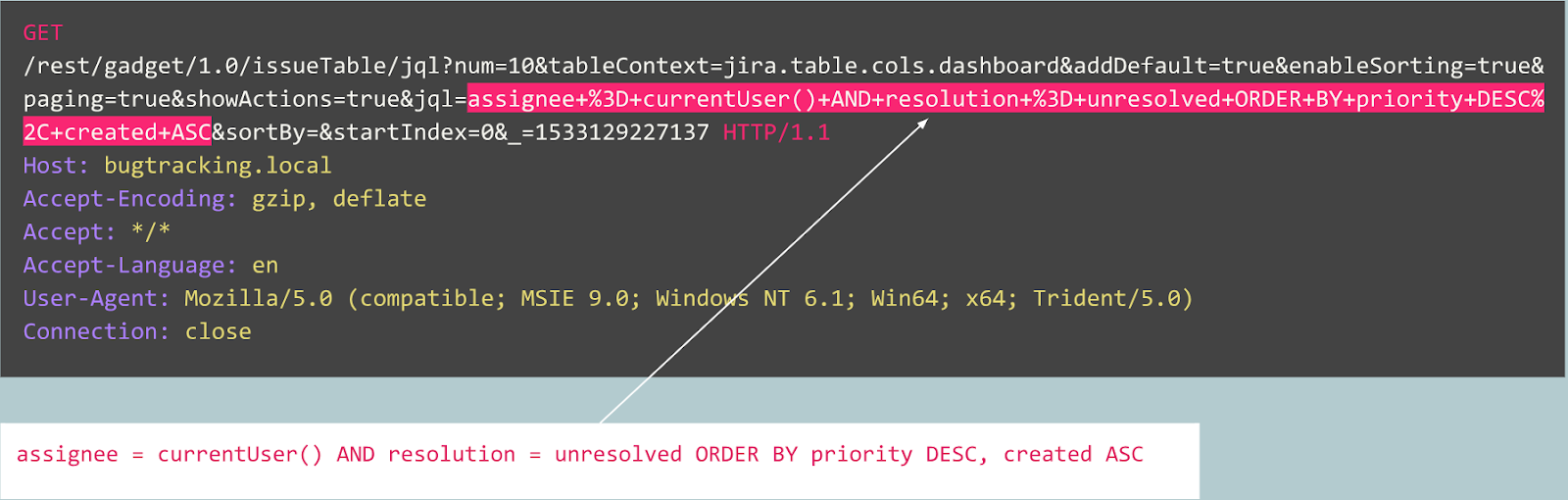
Is this query abnormal?
In fact, this request is a bug in the Jira tracker and is typical for this service, which means that the request is expected and normal.
Now consider the following example:

At first glance, the request looks like a regular user registration on a website based on Joomla CMS. However, the requested operation is user.register instead of regular registration.register. The first option is outdated and contains a vulnerability that allows anyone to register as an administrator. The exploit for this vulnerability is known as Joomla <3.6.4 Account Creation / Privilege Escalation (CVE-2016-8869, CVE-2016-8870).

Where did we start
Of course, we first studied the existing solutions to the problem. Various attempts to create algorithms for detecting attacks based on statistics or machine learning have been made for decades. One of the most popular approaches is to solve the classification problem, when classes represent something like “expected queries”, “SQL injections”, XSS, CSRF, etc. This way you can achieve some good accuracy for a data set using the classifier However, this approach does not solve very important problems from our point of view:
- Class selection is limited and predefined . What if your model in the learning process is represented by three classes, say “normal queries”, SQLi and XSS, and during system operation does it encounter a CSRF or zero-day attack?
- The value of these classes . Suppose you need to protect ten clients, each of which runs completely different web applications. For most of them, you have no idea what SQL injection actually looks like for their application. This means that you have to somehow artificially create data sets for training. This approach is not optimal, because in the end you will learn from data that is different in its distribution from real data.
- Interpretability of model results . Well, the model produced the result “SQL injection”, and now what? You and, more importantly, your client, who sees the warning first and usually is not an expert on web attacks, should guess which part of the query your model considers to be malicious.
Remembering all these problems, we still decided to try to train the model of the classifier.
Since the HTTP protocol is a text protocol, it was obvious that we need to look at modern text classifiers. One well-known example is sentiment analysis in the IMDB film review data set. Some solutions use RNN to classify reviews. We decided to try a similar model with RNN-architecture with some minor differences. For example, in the RNN architecture in natural language, a vector representation of words is used, but it is unclear which words are found in unnatural language, such as HTTP. Therefore, we decided to use the vector representation of symbols for our task.
Finished views do not solve our problem, so we used simple symbol mappings to numeric codes with several internal markers, such as
GOand EOS. After completing the development and testing of the model, all the previously predicted problems became apparent, but at least our team moved from useless assumptions to some result.
What's next?
Next, we decided to take some steps towards interpreting the model results. At some point we came across the attentional mechanism “Attention” and began to implement it in our model. And it gave promising results. Now, our model has begun to display not only class labels, but also attention factors for each character that we have given to the model.
Now we could visualize and show in the web interface the exact place where the “SQL injection” attack was detected. It was a good result, but other problems from the list still remained unresolved.
It was obvious that we should continue to move in the direction of extracting benefits from the mechanism of attention and move away from the task of classification. After reading a lot of related research on sequence models (attentional mechanisms [2], [3], [4], vector representation, autoencoder architectures) and experiments with our data, we were able to create an anomaly detection model, which ultimately would work more or less in the way that the expert does.
Autoencoders
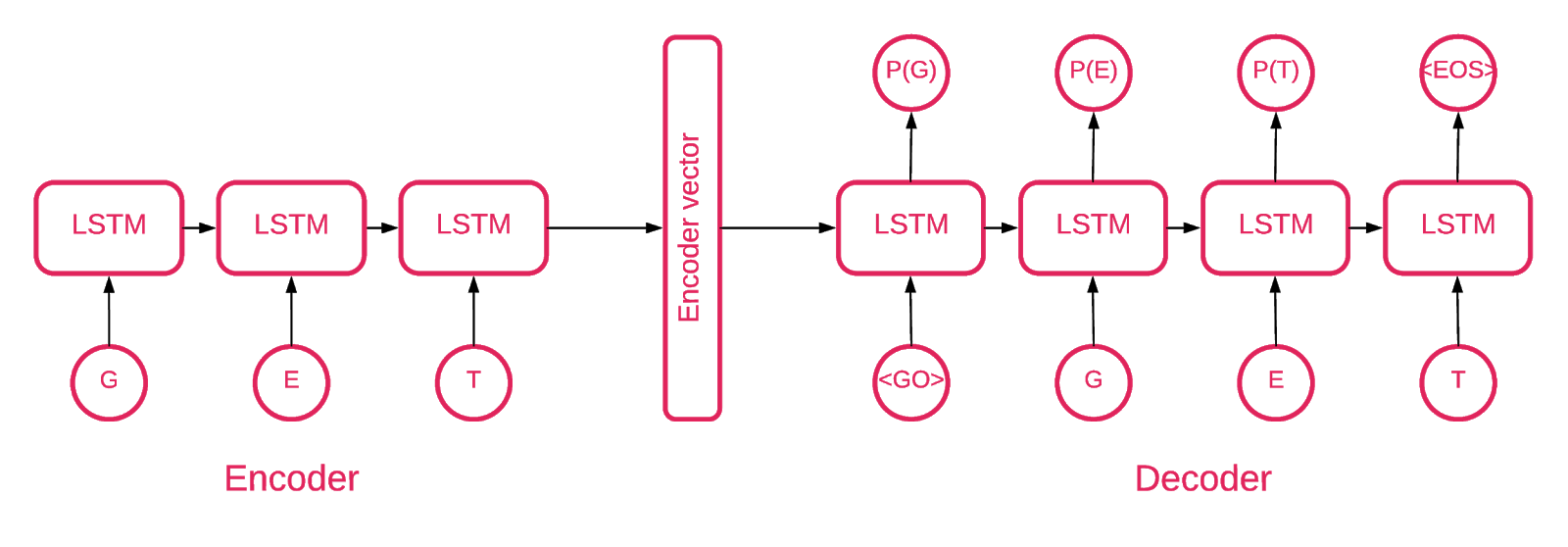
At some point, it became clear that the Seq2Seq [5] architecture is best suited for our task.
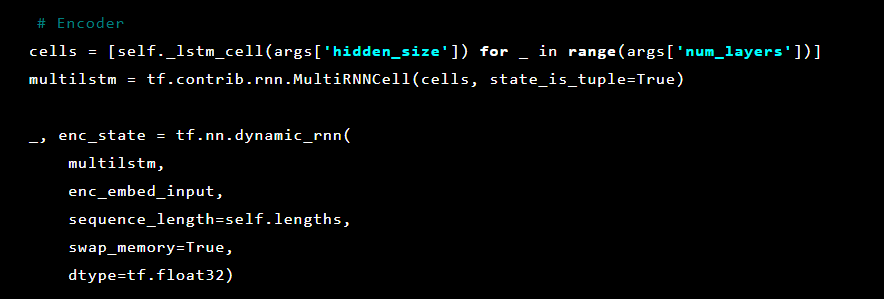
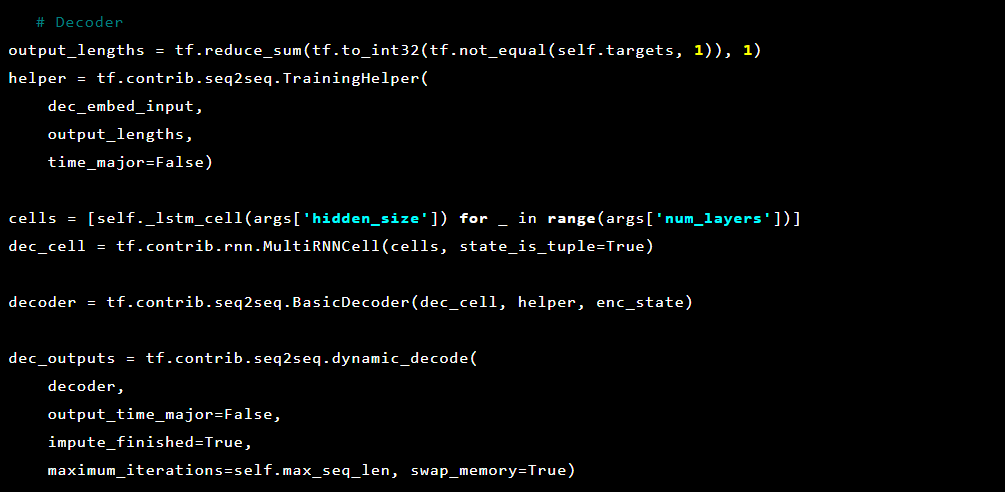
The Seq2Seq model [7] consists of two multilayer LSTM coders and decoders. The encoder maps the input sequence to a fixed-length vector. The decoder decodes the target vector using the encoder output. When learning, an autoencoder is a model in which target values are set the same as input values.
The idea is to teach the network to decode things that it has seen, or, in other words, to approximate the identical mapping. If a trained avtoenkoder give an abnormal pattern, he probably recreates it with a high degree of error, simply because he had never seen it.
Decision
Our solution consists of several parts: model initialization, training, forecasting and testing. Most of the code located in the repository, we hope, does not require explanations, so we will focus only on the important parts.
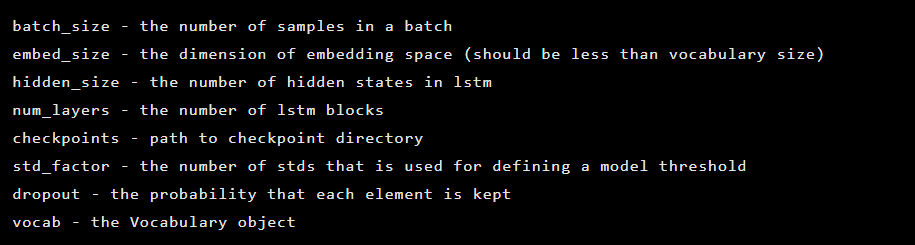
The model is created as an instance of the Seq2Seq class, which has the following constructor arguments:
Next, the autoencoder layers are initialized. First, the encoder:
Then the decoder:
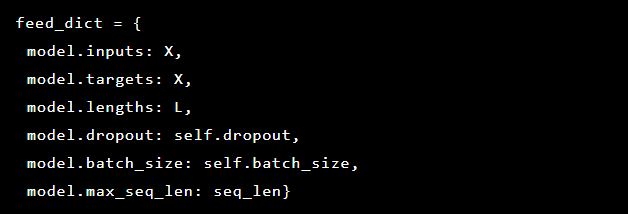
Since the problem that we solve is the detection of anomalies, the target values and the input data are the same. So our feed_dict looks like this:
After each epoch, the best model is saved as a control point, which can then be loaded. For testing purposes, a web application was created that we defended with a model to check whether real attacks were successful.
Inspired by the attentional mechanism, we tried to apply it to the autoencoder model to mark the anomalous parts of this query, but noticed that the probabilities derived from the last layer work better.

At the testing stage in our delayed sample, we got very good results: precision and recall are close to 0.99. And the ROC curve tends to 1. Looks amazing, doesn't it?
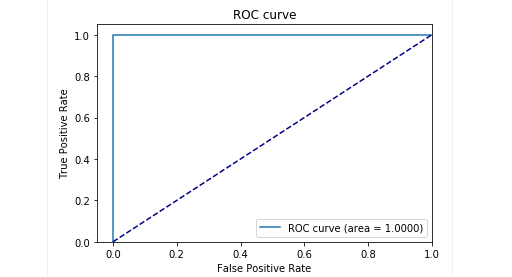
results
The proposed autoencoder model Seq2Seq was able to detect anomalies in HTTP requests with very high accuracy.
This model acts like a person: examines only the "normal" user requests to a web application. And when it detects anomalies in queries, it highlights the exact place of the query, which it considers abnormal.
We tested this model on some attacks on a test application and the results were promising. For example, the image above shows how our model found a SQL injection divided into two parameters in a web form. Such SQL injections are called fragmented: pieces of attack payload are delivered in several HTTP parameters, which makes it difficult to detect for classic WAF based on rules, since they usually check each parameter separately.
The model code and the training and test data are published as a Jupyter laptop so that everyone can reproduce our results and suggest improvements.
Finally
We believe that our task was rather non-trivial. We would like with a minimum of effort spent (first of all - to avoid mistakes due to over-complication of the solution) to come up with a method of detecting attacks, which would learn how to solve what is good and what is bad by magic. In the second place, I wanted to avoid problems with the human factor, when exactly the expert decides what is a sign of an attack and what is not. Summing up, I would like to note that the autoencoder with the Seq2Seq architecture for the task of searching for anomalies, in our opinion and for our problem, handled it perfectly.
We also wanted to solve the problem of data interpretability. Usually using complex neural network architectures make it very difficult. In a series of transformations in the end, it is already difficult to say what it was, what part of the data affected the decision the most. However, after rethinking the approach to the interpretation of the data by the model, it was sufficient for us to obtain the probabilities for each character from the last layer.
It should be noted that this is not quite a production version. We cannot disclose the details of the implementation of this approach into a real product, and we want to warn you that simply taking and integrating this solution into a product will not work.
GitHub repository: goo.gl/aNwq9U
Authors : Alexandra Murzina ( murzina_a ), Irina Stepanyuk (GitHub ), Fedor Sakharov ( GitHub ), Arseny Reutov ( Raz0r )