Using VTune Amplifier 2016 to analyze HelloOpenCL GPU application
- Transfer
VTune Amplifier 2016 can be used to analyze OpenCL programs. In this article, you will learn how to use this solution, as well as how to create a simple OpenCL program called HelloOpenCL using Microsoft Visual Studio and Intel OpenCL code builder.
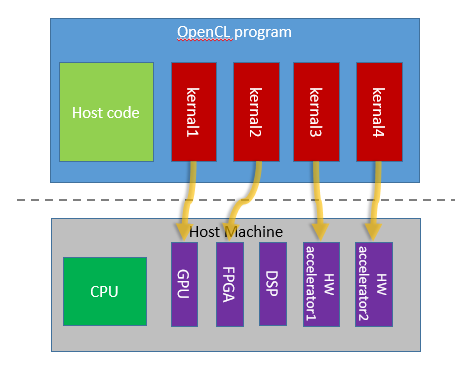
OpenCL is an open standard designed to implement parallel programming on heterogeneous systems, for example, systems with a CPU, GPU, digital signal processors, FPGA and other physical devices. Any OpenCL application usually contains two versions of code: for the host and for the device (“device kernel” or “kernels”). Host APIs contain two types of APIs. Platform APIs are designed to test available devices and their capabilities in order to select and initialize OpenCL devices. Runtime APIs are used to configure and execute kernels on selected devices. To develop code for devices running in the OpenCL runtime, you can use the Intel OpenCL development environment code collector. Different hardware vendors have their own implementation of the OpenCL runtime. Therefore, pay attention to
An analysis of VTune OpenCL will help determine which OpenCL cores spend the most time and how often these cores are called. In addition, copying data between different hardware components also takes some time due to switching the hardware context. At VTune, OpenCL memory read and write metrics help you analyze latency caused by memory access. In the following sections, we will look at creating a simple HelloOpenCL program and using VTune OpenCL analysis with the new architecture schema feature.
Run the first OpenCL program for the GPU - HelloOpenCL
Before you begin developing the HelloOpenCL program, you need to download a number of components. To compile kernel code and verify platform compatibility, you can download the Intel OpenCL code builder contained in the INDE package . Secondly, you need to install the OpenCL runtime implementation on the target device. The Intel OpenCL implementation is part of the Intel graphics package. You can download the driver here . Visit this page for instructions and other download options.
After installing Intel OpenCL code builder, you can check which OpenCL devices it supports. This test target system is equipped with 4th generation Intel® Core ™ processors (Haswell).
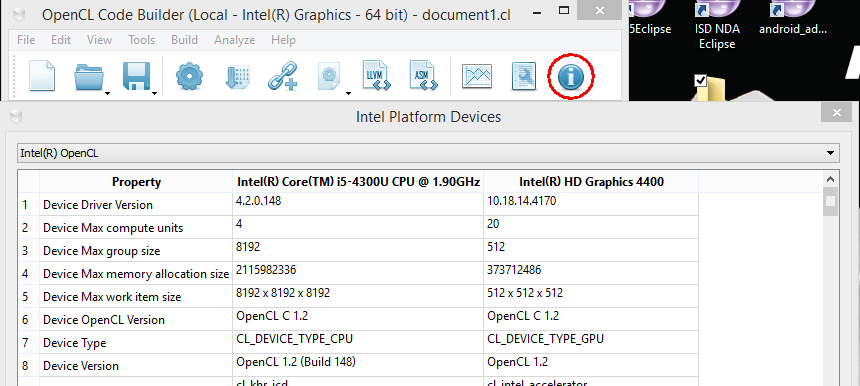
After making sure that the environment supports the necessary OpenCL devices, as shown in the figure above, you can use Microsoft Visual Studio Professional 2013 to create your first OpenCL program using the installed HelloOpenCL template, or use directly the sample code that we included in this article. This sample code asks the GPU to perform a mathematical addition operation on two two-dimensional buffers; the sum are two-dimensional output buffers. Such a scenario can be applied using standard image filters. Here is sample HelloOpenCL code .
Profiling HelloOpenCL with VTune Amplifier 2016
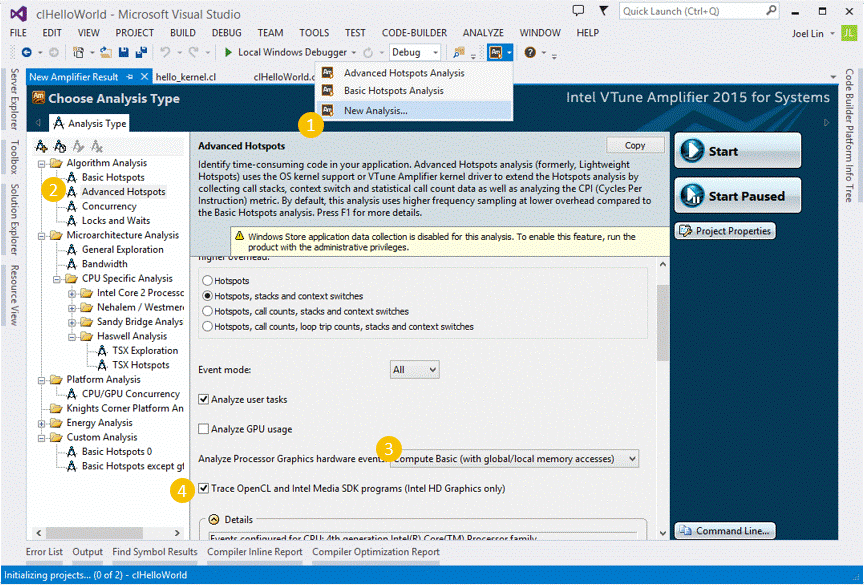
After successfully building the HelloOpenCL program, you can start VTune to profile the application in the Visual Studio development environment. For a detailed description of how to configure OpenCL profiling in VTune, see the following figure.
- Launch VTune in the VS 2013 development environment.
- Select analysis type Advanced Hotspots.
- Select graphics hardware memory access events.
- Select the OpenCL program check box.
After successfully collecting VTune logs, you will see the VTune analysis graph shown below by going to the Graphics tab. For information on the features, see the following pointers.

- VTune contains several group views of the function call list. For the openCL program for the GPU, there is a group view Computing Task Purpose / *, which allows you to better explain the effectiveness of the OpenCL API using metrics that support OpenCL.
- These annotations describe the OpenCL system API codes that run on the CPU side. They also provide information on how long a CPU takes one function of a task. clBuildProgram interprets the kernel code into a program that can be run in the OpenCL runtime. clCreateKernel selects one kernel function in a previous compiled OpenCL program, which may contain several kernel functions. clEnqueueNDRange places a specific kernel function in the OpenCL command queue, from which this command is received and processed by the GPU.
- This Intel® HD Graphics 4 ... timeline shows that Add is the kernel feature planned in the implementation of the runtime environment on Intel GPUs.
- It is highlighted when the actual Add action occurs on the GPU hardware. There is a gap between the planned execution time of the kernel function and the actual execution time caused by certain preparation and context switching.
- This is a new feature available in the latest version of VTune Amplifier 2016. As shown in the following figure, it shows the efficiency of data transfer using a static data form and presents data on the speed of data flows in the general scheme of the GPU architecture. The read speed of untyped memory is twice as fast as the write speed, which is consistent with the behavior of the HelloOpenCL application.

Using this architecture scheme, you can also monitor the operation of buffers that are allocated in the 3rd level cache in the HelloOpenCL application. GPU utilization can be significantly improved because most of the time the GPU is idle. In other words, an Intel OpenCL device can perform more complex tasks.