Ethernet + PCIe + FPGA = LOVE

Ethernet access is not possible without network interface cards (NICs). At low speeds (up to 1G), NICs are integrated into motherboards, and at high speeds (10G / 40G) NICs are located on a separate PCIe board. The main core of such a board is an integrated chip (ASIC), which is engaged in receiving / sending packets at the lowest level. For most tasks, the capabilities of this chip are more than enough.
What to do if the capabilities of the network card are not enough? Or does the task require the closest access to a low level? Then boards with reprogrammable logic - FPGAs come onto the scene.
What tasks they solve, what they place, as well as the most interesting representatives you will see under the cut!
Caution , there will be pictures!
Plan:
FPGA Board Applications
DPI, filtering and firewall
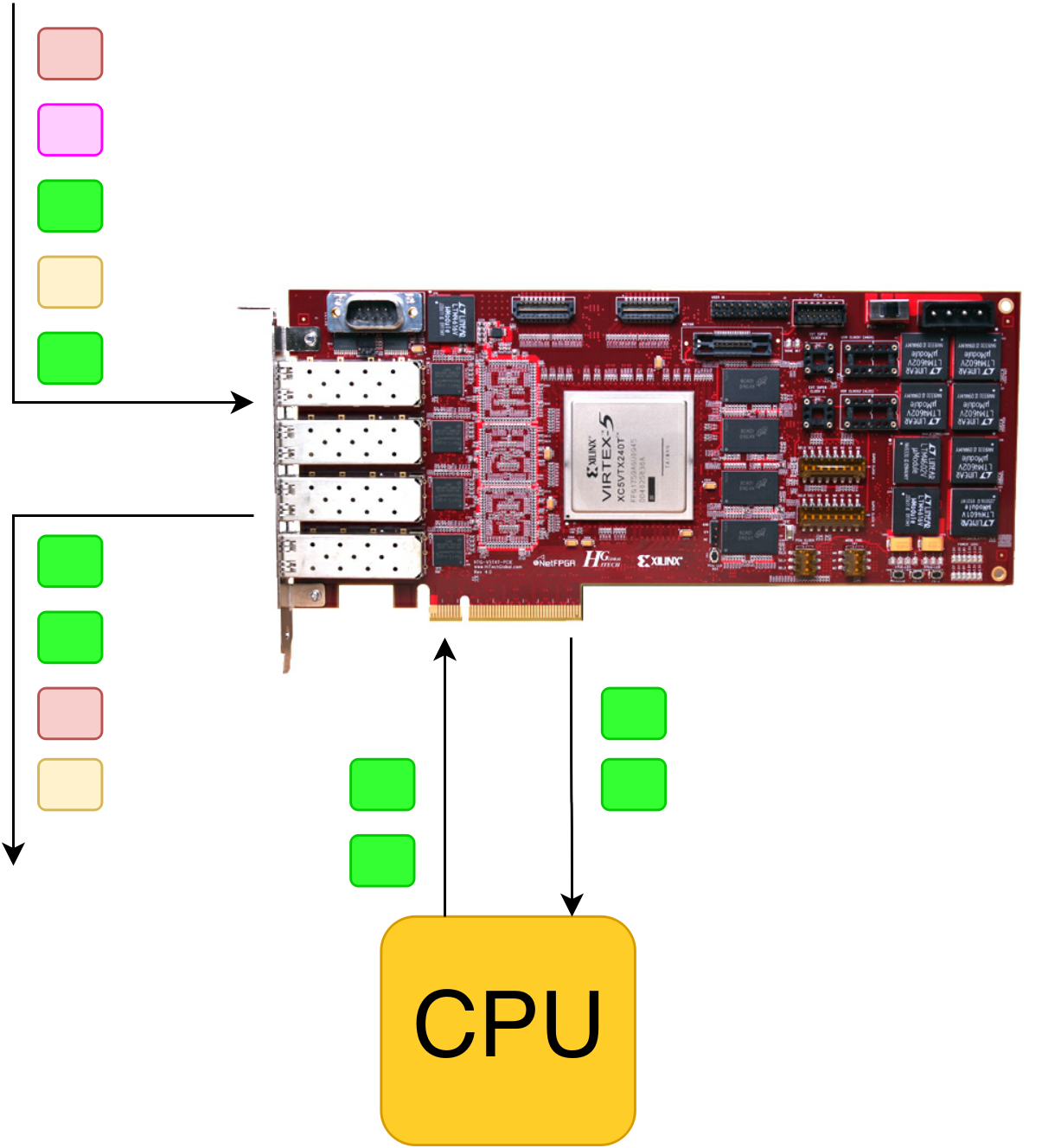
A server with such a board can get into a “gap” and monitor all packets passing through it. Intelligent DPI is implemented on the basis of the processor, and packet transfer and simple filtering (for example, many 5-tuple rules) are implemented on the basis of FPGAs.
How can I do that:
- The streams that we trust, or the solution for them is already in the table by FPGA, pass through the chip with a slight delay, the rest are copied to the CPU and processing is done there.
- FPGA can remove part of the load from the CPU and look for suspicious signatures in itself, for example, according to the Bloom algorithm . This algorithm has the probability of a false positive, so if there is a line in the packet that Bloom has reacted to, then such a packet is copied to the CPU for additional analysis.
- Only the traffic that is interesting is processed on the processor - the FPGA selects packets (for example, HTTP requests or SIP traffic) by the specified criteria and copies them to the CPU, everything else (torrents, video, etc.) passes through the FPGA without significant delay.
All three of these options can be combined in various variations. Also FPGA can do some other dirty work, for example, act as a shaper / polyser, or collect statistics on flows.
In the illustration above, green packets are processed on the CPU, burgundy and yellow passed through filters in FPGA, and pink ones were dropped (also in FPGA).
Traffic analysis and capture
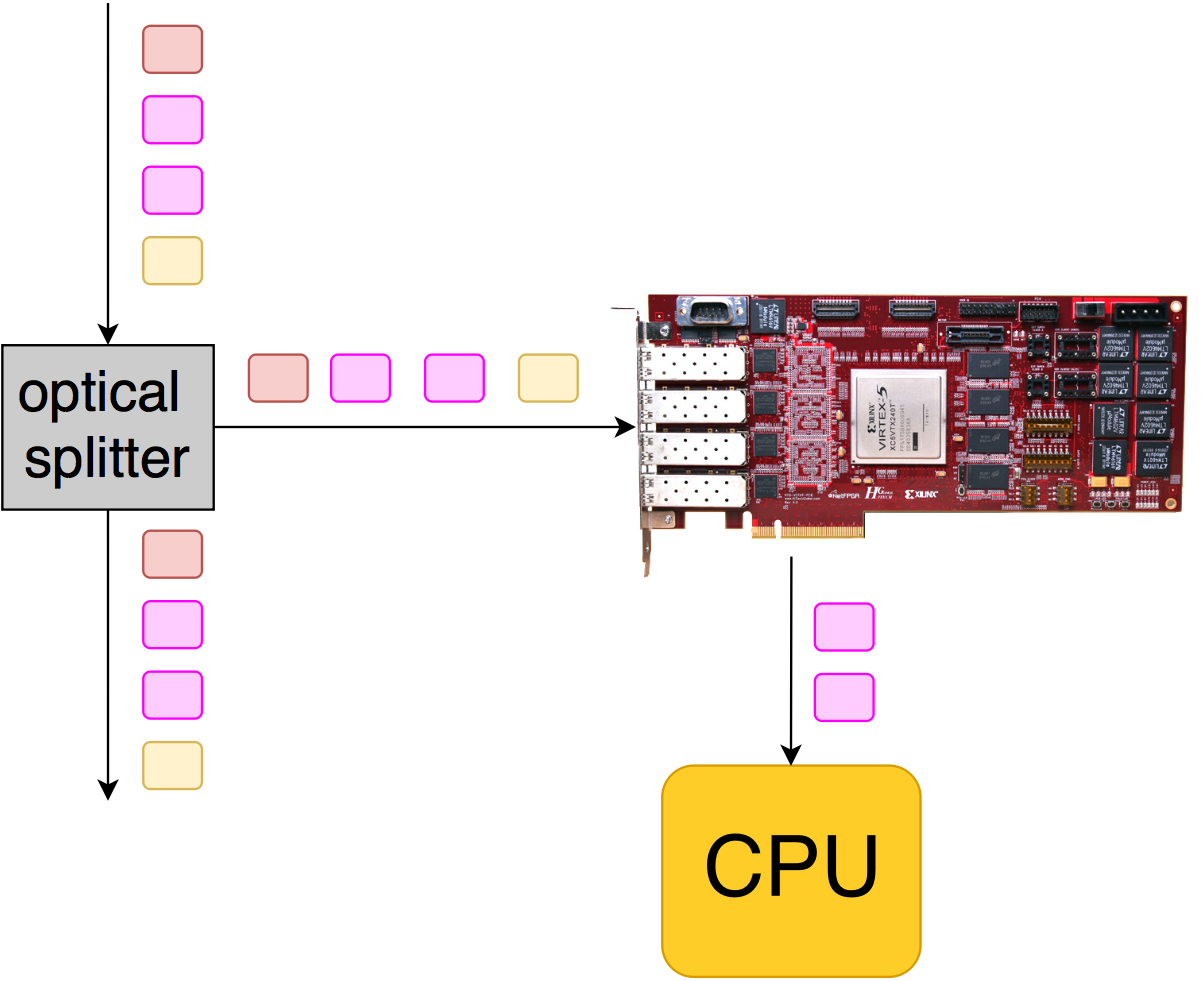
Sometimes these boards are used to capture traffic and further post-processing on the CPU (recording in pcap, delay analysis, etc.). In this case, a splitter is inserted into the links (or traffic is taken from the port's mirror). The result is a non-intrusive connection, similar to what we did in the RTP stream monitoring project .
Here, FPGA is required:
- Filtering by fields (type 5-tuple): to select only the traffic that is interesting.
- PTP synchronization, for hardware timestamping packets: the time is latched when a packet arrives, and this mark is placed at the end of the packet. Then on the CPU you can calculate, for example, the response time to the request.
- Slicing - cutting off only the necessary piece of data (most often it is the first N bytes from the packet - in order to copy only the headers, because very often the data is not very interesting).
- Packet Buffering:
- if the CPU doesn’t have time to write in case of some bursts, then you can smooth it out if you place packets in external memory for a couple of gigabytes
- if we want to guarantee the recording of packets for a short time (for example, after a trigger is triggered) - it is most often applicable for high speeds (40G / 100G).
- Throwing packets into queues and CPU cores.
Having access to the lowest level (well, almost), you can support any protocol or tunneling, and not wait for Intel to do this in its cards.
In the above illustration, the FPGA accepts all packets after the traffic branches, but only those of interest to us are copied to the CPU (pinkish).
Network card
Cards with FPGAs can be used as a regular NIC, but there is not much point in this:
- At present, at all Ethernet speeds (up to 100G inclusive), there are network cards based on ASICs. For the price they will be cheaper than FPGA solutions.
- If you write a card yourself, then for a less serious performance, you need to wind a huge number of buns in such a card (RSS, LSO, LRO).
The meaning appears only when it is necessary to provide a unique chip, which will never be in the chip from Intel. For example, hardware encryption according to GOST or Grasshopper .
Network accelerator
CPU load reduction
When high speeds appear, the processor does not have time to do everything: I want to remove some of the tasks from it. For example, what happens when you copy a large amount of data over a network?
The processor must:
- take some piece of data
- thrust into TCP, split into several packets, according to MTU
- substitute a header (MAC / IP addresses)
- calculate IP and TCP checksums (although most NICs already take care of this)
- pass descriptor to NIC
It is also necessary:
- follow answers
- resend packets if the packet is lost
- lower / increase tcp-window and so on
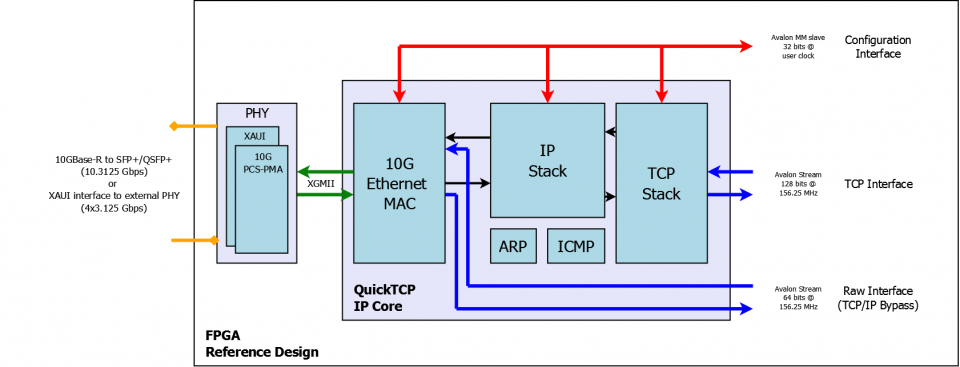
The TCP stack can be implemented on FPGA: it is enough for the CPU to provide a pointer to the raw data and the IP + port of the receiver, and all the low-level work (establishing a connection, forwarding, etc.) will be done by a piece of iron.
There are ready-made IP cores that do all this: for example, implementations of TCP and UDP stacks from PLDA .
They have standard interfaces (Avalon or AXI), which makes them easy to connect to other IP cores.
Faster Response
There is a class of tasks where money is brought not by processors, but by reaction speed. Of course I'm talking about High Frequency Trading . The role of FPGA in HFT can be found in this article.
The PLDA website provides a video and an example of how this is done. Using hardware TCP and UDP cores allows you to reduce the latency for purchases / sales.
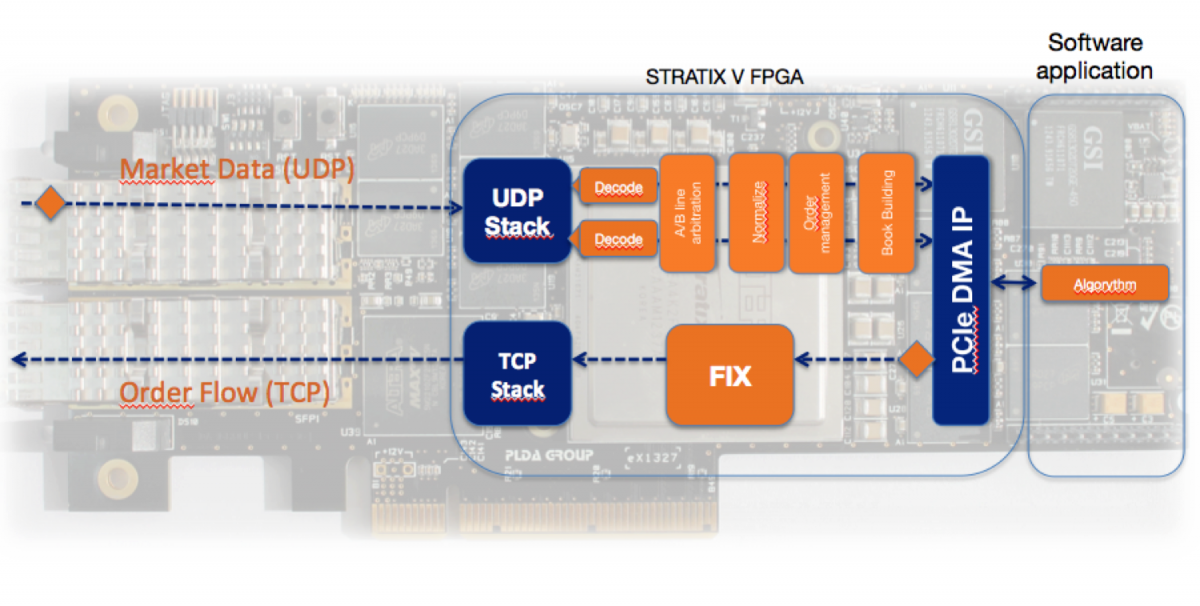
Hidden text
I apologize for the red underscores - the picture was taken from the PLDA website, and they have it in the original ...
There are special IP cores that decode data from the markets and are ready to interface with hardware TCP and UDP stacks.
Of course, using standard cores or approaches will not give an advantage over competitors: exclusive solutions are being developed, because "They want an even smaller delay . "
Measuring equipment
Network emulators
It often happens that you need to check the engineering solution in the laboratory, because in combat, it can be very expensive.
Recently there was an article from CROC about traffic optimization in the North and large RTT. To check what the quality of services will be in real conditions, you must first create these conditions in your laboratory. To do this, you can use the usual Linux machine, but there are special glands that are engaged in network emulation.
Most often it is necessary to be able to set such parameters as delay / jitter, packet loss (error). We can’t do without hardware support (read, FPGA), but we also need a “smart” processor to emulate various protocols (user sessions). In order not to develop hardware from scratch, you can take a server and insert a PCIe card with FPGA.
Faster Computing
Such cards can also be used to speed up some calculations or modeling, for example, for biology or chemistry. An example of such modeling was described by Algeronflowers in this article. In this case, Ethernet ports may not be needed, but on the other hand they can be useful if you want to make a farm of boards: input or output data for calculation to transmit via Ethernet.
Opencl

Sometimes there is no need to squeeze out all the juices from the iron: time-to-market is very important. Many developers refuse to use FPGA, because they are frightened by the low-level optimization to the clock (plus you need to know the new language (s) and instrument). I would like to write code at a "high" level, and the compiler will decompose everything into triggers / memory blocks. One such option is OpenCL . Altera and Xilinx support.
OpenCL on FPGA is the topic of a separate article (and not one). I recommend that you familiarize yourself with a presentation from Altera about the technology overview and development path for FPGA.
Highload
On the Internet you can find a lot of news about the fact that giants are eyeing the FPGA to process big data in data centers.
So, there was a note that Microsoft uses FPGA to speed up the search engine Bing. Technical details can be found in A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services .
Unfortunately, there is no good technical article in Russian about this, although the topic is very interesting. Can olgakuznet_ms or her colleagues fix this flaw?
Hope the releaseCPU + FPGA chips will encourage developers of highly loaded systems to transfer part of the calculations to FPGA. Yes, development under FPGA is “more complicated” than under CPU, but on specific tasks it can give a wonderful result.
Development / debugging of IP cores and software
Such boards can still be used by ASIC / FPGA developers to verify their IP cores, which can then be launched on completely different pieces of hardware.
It often happens that software is written at the same time as the piece of hardware is developed / produced, and it is already necessary to debug the software somewhere. In this context, software is like FPGA firmware + various drivers and user-space programs. In the 100G project of the analyzer and balancer , problems arose that we never solved:
- FPGA configuration (CSR: status-control registers) must occur via PCIe
- for linux'a FPGA with a bunch of interfaces should look like a network card: you need to write driver (s), and transfer packets from c / to the host
Of course, there were other tasks in parallel (such as generating / filtering 100G traffic), but they were quietly solved in the simulator, but you don’t really drive these two tasks in the simulator. What have we done? It turned out that we have a devboard from Altera. Despite the fact that there is a completely different chip, another PCIe, etc., we debugged a bunch of FPGA + drivers on it, and when the production department handed us a board for b100, then after raising the iron, this whole bunch worked without problems.
General scheme
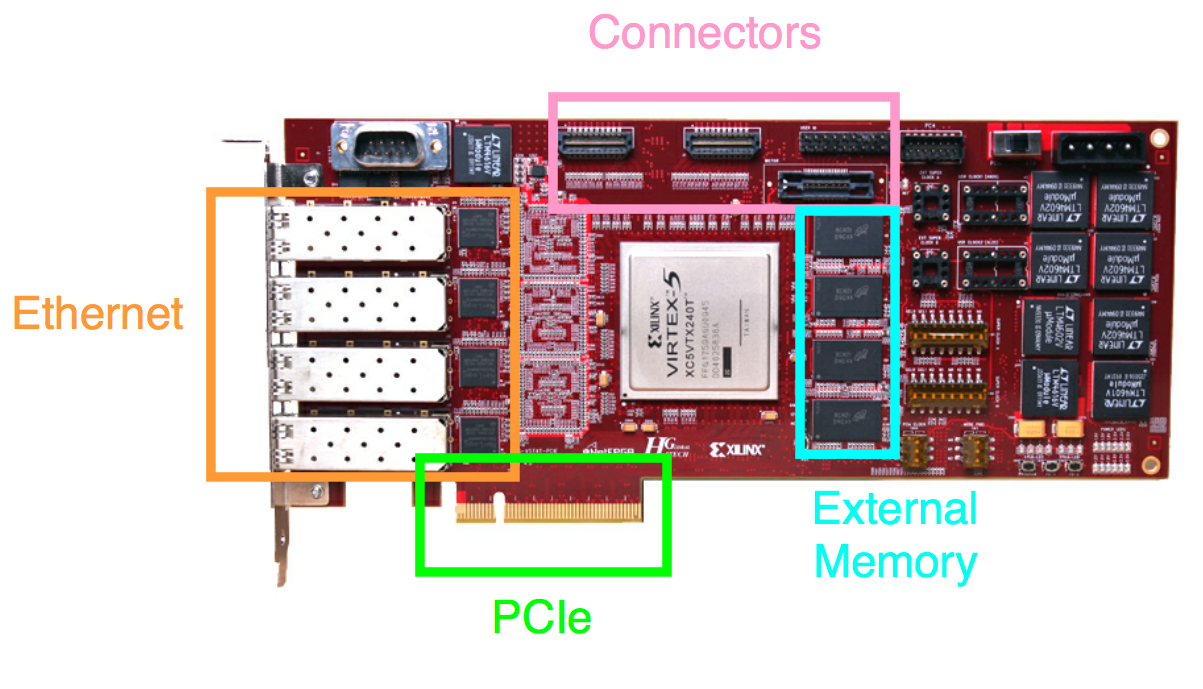
Before reviewing the cards, consider the general scheme of such PCIe cards.
Ethernet
The boards are equipped with standard Ethernet connectors:
- SFP - 1G
- SFP + - 10G
- QSFP - 40G
- CFP / CFP2 / CFP4 - 100G
The most common combinations are:
- 4 x SFP / SFP +
- 2 x QSFP
- 1 x CFP
You can read about what happens at a low level and how the connection to 10G to integrated circuits occurs, for example, here .
PCIe
A standard connector that can be plugged into a computer with an ordinary motherboard. At the moment, the top FPGAs support Gen3 x8 IP hardware cores, but this bandwidth (~ 63 Gbps) is not enough for all tasks. On some boards, there is a PCIe switch that combines 2 Gen3 x8 channels into one Gen3 x16.
On future chips, Altera and Xilinx announce hardware support for Gen3 x16, and even Gen4.
Connectors

Sometimes place the connector (s) for connecting expansion cards, but there is no de facto standard (such as USB). The most common are VITA ( FMC ) and HSMC .
Avago MiniPod

The above connectors have a slight drawback - they are metallic and attenuation at high frequencies / long distances can be significant.
In response to this problem, Avago has developed Avago Minipod : optical transceivers. They are ready to transfer 12 lanes of 10-12.5GBd. In size, the connector is comparable to a coin. Using this connector, you can connect not only adjacent boards, but also make connections in supercomputers or in racks between servers.
When our colleagues showed the MiniPod demo on such a board , they said that no additional IP cores or Verilog code needed to be inserted - these modules are simply connected to the I / O of the FPGA transceivers, and everything works.
External memory
There is not much memory in FPGAs - there are 50-100 Mbit in the top chips. To process big data, an external memory is connected to the chip.
Two types of memory are allocated:
When choosing take into account such parameters as price, volume, delays in sequential / random reading, bandwidth, power consumption, availability of memory controllers, ease of wiring / replacement, and so on.
Altera has an External Memory Interface Handbook , which, as you might guess, is dedicated to external memory. An interested reader in the chapter Selecting Your Memory will find tables comparing various types of memory and selection tips. The guide itself is available here (carefully, the file is large).
If you look at the use of memory in communication networks, then the tips are approximately the following:
- DRAM is used to create large buffers (for packets)
- SRAM:
- decision tables / structures where to send the packet
- queue management structures
- calculation of packet statistics (RMON, etc.)
- a hybrid approach is possible - DRAM is used to store the payload of a packet, and only the header is placed in SRAM
If you open the presentation of Cisco's Anatomy of Internet Routers , you can see that in some routers they use RLDRAM as DRAM.
Hmc
HMC (Hybrid Memory Cube) is a new type of RAM memory that can supersede DDR / QDR memory in some applications: promise significant bandwidth acceleration and lower power consumption. On the hub you can find news: one and two . In the comments to them you can find fears that this is still far away and so on.
I assure you that everything is not so bad. So, six months (!) Ago, our colleagues from EBV showed a working demoboard of four Stratix V (on the sides) and HMC (in the center).

Commercial samples (for mass product) are expected to be available in 2015.
PCIe Card Review
The review is probably too big a word - I will try to show the most interesting representatives from different companies. There will be no comparison or unpacking tables. In fact, there will not be much variety between the boards; they all fit into the “template” that was described earlier. I am sure that you can find about five to seven more companies that produce such boards, and there are about a dozen more boards themselves.
NetFPGA 10G
Hidden text
FPGA:
10-gigabit ethernet networking ports
Quad Data Rate Static Random Access Memory (QDRII SRAM)
Reduced Latency Random Access Memory (RLDRAM II)
- Xilinx Virtex-5 TX240T
- 240K logic cells
- 11.664 Kbit block RAM
10-gigabit ethernet networking ports
- 4 SFP + connectors
Quad Data Rate Static Random Access Memory (QDRII SRAM)
- 300MHz Quad data rate (1.2 Giga transactions every second), synchronous with the logic
- Three parallel banks of 72 MBit QDRII+ memories
- Total capacity: 27 MBytes
- Cypress: CY7C1515KV18
Reduced Latency Random Access Memory (RLDRAM II)
- Four x36 RLDRAMII on-board device
- 400MHz clock (800MT/s)
- 115.2 Gbps peak memory throughput
- Total Capacity: 288MByte
- Micron: MT49H16M36HT-25
This is not the top card, but I could not tell about it:
- NetFPGA boards are positioned as “open research platforms”: they are used worldwide (in more than 150 institutions). Students / researchers can do various labs / projects on them.
- the project is positioned as opensource: there is an organization of the same name on the github . On the github in the private repository are various reference designs (network card, switch, router, etc.), which are written in Verilog and distributed under the LGPL. They will become available after a simple registration .
Advanced IO V5031

Hidden text
- Altera Stratix V
- Quad 10 Gigabit Ethernet SFP+ optical ports
- 2 banks of 1GB to 8GB 72-bit 1066MHz DDR3 SDRAM
- 4 banks of 36Mbit to 144Mbit 18-bit 350MHz QDRII+ SRAM
- x8 PCI Express Gen 3
- PPS Interface for time synchronization with microsecond resolution
This board has a twin brother: captureXG 1000 , but it is already positioned as a card for recording data streams:
Hidden text
- Time Synchronization: IRIG-A, B and G time synchronization via a front panel SMA connector
- Filters: 128 programmable 5-tuple filters ( IPv4, TCP, UDP, ICMP, ARP )
- Packet Capture: PCAP Next Generation format or raw data format
In fact, to the card that was shown above, they wrote firmware for the FPGA, as well as the driver. And this already actually turns out to be another product that is ready to work out of the box. I wonder what is the difference in money between the two products.
Napatech NT40E3-4-PTP

Another card for recording and analyzing traffic:
Hidden text
Увы, больше технических подробностей из маркетинговой брошюры выжать не удалось.
- FPGA: Xilinx Virtex-7
- Quad 10 Gigabit Ethernet SFP+ optical ports
- 4 GB DDR3
- PCIe x8 Gen 3
Увы, больше технических подробностей из маркетинговой брошюры выжать не удалось.
In such a case, she looks very pretty. Fundamentally in terms of hardware, this card is not very different from others, but Napatech considers it as a finished product and screwed up a bunch of features that are implemented on FPGA:
Hidden text
- Hardware Time Stamp
- Full line-rate packet capture
- Frame buffering
- Frame and protocol information
- Time Stamp Injection
- Buffer size configuration
- Onboard IEEE 1588-2008 (PTP v2) support
- Inter-Frame Gap Control
- Frame Classification
- HW Time Synchronization
- Extended RMON1 port statistics
- Advanced Statistics
- Synchronized statistics delivery
- Flow identification based on hash keys
- Dynamic hash key selection
- Frame and flow filtering
- Deduplication
- Slicing
- Intelligent multi-CPU distribution
- Cache pre-fetch optimization
- Coloring
- IP fragment handling
- Checksum verification
- Checksum generation
- GTP tunneling support
- IP-in-IP tunneling support
- Filtering inside tunnels
- Slicing inside tunnels
All this can be done on other cards. You just have to spend time on this.
COMBO-80G

Hidden text
- Virtex-7 FPGA chip manufactured by Xilinx company
- 2× QSFP+ cage multi/single mode, CWDM or copper
- 4× 10G to 40G fanout modules for 10G Ethernet technology
- PCI Express 3.0 x8, throughput up to 50Gb/s to software
- 2× 72Mbits QDRII+ SRAM memory
- 2× 1152Mbits RLDRAM III memory
- 2× 4GB DDR3 memory
- External PPS (Pulse per second) synchronization
- Unique on-the-fly FPGA boot system (no need for host computer reboot)
Nallatech 385A and Nallatech 385C

Hidden text
385A:
385C:
Общее:
- Arria 10 1150 GX FPGA with up to 1.5 TFlops
- Network Enabled with (2) QSFP 10/40 GbE Support
385C:
- Altera Arria 10 GT FPGA with up to 1.5 TFlops
- Network Enabled with (2) QSFP28 100 GbE support
Общее:
- Low Profile PCIe form factor
- 8 GB DDR3 on-card memory
- PCIe Gen3 x8 Host Interface
- OpenCL tool flow
As you can see, these are two twin brothers: the 385A has a more budget FPGA (GX) with 17.4 Gbps transceivers, which is enough for 10 / 40G, and the 385C already uses Arria 10 GT, because you need 28 Gpbs transceivers to support 100G, which come in 4x25G performance.
I note that Nallatech provides OpenCL BSP for these cards.
HiTech Global 100G NIC

Hidden text
- x1 Xilinx Virtex-7 H580T
- x16 PCI Express Gen3 (16x8Gbps)
- x1 CFP2 (4x25Gbps)
- x1 CFP4 (4x25Gbps)
- x1 Cypress QDR IV SRAM
- x2 DDR3 SODIMMs (with support up to 16GB)
- x4 Avago MiniPod (24 Tx and 24 Rx) for board-to-board high-speed communications
- x1 FMC with 8 GTH transceivers and 34 LVDS pairs (LA0-LA33)
Here we see both the FMC connector for connecting other boards, and the Avago MiniPod, which was mentioned earlier.
Bonus:
Nallatech 510t

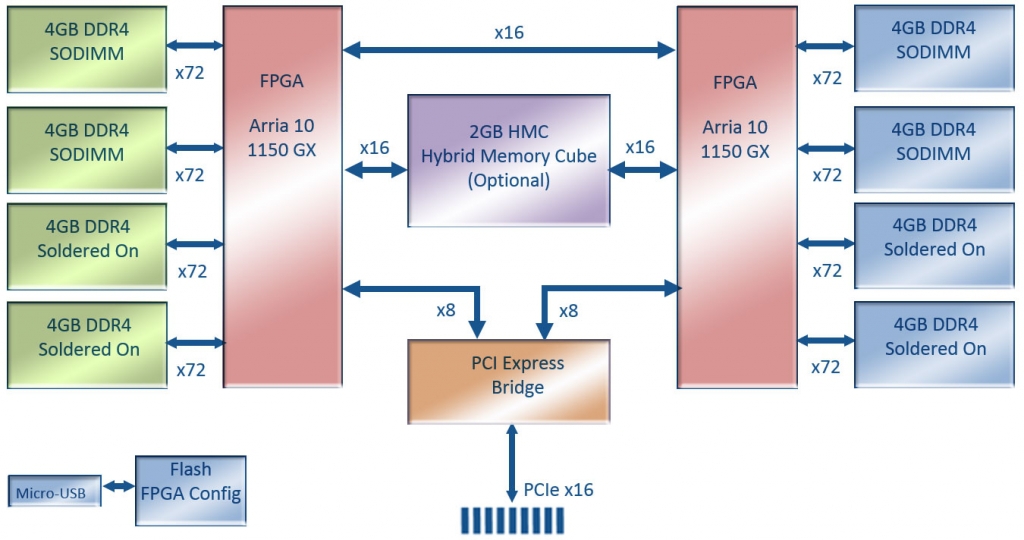
There is no Ethernet in this card, but it's really a bomb .
Hidden text
- GPU Form Factor Card with (2) Arria 10 10A1150GX FPGAs
- Dual Slot Standard Configuration
- Single Slot width possible, if user design fits within ~100W power footprint
- PCIe Gen3 x 16 Host Interface
- 290 GBytes/s Peak Aggregate Memory Bandwidth:
- 85GB/s Peak DDR4 Memory Bandwidth per FPGA (4 Banks per FPGA)
- 30GB/s Write + 30GB/s Read Peak HMC Bandwidth per FPGA
Here are two fat top-end chips that are riveted using 20-nm technology, and DDR4, and HMC. Performance promised up to 3 TFlops!
Judging by the render, the real hardware is still far away, but it feels like it will be gold (for the price), but it will occupy its niche: it is positioned as a coprocessor for data centers. They promise support for OpenCL, which means that no one will be nursing this board before the clock: they will drive the ready-made algorithms and burn the watts. Who knows, maybe on this board Youtube, Facebook, VK will convert the video, replacing dozens of servers? Or maybe special effects for the new Avatar will be rendered on such farms?
Conclusion
Having looked at all this variety of boards, my colleagues and I thought: why don't we also make such a card?
By the complexity of the printed circuit board, it will not be more difficult than the B100 , we seem to be able to write software for FPGA and Linux, and there are some companies and departments in demand for such glands.
My colleagues and I argued a little about what card to do, and we are interested in what you think about this.
Thanks for attention! Ready to answer questions in the comments or in PM.
Only registered users can participate in the survey. Please come in.