Kaggle. Prediction of sales, depending on weather conditions

As recently as last Friday, I had an interview at a company in Palo Alto on the position of Data Scientist, and this many-hour marathon, from technical and not-so-very questions, was supposed to begin with my presentation about some project in which I was engaged in data analysis. Duration - 20-30 minutes.
Data Science is a vast area that includes a lot of things . Therefore, on the one hand, there is plenty to choose from, but, on the other hand, it was necessary to choose a project that would be correctly accepted by the public, that is, so that the audience understood the task, understood the logic of the solution, and at the same time could be inspired by how the approach that I used may be related to what they do every day at work.
{kind=link}
A few months earlier, my friend, an Indian, was trying to get into the same company. He told them about one of his tasks, on which he worked in graduate school. And, offhand, it looked good: on the one hand, this is due to what he has been doing for the past few years at the university, that is, he can explain details and nuances at a deep level, and on the other hand, the results of his work were published in a peer-reviewed magazine, that is, it is a contribution to the world piggy bank of knowledge. But in practice, it worked in a completely different way. Firstly, to explain what you want to do and why, you need a lot of time, and he has 20 minutes to do everything. And secondly, his story about how a graph with some parameters is divided into clusters, and how it all looks like a phase transition in physics, raised a legitimate question: “Why do we need this?”
I decided to talk about one of the competitions on kaggle.com, in which I participated.
The choice fell on the task in which it was necessary to predict the sale of goods that are sensitive to weather conditions depending on the date and these same weather conditions . The competition was held from April 1 to May 25, 2015. Unlike regular competitions in which winners get big and not very money and where it is allowed to share the code and, more importantly, ideas, the prize in this competition was simple: job recruiter will look at your resume. And since the recruiter wants to evaluate your model, it was forbidden to share code and ideas.
Task:
- 45 hypermarkets in 20 different places on the world map (geographical coordinates are unknown to us)
- 111 goods whose sales can theoretically depend on the weather, such as umbrellas or milk (the goods are anonymous. That is, we are not trying to predict how many galoshes were sold on a given day. We are trying to predict how many goods were sold, say, with an index of 31)
- Data from January 1, 2012 to September 30, 2014
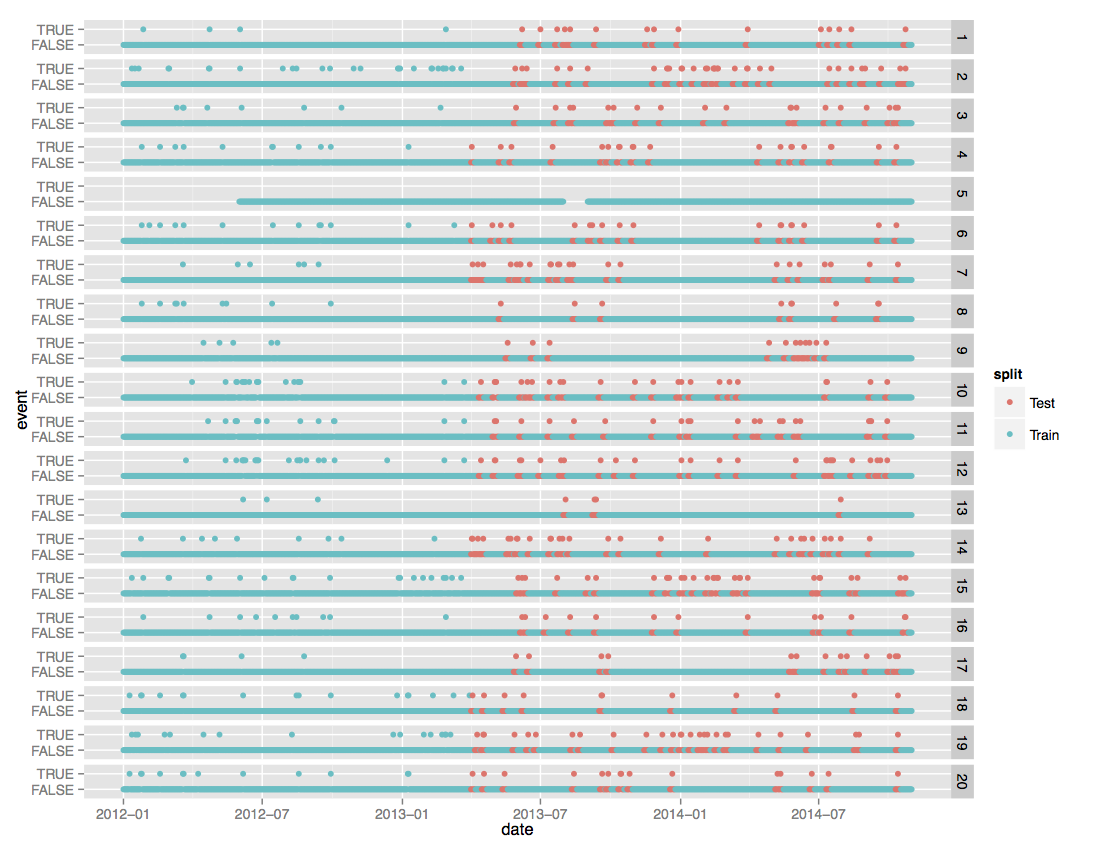
This not very clear picture, which was borrowed from the data description page for this competition, shows:
- Column with numbers on the right - meteorological stations.
- Each meteorological station has two rows: lower - all dates, upper - dates with non-standard weather conditions: storm, strong wind, heavy rain or hail, etc.
- Blue dots - train set, for which both weather and sales are known. Red - test set. Weather conditions are known, but there is no sale.
The data is presented in four csv files:
- train.csv - sales of each of 111 goods in each of 45 stores on a daily basis from train set
- test.csv - dates on which sales in each of 45 stores should be predicted for each of 111 products
- key.csv - which weather stations are located next to which stores
- weather.csv - weather conditions for each day in the interval from January 1, 2012 to September 30, 2012 for each of the 20 weather stations
Meteorological stations provide the following data (In parentheses, the percentage of missing values.):
- Maximum Temperature [degrees Fahrenheit] (4.4%)
- Minimum Temperature [degrees Fahrenheit] (4.4%)
- Average temperature [degrees Fahrenheit] (7.4%)
- Deviation from expected temperature [degrees Fahrenheit] (56.1%)
- Dew Point [degrees Fahrenheit] (3.2%)
- Wet Thermometer Temperature [degrees Fahrenheit] (6.1%)
- Sunrise Time (47%)
- Sunset time (47%)
- Summary description of type rain, fog, tornado (53.8%)
- Precipitation in the form of snow [inches] (35.2%)
- Rainfall [inches] (4.1%)
- Station atmospheric pressure [inches of mercury] (4.5%)
- Atmospheric pressure at sea level [inches of mercury] (8.4%)
- Wind speed [mph] (2.8%)
- Wind direction [degrees] (2.8%)
- Average wind speed [miles per hour] (4.2%)
Obvious data problems:
- We do not know the geographical coordinates of the stores. And that's bad. Rain or sunshine is important, but Alaska and San Francisco are likely to show different sales dynamics.
- Product names are anonymized. We do not know if the product with ID = 35 is milk, whiskey or cotton pants.
- The organizers of the competition decided to aggravate the previous paragraph and wrote in English on white that there are no guarantees that ID = 35 in one store will mean the same as in another.
- Meteorological stations measure not everything and not always. The weather data is quite leaky. And the question of how to fill these gaps will need to be addressed somehow.
For me, the main thing in any task in machine learning that I am working on is the “question”. In the sense that you need to understand the question in order to find the answer. This seems like a tautology, but I have examples in both scientific activity and in third-party projects like kagla, when people tried to find an answer not to the question that was asked, but to some one they had invented, and it didn’t end with anything good .
The second most important is the metric. I don’t like the way it sounds: "My model is more accurate than yours." It would sound much nicer to sound similar in meaning, but slightly more accurate: “My model is more accurate than yours if we apply this metric for evaluation.”
We need to predict how many goods will be sold, that is, this regression task. The standard regression metric of standard deviation can be used, but illogical. The problem is that an algorithm that will try to predict how many pairs of rubber boots will be sold can predict negative values. And then the question will be, what to do with these negative values? Zero out? Take the absolute value? It’s dreary. You can do better. Let's do a monotonous transformation of what needs to be predicted, so that the converted values can take any real, including negative, values. We predict them, and then perform the inverse transformation to the interval of non-negative real numbers.
You can think of it as if our error function were defined in this way:
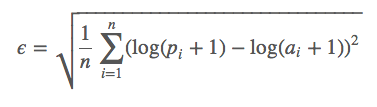
Where:
- a - real value
- p is our prediction
- the natural logarithm of the argument shifted by 1 is a monotone map from a non-negative real axis to the entire axis, with an obvious inverse transformation.
But, more importantly, in this competition, the accuracy of our prediction is evaluated precisely by this metric. And I will use it precisely: what the organizers want, I will give them to them.
Zero iteration or base model.
When working on various tasks, this approach showed itself well: as soon as you started working on a task, you create a “clumsy” script that makes a prediction on our test set. Clumsy because it is created in a dull way, without reflection, without looking at the data. And without building any distributions. The idea is that I need a lower bound for the accuracy of the model that I can offer. As soon as I have such a “clumsy” script, I can check some new ideas, create new signs, adjust the model parameters. I usually evaluate accuracy in two ways:
- The result of the prediction evaluation on the test set, which shows us the Public Leaderboard on kaggle.
- hold out set if train set is large and uniform, or 5 fold cross validation if train set is small or uneven
The first is good because it does not take much time. Made a prediction, sent it to the site - got the result. The bad thing is that the number of attempts per day is limited. In this competition, this is 5. He is also good at showing the relative accuracy of the model. Error 0.1 - is it a lot or a little? If many on the Public Leaderboard have fewer predictions, this is a lot.
The second is good in that you can evaluate various models as many times as you like.
The problem is that a model evaluated using the same metric can give different accuracy in these two approaches:
Inconsistencies can be caused by:
- data in train and test are collected from different distributions
- very small train or test
- tricky metric does not allow human cross validation
In practice, it is enough that the improvement in the accuracy of the cross validation model corresponds to the improvement in the results on the Public Leaderboard, exact numerical compliance is not necessary.
So here. First of all, I wrote a script that:
- Distills the time of sunrise / sunset from hours and minutes to the number of minutes from midnight.
- Summary of weather conditions in dummy variables.
- Instead of all missing values -1.
- We connect the corresponding train.csv / test.csv, key.csv and weather.csv
- The resulting train set - 4,617,600 objects.
- The resulting test set - 526,917 objects.
Now we need to feed this data to some algorithm and make a prediction. There is a sea of various regression algorithms, each with its own pros and cons, that is, there is plenty to choose from. My choice in this case for the base model is Random Forest Regressor . The logic of this choice is that:
- Random Forest has all the advantages of Decision Tree algorithms. For example, theoretically he is indifferent to whether a numerical or categorical variable.
- It works smartly enough. If memory serves me right, the complexity is O (n log (n)), where n is the number of objects. This is worse than the method of stochastic gradient descent with its linear complexity, but better than the support vector method with a nonlinear core, in which O (n ^ 3).
- Evaluates the importance of attributes, which is important for the interpretation of the model.
- Indifferent to multicollinearity and correlation of data.
Prediction => 0.49506
Iteration 1.
Usually in all online classes there is a lot of discussion about which graphs to build in order to try to understand what is going on. And this idea is correct. But! There is a problem in this case. 45 stores, 111 products, and there is no guarantee that the same ID in different stores corresponds to the same product. That is, it turns out that it is necessary to research, and then predict 45 * 111 = 4995 different pairs (store, product). For each pair, weather conditions can work differently. The correct, simple, but not obvious idea is to build a heatmap for each pair (store, product), on which to display how many units of the product were sold for the whole time:

- In the vertical - the product index.
- Horizontal - store intex.
- The brightness of the dots is Log (how many units of goods sold in all the time).
And what do we see? The picture is quite pale. That is, it is possible that some goods in some stores were not sold in principle. I associate this with the geographical location of the stores. (Who will buy the downy sleeping bag in Hawaii?). And let's exclude from our train and test those products that have never been sold in this store.
- train from 4617600 is reduced to 236038
- test from 526917 is reduced to 26168
that is, the data size has decreased by almost 20 times. And as a consequence:
- We removed some of the noise from the data. As a result, it will be easier for the algorithm to train and predict, that is, the accuracy of the model should increase.
- The model is training much faster, that is, testing new ideas has become much easier.
- Now we train on a reduced train (236038 objects), we predict on a reduced test (26168 objects), but since the cuggle wants a prediction with a size (526917 objects), then we balance the remainder with zeros. The logic is that if some product has never been sold in this store, then either it will never be sold or it will be sold, but we can not predict this in any case.
Prediction -> 0.14240 . The error decreased three times.
Iteration 2.
Trimming the train / test sizes worked great. Is it possible to aggravate? It turns out that you can. After the previous iteration, I got only 255 non-zero pairs (store, product), and this is already visible. I looked at the charts for each pair and found that some goods were not sold not because of bad / good weather conditions, but simply because they were not available. For example, here is a picture for product 93, in store 12:
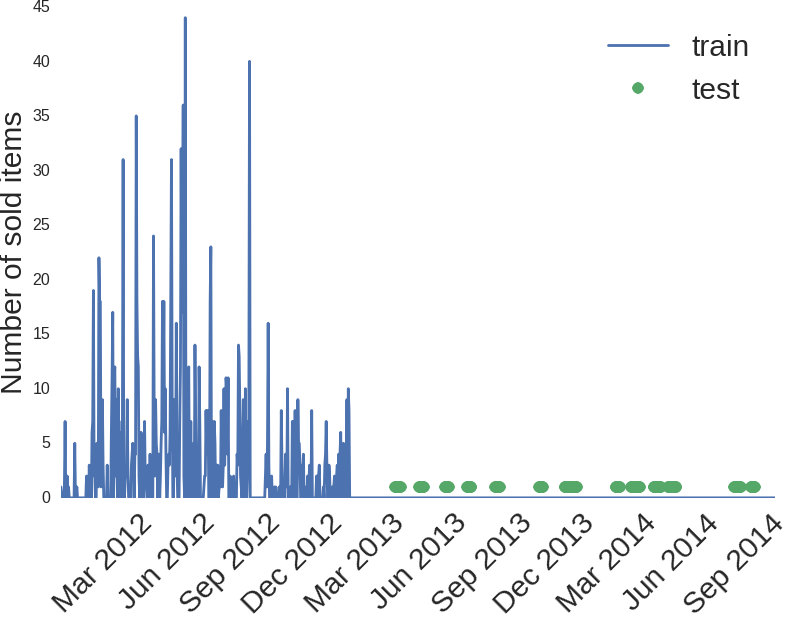
I don’t know what kind of product it is, but there is a suspicion that its sales ended at the end of 2012. You can try to remove these products from train and set 0 to all of them in test, as our prediction.
- train is reduced to 191,000 objects
- test is reduced to 21272 objects
Prediction -> 0.12918
Iteration 3.
The name of the competition involves prediction based on weather data, but, as usual, they are cunning. The problem that we are trying to solve sounds differently:
“You have a train, you have a test, spin as you like, but make the most accurate prediction for this metric.”
What's the difference? The difference is that we have not only weather data, but also a date. And date is a source of very powerful attributes.
- Data for three years => annual frequency => new signs year and number of days from the new year
- People get paid once a month. It is possible that there is a monthly frequency in purchases. => new month sign
- How people shop can be related to the day of the week. Rain is, of course, yes, but Friday evening is Friday evening => a new sign is the day of the week .
Prediction -> 0.10649 (by the way, we are already in the top 25%)
And what about the weather?
It turns out that the weather is not very important. I honestly tried to add weight to her. I tried to fill in the missing values in various ways, such as the average values for the attribute, for different tricky subgroups, tried to predict the missing values using various machine learning algorithms. It helped a little, but at the level of error.
The next step is linear regression.
Despite the apparent simplicity of the algorithm, and the bunch of problems that this algorithm has, it also has significant advantages that make it one of my favorite regression algorithms.
- Categorical signs, such as day of the week, month, year, store number, product index are distilled into dummy variables
- Scaling to increase the speed of convergence and interpretability of the results.
- Twist the regularization parameters L1 and L2.
Prediction -> 0.12770
This is worse than Random Forest, but not so much.
The question is, why do I need linear regression on non-linear data? There is a reason for that. And this reason is an assessment of the importance of symptoms.
I use three different approaches for this assessment.
The first is what RandomForest produces after we trained it:

What do we see in this picture? The fact that the type of goods sold, as well as the store number, is important. And the rest is much less important. But we could say this without even looking at the data. Let's remove the product type and store number:
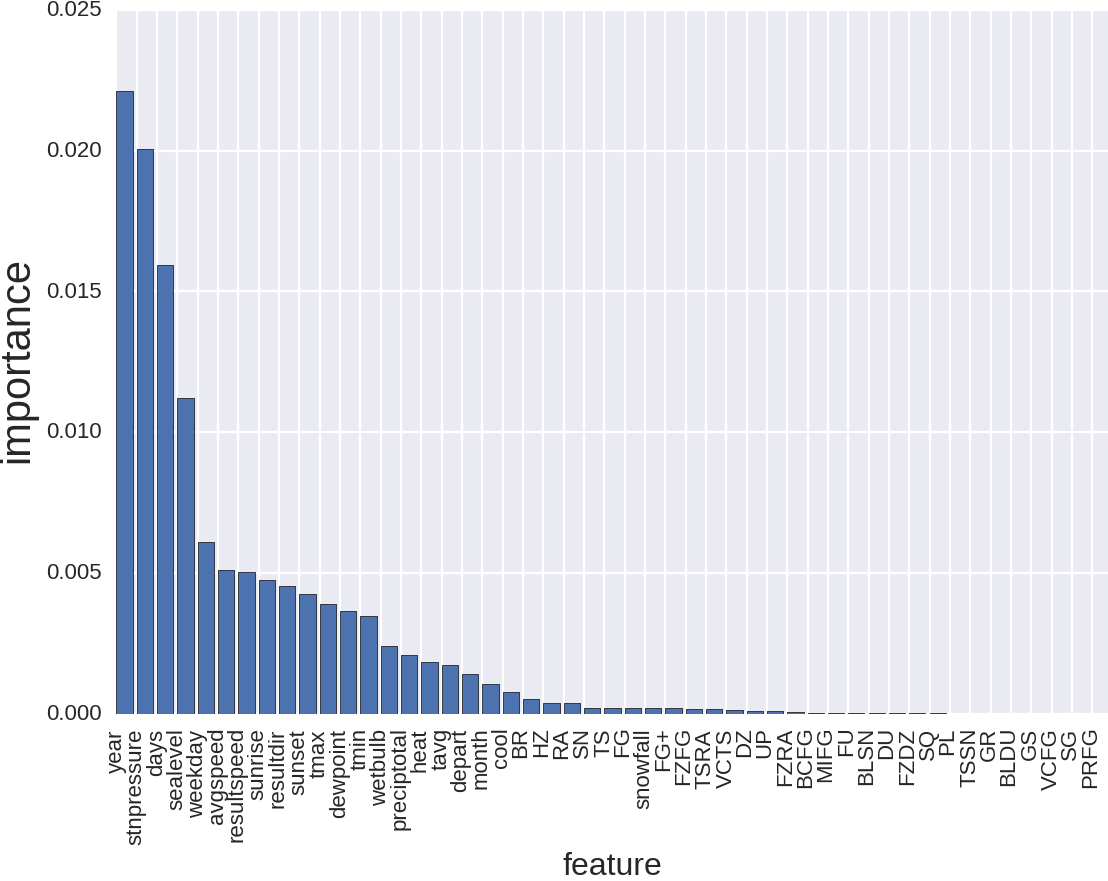
And what is there? Year - perhaps this is logical, but it is not obvious to me. Pressure, by the way, was understandable to me, but to the people to whom I broadcast it, it was not very. Still, in St. Petersburg, the weather changes frequently, which is accompanied by a change in atmospheric pressure, and I was in the know about how this changes mood and well-being, especially among older people. To people living in California, with its stable climate, this was not obvious. What's next? The number of days since the beginning of the year is also logical. Cuts off what season we are trying to predict sales. And the weather, whatever one may say, may be connected with the season. Then the day of the week is also clear. Etc.
The second method is the absolute value of the coefficients, which is produced by linear regression on the scaled data. The larger the coefficient, the more influence it has.
The picture looks like this and little is clear here. The reason that there are so many signs is because, for example, the product type for RandomForest is one sign, and here there are already 111 of them, the same with the store number, month and day of the week. Let's remove the product type and store number.
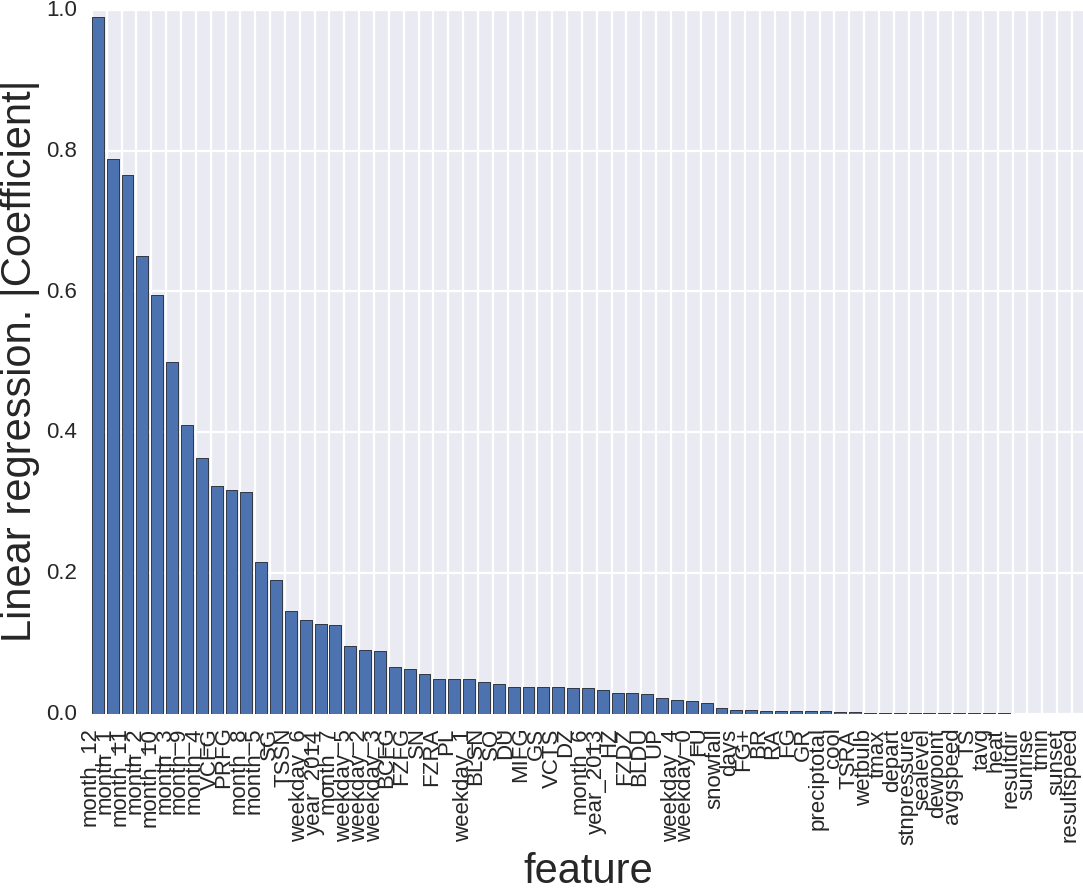
That's better. What's going on here? A month is important, especially if it is December, January or November. It seems logical too. Winter. Weather. And, importantly, the holidays. Here is the New Year, and Thanksgiving, and Christmas.
The third method is the brute force method, toss out signs one at a time and watch how this will affect the accuracy of the prediction. The most reliable, but the most dreary.
With the finding of signs and their interpretation, they seem to have finished, now numerical methods. Everything is straightforward here. We try different algorithms, find the optimal parameters manually or using GridSearch. We combine. We predict.
- Linear Regression ( 0.12770 )
- Random Forest ( 0.10649 )
- Gradient Boosting ( 0.09736 )
I did not particularly invent. He took a weighted average of these predictions. He calculated the weights by predicting these algorithms on a holdout set, which he bit off from the train set.
It turned out something like 0.85% Gradient Boosting, 10% Random Forest, 5% Linear regression.
Result 0.09532 (15th place, top 3%)

In this graph, the best known result is the first place on the Private LeaderBoard.
What didn't work:
- kNN is a simple algorithm, but often performs well as part of an ensemble. I could not squeeze less out of it (0.3)
- Neural networks - with the right approach, even on such mixed data they show a decent result, and what’s important, they often show themselves wonderfully in ensembles. Then I didn’t have the bluntness of my hands; somewhere, somewhere, I was too clever.
- I tried to build separate models for each weather station, product and store, but there is very little data, so the accuracy of the prediction decreases.
- An attempt was made to analyze time series and highlight the trend, and periodic components, but this accuracy of the prediction also did not increase.
Total:
- Cunning algorithms are important, and now there are algorithms that produce very accurate results right out of the box. (For example, I was pleased with a convolutional neural network of 28 layers, which itself isolates the surviving features from the images. )
- The preparation of data and the creation of competent attributes is often (but not always) much more important than complex models.
- Often brilliant ideas do not work.
- Sometimes completely stupid and hopeless ideas work great.
- People are those creatures who like to be in a comfort zone and follow their time-tested schedule, which is based on a calendar, and not on a momentary impulse caused by weather conditions.
- I tried to squeeze as much of this data as possible, but if we knew the price of the goods, or their names, or the geographical location of the stores, the solution would be different.
- I did not try to add weather before and after the day for which a prediction should be made. Also, I have not tried to create a separate attribute to describe the holidays. It is possible that this would help.
- I spent a week on everything about everything, from time to time looking up from adding a dissertation and starting another iteration. Perhaps the accuracy of the prediction could be increased if I spent more time, although on the other hand, since I did not do this in a week, then so be it. On kaggle.com there are a lot of interesting competitions, and getting stuck on one thing is not very right in terms of the effectiveness of obtaining knowledge.
- I recommend it to anyone who has not tried to compete in kaggle.com . It is interesting and informative.
UPDATE:
In the comments, a very correct question was asked about overfitting, and I decided to add a text describing how the accuracy of your model is evaluated on kaggle.com.
Often during the interview, they ask me where I got experience in machine learning from. Previously, I replied that the theoretical preparation of online classes, reading books, scientific articles and forums related topics. And the practical one from the attempts to use machine learning in condensed matter physics and the experience of participating in kagle competitions. Moreover, in fact, in terms of knowledge, kaggle gave me much more. At least because there I worked with more than 20 different tasks, and each has its own nuances and troubles. For instance:
- Otto Group Product Classification Challenge - The data was prepared in such a way that no one really succeeded in creating any signs. The emphasis in this competition was on numerical methods. Algorithms, model parameters, ensembles. In this competition, I figured out the algorithms: Gradient Boosting, met Neural Networks, learned how to make simple ensembles. He began to actively use scikit-learn, graphlab, xgboost.
- Search Results Relevance - Here Natural Language Processing with all relevant theoretical and practical problems. Theoretical base and practical experience of using SVM, bag of words, word2vec, glove, nltk.
- Avito Context Ad Clicks - There was a question of scalability. 300 million objects with a bunch of signs. And then I went Apache Spark, showed all the power and shortcomings of the logistic regression. (Unfortunately, my hands did not reach FFM)
- Diabetic Retinopathy Detection - Image processing, extraction of signs from images, neural networks, advantages and disadvantages of using the GPU. Experience with Theano and ImageMagic.
and so on, another 15 different problems. It is very important that thousands of people with different knowledge and experience worked on these tasks at the same time, sharing ideas and code. Sea of knowledge. In my opinion, this is a very effective training, especially if you simultaneously get acquainted with the corresponding theory. Each competition teaches something, and in practice. For example, at our faculty, many have heard about the PCA, and many believe that this is a magic wand that can be used almost blindly to reduce the number of signs. And in fact, PCA is a very powerful technique, if used correctly. And very powerfully shoots in the leg, if wrong. But until you tried it on various types of data, you really don’t feel it.
And, in my innocence, I assumed that those who heard about the Kagl perceive it that way. It turned out that no. Communicating with my friends Data Scientists, as well as slightly discussing my experience on coughing on various ones, I realized that people don’t know how the accuracy of the model is evaluated at these competitions and the general opinion about caglers is overfitters, and this experience participation in competitions is more negative than positive.
So, I’ll try to explain how it is and what:
Most (but not all) of the tasks that are offered to those who wish are training with a teacher. That is, we have a train set, there is a test set. And you need to make a prediction on test. The accuracy of the model is evaluated by how correctly we predicted test. And that sounds bad. In the sense that experienced Data Scientists will immediately see the problem. Making a bunch of predictions on test, we aggressively overfit. And that model which precisely works on test can disgustingly work on new data. And this is exactly how most of those who heard about Kagl, but have not tried, think about this process. But! In fact, this is not so.
The idea is that the test set is split into two parts: Public and Private. Usually in the proportion of 30% on Public, and 70% on Private. You make a prediction on the entire test set, but until the competition is over, you can see the accuracy of your prediction only on Public. And after the end of the competition, accuracy on Private becomes available to you, and this Private is the final accuracy of your model.
An example of a competition that I described in this text.
The competition ends on May 25th. => Until 5:00 p.m., PST, a prediction error of 30% test set, that is, the Public part, is available to you. In my case, it was 0.09486 and 10th place on the Public Leaderboard. At five in the evening, the PST competition ends. And the prediction for the remaining 70% (Private) becomes available.
I have it0.09532 and 15th place. That is, I slightly overfit.
The total accuracy of your model on Private is estimated by the two predictions you choose. As a rule, I choose one of them - the one that gives the smallest error on the Public Leaderboard, and the second one that gives the smallest error on the Cross Validation, calculated on the train set.
Usually I work in this mode: if the error on the local cross validation has decreased => send the prediction to the cuggle. That is, a strong overfit does not occur. Model parameters are also selected based on the magnitude of the error at cross validation. For example, the weights with which I averaged Linear Regression, Random Forest and Gradient Boosting were determined by a piece of data that I bit off from the train and did not use to train the model, as I did not use the test set either.
As Owen correctly noted , in one of his presentations , the correct assessment of the accuracy of a model is much more important than the complexity of the model. Therefore, when I create my naive script (zero iteration), mentioned above, I focus not on data analysis and model accuracy, but on the fact that the cross validation error on the train set corresponds to the error on the Public Leaderboard.
It is not always simple, but often simply impossible.
Examples:
- Facebook Recruiting IV: Human or Robot? - something didn’t grow together here. Moreover, the people on the forum discussed how to do it humanly, that is, I'm not the only one. I just fought with reviewers on the topic of the dissertation, so here I just overfilled the Public Leaderboard, but neatly. My place at Private is 91st place higher than at Public. Most likely because the others overfed more aggressively. But in general, this is an example of competition when Public and Private are from slightly different distributions.
- Restaurant Revenue Prediction is generally an Achtung. train set - 137 objects, including outliers. test set - 10000. Here, simply because of the small size of the train, you can only imagine anything but overfit Public Leaderboard. As a result, there is a strong difference between Private and Public. But this, in principle, was the most stupid task among those that I worked on.
- ECML / PKDD 15: Taxi Trajectory Prediction (I) and ECML / PKDD 15: Taxi Trip Time Prediction (II) - in these two competitions, firstly, the task structure is so tricky that you need to think hard how to correctly evaluate the accuracy using local cross validation. Well, the sizes of train / test also add. Millions of objects in train and about a thousand in test.
- ICDM 2015: Drawbridge Cross-Device Connections is semi-supervised learning and I’ve already broken my brain with this task. It seems to have come up with how to locally evaluate the accuracy of the model. But here I have to think and read a lot. This competition ends in 12 days. As they say in Odessa: "We will see." Maybe I’ll invent something.
Morality - I tried to clarify that the people who participate in the kaggle.com showings are a different audience. At first, the majority is engaged in adjusting the parameters, based on the results of the Public Leaderboard, and then howls on the forum that “the world is cruel, everyone is to blame”, when their final place on Private is much lower than expected. But, as a rule, after the first such puncture, the chakras open and the audience approaches the question of assessing the accuracy of the model very reverently, with an understanding of where KFold is needed, where is StarifiedKFold, where it is enough to hold out set, how many folds you need to take, how to interpret the results, and in general, where does the rake exist, and when it is possible to step on it, and when it is not worth it.
Only registered users can participate in the survey. Please come in.
Have you tried participating in promotions at kaggle.com?
- 10.5% Actively involved. 16
- 2.6% Actively participated, but earlier. Now there is no time / desire. 4
- 21.1% Tried it once or twice. (That is, sent predictions to the site for evaluation) 32
- 37% registered, but did not try to send their predictions. 56
- 13.2% Opened the site, looked and closed. 20
- 3.3% I heard about kaggle.com, but never logged in. 5
- 11.9% The first time I heard about kaggle.com. 18