Incrementally updated backup as a database backup strategy
Today, there are many options for backing up Oracle DBMSs that allow administrators to sleep peacefully at night and not worry about what could happen and how to avoid it. Also to help - a lot of software to simplify daily routine tasks.
Using Recovery Manager (RMAN), according to official documentation, is the recommended and one of the most optimal methods for backing up and restoring an Oracle database. And the ability to perform “hot” backups, leaving the database accessible for readings and changes, makes this utility a powerful tool for backing up highly accessible systems.
In the article, I will not talk about all the features of the Recovery manager, but I will describe one of the interesting backup strategies that allows you to take a fresh look at building a fault tolerance system in an enterprise. Incrementally updated backup technology appeared in the 10th version of Oracle. It provides the same recovery options as copying a database image (image copy), but is faster and has less load on system resources. This option also reduces recovery time due to fewer logs that must be used to update data.
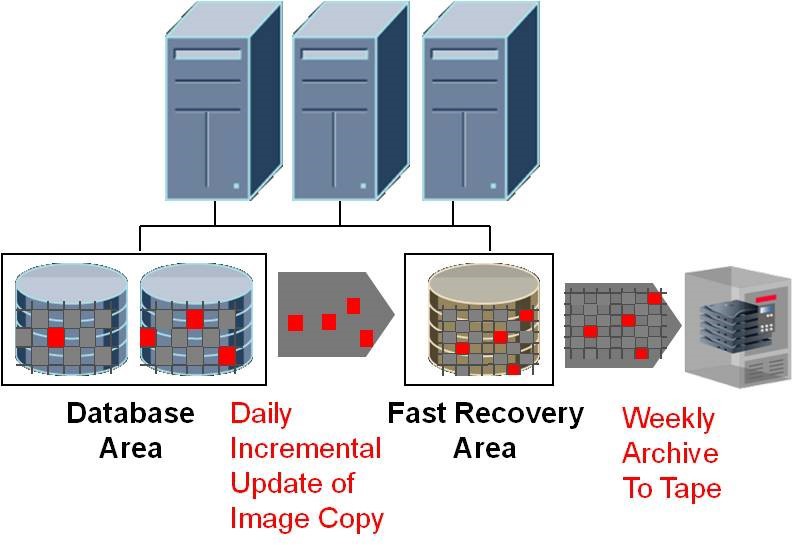
The essence of saving data with the help of Recovery manager is that we make a full copy of the database once, and then only copy the changes, and at the same time, every time when performing an incremental backup, the previous one is rolled onto the database image, updating the data. As a result, our physical-level backup always consists of a copy of data and a change file.
Consider a run example:
RUN
{
RECOVER COPY OF DATABASE
WITH TAG 'incremental';
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG 'incremental'
DATABASE;
}
We can schedule this command for daily execution. Here is how it will be interpreted:
Thanks to the chosen backup strategy, we can restore the database at the time of the last incremental backup. It is permissible to extend the interval, while maintaining the possibility of recovery for the period we need in the past, for example, to make a weekly recovery interval: thus, the incremental copy will not update the data until 7 days have passed since it was taken. At the same time, a new file with differential changes will be generated every day, which will be taken into account from the previous backup.
Consider an example recovery command with a window of 7 days:
RUN
{
RECOVER COPY OF DATABASE
WITH TAG 'incremental'
UNTIL TIME 'SYSDATE - 7';
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG 'incremental'
DATABASE;
}
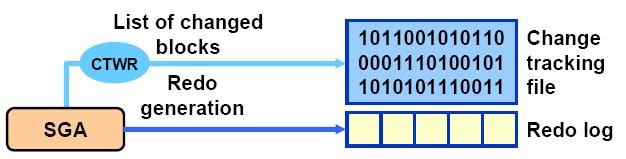
Together with an incrementally updated backup, we can use another technology - BLOCK CHANGE TRACKING. When performing a backup, the recovery manager examines each data block, tracking changes. The execution time of such a procedure is directly proportional to the size of the data files. It can be quite long, even if only a few blocks were changed. Starting with the 10th version, Oracle introduced a new technology - BLOCK CHANGE TRACKING, we can create a special file that records modified blocks since the previous backup. RMAN then uses it to identify the changes. You no longer need to fully study all the available data. Thus, the execution speed of an incremental copy is directly proportional to the changed blocks.
Using the above strategy for backing up the DBMS, we can quickly recover individual damaged files:
In this case, the instance will now operate on a file located in a new location. In the same way, you can return it to its original location.
In the event of the loss of all files, we can completely restore the entire database by pre-mounting it with the following command:
SWITCH DATABASE TO COPY;
RECOVER DATABASE;
The backup strategy presented in the article is a very effective way to protect the DBMS from data loss. The technology of fixing already changed blocks paired with incremental backup can significantly speed up the daily hot backup procedure. And the ability to quickly switch the damaged file to a fresh copy makes it a great help in systems critical to recovery time. It is also worth noting the simplicity of deploying a base clone, for example, for a development environment, because our backup is a full copy that does not require separate file manipulations.
The author is Oleg Konstantinov.
Using Recovery Manager (RMAN), according to official documentation, is the recommended and one of the most optimal methods for backing up and restoring an Oracle database. And the ability to perform “hot” backups, leaving the database accessible for readings and changes, makes this utility a powerful tool for backing up highly accessible systems.
In the article, I will not talk about all the features of the Recovery manager, but I will describe one of the interesting backup strategies that allows you to take a fresh look at building a fault tolerance system in an enterprise. Incrementally updated backup technology appeared in the 10th version of Oracle. It provides the same recovery options as copying a database image (image copy), but is faster and has less load on system resources. This option also reduces recovery time due to fewer logs that must be used to update data.
Concept
The essence of saving data with the help of Recovery manager is that we make a full copy of the database once, and then only copy the changes, and at the same time, every time when performing an incremental backup, the previous one is rolled onto the database image, updating the data. As a result, our physical-level backup always consists of a copy of data and a change file.
Consider a run example:
RUN
{
RECOVER COPY OF DATABASE
WITH TAG 'incremental';
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG 'incremental'
DATABASE;
}
We can schedule this command for daily execution. Here is how it will be interpreted:
Day 0
- RECOVER - since there is no incremental backup or a full copy, the command does not have any effect.
- BACKUP - since there is no copy of the data (level 0), the command creates it with the specified tag. This level is necessary to create a loop.
Day 1
- RECOVER - this time there are copies of the database, but there is no incremental backup of the first level that could be applied. The command has no effect.
- BACKUP - the team creates an incremental backup of the first level and assigns the necessary tag to it. It contains changes made from day 0 to 1.
Day 2 and thereafter
- RECOVER - an incremental backup of the first level made on the previous day is applied to the copy of the database, rolling forward the recorded changes.
- BACKUP - the team creates an incremental backup of the first level and assigns the necessary tag to it. It contains changes made from day 1 to day 2.
Thanks to the chosen backup strategy, we can restore the database at the time of the last incremental backup. It is permissible to extend the interval, while maintaining the possibility of recovery for the period we need in the past, for example, to make a weekly recovery interval: thus, the incremental copy will not update the data until 7 days have passed since it was taken. At the same time, a new file with differential changes will be generated every day, which will be taken into account from the previous backup.
Consider an example recovery command with a window of 7 days:
RUN
{
RECOVER COPY OF DATABASE
WITH TAG 'incremental'
UNTIL TIME 'SYSDATE - 7';
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG 'incremental'
DATABASE;
}
Optimization
Together with an incrementally updated backup, we can use another technology - BLOCK CHANGE TRACKING. When performing a backup, the recovery manager examines each data block, tracking changes. The execution time of such a procedure is directly proportional to the size of the data files. It can be quite long, even if only a few blocks were changed. Starting with the 10th version, Oracle introduced a new technology - BLOCK CHANGE TRACKING, we can create a special file that records modified blocks since the previous backup. RMAN then uses it to identify the changes. You no longer need to fully study all the available data. Thus, the execution speed of an incremental copy is directly proportional to the changed blocks.
- It is worth noting that the size of the change tracking file is very small and absolutely does not need administration (the proportion to the total size of all data files is approximately 1 / 30,000).
- By default, the file is located in the FRA zone, but can also be placed anywhere that is indicated when this functionality is turned on.
- RMAN does not reserve a change tracking file, so if it is damaged or accidentally deleted, you can simply create a new one (accordingly, the initial entry of the changed data will be performed again).
Quick recovery
Using the above strategy for backing up the DBMS, we can quickly recover individual damaged files:
- if the database is open - put the file offline;
- run the command: switch datafile 'datafile_name' to copy;
- execute recover to apply current logs;
- put the file online.
In this case, the instance will now operate on a file located in a new location. In the same way, you can return it to its original location.
In the event of the loss of all files, we can completely restore the entire database by pre-mounting it with the following command:
SWITCH DATABASE TO COPY;
RECOVER DATABASE;
Conclusion
The backup strategy presented in the article is a very effective way to protect the DBMS from data loss. The technology of fixing already changed blocks paired with incremental backup can significantly speed up the daily hot backup procedure. And the ability to quickly switch the damaged file to a fresh copy makes it a great help in systems critical to recovery time. It is also worth noting the simplicity of deploying a base clone, for example, for a development environment, because our backup is a full copy that does not require separate file manipulations.
The author is Oleg Konstantinov.