Automatic control using Windows registry remote access
- Tutorial
Support for proper, correct operation of computers and software for ordinary users - a routine of technical support staff and / or administrators. If the company is small and everyone is in one or two rooms, it is usually easy to go yourself and solve the problem or check what you need.
But what if the company is large and the user is located at another site / in another city / country?

One of the classic tools for this kind of work is a remote connection (using RDP, software like TeamViewer / Skype with a demonstration of the desktop, and so on). However, it is not without fundamental flaws:
- in any case, the end user will be distracted from his work (in some cases, even without seeing his desktop)
- these tools will not always work if there are errors on the remote computer
- installing third-party software (including proprietary software, in the case of TeamViewer) is not always welcomed by company policy
- the method is practically not automated
Finally, this approach is used when the incident has already occurred (it’s hard to imagine that the administrator would from time to time “proactively” connect to each user). That is why the control mechanism (monitoring) of remote computers is important.
One possible solution is to use remote access to the Windows registry. It stores data in the form of a hierarchical database, which allows them to be quickly received and stored compactly. Use the registry to store their own settings and parameters as the OS and built-in services, and most third-party programs. Therefore, the contents of the registry in many ways affects the operation of the system.
Based on this, the registry may well be used as an "indicator" for control (you can detect an error if it is associated with incorrect parameters in the registry or simulate a problem situation in yourself).
Another possibility that this solution gives is the possibility of administrative control of users (for example, remote reading allows you to see the facts of installing unwanted programs and making changes to settings) - do not forget about the influence of the "human factor" on the system. In practice, this was useful in the framework of the SkypeTime project , where it was necessary to track the correction of settings in Skype for Business.

But the registry contains thousands of entries, it is extremely difficult to control all of them. Therefore, first of all, it is necessary to limit the subject of control - to determine which parameters interest us and to find out which particular registry branches contain the corresponding values. As a rule, the latter is not difficult to find in the documentation / Internet, or to determine independently based on the names of the keys.
Having defined the subject of control, you can proceed to the direct configuration of remote access. To do this, you need to activate the Remote Procedure Call service on remote computers and configure the firewall as necessary, which is convenient to do using group policies. Taking into account the security requirements, access requires domain administrator or local administrator rights on each of the devices.
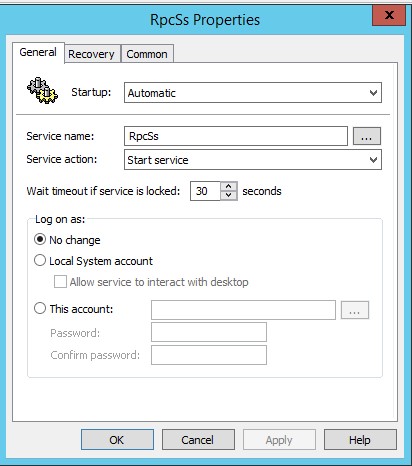
Для активации самой службы, в разделе Computer Configuration > Preferences > Control Panel Settings > Services задаем для службы RpcSs параметры, как на скрин-шоте
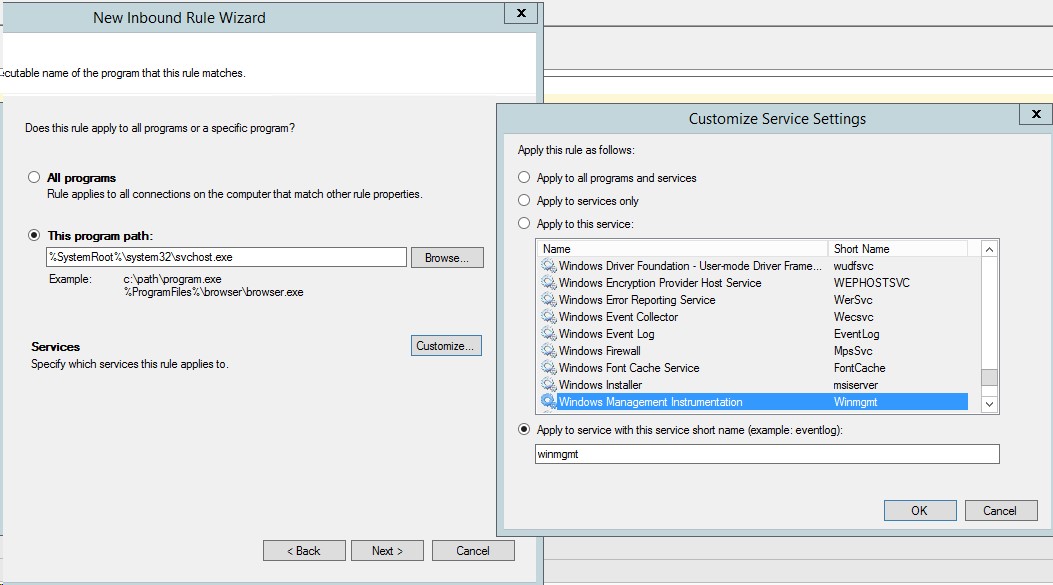
Осталось добавить соответствующие исключения Firewall. В этой же политике в разделе Computer Configuration > Policies > Windows Settings > Security Settings > Windows Firewall with Advanced Security > Inbound Rules создаем New Rule:
Rule Type – Custom

В качестве пути программы указываем – %SystemRoot%\system32\svchost.exe
Из дополнительных настроек в разделе Службы (Services) задаем Применять к службе со следующим кратким именем – Winmgmt
На следующих страницах задаем TCP без указания конкретных портов и для всех адресов

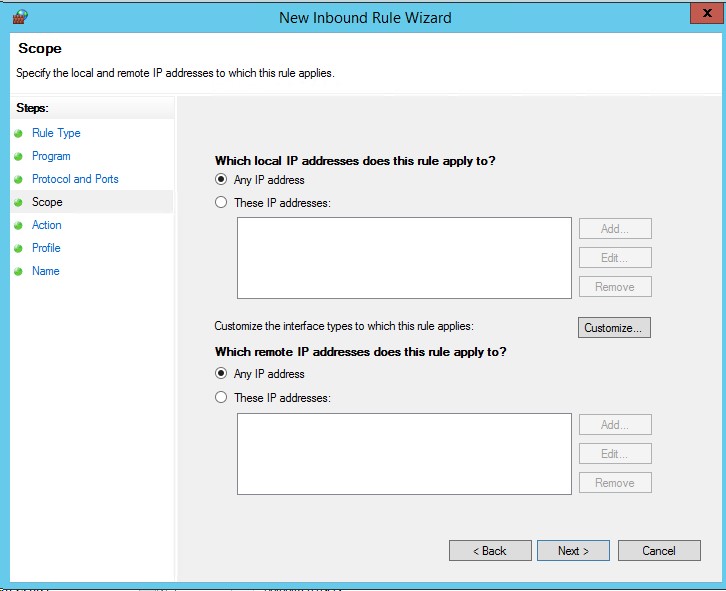
и разрешаем подключение (Allow the Connection) для доменного профиля


However, it is ungrateful and senseless to control the registry of tens and hundreds of computers "manually" (even though several records). Fortunately, this process is fairly easy to automate using scripts. For example, the following script on PowerShell allows you to find out which user has changed the AwayThreshold and IdleThreshold parameters (the time to “Out of place” and “Inactive”) for Skype for Business.
Param (
[alias("c")]
[string]$FromFileComputers,
[alias("r")]
[string]$OutputRPCErrorsFile,
[alias("u")]
[string]$FromFileUsers,
[alias("o")]
[string]$OutputFile="output.csv",
[alias("a")]
[int]$MinAway,
[alias("i")]
[int]$MinIdle
)
$RPCErrorsArray = @()
$result = @()
$HKU = 2147483651
$RegistryForCheckArray = "SOFTWARE\Microsoft\Office\13.0\Lync","SOFTWARE\Microsoft\Office\14.0\Lync","SOFTWARE\Microsoft\Office\15.0\Lync","SOFTWARE\Microsoft\Office\16.0\Lync","SOFTWARE\Microsoft\Communicator"
$CurrentComputerNumber = 0;
if(![string]::IsNullOrEmpty($FromFileUsers))
{
$Users = Get-Content $FromFileUsers;
}
if(![string]::IsNullOrEmpty($FromFileComputers))
{
$Comps = Get-Content $FromFileComputers;
}
else
{
$date = (get-date).AddMonths(-1)
$Comps = Get-ADComputer -filter { lastlogontimestamp -ge $date } | select name | ForEach-Object {$_.name}
#$Comps = "NB_CY"
}
$ServersCount = ($Comps).Count;
Foreach ($Comp in $Comps) {
$CurrentComputerNumber++
try
{
Write-Host "Checking: $Comp [$CurrentComputerNumber/$ServersCount]";
$profiles = Get-WmiObject Win32_UserProfile -filter"Loaded=$true and special=$false" -ComputerName $Comp -ErrorAction Stop
$reg = [wmiclass]"\\$Comp\root\default:stdregprov"
Foreach ($profile in $profiles)
{
$username = Split-Path $profile.LocalPath -Leaf
if(![string]::IsNullOrEmpty($FromFileUsers))
{
if(!$Users.Contains($username))
{
continue;
}
}
Foreach( $registry in $RegistryForCheckArray)
{
$hkey = "$($profile.sid)\$registry"
#Write-Host "KEY: $hkey"
$away = $reg.GetDWORDValue($hku,$hkey,"AwayThreshold").uValue
$idle = $reg.GetDWORDValue($hku,$hkey,"IdleThreshold").uValue
$sip = $reg.GetStringValue($hku,$hkey,"ServerSipUri").sValue
if([string]::IsNullOrEmpty($away) -and [string]::IsNullOrEmpty($idle))
{
continue;
}
if(($MinAway -gt 0 -and $away -lt $MinAway) -or ($MinIdle -gt 0 -and $idle -lt $MinIdle))
{
continue;
}
$result += New-Object PsObject -Property @{
"PC" = $Comp
"Username" = $username
"SIP" = $sip
"SFB_Away" = $away
"SFB_Idle" = $idle
}
}
}
}
catch
{
if ($_.Exception.GetType().Name -eq "COMException") {
$RPCErrorsArray += $Comp;
}
Write-Host "Error: ($_.Exception.GetType().Name)";
$_.Exception
}
}
$result | Export-csv -Path $OutputFile
$result | Format-Table -Property PC,Username,SIP,SFB_Away,SFB_Idle -AutoSize
Write-Host "Saved to: $OutputFile"if(![string]::IsNullOrEmpty($OutputRPCErrorsFile))
{
$RPCErrorsArray | out-file $OutputRPCErrorsFile
Write-Host "RPC errors saved to: $OutputRPCErrorsFile"
}For more convenience, the script can be run with the following parameters:
-c path to the file with the list of hostname computers to check, if not specified - receives computers from AD with activity for 30 days.
-r path to the file in which the hostname of the computers that had the RPC error will be written.
-u path to the file with the list of users (login), if not specified - checks all.
-o path to the file, in which the result of the script execution will be, by default output.csv.
-a is the minimum value for the AwayThreshold parameter, entries with a value less than the specified value will not receive the result of the script execution.
-i is the minimum value for the IdleThreshold parameter, entries with a value less than the specified one will not receive the result of the script execution.
Next, the script launch can be automated by adding to the Windows Task Scheduler (Task Scheduler) or via the Sheduled Job functionality in PowerShell.