Sentiment text analysis
- Tutorial
Sentiment analysis of information flows has great potential for monitoring, analytical and signaling systems, for workflow systems and advertising platforms targeted on the subject of web pages.
This material introduces the concept of sentiment analysis, the basic methods for determining tonality and new approaches in this area.

Natural language text, in addition to information, can express an emotional appreciation of what is being reported. For example, such a proposal contains a negative assessment of what is happening:
(1) In 2012, Armstrong, following an investigation by the American Anti-Doping Agency, was convicted of using illegal drugs.
And this is positive:
(2) Apple has received final permission to build a new campus.
The emotional assessment expressed in the text is called the tonality or sentiment (from English sentiment - feeling; opinion, mood) of the text. A person evaluates the world at once on many scales (good-bad, strong-weak, big-small, happy-unhappy, funny-sad, fast-slow, etc.), and these scales are emotionally loaded in different ways. But for simplicity, we can assume that the emotional rating comes down to a good-bad or positive-negative scale.
Historically, the traditional approach to sentiment analysis has been the task of classifying a text (part of a text) into two or three categories (negative, positive, neutral, or simply: negative or positive) [Pang & Lee; Turney]. It was with such a task that the analysis of tonality began its development: to evaluate the sentiment of evaluative reviews on any topic (cinema, restaurants, electronics, etc.).
Nevertheless, this is not the only and non-determining type of task that sentiment analysis of the text should solve. Currently, readers are not interested in the overall emotional assessment of the text (the average temperature in the hospital), but in the attitude of sentiment to a specific object mentioned in the text, or the attitude of the subject of the utterance to the object under discussion.
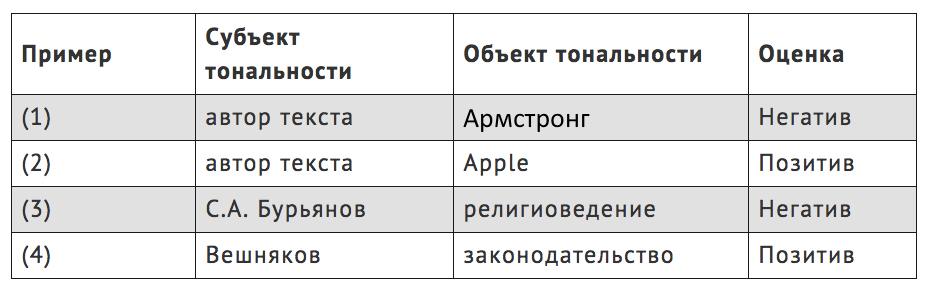
The object relative to which an emotional assessment is expressed is commonly called the object of tonality. So, in sentence (1) the object of tonality is Armstrong , and in sentence (2) - Apple . This kind of sentiment analysis is called object-based.
The carrier of the emotional assessment expressed in the text is also usually a well-defined person, in the general case it is the author of the text. However, if the author of the text refers to someone’s opinion, as in sentence (3) below, or cites another person’s statement, as in sentence (4), then the carrier of the emotional assessment, or, as they say, the subject of tonality will be the one on whose opinion is referenced.
(3) Religious studies, according to S. A. Buryanov, today is not an exact science characterized by unity and has strict and generally accepted principles.
(4) The head of the Central Election Commission, Veshnyakov, yesterday once again praised the changes to the election law and said that now the legislation covers many loopholes for abuse.
Thus, the tonality of the utterance is determined by three components: the subject of tonality (who made the assessment), the object of tonality (about whom or what the assessment is expressed about) and the actual tonal assessment (as estimated). In our examples, you can find such components of tonality:
In one sentence, several emotional assessments can be made simultaneously regarding different objects of tonality:
(5) Samsung was obliged to payApple compensation of $ 290 million.
Regarding Apple, this is rather a positive event, which can not be said about Samsung .
There can also be a different tonality with respect to the same object:
(6) Caramel-based Lemonade “Beloved”, so loved by customers in our region, can provoke the development of diseases.
Here the object “lemonade” is mentioned both in a positive way and in a negative way.
Another direction of sentiment analysis is the identification of negativity / positivity of attributes of the tonality object (feature-based / aspect-based sentiment analysis), for example,
(7) Another plus of this smartphone is the light indicator, which significantly saves battery power, supports flash drives up to 8 GB, but the camera is very weak.
Here, the object of tonality is a “smartphone”, but its tonality consists of several factors (light indicator, battery, flash drive, camera), which can have different polarity. Thus, the task here is to identify the attributes of the product (object) and determine their tonality. Moreover, the same qualitative characteristic for one attribute can be positive, and it can be negative for another attribute (for example, a “big battery” for a phone is rather good, but a “big weight” for a phone is rather bad).
In addition to tonality itself, the text can be judged by the subjectivity / objectivity of judgment (Opinion Mining). If this is the opinion of the author of the statement containing a subjective assessment of what is being described, then the text is considered subjective. Conversely, if this is a media report or opinion, by default shared by the participants in the dialogue, then it is considered objective.
For example, a message from the social network:
(8) For now, I remain with my own opinion - the Samsung Galaxy Note 3 is the best gadget that passed through my hands!
has a subjective rating for the smartphone. A text from the media:
(9) Promsvyazbank has strengthened its position in the top 10 Russian banks in terms of a portfolio of loans to organizations.
contains objective information.
Subjective information will include direct and indirect speech in the text, as well as citation (see examples 3 and 4). In such cases, the automatic determination of the subjectivity / objectivity of a statement is technically much easier to implement than in the general case.
Methods for determining tonality
There are two main methods for solving this problem of automatic determination of tonality:
In addition, sometimes a mixed method is used (a combination of the first and second approaches).
In the statistical approach, to solve the problem of general classification of texts into tonality classes, the support vector method (SVM), Bayesian models, various kinds of regressions are widely used [Chetviorkin & Loukachevitch - description of ROMIP-2011 competition for sentiment analysis of data, almost all participants used SVM or Bayes] .
If the goal is to determine the tonality of a specific, predetermined object (several objects), then more complex statistical algorithms are used, such as CRF [Antonova and Soloviev], semantic proximity algorithms (for example, latent-semantic analysis - LSA, latent Dirichlet allocation - LDA) and others, as well as methods based on the rules [Pazelskaya and Soloviev].
To determine the attributive tonality, language models [García-Moya & all], neural networks [Tarasov], or thematic thesauri are used.
SentiFinder tonality determination
module The SentiFinder module determines three types of tonality of Russian-language texts (positive, negative and neutral) with respect to a given tonality object both within a single sentence and averaged throughout the document.
The module is implemented on an algorithm of random Markov fields using tonal dictionaries. This made it possible to achieve not only good quality (average accuracy in three types of tonality of about 87%.) And high speed of word processing (the speed of the SentiFinder module is more than 100 kB / s on one stream).
A feature of this module is that it allows you to evaluate the power of emotionality. Thus, the user is given the opportunity not only to obtain a qualitative emotive assessment of the document as a whole regarding the object of interest of tonality, but also a quantitative ratio of the negative and positive attitude towards it.
The module can work with both “classic” texts of the news stream and the “non-classical” language of social messages. media.
You can get acquainted with this service on the website eurekaengine.ru
References
This material introduces the concept of sentiment analysis, the basic methods for determining tonality and new approaches in this area.
Natural language text, in addition to information, can express an emotional appreciation of what is being reported. For example, such a proposal contains a negative assessment of what is happening:
(1) In 2012, Armstrong, following an investigation by the American Anti-Doping Agency, was convicted of using illegal drugs.
And this is positive:
(2) Apple has received final permission to build a new campus.
The emotional assessment expressed in the text is called the tonality or sentiment (from English sentiment - feeling; opinion, mood) of the text. A person evaluates the world at once on many scales (good-bad, strong-weak, big-small, happy-unhappy, funny-sad, fast-slow, etc.), and these scales are emotionally loaded in different ways. But for simplicity, we can assume that the emotional rating comes down to a good-bad or positive-negative scale.
Historically, the traditional approach to sentiment analysis has been the task of classifying a text (part of a text) into two or three categories (negative, positive, neutral, or simply: negative or positive) [Pang & Lee; Turney]. It was with such a task that the analysis of tonality began its development: to evaluate the sentiment of evaluative reviews on any topic (cinema, restaurants, electronics, etc.).
Nevertheless, this is not the only and non-determining type of task that sentiment analysis of the text should solve. Currently, readers are not interested in the overall emotional assessment of the text (the average temperature in the hospital), but in the attitude of sentiment to a specific object mentioned in the text, or the attitude of the subject of the utterance to the object under discussion.
The object relative to which an emotional assessment is expressed is commonly called the object of tonality. So, in sentence (1) the object of tonality is Armstrong , and in sentence (2) - Apple . This kind of sentiment analysis is called object-based.
The carrier of the emotional assessment expressed in the text is also usually a well-defined person, in the general case it is the author of the text. However, if the author of the text refers to someone’s opinion, as in sentence (3) below, or cites another person’s statement, as in sentence (4), then the carrier of the emotional assessment, or, as they say, the subject of tonality will be the one on whose opinion is referenced.
(3) Religious studies, according to S. A. Buryanov, today is not an exact science characterized by unity and has strict and generally accepted principles.
(4) The head of the Central Election Commission, Veshnyakov, yesterday once again praised the changes to the election law and said that now the legislation covers many loopholes for abuse.
Thus, the tonality of the utterance is determined by three components: the subject of tonality (who made the assessment), the object of tonality (about whom or what the assessment is expressed about) and the actual tonal assessment (as estimated). In our examples, you can find such components of tonality:
In one sentence, several emotional assessments can be made simultaneously regarding different objects of tonality:
(5) Samsung was obliged to payApple compensation of $ 290 million.
Regarding Apple, this is rather a positive event, which can not be said about Samsung .
There can also be a different tonality with respect to the same object:
(6) Caramel-based Lemonade “Beloved”, so loved by customers in our region, can provoke the development of diseases.
Here the object “lemonade” is mentioned both in a positive way and in a negative way.
Another direction of sentiment analysis is the identification of negativity / positivity of attributes of the tonality object (feature-based / aspect-based sentiment analysis), for example,
(7) Another plus of this smartphone is the light indicator, which significantly saves battery power, supports flash drives up to 8 GB, but the camera is very weak.
Here, the object of tonality is a “smartphone”, but its tonality consists of several factors (light indicator, battery, flash drive, camera), which can have different polarity. Thus, the task here is to identify the attributes of the product (object) and determine their tonality. Moreover, the same qualitative characteristic for one attribute can be positive, and it can be negative for another attribute (for example, a “big battery” for a phone is rather good, but a “big weight” for a phone is rather bad).
In addition to tonality itself, the text can be judged by the subjectivity / objectivity of judgment (Opinion Mining). If this is the opinion of the author of the statement containing a subjective assessment of what is being described, then the text is considered subjective. Conversely, if this is a media report or opinion, by default shared by the participants in the dialogue, then it is considered objective.
For example, a message from the social network:
(8) For now, I remain with my own opinion - the Samsung Galaxy Note 3 is the best gadget that passed through my hands!
has a subjective rating for the smartphone. A text from the media:
(9) Promsvyazbank has strengthened its position in the top 10 Russian banks in terms of a portfolio of loans to organizations.
contains objective information.
Subjective information will include direct and indirect speech in the text, as well as citation (see examples 3 and 4). In such cases, the automatic determination of the subjectivity / objectivity of a statement is technically much easier to implement than in the general case.
Methods for determining tonality
There are two main methods for solving this problem of automatic determination of tonality:
- The statistical method. For it we need the collections (corpus) of texts previously marked by tonality, on which the model is trained, with the help of which the tonality of the text or phrase is determined.
- A method based on dictionaries and rules. For this, dictionaries of positive and negative words and expressions are pre-compiled. This method can use both lists of templates and rules for connecting tonal vocabulary within sentences, based on grammar and parsing.
In addition, sometimes a mixed method is used (a combination of the first and second approaches).
In the statistical approach, to solve the problem of general classification of texts into tonality classes, the support vector method (SVM), Bayesian models, various kinds of regressions are widely used [Chetviorkin & Loukachevitch - description of ROMIP-2011 competition for sentiment analysis of data, almost all participants used SVM or Bayes] .
If the goal is to determine the tonality of a specific, predetermined object (several objects), then more complex statistical algorithms are used, such as CRF [Antonova and Soloviev], semantic proximity algorithms (for example, latent-semantic analysis - LSA, latent Dirichlet allocation - LDA) and others, as well as methods based on the rules [Pazelskaya and Soloviev].
To determine the attributive tonality, language models [García-Moya & all], neural networks [Tarasov], or thematic thesauri are used.
SentiFinder tonality determination
module The SentiFinder module determines three types of tonality of Russian-language texts (positive, negative and neutral) with respect to a given tonality object both within a single sentence and averaged throughout the document.
The module is implemented on an algorithm of random Markov fields using tonal dictionaries. This made it possible to achieve not only good quality (average accuracy in three types of tonality of about 87%.) And high speed of word processing (the speed of the SentiFinder module is more than 100 kB / s on one stream).
A feature of this module is that it allows you to evaluate the power of emotionality. Thus, the user is given the opportunity not only to obtain a qualitative emotive assessment of the document as a whole regarding the object of interest of tonality, but also a quantitative ratio of the negative and positive attitude towards it.
The module can work with both “classic” texts of the news stream and the “non-classical” language of social messages. media.
You can get acquainted with this service on the website eurekaengine.ru
References
- Bo Pang, Lillian Lee, Shivakumar Vaithyanathan Thumbs up? Sentiment Classification using Machine Learning Techniques // - 2002. - S. 79–86.
- Peter Turney Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews // Proceedings of the Association for Computational Linguistics. - 2002. - S. 417-424. - arΧiv: LG / 0212032
- Anna Antonova and Aleksey Soloviev, Using the method of conditional random fields for processing texts in Russian. Computer Linguistics and Intelligent Technologies: Dialogue 2013. Sat scientific articles / Vol. 12 (19) .- M.: Publishing House of the Russian State Humanitarian University, 2013.– P.27-44.
- Sentiment Analysis Track at ROMIP-2012. Chetviorkin II, Loukachevitch NV Computer Linguistics and Intelligent Technology. Computer Linguistics and Intelligent Technologies: Dialogue 2013. Sat scientific articles volume 2, p. 40-50.
- Anna Pazelskaya and Alexey Soloviev, Method for the determination of emotions in texts in Russian. Computational linguistics and intellectual technologies. Computational linguistics and intellectual technologies: “Dialog-2011”. Sat scientific articles / Vol. 11 (18) .- M.: Publishing House of the Russian State Humanitarian University, 2011.– P.510-523.
- Tarasov DS Deep Recurrent Neural Networks for Multiple Language Aspect-Based Sentiment Analysis // Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue-2015”, Issue 14 (21), V.2, pp. 65-74 (2015).
- García-Moya, L., Anaya-Sanchez, H., Berlanga-Llavori, R .: Retrieving product features and opinions from customer reviews. IEEE Intelligent Systems 28 (3), 19–27 (2013)