How to write a simple tsumego lattice
 About a year ago, a friend showed me what Go is and how it is played. I well remember how in one of the first games I proudly built a chain of stones that connected the bottom side of the board to the top, as well as a chain connecting the left side to the right, to which my friend told me that this was certainly good, but I lost. It then took me a long time to understand why. Since then, I have progressed to about the first KGS dan, and a friend has stopped playing with me.
About a year ago, a friend showed me what Go is and how it is played. I well remember how in one of the first games I proudly built a chain of stones that connected the bottom side of the board to the top, as well as a chain connecting the left side to the right, to which my friend told me that this was certainly good, but I lost. It then took me a long time to understand why. Since then, I have progressed to about the first KGS dan, and a friend has stopped playing with me.To play well in go you need to see a few moves ahead, and this skill develops well the solution of which there are many on goproblems. Naturally, one day I was struck by the thought that it would be nice to write a lattice of these things and, ideally, embed it in goproblems, especially since adum approves this idea. Since I myself am solving it by a very leisurely method of trying more or less meaningful moves at a speed of about 1 move in a couple of seconds, while regularly forgetting how the search started (and this is enough to confidently solve problems 3 given), I figured out how incredible speed and accuracy will work the simplest search in depth, that is, dfs, and rated the complexity of the task as “for a couple of days”. Immediately, I tried to quickly write this grille “head-on” through the simplest dfs and stumbled upon a minor nuisance: in the process of searching, the same positions were met many times and recounting them anew was somehow completely suboptimal even for a fast-written lattice. Without thinking twice, I started a cache for storing already resolved positions and immediately stumbled upon another nuisance: the solution found once may be incorrect if you come to this position by another sequence of moves. Here I hung, not knowing what to do, but decided that this trouble is easily solved - you just need to think a little. I thought for a long time and decided that it makes sense to see what is already ready on this topic - articles, algorithms, etc. The first thing that caught my eye was a certain “lambda depth first proof number search” and seeing that the size of the article was only a few pages, I started to read with pleasure. The article found links to other similar articles by Martin Mueller and Akiro Kishimoto, there is still a link in those articles, there appeared a link to a 200-page dissertation by Kishimoto, and then I realized the scale of the problem: the solution of even very simple ones was so algorithmically complex that in most cases the question is not even how to sort through all the options, but how to generally find something on the board (which even a novice player does in a second), how to understand what needs to be captured or defended (also trivial for a person) and what moves make sense (also obvious in most cases) and if it comes to actually sorting out var Antes, then we can say tsumego decided (although efficient sorting algorithm is extremely catchy). In general, I realized that my IQ is clearly not enough to solve such a problem on the go and I decided
As far as I know, there are very few programs that solve everything:
- GoTools by Thomas Wolf: up to 15 possible moves, closed source code, straightforward dfs with very advanced static analysis.
- Martin Müller's Tsumego Explorer (which, by the way, is 7 given): up to 30 possible moves, open source Java (although it is not clear where to get it), advanced l-df-pn-r search with the very advanced static analysis described in Muller's articles and dissertation Kishimoto.
- Martin Muller's Fuego: a full-fledged 2+ bot is given (I can’t appreciate its strength because it is clearly stronger than me) with open source C ++ (can be downloaded from SourceForge).
Neither Mueller nor adum heard about any js solvers (and the solver must be on js so that it can be embedded in goproblems), and if so, it makes sense to try to write it - especially since Mueller and Kishimoto wrote a lot of articles and even programs on this topic.
 On the left is a typical tsumego. In the general case, the task is to find the best move (and whether it is needed at all) for both black and white. Obviously, if White moves first, they capture the corner. If Black moves first, then they can save the angle, but one of the solutions leads to ko and if Black loses to ko, they lose the angle, and the other solution preserves the angle without any ko, which is usually preferable.
On the left is a typical tsumego. In the general case, the task is to find the best move (and whether it is needed at all) for both black and white. Obviously, if White moves first, they capture the corner. If Black moves first, then they can save the angle, but one of the solutions leads to ko and if Black loses to ko, they lose the angle, and the other solution preserves the angle without any ko, which is usually preferable.For simplicity, we assume that there is some way to look at the board and find out all meaningful moves that need to be sorted out to solve (in fact, this means that all such moves will be set manually). We define a function R that says who wins on board b:
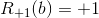 if black starts and wins.
if black starts and wins.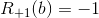 if black starts and loses.
if black starts and loses.
By the definition of R, Black is obliged to make the first move even if he upsets the balance in the sec - this eliminates the situation in which White and Black constantly pass. Similarly for whites. If both black and white lose, these are the seks. Then this function can be recursively defined as follows:
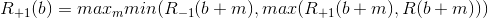
It looks a bit confusing, but its essence is simple:
- By the definition of R, Black is forced to make some kind of move, so they choose the best among all possible moves. Hence the maximum for all moves m.
- Then the move goes to White and they may decide to make a move or not - this is the minimum. If White makes a move, the result will be
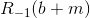 where b + m is the board b to which black stone m was added.
where b + m is the board b to which black stone m was added. - If White misses the move (and this does not contradict the definition of R), then Black has a choice: make a move or save too, which will end the game - this is the second maximum. If Black makes a move, it turns out
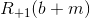 , and if he passes, then R (b + m) determines who won (in practice, this is just a check to see if there is a stone on the board that needed to be captured).
, and if he passes, then R (b + m) determines who won (in practice, this is just a check to see if there is a stone on the board that needed to be captured).
The symmetric formula is obtained for whites. If you count it “forehead”, you get a straightforward dfs with enumeration of all options, which even for the simplest attack of 5 points works very slowly. You can write it like this:
function solve(board: Board, color: Color): Result {
var result = -color; // that's a loss
for (const move of board.getMovesFor(color)) {
const nextBoard = board.fork().play(move);
result = bestFor(color, // it's +color's turn, so he chooses
result,
bestFor(-color, // now it's -color's turn
solve(nextBoard, -color), // -color makes a move
bestFor(color, // -color can pass, but then it's +color's turn again
solve(nextBoard, color), // +color makes two moves in a row
estimate(nextBoard)))); // neither player makes a move
}
return result;
}
Note that this algorithm will spend a lot of time wasting time proving that the simplest secs are secs. If the white and black groups have only common freedoms and there are many of these freedoms, then this algorithm will first try to play in the first freedom, find out that it does not work out, then play in the second freedom and again find out that it is impossible to win, etc. You can even create a simple recursive formula for the number of moves that this algorithm will make to iterate over all the options. Growth is more than exponential. This problem can probably be solved only by static analysis.
Now we need to make sure that the same board is not solved twice. For example, once you find a solution for a 5-point overpass, you can reuse it if another position reduces to that overpass. Such a solution cache is usually called a transposition table (tt). The key in this table will be the hash of the board + the color of the one who goes first. At first, I naively implemented it like this:
const tt: { [key: string]: Result } = {};
function solve(board: Board, color: Color): Result {
const key = color + board.hash();
var result = -color; // that's a loss
if (key in tt)
return tt[key];
for (const move of board.getMovesFor(color)) {
const nextBoard = board.fork().play(move);
result = bestFor(color, // it's +color's turn, so he chooses
result,
bestFor(-color, // now it's -color's turn
solve(nextBoard, -color), // -color makes a move
bestFor(color, // -color can pass, but then it's +color's turn again
solve(nextBoard, color), // +color makes two moves in a row
estimate(nextBoard)))); // neither player makes a move
}
return tt[key] = result;
}
The solution to this problem is mentioned many times in the articles of Müller and Kishimoto and it sounds like this: if no repetition was found in the search for a solution, then it does not depend on the path that came to this position. If you think about it, then the statement is not at all obvious. When I was tired of coming up with a proof, I wrote to Müller and he said that yes, this is a very strong and universal statement and the proof seems to be somewhere in the dissertation. I couldn’t find this proof there, but I thought of my own one which works if we assume that all solutions already resolved and independent of the path are never deleted (due to lack of memory).
- solution for 13 is already cached and what
- all intermediate solutions that were also found without detecting cycles remained in the cache.
Let's say that we start from vertex 17 and try to get to 13. The essence of the proof is that since there are no cycles in the decision tree, then to connect 17 to 13 you need to go beyond the tree, which is impossible. Vertex 17 is white (well, yes, it is red, but we assume that it is white) and therefore all the moves from it are in the tree: we make any move from 17 and still remain in the decision tree. Let's say we hit the 25th black peak. Since the vertex is black, then the solution (the right move) for it is written in the cache (from which nothing is ever deleted) and since we go along this hypothetical path after the solution for 25 has been found, we are forced to take a ready-made solution from the cache and get into the white peak that is still in the tree. So we follow this hypothetical path until we find ourselves at an impasse with no moves.
As you can see, in order to solve the problem with loops, you need quite a bit:
- Look for a solution for the path, not for the position: solve (path: Board [], color: Color).
- If during the search we come across a repetition, we consider it a defeat, but at the same time we point to the top in the path that repeats (just remember the index in the path). The meaning of the pair (result, index) is that the solution is not unconditional, but depends on repetition with a certain position.
- If among all possible moves all lead to defeat, we find the minimum among all indices indicating repetition and return this minimum.
- If there are winning moves, it is preferable to choose the one with the repetition index as large as possible. In the best case, the gain will be unconditional, i.e. not depend on the path.
This (and a simple heuristic that maximizes the freedom of its stones and minimizes the freedom of others) is enough to solve the simplest carpenter square.
To solve something more interesting, like the first one, you need to be able to consider co. One possible approach is to consider “dynamically”, i.e. if a repetition occurs in the search process, branch the search into two cases (when there is a threat and when there is none), but for this you will have to thoroughly shovel the entire code. Another approach is “static” accounting for:
- The new parameter is the number of external threats. Say, if this parameter is +3, then Black has three more threats, and if -2, then White has two more threats.
- If in the process of solving a repetition occurs and there is a threat to this repetition, it is wasted, the path is reset (in fact, the goal of the threat is to reset the path and start the search, as it were, from scratch).
- Decisions in the cache are written not as a single number (+1 or -1), but as an endless array of numbers on both sides where the result is written for each number of threats: for -2 threats, White wins, if White only has 1 threat, then it turns out seca, and if there are no threats, then black wins. Obviously, if Black wins with N threats, then he will win with N + 1 as well. Similarly for whites. This shows that the solution can be written in the form of two numbers: the number of threats that is black enough to win (maxb), and the number of threats that is white enough to win (minw). Then if we are looking for a solution for position b having k co threats and for b minw and maxb are known from previous attempts to solve, then we can immediately return the answer for k <minw (White wins) and for k> maxb (Black wins), and for minw <k <
interface Results {
minw: number; // white wins if nkt <= minw
maxb: number; // black wins if nkt >= maxb
}
const tt: { [key: string]: Results } = {};
function solve(path: Board[], color: Color, nkt: number): Result {
function solveFor(color: Color, nkt: number): Result {
const board = path[path.length - 1];
const key = color + board;
const cached = tt[key] || { minw: -Infinity, maxb: +Infinity };
if (color > 0 && nkt >= cached.maxb)
return +1; // black has enough ko treats to win
if (color < 0 && nkt <= cached.minw)
return -1; // white has enough ko treats to win
var result = -color; // that's a loss
var depth = Infinity; // where repetition occured
/* ... */
if (color > 0 && nkt < cached.maxb)
cached.maxb = nkt;
if (color < 0 && nkt > cached.minw)
cached.minw = nkt;
tt[key] = cached;
return [result, depth];
}
return solveFor(color, nkt);
}
Now, in order to solve the problem taking into account external threats, we must first solve it under the assumption that there are no threats (nkt = 0) and continue to increase or decrease this parameter until this can change the result. This, theoretically, can be determined by the decision graph: if the solution found depends on the lost ko, then it makes sense to add one external ko threat and solve it again. In fact, I did not do this, and the number of threats needed extremely rarely exceeds 1, i.e. there are problems in which you need to win two ko to solve, but this is exotic, so if you solve it for | nk2 | <2, then you can, in general, say that the problem is solved. It should be noted that this way 99% of the time is spent searching for the first solution (usually for nkt = 0) that fills the cache (tt) after which the solutions for other nkt are found almost instantly (even on JS).
That's all. Such a simple lattice on JS without any optimizations, which creates temporary objects for everyone (what GC loads), and before each move copies the entire board, is able to quickly, in a few seconds, solve everything with 10 free cells (like that, what I showed at the beginning). At just a little larger, it just hangs and will load the GC most of the time. However, I don’t see the point in optimizations of this kind, because there are a bunch of ways to make the algorithm itself faster:
- Apply advanced depth search: dfpn, dfpnr, ldfpnr. Muller writes that ldfpnr can overpower it with 27 free cells, which is a lot.
- To write static analysis algorithms - I haven't even implemented Benson's algorithm yet. This will stop the search when it is clear who won. This is probably the main reason that we can solve everything so quickly: usually finding a solution in the mind looks like sorting out a few short sequences that end with the assessment “well, here, obviously, white is captured.”
- Come up with how to look for something on the board and where to make moves. To do this, you only need to “carefully” carefully observe your own thinking and understand how exactly we find something. The key to this search, of course, is to assess the survivability of the group (a handful of closely spaced stones), which is based on determining whether the group can make two eyes: it is always located near a weak and relatively large group (so that it makes sense to capture or save it).
- Make some kind of tricks library (tesuji): squeeze, wedge, snapback, ladder, net, etc. These tricks play a huge role in finding a solution in the mind: after all, we do not calculate every possible option every time to find a snapback - we just notice a characteristic combination of stones and check if something can be squeezed out of this trick.
Who cares , you can see the code on the github . There, frankly, everything needs to be rewritten nafig as soon as I understand how to organize the lattice code so that it is divided into modules without sacrificing speed and so that later it is possible to connect the modules responsible for static analysis, for sec recognition, for different tricks etc. Well, so that you can write unit tests, otherwise after each change, I think, “does this crap still work?”