Practice using the actor model in the back end platform of Quake Champions
I continue to lay out reports with Pixonic DevGAMM Talks - our September mitap for developers of highly loaded systems. They shared a lot of experience and cases, and today I am publishing a transcript of a speech by the backend developer from Saber Interactive, Roman Rogozin. He talked about the practice of using the actor model on the example of controlling players and their states (other reports can be found in the end of the article, the list is supplemented).
Our team is working on a backend for Quake Champions, and I’ll talk about what an actor model is and how it is used in the project.
A little about the stack of technology. We write code in C #, respectively, all technologies are tied to it. I want to note that there will be some specific things that I will show with the example of this language, but the general principles will remain unchanged.

At the moment we are hosting our services in Azure. There are some very interesting primitives that we don’t want to give up, such as Table Storage and Cosmos DB (but we try hard not to tie them up for the sake of the cross-platform project).
Now I would like to talk a little bit about what an actor model is. And let me begin by saying that it, as a principle, appeared more than 40 years ago.
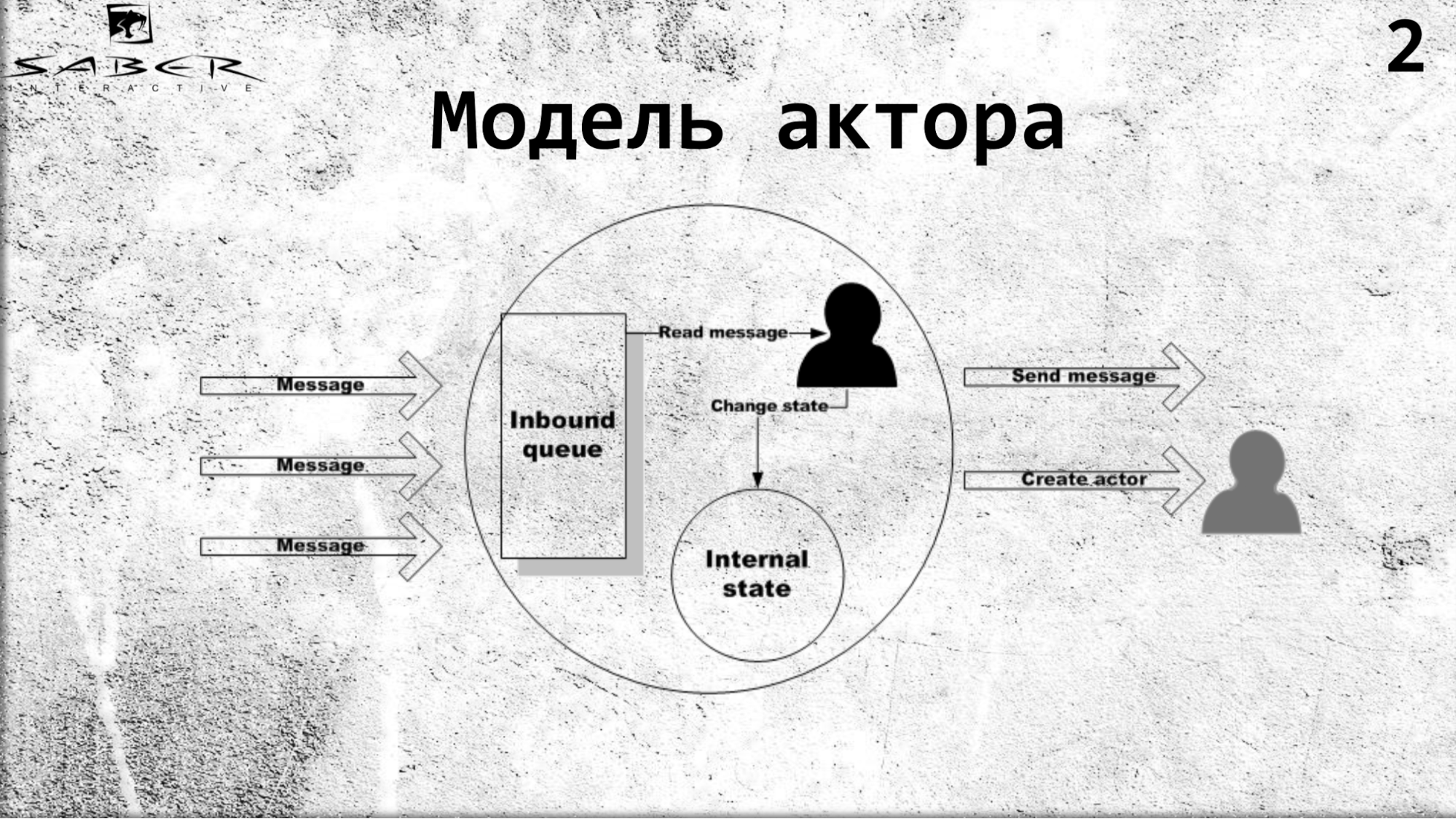
Actor is a parallel computing model that states that there is some isolated object that has its own internal state and exclusive access to change this state. The actor can read messages, and consistently, perform some kind of business logic, change the internal state if desired, and send messages to external services, including other actors. And he can create other actors.
Actors communicate among themselves with asynchronous messages, which allows you to create highly loaded distributed cloud systems. In this regard, the actor model and received widespread recently.
Summarizing what has been said, let's imagine that we have cloud, where there is a cluster of servers, and our actors are spinning on this cluster.
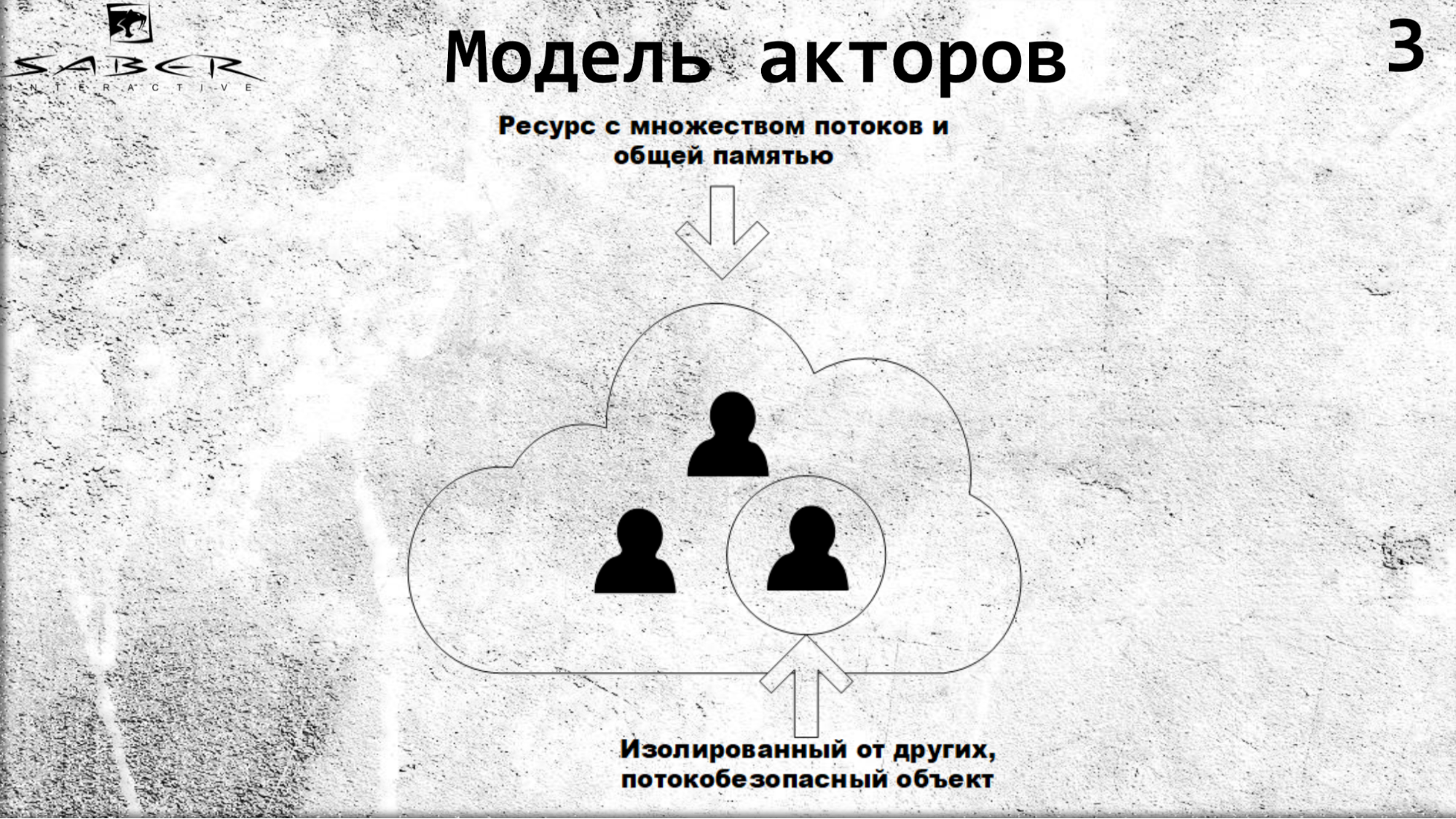
Actors are isolated from each other, communicate through asynchronous calls, and within themselves the actors are thread-safe.
How it might look like. Suppose we have several users (not a very large load), and at some point we understand that there is an influx of players, and we need to urgently make upscale.
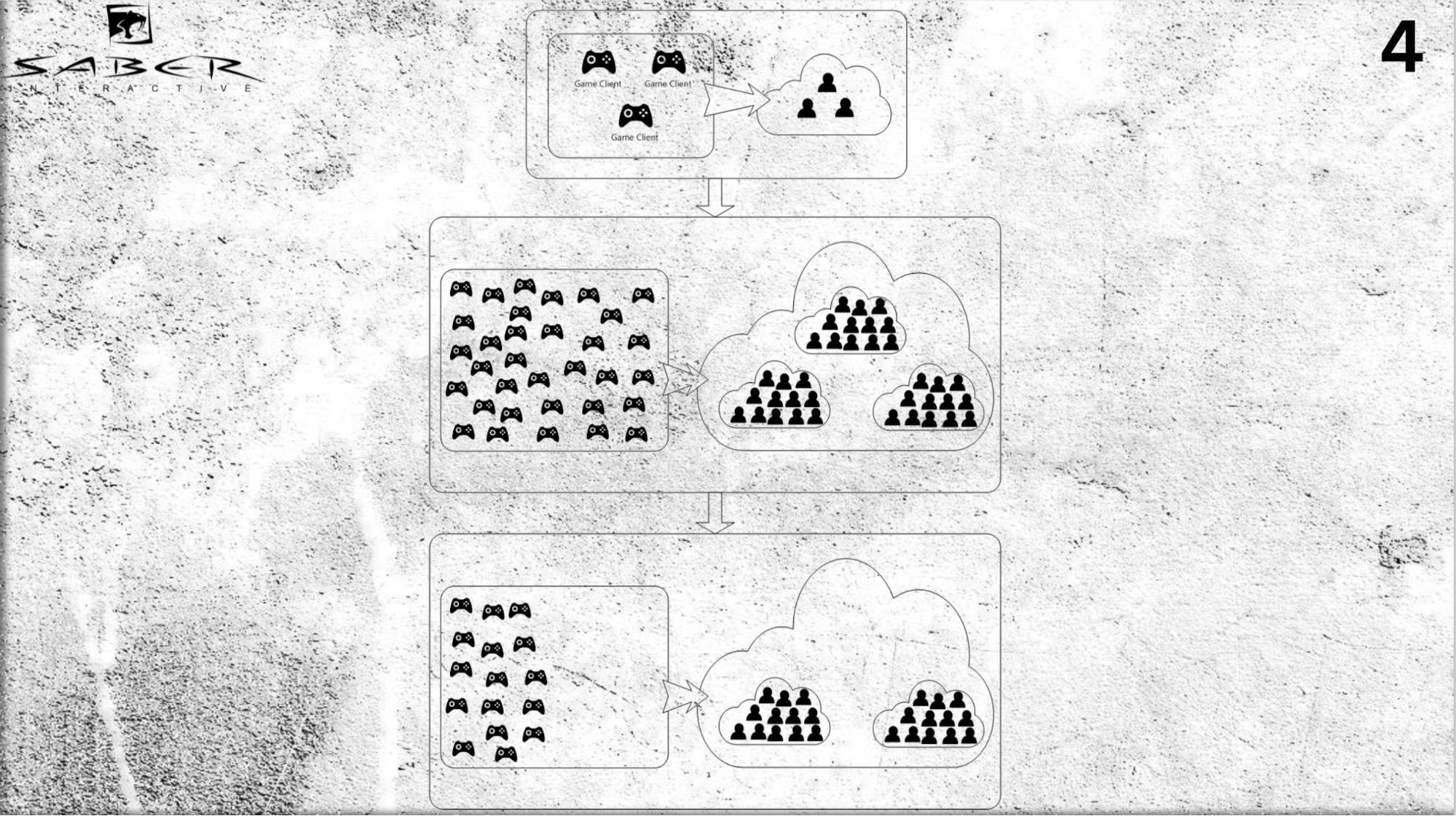
We can add servers to our cloud and, using the actor model, stuff individual users — assign each actor to each individual and allocate space for memory and processor time for that actor in the cloud.
Thus, the actor, firstly, plays the role of a cache, and secondly, it is a la “smart cache”, which is able to process some messages, to execute business logic. Again, if you need to do a downscale (for example, the players are out) - there is also no problem to remove these actors from the system.
We in backend'e use not the classical actor model, but on the basis of the Orleans framework. What is the difference - I will try to tell you now.

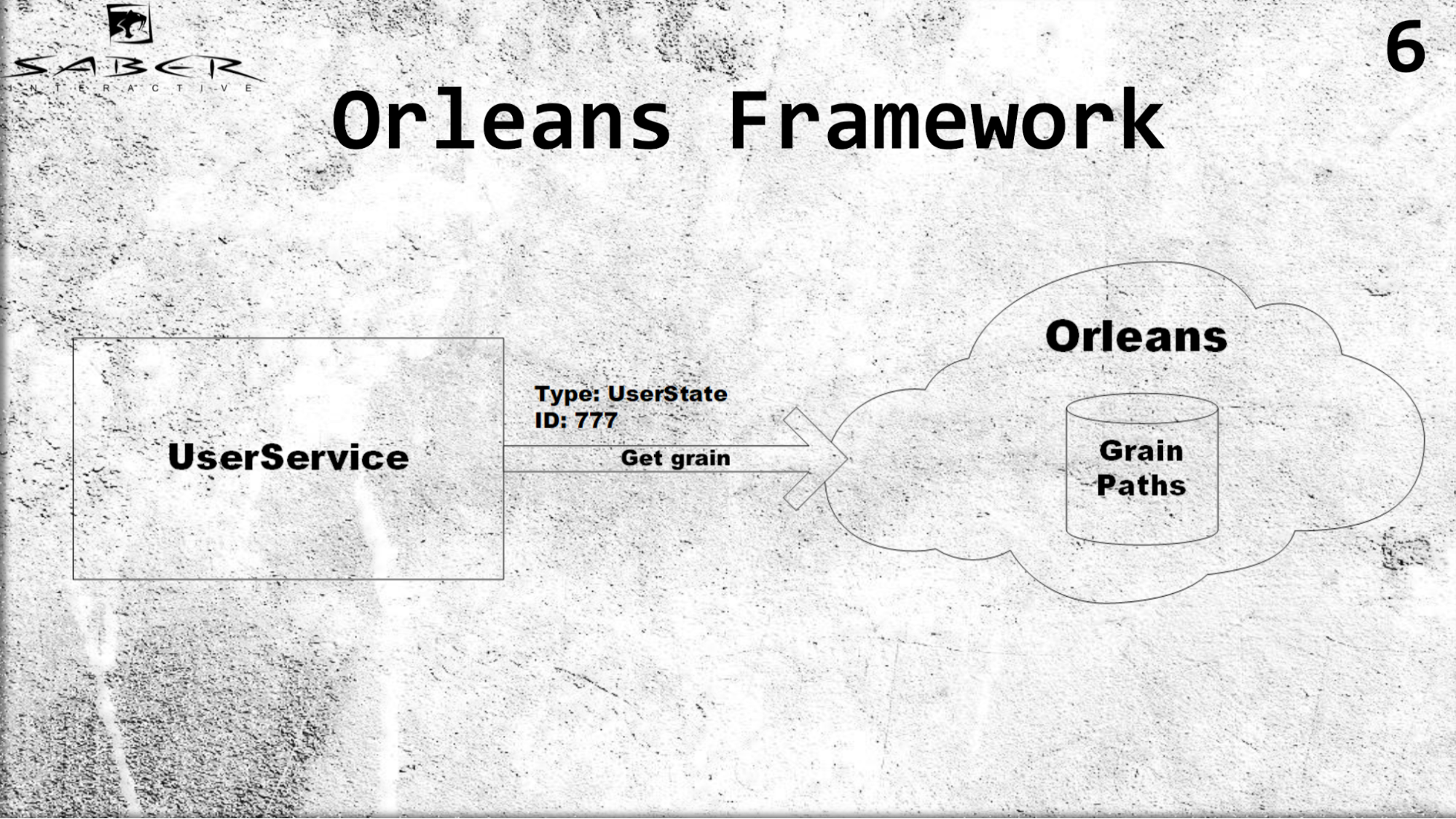
Firstly, Orleans introduces the concept of a virtual-actor or, as it is also called, grain (grain). Unlike the classical actor model, where a service is responsible for creating this actor and placing it on one of the servers, Orleans takes over the work. Those. if a certain user service requests a certain grein, Orleans will understand which server is now less loaded, will locate the actor there and return the result to the user service.
Example. For a grein, it is important to know only the type of the actor, say user states, and ID. Suppose user ID 777, we get the grains of this user and do not think about how to store this grain, we do not manage the grain's life cycle. Orleans inside of itself keeps the paths of all actors in a very tricky way. If there is no actor, it creates them, if the actor is alive, it returns it, and for user services it looks like all actors are always alive.
What advantages does this give us? First, transparent load balancing due to the fact that the programmer does not need to control the location of the actor himself. He simply says Orleans, which is deployed on several servers: give me such and such actor from your servers.
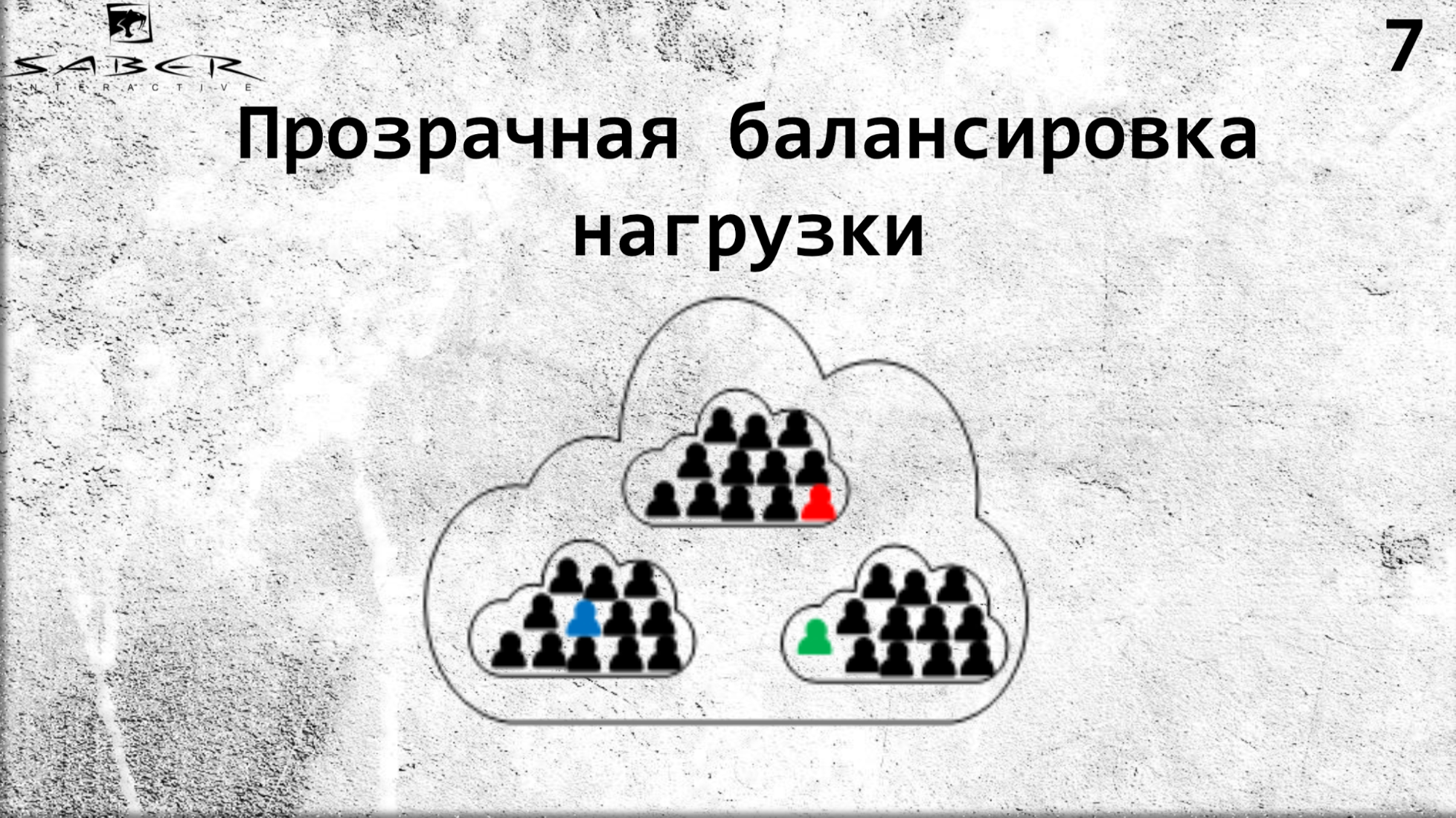
If desired, you can make downscale, if the load on the processor and memory is small. Again, you can do in the opposite direction upscale. But the service does not know anything about it, he asks for a grain, and Orleans gives him this grain. Thus, Orleans takes on the infrastructure care for the life cycle of the grains.
Secondly, Orleans handles server crashes.

This means that if in the classical model the programmer is responsible for handling such a case independently (the actor was placed on some server, and this server fell, and we ourselves have to raise this actor on one of the live servers), which adds more mechanical or hard-networked work for a programmer, then in Orleans this looks transparent. We request a grain, Orleans sees that it is unavailable, picks it up (resides on some of the live servers) and returns it to the service.
To make it a little more clear, let’s analyze a small example of how a user reads some of his own state.
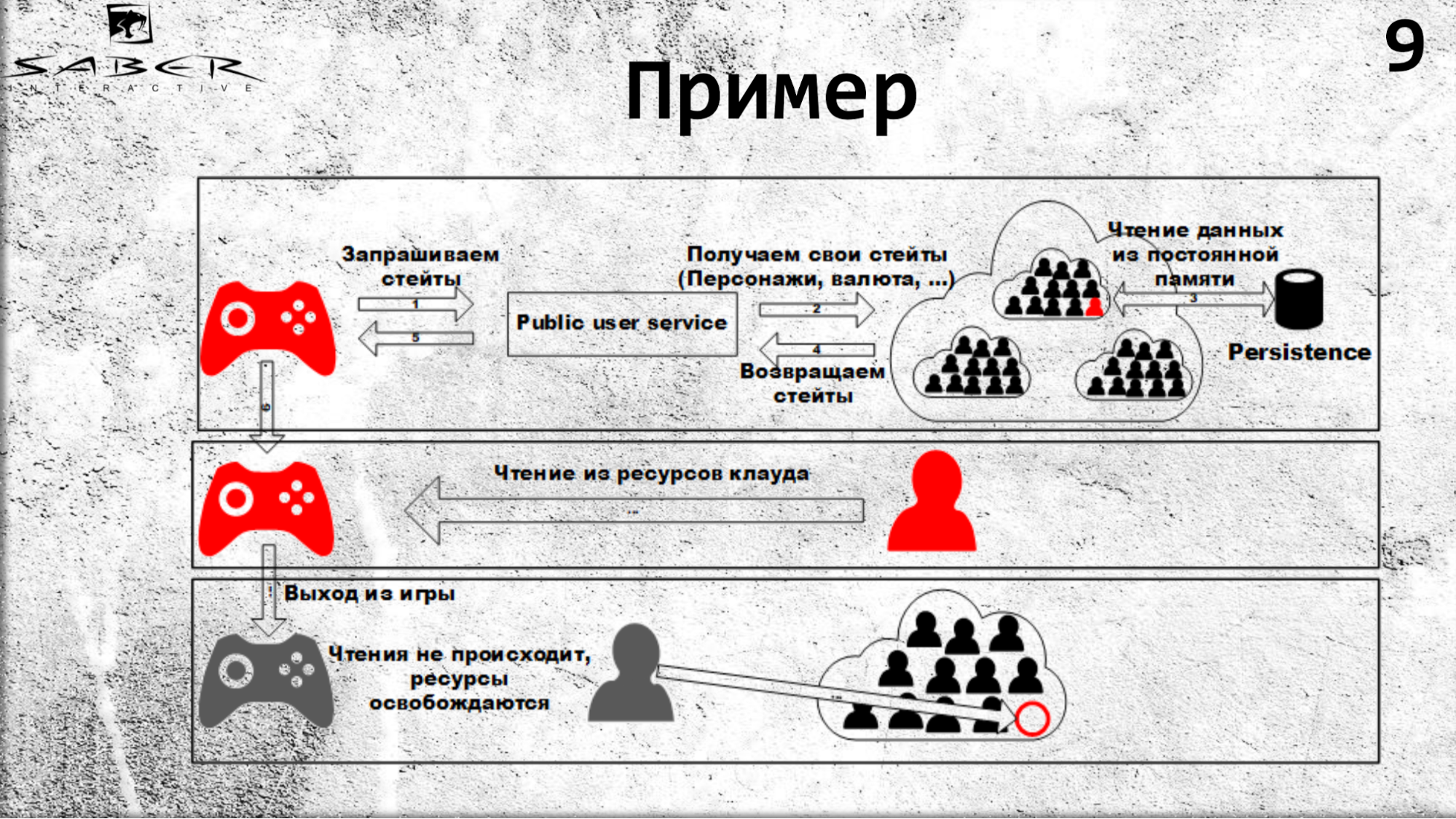
The state can be its economic condition, which stores the armor, weapon, currency or champions of this user. In order to get these states, he contacts the PublicUserService, which calls the Orleans for a state. What happens: Orleans sees that such an actor (ie, a grain) does not yet exist, it creates it on a free server, and the grain reads its state from some Persistence-storage.
Thus, the next time resources are read from the cloud, as shown in the slide, all reading will occur from the grain cache. If the user is out of the game, resources are not read, so Orleans understands that the grain is no longer used by anyone and can be deactivated.
If we have several clients (a game client, a game server), they can request the user's steate, and some of them will raise this grain. More precisely, it will force Orleans to raise it, and then all the calls, as we already know, occur in it thread-safe, sequentially. First, the state will receive the client, and then the game server.
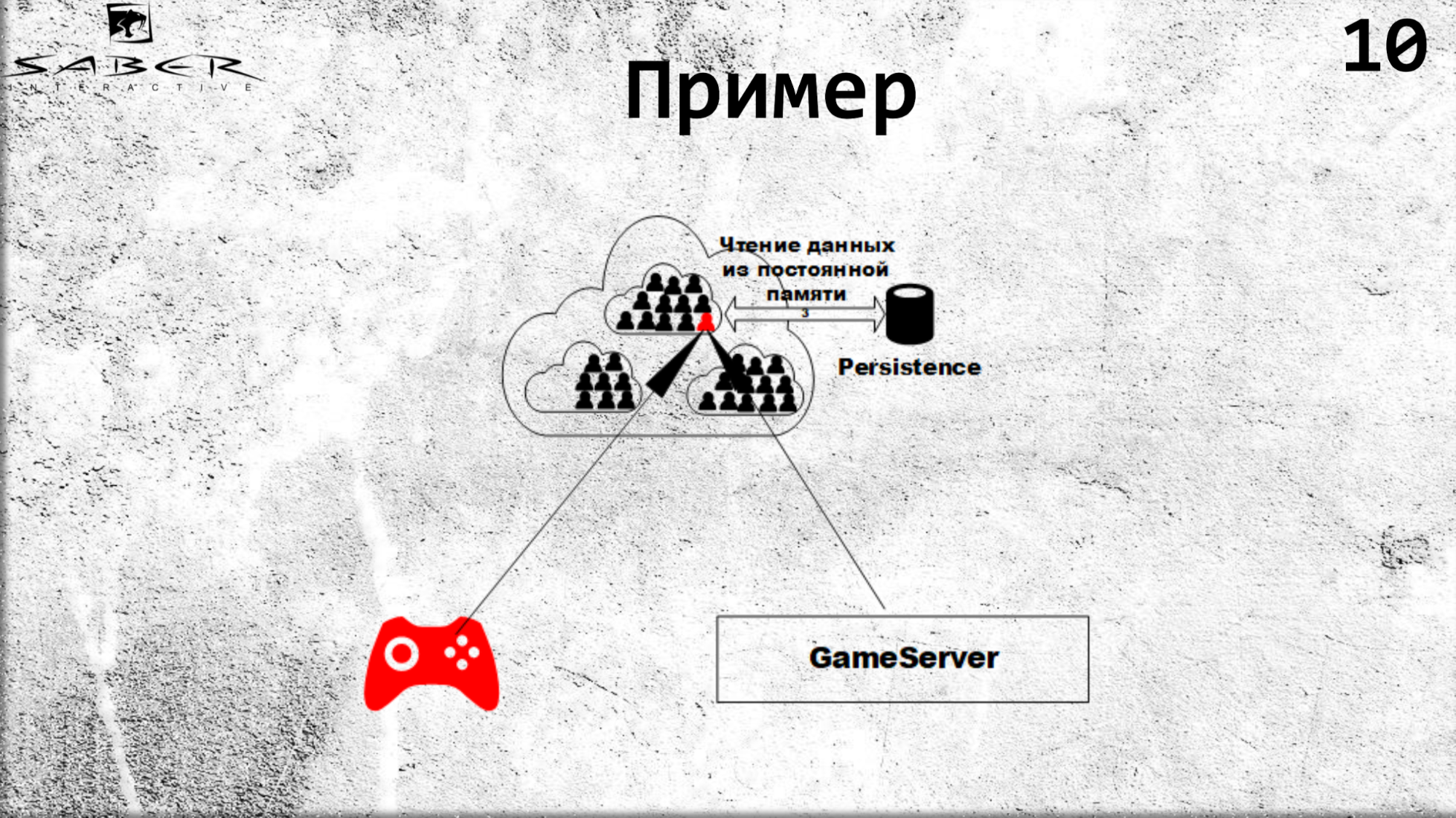
The same flow on the update. When a client wants to update some state, he will transfer this responsibility to the grain, i.e. he will say to him: “give this user 10 gold”, and the grain rises, it processes this state with some kind of business logic inside the grain. And then there is the update of the grain cache and, if desired, the persistence in Persistence.

Why is it necessary to save in Persistence? This is a separate topic and it lies in the fact that sometimes it is not particularly important for us that the grain constantly keeps its states in Persistence. If this is a player’s fortune online, we’re ready to risk losing it for the sake of performance, but if it concerns the economy, then we must be sure that his states are saved.
The simplest case: for each call to save the state, write this update in Persistence. Thus, if the grain suddenly collapses unexpectedly, the next raise of the grain to one of the other servers will cause an update of the cache with the actual data.
A small example of how it looks.

As I said before, a grain consists of a type and some key (in this case, the type is IPlayerState, the key is IGrainWithGuidKey, which means it is a Guid). And we have an interface that we implement, i.e. GetStates returns some list of steytov and ApplyState which any state applies. The Orleans methods return a Task. What this means: Task is a promise that tells us that when the state returns, the promise will be in the resolved state. We also have some kind of PlayerState that we get using the GrainFactory. Those. here we get the link, and know nothing about the physical location of this greyna. When you call GetStates, Orleans will raise our grain, read the state from the Persistence store to its memory, and when ApplyState apply the new state, and also update this state in its memory and in Persistence.
I would also like to make out a slightly more complex example on the High Level architecture of our UserStates service.
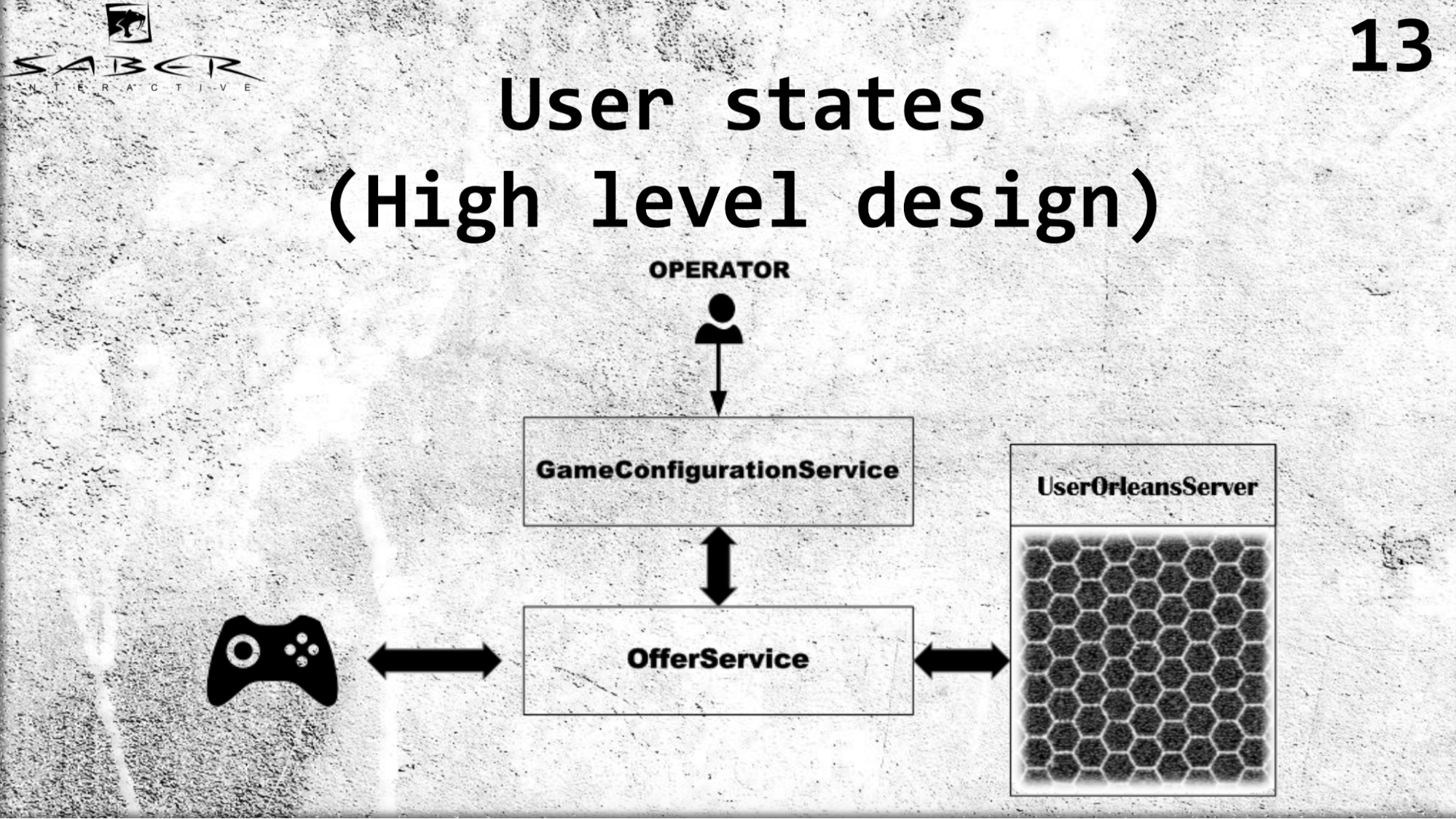
We have some kind of game client that gets its steats via OfferSevice. We have a GameConfigurationService, responsible for the economic model of a group of users, in this case our user. And we have an operator who changes this economic model. In accordance with it, the user requests OfferSevice to get his steytov. And OfferSevice is already accessing the UserOrleans service, which consists of these grains, raises this state of the user in its memory, possibly executes some business logic, and returns the data back to the user via the OfferService.
In general, I would like to draw your attention to the fact that Orleans is good for its ability of high parallelism due to the fact that greyns are independent of each other. And on the other hand, inside the grain we do not need to use synchronization primitives, because we know that every call to this grain will somehow be consistent.
Here I would like to make out some of the pitfalls of this model.

The first is too big grain. Since all the calls in the greyne are thread-safe, one after the other, and if we have some kind of greasy logic on the greyne, we will have to wait too long. Again, too much memory is allocated to one such grain. There is no exact algorithm for what the size of the grain should be, because too small a grain is also bad. Here it is rather necessary to proceed from the optimal value. I will not say exactly what it is that the programmer himself decides.
The second problem is not so obvious - this is the so-called chain reaction. When a user picks up some kind of grain, the latter in turn may implicitly raise other greyna in the system. How it happens: the user gets his fortunes, and the user has friends and he gets the fortunes of his friends. Thus, the whole system keeps all its grains in memory, and if we have 1000 users and each have 100 friends, then 100,000 grains can be active just like that. Such a case should also be avoided - somehow, you should keep the steates of friends in some kind of shared memory.

Well, what technologies exist for the implementation of the model of actors. Perhaps the most famous is Akka, which came to us from Java. There is a fork called Akka.NET for .NET. There are Orleans, which is open-source and there are in other languages, like implementation. There are Azure-primitives, such as Service Fabric Actor - a lot of technologies.
- How do you solve classic problems, like CICD, updating these actors, do Docker use and do you need it at all?
- We do not use docker yet. In general, DevOps is engaged in development, they deploy our services in the Azure cloud service.
- Continuous update, no downtime, how is it going? Orleans decides for itself which server the grain will go to, which server the query will go to and how to update this service. Those. a new business logic has appeared, an update of the same actor has appeared - how are these updates rolling?
- If it is about updating the entire service, and if we have updated some of the actor’s business logic, we can roll out the new Orleans service for it. Usually we have this solved through our primitives called topology. We rolled out some new Orleans service, which, for the time being, let's say, is empty, and without an actor, we derive the old service and replace it with a new one. There will be no actors in the system at all, but the next time the user is prompted, these actors will already be created. There might be some spike in the beginning. In such cases, the update usually takes place in the morning, since in the morning we have the smallest number of players.
- How does Orleans understand that the server fell? You told me that he quickly throws actors onto another server ...
- He has a pingator who periodically understands which of the servaks are live.
- Does he ping an actor or a server specifically?
- Specifically server.
- Such a question: an error occurred inside the actor, you say it goes step by step, each instruction. But there was an error and what happens to the actor? Suppose such an error that is not processed. Is the actor just dying?
- No, Orleans throws exception in the standard .NET schema.
- Look, we did not handle the exception, the actor apparently died. I don’t know what the player will look like, but what happens next? Are you trying to somehow restart this actor or do something else in this spirit?
- It depends on what case, it depends on what behavior. For example retriable or not retriable.
- Ie Is it all configurable?
- Rather, it is programmed. Any exceptions we handle. Those. we clearly see that such an error code, and some, like unhandled exceptions, are already progressed further.
- You have a few Persistence'ov is a database type?
- Persistence, yes, a database with permanent storage.
- Suppose, went to the database, in which (conditionally) game money. What happens if the actor cannot reach it? How do you handle it?
- First, it is Storage. At the moment, we use Azure Table Storage and such problems actually happen - Storage drops. Usually in this case it is necessary to reconfigure it.
- If the actor could not get something in Storage, what does the player look like? Does he simply not have this money or does he have the game immediately closed?
- These are critical changes for the user. Since each service has its own severity, in this case, the user service is a terminal state, and the client simply crashes.
- It seemed to me that the messages of the actors occur through asynchronous queues. How optimized is this solution? Does it not swell, does it not cause the player to hang up? Wouldn't it be better to use a reactive approach?
- The problem of queues in the actors is quite well-known, because we so clearly cannot control the size of the queue, you are right. But Orleans, firstly, undertakes some work on management and, secondly, I think that just by timeout access to the actor will fall, i.e. we can not reach the actor, for example.
- How does it affect the player?
- Since the user service calls the actor, an exception timeout exception will be thrown to him and, if this is a “critical” service, the client will throw out the error and close. And if it is less critical, then it will wait.
- Ie Do you have the threat of DDoS? A large number of minor action can put a player? Suppose someone quickly starts inviting friends, etc.
- No, there is a request limiter, which will not allow too often to access services.
- How do you handle data consistency? Suppose we have two users, we must take something from one person and charge something to another, and for this to be transactional.
- Good question. First, Orleans 2.0 supports Distributed Actor Transaction - this is the first way out. More precisely, you need to talk about the economy. And as the easiest way - in the last Orleans transactions between actors are implemented without any problems.
- Ie Is it already able to guarantee that the data will go holistically into persistence?
- Yes.
Our team is working on a backend for Quake Champions, and I’ll talk about what an actor model is and how it is used in the project.
A little about the stack of technology. We write code in C #, respectively, all technologies are tied to it. I want to note that there will be some specific things that I will show with the example of this language, but the general principles will remain unchanged.
At the moment we are hosting our services in Azure. There are some very interesting primitives that we don’t want to give up, such as Table Storage and Cosmos DB (but we try hard not to tie them up for the sake of the cross-platform project).
Now I would like to talk a little bit about what an actor model is. And let me begin by saying that it, as a principle, appeared more than 40 years ago.
Actor is a parallel computing model that states that there is some isolated object that has its own internal state and exclusive access to change this state. The actor can read messages, and consistently, perform some kind of business logic, change the internal state if desired, and send messages to external services, including other actors. And he can create other actors.
Actors communicate among themselves with asynchronous messages, which allows you to create highly loaded distributed cloud systems. In this regard, the actor model and received widespread recently.
Summarizing what has been said, let's imagine that we have cloud, where there is a cluster of servers, and our actors are spinning on this cluster.
Actors are isolated from each other, communicate through asynchronous calls, and within themselves the actors are thread-safe.
How it might look like. Suppose we have several users (not a very large load), and at some point we understand that there is an influx of players, and we need to urgently make upscale.
We can add servers to our cloud and, using the actor model, stuff individual users — assign each actor to each individual and allocate space for memory and processor time for that actor in the cloud.
Thus, the actor, firstly, plays the role of a cache, and secondly, it is a la “smart cache”, which is able to process some messages, to execute business logic. Again, if you need to do a downscale (for example, the players are out) - there is also no problem to remove these actors from the system.
We in backend'e use not the classical actor model, but on the basis of the Orleans framework. What is the difference - I will try to tell you now.
Firstly, Orleans introduces the concept of a virtual-actor or, as it is also called, grain (grain). Unlike the classical actor model, where a service is responsible for creating this actor and placing it on one of the servers, Orleans takes over the work. Those. if a certain user service requests a certain grein, Orleans will understand which server is now less loaded, will locate the actor there and return the result to the user service.
Example. For a grein, it is important to know only the type of the actor, say user states, and ID. Suppose user ID 777, we get the grains of this user and do not think about how to store this grain, we do not manage the grain's life cycle. Orleans inside of itself keeps the paths of all actors in a very tricky way. If there is no actor, it creates them, if the actor is alive, it returns it, and for user services it looks like all actors are always alive.
What advantages does this give us? First, transparent load balancing due to the fact that the programmer does not need to control the location of the actor himself. He simply says Orleans, which is deployed on several servers: give me such and such actor from your servers.
If desired, you can make downscale, if the load on the processor and memory is small. Again, you can do in the opposite direction upscale. But the service does not know anything about it, he asks for a grain, and Orleans gives him this grain. Thus, Orleans takes on the infrastructure care for the life cycle of the grains.
Secondly, Orleans handles server crashes.
This means that if in the classical model the programmer is responsible for handling such a case independently (the actor was placed on some server, and this server fell, and we ourselves have to raise this actor on one of the live servers), which adds more mechanical or hard-networked work for a programmer, then in Orleans this looks transparent. We request a grain, Orleans sees that it is unavailable, picks it up (resides on some of the live servers) and returns it to the service.
To make it a little more clear, let’s analyze a small example of how a user reads some of his own state.
The state can be its economic condition, which stores the armor, weapon, currency or champions of this user. In order to get these states, he contacts the PublicUserService, which calls the Orleans for a state. What happens: Orleans sees that such an actor (ie, a grain) does not yet exist, it creates it on a free server, and the grain reads its state from some Persistence-storage.
Thus, the next time resources are read from the cloud, as shown in the slide, all reading will occur from the grain cache. If the user is out of the game, resources are not read, so Orleans understands that the grain is no longer used by anyone and can be deactivated.
If we have several clients (a game client, a game server), they can request the user's steate, and some of them will raise this grain. More precisely, it will force Orleans to raise it, and then all the calls, as we already know, occur in it thread-safe, sequentially. First, the state will receive the client, and then the game server.
The same flow on the update. When a client wants to update some state, he will transfer this responsibility to the grain, i.e. he will say to him: “give this user 10 gold”, and the grain rises, it processes this state with some kind of business logic inside the grain. And then there is the update of the grain cache and, if desired, the persistence in Persistence.
Why is it necessary to save in Persistence? This is a separate topic and it lies in the fact that sometimes it is not particularly important for us that the grain constantly keeps its states in Persistence. If this is a player’s fortune online, we’re ready to risk losing it for the sake of performance, but if it concerns the economy, then we must be sure that his states are saved.
The simplest case: for each call to save the state, write this update in Persistence. Thus, if the grain suddenly collapses unexpectedly, the next raise of the grain to one of the other servers will cause an update of the cache with the actual data.
A small example of how it looks.
As I said before, a grain consists of a type and some key (in this case, the type is IPlayerState, the key is IGrainWithGuidKey, which means it is a Guid). And we have an interface that we implement, i.e. GetStates returns some list of steytov and ApplyState which any state applies. The Orleans methods return a Task. What this means: Task is a promise that tells us that when the state returns, the promise will be in the resolved state. We also have some kind of PlayerState that we get using the GrainFactory. Those. here we get the link, and know nothing about the physical location of this greyna. When you call GetStates, Orleans will raise our grain, read the state from the Persistence store to its memory, and when ApplyState apply the new state, and also update this state in its memory and in Persistence.
I would also like to make out a slightly more complex example on the High Level architecture of our UserStates service.
We have some kind of game client that gets its steats via OfferSevice. We have a GameConfigurationService, responsible for the economic model of a group of users, in this case our user. And we have an operator who changes this economic model. In accordance with it, the user requests OfferSevice to get his steytov. And OfferSevice is already accessing the UserOrleans service, which consists of these grains, raises this state of the user in its memory, possibly executes some business logic, and returns the data back to the user via the OfferService.
In general, I would like to draw your attention to the fact that Orleans is good for its ability of high parallelism due to the fact that greyns are independent of each other. And on the other hand, inside the grain we do not need to use synchronization primitives, because we know that every call to this grain will somehow be consistent.
Here I would like to make out some of the pitfalls of this model.
The first is too big grain. Since all the calls in the greyne are thread-safe, one after the other, and if we have some kind of greasy logic on the greyne, we will have to wait too long. Again, too much memory is allocated to one such grain. There is no exact algorithm for what the size of the grain should be, because too small a grain is also bad. Here it is rather necessary to proceed from the optimal value. I will not say exactly what it is that the programmer himself decides.
The second problem is not so obvious - this is the so-called chain reaction. When a user picks up some kind of grain, the latter in turn may implicitly raise other greyna in the system. How it happens: the user gets his fortunes, and the user has friends and he gets the fortunes of his friends. Thus, the whole system keeps all its grains in memory, and if we have 1000 users and each have 100 friends, then 100,000 grains can be active just like that. Such a case should also be avoided - somehow, you should keep the steates of friends in some kind of shared memory.
Well, what technologies exist for the implementation of the model of actors. Perhaps the most famous is Akka, which came to us from Java. There is a fork called Akka.NET for .NET. There are Orleans, which is open-source and there are in other languages, like implementation. There are Azure-primitives, such as Service Fabric Actor - a lot of technologies.
Questions from the audience
- How do you solve classic problems, like CICD, updating these actors, do Docker use and do you need it at all?
- We do not use docker yet. In general, DevOps is engaged in development, they deploy our services in the Azure cloud service.
- Continuous update, no downtime, how is it going? Orleans decides for itself which server the grain will go to, which server the query will go to and how to update this service. Those. a new business logic has appeared, an update of the same actor has appeared - how are these updates rolling?
- If it is about updating the entire service, and if we have updated some of the actor’s business logic, we can roll out the new Orleans service for it. Usually we have this solved through our primitives called topology. We rolled out some new Orleans service, which, for the time being, let's say, is empty, and without an actor, we derive the old service and replace it with a new one. There will be no actors in the system at all, but the next time the user is prompted, these actors will already be created. There might be some spike in the beginning. In such cases, the update usually takes place in the morning, since in the morning we have the smallest number of players.
- How does Orleans understand that the server fell? You told me that he quickly throws actors onto another server ...
- He has a pingator who periodically understands which of the servaks are live.
- Does he ping an actor or a server specifically?
- Specifically server.
- Such a question: an error occurred inside the actor, you say it goes step by step, each instruction. But there was an error and what happens to the actor? Suppose such an error that is not processed. Is the actor just dying?
- No, Orleans throws exception in the standard .NET schema.
- Look, we did not handle the exception, the actor apparently died. I don’t know what the player will look like, but what happens next? Are you trying to somehow restart this actor or do something else in this spirit?
- It depends on what case, it depends on what behavior. For example retriable or not retriable.
- Ie Is it all configurable?
- Rather, it is programmed. Any exceptions we handle. Those. we clearly see that such an error code, and some, like unhandled exceptions, are already progressed further.
- You have a few Persistence'ov is a database type?
- Persistence, yes, a database with permanent storage.
- Suppose, went to the database, in which (conditionally) game money. What happens if the actor cannot reach it? How do you handle it?
- First, it is Storage. At the moment, we use Azure Table Storage and such problems actually happen - Storage drops. Usually in this case it is necessary to reconfigure it.
- If the actor could not get something in Storage, what does the player look like? Does he simply not have this money or does he have the game immediately closed?
- These are critical changes for the user. Since each service has its own severity, in this case, the user service is a terminal state, and the client simply crashes.
- It seemed to me that the messages of the actors occur through asynchronous queues. How optimized is this solution? Does it not swell, does it not cause the player to hang up? Wouldn't it be better to use a reactive approach?
- The problem of queues in the actors is quite well-known, because we so clearly cannot control the size of the queue, you are right. But Orleans, firstly, undertakes some work on management and, secondly, I think that just by timeout access to the actor will fall, i.e. we can not reach the actor, for example.
- How does it affect the player?
- Since the user service calls the actor, an exception timeout exception will be thrown to him and, if this is a “critical” service, the client will throw out the error and close. And if it is less critical, then it will wait.
- Ie Do you have the threat of DDoS? A large number of minor action can put a player? Suppose someone quickly starts inviting friends, etc.
- No, there is a request limiter, which will not allow too often to access services.
- How do you handle data consistency? Suppose we have two users, we must take something from one person and charge something to another, and for this to be transactional.
- Good question. First, Orleans 2.0 supports Distributed Actor Transaction - this is the first way out. More precisely, you need to talk about the economy. And as the easiest way - in the last Orleans transactions between actors are implemented without any problems.
- Ie Is it already able to guarantee that the data will go holistically into persistence?
- Yes.
More reports from Pixonic DevGAMM Talks
- Using Consul to scale stateful services (Ivan Bubnov, DevOps at BIT.GAMES);
- CICD: Seamless Deploy on Distributed Cluster Systems without Downtime (Egor Panov, Pixonic System Administrator);
- The architecture of the meta-server mobile online shooter Tacticool (Pavel Platto, Lead Software Engineer in PanzerDog);
- How ECS, C # Job System and SRP change the approach to architecture (Valentin Simonov, Field Engineer in Unity);
- KISS principle in development (Konstantin Gladyshev, Lead Game Programmer at 1C Game Studios);
- General game logic on the client and server (Anton Grigoriev, Deputy Technical Officer in Pixonic).
- Cucumber in the cloud: using BDD scripts for load testing a product (Anton Kosyakin, Technical Product Manager in ALICE Platform).