Extra Large Postgres
It just so happened that recently I had to deal with optimization and scaling of various systems. One of the tasks was scaling PostgreSQL. How is database optimization usually done? Probably the first thing they look at is how to choose the optimal settings for the job and which indexes you can create. If it doesn’t work out a little blood, they go on to increase server capacities, transfer log files to a separate disk, load balance, partition tables into partitions, and refactoring and redesigning the model of all kinds. And now everything is perfectly tuned, but there comes a time when all these movements are not enough. What to do next? Horizontal scaling and data sharding.

I want to share the experience of deploying a horizontally scalable cluster on the Postgres-XL DBMS.
Postgres-XL is a great tool that allows you to combine several PostgreSQL clusters in such a way that they work as a single DB instance. There is no difference for the client connecting to the database; it works with a single PostgreSQL instance or with a Postgres-XL cluster. Postgres-XL offers 2 modes for distributing tables across a cluster: replication and sharding. During replication, all nodes contain the same copy of the table, and during sharding, data is evenly distributed among cluster members. The current implementation is based on PostgreSQL-9.2. So almost all features of version 9.2 will be available to you.
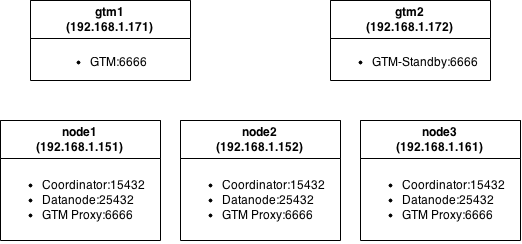
Postgres-XL consists of three types of components: global transaction monitor ( GTM ), coordinator (coordinator) and data node (datanode).
GTM - responsible for ensuring ACID requirements. Responsible for issuing identifiers. Since it is a single point of failure, it is recommended to back up using GTM Standby. Providing a separate server for GTM is a good idea. To combine multiple requests and responses from coordinators and data nodes running on the same server, it makes sense to configure GTM-Proxy. Thus, the load on GTM is reduced as the total number of interactions with it is reduced.
Coordinator- the central part of the cluster. It is with him that the client application interacts. Manages user sessions and interacts with GTM and data nodes. Parses requests, builds a query execution plan and sends it to each of the components participating in the request, collects the results and sends them back to the client. The coordinator does not store any user data. It stores only service data to determine how to handle requests where data nodes are located. If one of the coordinators fails, you can simply switch to another.
A data node is a place where user data and indexes are stored. Communication with data nodes is carried out only through coordinators. To ensure high availability, you can back up each of the stanby nodes with a server.

You can use pgpool-II as a load balancer . His setting for many commented on the Habré, for example, here and there is good practice to install the coordinator and host of data on a single machine, as we do not need to worry about balancing the load between them and the data from replicated tables are available on the site without having to send an additional request over the network.
Each node is a virtual machine with modest hardware: MemTotal: 501284 kB, cpu MHz: 2604.
Everything is standard here: download source from offsite , deliver dependencies, compile. Collected on Ubuntu server 14.10.
After the package is assembled, fill it with the nodes of the cluster and proceed to the configuration of the components.
To ensure fault tolerance, consider the example of setting up two GTM servers. On both servers, create a working directory for GTM and initialize it.
After that, go to config settings:
gtm1
gtm2
Save, start:
In the logs, we observe the entries:
LOG: Started to run as GTM-Active.
LOG: Started to run as GTM-Standby.
After editing the config, you can run:
For other nodes, the setting differs only by specifying a different name.
Now edit pg_hba.conf:
Everything is ready and you can run.
We go to the coordinator:
We fulfill the request:
The request shows how the current server sees our cluster.
Output Example:
These settings are incorrect and can be safely deleted.
Create a new mapping of our cluster:
On the remaining nodes, you need to do the same.
The data node will not allow you to completely clear the information, but you can overwrite it:
Now everything is configured and working. Let's create some test tables.
4 tables were created with the same structure, but different distribution logic across the cluster.
The data of the test1 table will be stored only on 2 data nodes - datanode1 and datanode2 , and they will be distributed according to the roundrobin algorithm. The remaining tables involve all nodes. The test2 table is in replication mode. To determine which server the data of the test3 table will be stored on , a hash function is used for the id field , and to determine the distribution logic of test4, a module is taken for the status field . Let's try filling them out now:
Now we request this data and see how the scheduler works
The scheduler tells us how many nodes will participate in the request. Since table2 is replicated to all nodes, only 1 node will be scanned. By the way, it is unclear by what logic he is chosen. It would be logical for him to request data from the same node on which the coordinator is.
By connecting to the data node (on port 25432), you can see how the data was distributed.
Now let's try to fill the tables with a large amount of data and compare query performance with standalone PostgreSQL.
Request in a Postgres-XL cluster:
The same query on the server with PostgreSQL:
We observe a twofold increase in speed. Not so bad, if you have enough cars at your disposal, then such scaling looks quite promising.
As noted in the comments, it would be interesting to look at join tables distributed over several nodes. Let's try:
Request on the same data volumes, but on standalone server:
Here the gain is only 1.5 times.
PS I hope this post helps someone. Comments and additions are welcome! Thank you for attention.
I want to share the experience of deploying a horizontally scalable cluster on the Postgres-XL DBMS.
Postgres-XL is a great tool that allows you to combine several PostgreSQL clusters in such a way that they work as a single DB instance. There is no difference for the client connecting to the database; it works with a single PostgreSQL instance or with a Postgres-XL cluster. Postgres-XL offers 2 modes for distributing tables across a cluster: replication and sharding. During replication, all nodes contain the same copy of the table, and during sharding, data is evenly distributed among cluster members. The current implementation is based on PostgreSQL-9.2. So almost all features of version 9.2 will be available to you.
Terminology
Postgres-XL consists of three types of components: global transaction monitor ( GTM ), coordinator (coordinator) and data node (datanode).
GTM - responsible for ensuring ACID requirements. Responsible for issuing identifiers. Since it is a single point of failure, it is recommended to back up using GTM Standby. Providing a separate server for GTM is a good idea. To combine multiple requests and responses from coordinators and data nodes running on the same server, it makes sense to configure GTM-Proxy. Thus, the load on GTM is reduced as the total number of interactions with it is reduced.
Coordinator- the central part of the cluster. It is with him that the client application interacts. Manages user sessions and interacts with GTM and data nodes. Parses requests, builds a query execution plan and sends it to each of the components participating in the request, collects the results and sends them back to the client. The coordinator does not store any user data. It stores only service data to determine how to handle requests where data nodes are located. If one of the coordinators fails, you can simply switch to another.
A data node is a place where user data and indexes are stored. Communication with data nodes is carried out only through coordinators. To ensure high availability, you can back up each of the stanby nodes with a server.
You can use pgpool-II as a load balancer . His setting for many commented on the Habré, for example, here and there is good practice to install the coordinator and host of data on a single machine, as we do not need to worry about balancing the load between them and the data from replicated tables are available on the site without having to send an additional request over the network.
Test Cluster Diagram
Each node is a virtual machine with modest hardware: MemTotal: 501284 kB, cpu MHz: 2604.
Installation
Everything is standard here: download source from offsite , deliver dependencies, compile. Collected on Ubuntu server 14.10.
$ sudo apt-get install flex bison docbook-dsssl jade iso8879 docbook libreadline-dev zlib1g-dev
$ ./configure --prefix=/home/${USER}/Develop/utils/postgres-xl --disable-rpath
$ make world
After the package is assembled, fill it with the nodes of the cluster and proceed to the configuration of the components.
GTM setup
To ensure fault tolerance, consider the example of setting up two GTM servers. On both servers, create a working directory for GTM and initialize it.
$ mkdir ~/gtm
$ initgtm -Z gtm -D ~/gtm/
After that, go to config settings:
gtm1
gtm.conf
...
nodename = 'gtm_master'
listen_addresses = '*'
port = 6666
startup = ACT
log_file = 'gtm.log'
...
nodename = 'gtm_master'
listen_addresses = '*'
port = 6666
startup = ACT
log_file = 'gtm.log'
...
gtm2
gtm.conf
...
nodename = 'gtm_slave'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'gtm1'
active_port = 6666
log_file = 'gtm.log'
...
nodename = 'gtm_slave'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'gtm1'
active_port = 6666
log_file = 'gtm.log'
...
Save, start:
$ gtm_ctl start -Z gtm -D ~/gtm/
In the logs, we observe the entries:
LOG: Started to run as GTM-Active.
LOG: Started to run as GTM-Standby.
Configuring GTM-Proxy
$ mkdir gtm_proxy
$ initgtm -Z gtm_proxy -D ~/gtm_proxy/
$ nano gtm_proxy/gtm_proxy.conf
gtm_proxy.conf
...
nodename = 'gtmproxy1' # the name must be unique
listen_addresses = '*'
port = 6666
gtm_host = 'gtm1' # specify the ip or host name on which the GTM master
gtm_port = 6666
log_file = 'gtm_proxy.log' is deployed
...
nodename = 'gtmproxy1' # the name must be unique
listen_addresses = '*'
port = 6666
gtm_host = 'gtm1' # specify the ip or host name on which the GTM master
gtm_port = 6666
log_file = 'gtm_proxy.log' is deployed
...
After editing the config, you can run:
$ gtm_ctl start -Z gtm_proxy -D ~/gtm_proxy/
Configuring Coordinators
$ mkdir coordinator
$ initdb -D ~/coordinator/ -E UTF8 --locale=C -U postgres -W --nodename coordinator1
$ nano ~/coordinator/postgresql.conf
coordinator / postgresql.conf
...
listen_addresses = '*'
port = 15432
pooler_port = 16667
gtm_host = '127.0.0.1'
pgxc_node_name = 'coordinator1'
...
listen_addresses = '*'
port = 15432
pooler_port = 16667
gtm_host = '127.0.0.1'
pgxc_node_name = 'coordinator1'
...
Data Node Setup
$ mkdir ~/datanode
$ initdb -D ~/datanode/ -E UTF8 --locale=C -U postgres -W --nodename datanode1
$ nano ~/datanode/postgresql.conf
datanode / postgresql.conf
...
listen_addresses = '*'
port = 25432
pooler_port = 26667
gtm_host = '127.0.0.1'
pgxc_node_name = 'datanode1'
...
listen_addresses = '*'
port = 25432
pooler_port = 26667
gtm_host = '127.0.0.1'
pgxc_node_name = 'datanode1'
...
For other nodes, the setting differs only by specifying a different name.
Now edit pg_hba.conf:
echo "host all all 192.168.1.0/24 trust" >> ~/datanode/pg_hba.conf
echo "host all all 192.168.1.0/24 trust" >> ~/coordinator/pg_hba.conf
Launch and Tuning
Everything is ready and you can run.
$ pg_ctl start -Z datanode -D ~/datanode/ -l ~/datanode/datanode.log
$ pg_ctl start -Z coordinator -D ~/coordinator/ -l ~/coordinator/coordinator.log
We go to the coordinator:
psql -p15432
We fulfill the request:
select * from pgxc_node;
The request shows how the current server sees our cluster.
Output Example:
node_name | node_type | node_port | node_host | nodeis_primary | nodeis_preferred | node_id
-------------+-----------+-----------+-----------+----------------+------------------+------------
coordinator1 | C | 5432 | localhost | f | f | 1938253334
These settings are incorrect and can be safely deleted.
delete from pgxc_node;
Create a new mapping of our cluster:
create node coordinator1 with (type=coordinator, host='192.168.1.151', port=15432);
create node coordinator2 with (type=coordinator, host='192.168.1.152', port=15432);
create node coordinator3 with (type=coordinator, host='192.168.1.161', port=15432);
create node datanode1 with (type=datanode, host='192.168.1.151', primary=true, port=25432);
create node datanode2 with (type=datanode, host='192.168.1.152', primary=false, port=25432);
create node datanode3 with (type=datanode, host='192.168.1.161', primary=false, port=25432);
SELECT pgxc_pool_reload();
select * from pgxc_node;
node_name | node_type | node_port | node_host | nodeis_primary | nodeis_preferred | node_id
--------------+-----------+-----------+---------------+----------------+------------------+-------------
datanode1 | D | 25432 | 192.168.1.151 | t | f | 888802358
coordinator1 | C | 15432 | 192.168.1.151 | f | f | 1938253334
coordinator2 | C | 15432 | 192.168.1.152 | f | f | -2089598990
coordinator3 | C | 15432 | 192.168.1.161 | f | f | -1483147149
datanode2 | D | 25432 | 192.168.1.152 | f | f | -905831925
datanode3 | D | 25432 | 192.168.1.161 | f | f | -1894792127
On the remaining nodes, you need to do the same.
The data node will not allow you to completely clear the information, but you can overwrite it:
psql -p 25432 -c "alter node datanode1 WITH ( TYPE=datanode, HOST ='192.168.1.151', PORT=25432, PRIMARY=true);"
Cluster testing
Now everything is configured and working. Let's create some test tables.
CREATE TABLE test1
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test1_id_pkey PRIMARY KEY (id)
) to node (datanode1, datanode2);
CREATE TABLE test2
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test2_id_pkey PRIMARY KEY (id)
) distribute by REPLICATION;
CREATE TABLE test3
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test3_id_pkey PRIMARY KEY (id)
) distribute by HASH(id);
CREATE TABLE test4
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL
) distribute by MODULO(status);
4 tables were created with the same structure, but different distribution logic across the cluster.
The data of the test1 table will be stored only on 2 data nodes - datanode1 and datanode2 , and they will be distributed according to the roundrobin algorithm. The remaining tables involve all nodes. The test2 table is in replication mode. To determine which server the data of the test3 table will be stored on , a hash function is used for the id field , and to determine the distribution logic of test4, a module is taken for the status field . Let's try filling them out now:
insert into test1 (id, profile, status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test2 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test3 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test4 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
Now we request this data and see how the scheduler works
explain analyze select count(*) from test1;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=27.50..27.51 rows=1 width=0) (actual time=0.649..0.649 rows=1 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2) (cost=0.00..24.00 rows=1400 width=0) (actual time=0.248..0.635 rows=2 loops=1)
Total runtime: 3.177 ms
explain analyze select count(*) from test2;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (datanode2) (cost=27.50..27.51 rows=1 width=0) (actual time=0.711..0.711 rows=1 loops=1)
Total runtime: 2.833 ms
explain analyze select count(*) from test3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=27.50..27.51 rows=1 width=0) (actual time=1.453..1.453 rows=1 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=0.00..24.00 rows=1400 width=0) (actual time=0.465..1.430 rows=3 loops=1)
Total runtime: 3.014 ms
The scheduler tells us how many nodes will participate in the request. Since table2 is replicated to all nodes, only 1 node will be scanned. By the way, it is unclear by what logic he is chosen. It would be logical for him to request data from the same node on which the coordinator is.
By connecting to the data node (on port 25432), you can see how the data was distributed.
Now let's try to fill the tables with a large amount of data and compare query performance with standalone PostgreSQL.
insert into test3 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,1000000) a;
Request in a Postgres-XL cluster:
explain analyze select profile, count(status) from test3
where status<>2
and switch_date between '1970-01-01' and '2015-01-01' group by profile;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=34.53..34.54 rows=1 width=12) (actual time=266.319..268.246 rows=10001 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=0.00..34.50 rows=7 width=12) (actual time=172.894..217.644 rows=30003 loops=1)
Total runtime: 276.690 ms
The same query on the server with PostgreSQL:
explain analyze select profile, count(status) from test
where status<>2
and switch_date between '1970-01-01' and '2015-01-01' group by profile;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=28556.44..28630.53 rows=7409 width=12) (actual time=598.448..600.495 rows=10001 loops=1)
-> Seq Scan on test (cost=0.00..24853.00 rows=740688 width=12) (actual time=0.418..329.145 rows=740579 loops=1)
Filter: ((status <> 2) AND (switch_date >= '1970-01-01 00:00:00'::timestamp without time zone) AND (switch_date <= '2015-01-01 00:00:00'::timestamp without time zone))
Rows Removed by Filter: 259421
Total runtime: 601.572 ms
We observe a twofold increase in speed. Not so bad, if you have enough cars at your disposal, then such scaling looks quite promising.
As noted in the comments, it would be interesting to look at join tables distributed over several nodes. Let's try:
create table test3_1 (id bigint NOT NULL, name text, CONSTRAINT test3_1_id_pkey PRIMARY KEY (id)) distribute by HASH(id);
insert into test3_1 (id , name) select a, md5(random()::text) from generate_series(1,10000) a;
explain analyze select test3.*,test3_1.name from test3 join test3_1 on test3.profile=test3_1.id;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=35.88..79.12 rows=1400 width=61) (actual time=26.500..17491.685 rows=999948 loops=1)
Total runtime: 17830.984 ms
Request on the same data volumes, but on standalone server:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=319.00..42670.00 rows=999800 width=69) (actual time=99.697..19806.038 rows=999940 loops=1)
Hash Cond: (test.profile = test_1.id)
-> Seq Scan on test (cost=0.00..17353.00 rows=1000000 width=28) (actual time=0.031..6417.221 rows=1000000 loops=1)
-> Hash (cost=194.00..194.00 rows=10000 width=41) (actual time=99.631..99.631 rows=10000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 713kB
-> Seq Scan on test_1 (cost=0.00..194.00 rows=10000 width=41) (actual time=0.011..46.190 rows=10000 loops=1)
Total runtime: 25834.613 ms
Here the gain is only 1.5 times.
PS I hope this post helps someone. Comments and additions are welcome! Thank you for attention.