LVS + OpenVZ
- Tutorial
Good day, dear readers!
In this article I want to tell you about load balancing technology, a little about fault tolerance and how to make friends with containers in OpenVZ. We will cover the basics of LVS, operating modes, and setting up a bunch of LVS with containers in OpenVZ. The article contains both the theoretical aspects of the work of these technologies and the practical part - traffic forwarding from the balancer into the containers. If this interests you, welcome!
For a start - links to publications on this topic on Habré:
Detailed description of the work of LVS. You can’t say better.
Article about OpenVZ containers
Summary of material above:
LVS (Linux Virtual Server) is a technology based on IPVS (IP Virtual Server), which is present in Linux kernels from version 2.4.x and newer. It is a kind of virtual switch level 4.
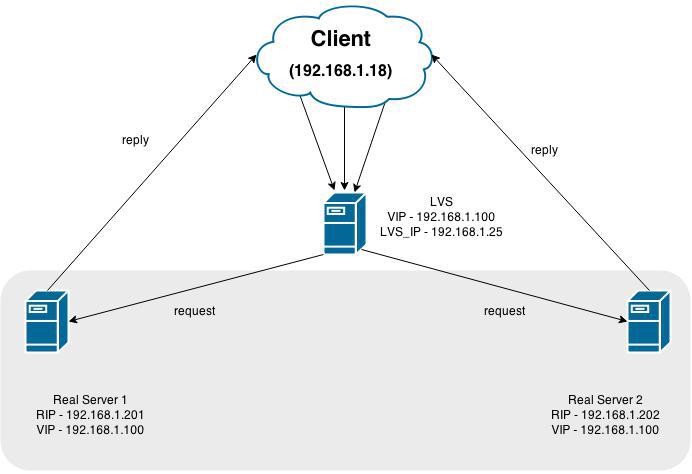
This picture shows LVS (the balancer itself), the virtual address to which the calls are accessed (VIP) 192.168.1.100 and 2 servers acting as back-end: 192.168.1.201 and 192.168.1.202
In the general case, everything works like this - we do entry point (VIP), where all requests come. Further, traffic is redirected to its backends, where it is processed and responded directly to the client (in the NAT scheme, the answer is returned via LVS back) You
can find the balancing methods here: link . Further in the article we believe that balancing Round-Robin
Operating modes:
A little more about each:
In this operating mode, the request is processed in the following scenario:
The client sends a packet to the network to the VIP address. This packet is caught by the LVS server, it replaces the MAKdestination address (and only it !!) to the poppy address of one of the back-end servers and the packet is sent back to the network. It is received by the back-end server, processes and sends the request directly to the client. The client receives a response to his request physically from another server, but does not see the substitution and rustles happily. The attentive reader will certainly be outraged - how can the Real Server process the request that came to a different IP address (in the packet, the destination address is still the same VIP)? And he will be right, because for correct operation, this address (VIP) should be placed somewhere in the back end, most often it is hung on a loopback. Thus, the biggest scam in this technology is committed.
The easiest mode of operation. The request from the client arrives at LVS, LVS redirects the request to the back-end, the latter processes the request, responds back to LVS, and the latter answers the client. It fits perfectly into the scheme where you have a gateway through which all the subnet traffic goes. Otherwise, doing NAT in the network will be extremely wrong.
It is an analogue of the first method, only traffic from LVS to backends is encapsulated in a packet. This is what we will configure below, so now I will not reveal all the cards :)
Install the server with LVS. Configuring on CentOS 6.6.
On a clean system, we do
Behind her, she will drag Apache, php and the ipvsadm we need. Apache and php are set up to access the administrative web-face, which I advise you to see once, configure everything basically and do not go there anymore :)
After installing all the packages, we do
set a password to access the admin panel:
After that, go to the IP_LVS address : 3636 /, enter the login (piranha) and password from the step above, and go to the admin panel:
Two tabs are interesting for us now - GLOBAL SETTINGS and VIRTUAL SERVERS.
Switch to GLOBAL SETTINGS and set the Tunneling operating mode.
On the VIRTUAL SERVERS tab, create one Virtual Server with the address 192.168.1.100 and port 80
There, on the REAL SERVER tab, we will set two back-end with the addresses 192.168.1.201 and 192.168.1.202 with ports 80
Details on the screenshots under the spoiler
We will leave the MONITORING SCRIPTS tab unchanged, although it is possible to configure the very flexible operation of checking the availability of nodes on it. By default, this is just a request of type GET / HTTP / 1.0 and checking that the web server responded to us.
You can execute arbitrary scripts, for example, such as under a spoiler.
We save the config, close the window and go to the console we are familiar with. If you suddenly wondered what we had generated there, then the service config is in /etc/sysconfig/ha/lvs.cf
We look at the current settings:
Not much. This is because our final nodes are not raised! I skip the installation and creation of OpenVZ containers, we believe that you magically have two containers with the addresses 192.168.1.201 and 192.168.1.202, and inside any web server on port 80 :)
Again, look at the output of the command:
Perfect! Exactly what is needed. If we suddenly turn off the web server on one of the nodes, then our balancer honestly will not send traffic there until the situation is corrected.
Let's take a closer look at our config for LVS:
The most interesting options here are timeout and reentry. In the given configuration, if our backend does not respond to us within 6 seconds, we will not send anything there. As soon as our bad guy will respond to us within 15 seconds - we can send traffic there.
There is still quiesce_server - if the server returns to service, then all connection counters are reset to zero and connections begin to be distributed as after the service was started.
LVS has its own Active Passive mechanism, which is not considered in the framework of this article, and I do not really like it. I would recommend using Pacemaker, as it has built-in mechanisms for throwing the pulse service (which is responsible for the whole mechanism)
But let's get back to reality.
Our cars are seen, the balancer is ready to send traffic to them. Let's do it on LVS
and try to contact our VIP for example:
Let's figure it out! There may be several reasons, and one of them is iptables on lvs. Although he is engaged in the transfer of traffic, but the port should be accessible. We arm ourselves with tcpdump and climb on LVS.
We start and see:
Requests came, what happened to them next?
There
And the traffic doesn’t go ... Trouble! We go to our nodes with OpenVZ, go inside the virtual machines and look at the traffic there. Requests from LVS reached them, but cannot be processed - protocol 4 is IP-in-IP
for us. We enable tunnel support for virtual machines
Do not forget to add them to startup -
We allow our virtual machines to have tunnel interfaces:
After that restart the containers.
Now we need to add an address inside the containers to this (tun0) interface. So let's do it:
Why is that?
Now running tcpdump we will see the long-awaited requests!
192.168.1.18 is the client.
The request reached the car! All cookies! But to stop early, continue. Why is no one answering us? It's all about the tricky kernel configuration, which checks the return path to the source - rp_filter
Turn off this check for our interface inside the container:
We check:
Answers! Answers! But the miracle is still not happening. Sorry Mario, your princess is in another castle. To go to another castle, first write everything down:
Turn off the rp_filter check and add an interface. Inside the containers:
And on the nodes:
Restart to confirm that everything is correct.
As a result of restarting the container, there should be such a picture:
And the princess is hidden in venet, as it is not sad. The technology of this device imposes the following limitations :
Those. our node does not accept packets that come with left sorts. And now the main crutch - add this address to the container! Let them be two addresses for each machine!
On the nodes, execute:
Of course, we get the warning that such an address is already in the grid! But balancing requires sacrifice.
Why do we need to delete routes - so that we do not broadcast this address to the network and other machines do not know about it. Those. formally, all requirements are met - the answer from the machine comes with the address 192.168.1.100, it has such an address. We are working!
To simplify the work, I want to recommend the script mount mechanism in OpenVZ, but in its pure form it will not help us, because an address route is added after the mount operation, and start scripts are executed inside the container.
The solution came from the OpenVZ forum.
We make two files (example for one container):
We will restart the container for verification, and now that moment has come - we open 192.168.1.100 iiii ... VICTORY!
A few more brief notes:
1) The worst thing that happens with this balancing is when the address carefully hung inside the container or on lo (for the Direct mode of operation) starts broadcasting to the network. Two tools will help you prevent this scenario - configuration tests and arptables . The tool is similar to iptables, but for ARP requests. I actively use it for my purposes - we prohibit certain arps from getting into the network.
2) This solution is not Enterprise level, because replete with crutches and bottlenecks. If you have the opportunity, use NAT, Direct, and only then Tunnel. This is due to the fact that, for example, in Direct - if the backend is active in ipvsadm output, then it will receive traffic to you. Here, he may not receive it, although the port is considered accessible and packets will fly there.
4) In normal virtualization (KVM, VmWare and others) - there will be no problems, as well as will not arise using veth devices.
5) To diagnose any problems with LVS - use tcpdump. And just use it too :)
Thank you for your attention!
In this article I want to tell you about load balancing technology, a little about fault tolerance and how to make friends with containers in OpenVZ. We will cover the basics of LVS, operating modes, and setting up a bunch of LVS with containers in OpenVZ. The article contains both the theoretical aspects of the work of these technologies and the practical part - traffic forwarding from the balancer into the containers. If this interests you, welcome!
For a start - links to publications on this topic on Habré:
Detailed description of the work of LVS. You can’t say better.
Article about OpenVZ containers
Summary of material above:
LVS (Linux Virtual Server) is a technology based on IPVS (IP Virtual Server), which is present in Linux kernels from version 2.4.x and newer. It is a kind of virtual switch level 4.
This picture shows LVS (the balancer itself), the virtual address to which the calls are accessed (VIP) 192.168.1.100 and 2 servers acting as back-end: 192.168.1.201 and 192.168.1.202
In the general case, everything works like this - we do entry point (VIP), where all requests come. Further, traffic is redirected to its backends, where it is processed and responded directly to the client (in the NAT scheme, the answer is returned via LVS back) You
can find the balancing methods here: link . Further in the article we believe that balancing Round-Robin
Operating modes:
- 1) Direct A lot of things about him
- 2) NAT Infromation about this mode of operation
- 3) Tunnel And about him
A little more about each:
1) Direct
In this operating mode, the request is processed in the following scenario:
The client sends a packet to the network to the VIP address. This packet is caught by the LVS server, it replaces the MAKdestination address (and only it !!) to the poppy address of one of the back-end servers and the packet is sent back to the network. It is received by the back-end server, processes and sends the request directly to the client. The client receives a response to his request physically from another server, but does not see the substitution and rustles happily. The attentive reader will certainly be outraged - how can the Real Server process the request that came to a different IP address (in the packet, the destination address is still the same VIP)? And he will be right, because for correct operation, this address (VIP) should be placed somewhere in the back end, most often it is hung on a loopback. Thus, the biggest scam in this technology is committed.
2) NAT
The easiest mode of operation. The request from the client arrives at LVS, LVS redirects the request to the back-end, the latter processes the request, responds back to LVS, and the latter answers the client. It fits perfectly into the scheme where you have a gateway through which all the subnet traffic goes. Otherwise, doing NAT in the network will be extremely wrong.
3) Tunnel
It is an analogue of the first method, only traffic from LVS to backends is encapsulated in a packet. This is what we will configure below, so now I will not reveal all the cards :)
Practice!
Install the server with LVS. Configuring on CentOS 6.6.
On a clean system, we do
yum install piranha
Behind her, she will drag Apache, php and the ipvsadm we need. Apache and php are set up to access the administrative web-face, which I advise you to see once, configure everything basically and do not go there anymore :)
After installing all the packages, we do
/etc/init.d/piranha-gui start ; /etc/init.d/httpd start
set a password to access the admin panel:
piranha-passwd
After that, go to the IP_LVS address : 3636 /, enter the login (piranha) and password from the step above, and go to the admin panel:
So to say admin
Two tabs are interesting for us now - GLOBAL SETTINGS and VIRTUAL SERVERS.
Switch to GLOBAL SETTINGS and set the Tunneling operating mode.
Little lyrical digression about OpenVZ
As you probably already know, if you worked with OpenVZ, the user is given a choice of two types of interfaces - venet and veth. The fundamental difference between the two is that veth is essentially a virtual network interface for each virtual machine with its own poppy address. Venet is a huge 3 level switch that all your machines are connected to.
You can read in more detail here.
A comparison table of interfaces from the link above:
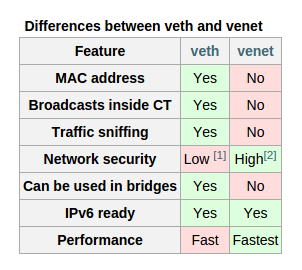
It so happened that venet is used everywhere in my work, so the configuration is done on it.
I must say right away - I failed to configure LVS-Direcrt for this type of interface. Everything rests on the fact that a node with virtual machines receives traffic, but does not know which machine to send it to. I’ll dwell on this a little more when traffic is forwarded into the container.
You can read in more detail here.
A comparison table of interfaces from the link above:
It so happened that venet is used everywhere in my work, so the configuration is done on it.
I must say right away - I failed to configure LVS-Direcrt for this type of interface. Everything rests on the fact that a node with virtual machines receives traffic, but does not know which machine to send it to. I’ll dwell on this a little more when traffic is forwarded into the container.
On the VIRTUAL SERVERS tab, create one Virtual Server with the address 192.168.1.100 and port 80
There, on the REAL SERVER tab, we will set two back-end with the addresses 192.168.1.201 and 192.168.1.202 with ports 80
Details on the screenshots under the spoiler
Setup Screenshots
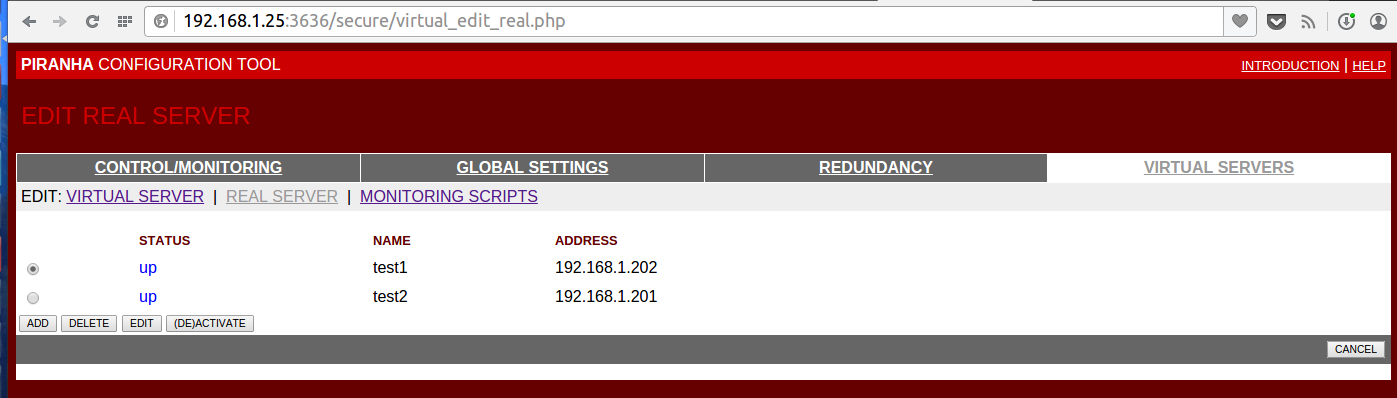
We will leave the MONITORING SCRIPTS tab unchanged, although it is possible to configure the very flexible operation of checking the availability of nodes on it. By default, this is just a request of type GET / HTTP / 1.0 and checking that the web server responded to us.
You can execute arbitrary scripts, for example, such as under a spoiler.
Scripts for checking various services
For example muscle
And the check in LVS is considered successful if the script returned UP and not successful if DOWN. He displays the server according to the results of the test
A piece of the config for this check
#!/bin/sh
CMD=/usr/bin/mysqladmin
IS_ALIVE=`timeout 2s $CMD -h $1 -P $2 ping | grep -c "alive"`
if [ "$IS_ALIVE" = "1" ]; then
echo "UP"
else
echo "DOWN"
fi
And the check in LVS is considered successful if the script returned UP and not successful if DOWN. He displays the server according to the results of the test
A piece of the config for this check
expect = "UP"
use_regex = 0
send_program = "/opt/admin/mysql_chesk.sh %h 9005"
We save the config, close the window and go to the console we are familiar with. If you suddenly wondered what we had generated there, then the service config is in /etc/sysconfig/ha/lvs.cf
We look at the current settings:
ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.100:80 wlc
Not much. This is because our final nodes are not raised! I skip the installation and creation of OpenVZ containers, we believe that you magically have two containers with the addresses 192.168.1.201 and 192.168.1.202, and inside any web server on port 80 :)
Again, look at the output of the command:
ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.100:80 wlc
-> 192.168.1.201:80 Tunnel 1 0 0
-> 192.168.1.202:80 Tunnel 1 0 0
Perfect! Exactly what is needed. If we suddenly turn off the web server on one of the nodes, then our balancer honestly will not send traffic there until the situation is corrected.
Let's take a closer look at our config for LVS:
/etc/sysconfig/ha/lvs.cf
serial_no = 4
primary = 192.168.1.25
service = lvs
network = tunnel
debug_level = NONE
virtual habrahabr {
active = 1
address = 192.168.1.100 eth0: 1
port = 80
send = "GET / HTTP / 1.0 \ r \ n \ r \ n "
Expect =" HTTP "
use_regex = 0
load_monitor = none
scheduler = wlc
protocol = tcp
timeout = 6
reentry = 15
quiesce_server = 0
server test1 {
address = 192.168.1.202
active = 1
weight = 1
}
server test2 {
address = 192.168.1.201
active = 1
weight = 1
}
}
primary = 192.168.1.25
service = lvs
network = tunnel
debug_level = NONE
virtual habrahabr {
active = 1
address = 192.168.1.100 eth0: 1
port = 80
send = "GET / HTTP / 1.0 \ r \ n \ r \ n "
Expect =" HTTP "
use_regex = 0
load_monitor = none
scheduler = wlc
protocol = tcp
timeout = 6
reentry = 15
quiesce_server = 0
server test1 {
address = 192.168.1.202
active = 1
weight = 1
}
server test2 {
address = 192.168.1.201
active = 1
weight = 1
}
}
The most interesting options here are timeout and reentry. In the given configuration, if our backend does not respond to us within 6 seconds, we will not send anything there. As soon as our bad guy will respond to us within 15 seconds - we can send traffic there.
There is still quiesce_server - if the server returns to service, then all connection counters are reset to zero and connections begin to be distributed as after the service was started.
LVS has its own Active Passive mechanism, which is not considered in the framework of this article, and I do not really like it. I would recommend using Pacemaker, as it has built-in mechanisms for throwing the pulse service (which is responsible for the whole mechanism)
But let's get back to reality.
Our cars are seen, the balancer is ready to send traffic to them. Let's do it on LVS
chkconfig pulse on
and try to contact our VIP for example:
Result
curl -vv http://192.168.1.100
* Rebuilt URL to: http://192.168.1.100/
* About to connect() to 192.168.1.100 port 80 (#0)
* Trying 192.168.1.100...
* Adding handle: conn: 0x7e9aa0
* Adding handle: send: 0
* Adding handle: recv: 0
* Curl_addHandleToPipeline: length: 1
* - Conn 0 (0x7e9aa0) send_pipe: 1, recv_pipe: 0
* Connection timed out
* Failed connect to 192.168.1.100:80; Connection timed out
* Closing connection 0
curl: (7) Failed connect to 192.168.1.100:80; Connection timed out
Let's figure it out! There may be several reasons, and one of them is iptables on lvs. Although he is engaged in the transfer of traffic, but the port should be accessible. We arm ourselves with tcpdump and climb on LVS.
We start and see:
tcpdump -i any host 192.168.1.100
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
13:36:09.802373 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2106524 ecr 0,nop,wscale 7], length 0
13:36:10.799885 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2106774 ecr 0,nop,wscale 7], length 0
13:36:12.803726 IP 192.168.1.18.37222 > 192.168.1.100.http: Flags [S], seq 3328911904, win 29200, options [mss 1460,sackOK,TS val 2107275 ecr 0,nop,wscale 7], length 0
Requests came, what happened to them next?
There
tcpdump -i any host 192.168.1.201 or host 192.168.1.202
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
13:37:08.257049 IP 192.168.1.25 > 192.168.1.201: IP 192.168.1.18.37293 > 192.168.1.100.http: Flags [S], seq 1290874035, win 29200, options [mss 1460,sackOK,TS val 2121142 ecr 0,nop,wscale 7], length 0 (ipip-proto-4)
13:37:08.257538 IP 192.168.1.201 > 192.168.1.25: ICMP 192.168.1.201 protocol 4 unreachable, length 88
13:37:09.255564 IP 192.168.1.25 > 192.168.1.201: IP 192.168.1.18.37293 > 192.168.1.100.http: Flags [S], seq 1290874035, win 29200, options [mss 1460,sackOK,TS val 2121392 ecr 0,nop,wscale 7], length 0 (ipip-proto-4)
13:37:09.256192 IP 192.168.1.201 > 192.168.1.25: ICMP 192.168.1.201 protocol 4 unreachable, length 88
And the traffic doesn’t go ... Trouble! We go to our nodes with OpenVZ, go inside the virtual machines and look at the traffic there. Requests from LVS reached them, but cannot be processed - protocol 4 is IP-in-IP
for us. We enable tunnel support for virtual machines
На нодах:
modprobe ipip
Видим в выводе lsmod | grep ipip модули
Do not forget to add them to startup -
cd /etc/sysconfig/modules/
echo "#!/bin/sh" > ipip.modules
echo "/sbin/modprobe ipip" >> ipip.modules
chmod +x ipip.modules
We allow our virtual machines to have tunnel interfaces:
vzctl set 201 --feature ipip:on --save
vzctl set 202 --feature ipip:on --save
After that restart the containers.
Now we need to add an address inside the containers to this (tun0) interface. So let's do it:
ifconfig tunl0 192.168.1.100 netmask 255.255.255.255 broadcast 192.168.1.100
Why is that?
Direct, Tunnel and Addresses
The common feature of these two methods is that in the final system (backend) VIP addresses are added for correct operation. Why is that? The answer is simple: the client accesses a fixed address and expects an answer from him. If someone from another address answers him, the client will consider such an answer as an error and simply ignore it. Imagine that you are asking to call the lovely girl Oksana to the phone, and the hoarse voice of Valentin Yakovlevich answers you.
For Direct, the processing steps of a package are arranged in a chain:
The client makes an ARP request to the VIP address, receives a response, generates a request with data, sends it to VIP, LVS caught these packets, changed the MAK there, gave it back to the network, the network equipment delivered the backend package via the poppy, he began to deploy it starting from the second level. MAK is mine? Yes. Is my IP? Yes. Processed and responded with source VIP (the package is intended for him) and destination client.
For Tunnel, the situation is almost the same, only without replacing the IAC, but full encapsulated traffic. The backend received a package designed specifically for him, and inside the request for a VIP address, which the backend must process and respond.
For Direct, the processing steps of a package are arranged in a chain:
The client makes an ARP request to the VIP address, receives a response, generates a request with data, sends it to VIP, LVS caught these packets, changed the MAK there, gave it back to the network, the network equipment delivered the backend package via the poppy, he began to deploy it starting from the second level. MAK is mine? Yes. Is my IP? Yes. Processed and responded with source VIP (the package is intended for him) and destination client.
For Tunnel, the situation is almost the same, only without replacing the IAC, but full encapsulated traffic. The backend received a package designed specifically for him, and inside the request for a VIP address, which the backend must process and respond.
Now running tcpdump we will see the long-awaited requests!
tcpdump -i any host 192.168.1.18
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
14:03:28.907670 IP 192.168.1.18.38850 > 192.168.1.100.http: Flags [S], seq 3110076845, win 29200, options [mss 1460,sackOK,TS val 2516581 ecr 0,nop,wscale 7], length 0
14:03:29.905359 IP 192.168.1.18.38850 > 192.168.1.100.http: Flags [S], seq 3110076845, win 29200, options [mss 1460,sackOK,TS val 2516831 ecr 0,nop,wscale 7], length 0
192.168.1.18 is the client.
The request reached the car! All cookies! But to stop early, continue. Why is no one answering us? It's all about the tricky kernel configuration, which checks the return path to the source - rp_filter
Turn off this check for our interface inside the container:
echo 0 > /proc/sys/net/ipv4/conf/tunl0/rp_filter
We check:
tcpdump -i any host 192.168.1.18
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 65535 bytes
14:07:03.870449 IP 192.168.1.18.39051 > 192.168.1.100.http: Flags [S], seq 89280152, win 29200, options [mss 1460,sackOK,TS val 2570336 ecr 0,nop,wscale 7], length 0
14:07:03.870499 IP 192.168.1.100.http > 192.168.1.18.39051: Flags [S.], seq 593110812, ack 89280153, win 14480, options [mss 1460,sackOK,TS val 3748869 ecr 2570336,nop,wscale 7], length 0
Answers! Answers! But the miracle is still not happening. Sorry Mario, your princess is in another castle. To go to another castle, first write everything down:
Turn off the rp_filter check and add an interface. Inside the containers:
echo "net.ipv4.conf.tunl0.rp_filter = 0" >> /etc/sysctl.conf
echo "ifconfig tunl0 192.168.1.100 netmask 255.255.255.255 broadcast 192.168.1.100" >> /etc/rc.local
And on the nodes:
echo "net.ipv4.conf.venet0.rp_filter = 0" >> /etc/sysctl.conf
Restart to confirm that everything is correct.
As a result of restarting the container, there should be such a picture:
ip a
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: venet0: mtu 1500 qdisc noqueue state UNKNOWN
link/void
inet 127.0.0.1/32 scope host venet0
inet 192.168.1.202/32 brd 192.168.1.202 scope global venet0:0
3: tunl0: mtu 1480 qdisc noqueue state UNKNOWN
link/ipip 0.0.0.0 brd 0.0.0.0
inet 192.168.1.100/32 brd 192.168.1.100 scope global tunl0
cat /proc/sys/net/ipv4/conf/tunl0/rp_filter
0
And the princess is hidden in venet, as it is not sad. The technology of this device imposes the following limitations :
Venet drop ip-packets from the container with a source address, and in the container with the destination address, which is not corresponding to an ip-address of the container .
Those. our node does not accept packets that come with left sorts. And now the main crutch - add this address to the container! Let them be two addresses for each machine!
Illustration of such a decision
On the nodes, execute:
vzctl set 201 --ipadd 192.168.1.100 --save
vzctl set 202 --ipadd 192.168.1.100 --save
и тут же на обоих нодах
ip ro del 192.168.1.100 dev venet0 scope link
Of course, we get the warning that such an address is already in the grid! But balancing requires sacrifice.
Why do we need to delete routes - so that we do not broadcast this address to the network and other machines do not know about it. Those. formally, all requirements are met - the answer from the machine comes with the address 192.168.1.100, it has such an address. We are working!
To simplify the work, I want to recommend the script mount mechanism in OpenVZ, but in its pure form it will not help us, because an address route is added after the mount operation, and start scripts are executed inside the container.
The solution came from the OpenVZ forum.
We make two files (example for one container):
cat /etc/vz/conf/202.mount
#!/bin/bash
. /etc/vz/start_stript/202.sh &
disown
exit 0
cat /etc/vz/start_stript/202.sh
#!/bin/bash
_sleep() {
sleep 4
status=(`/usr/sbin/vzctl status 202`)
x=1
until [ $x == 6 ] ; do
sleep 1
if [ ${status[4]} == "running" ] ; then
ip ro del 192.168.1.100 dev venet0 scope link
exit 0
else
x=`expr $x + 1`
fi
done
}
_sleep
И делаем исполняемыми:
chmod +x /etc/vz/start_stript/202.sh
chmod +x /etc/vz/conf/202.mount
We will restart the container for verification, and now that moment has come - we open 192.168.1.100 iiii ... VICTORY!
A few more brief notes:
1) The worst thing that happens with this balancing is when the address carefully hung inside the container or on lo (for the Direct mode of operation) starts broadcasting to the network. Two tools will help you prevent this scenario - configuration tests and arptables . The tool is similar to iptables, but for ARP requests. I actively use it for my purposes - we prohibit certain arps from getting into the network.
2) This solution is not Enterprise level, because replete with crutches and bottlenecks. If you have the opportunity, use NAT, Direct, and only then Tunnel. This is due to the fact that, for example, in Direct - if the backend is active in ipvsadm output, then it will receive traffic to you. Here, he may not receive it, although the port is considered accessible and packets will fly there.
4) In normal virtualization (KVM, VmWare and others) - there will be no problems, as well as will not arise using veth devices.
5) To diagnose any problems with LVS - use tcpdump. And just use it too :)
Thank you for your attention!