Intel® Graphics Technology. Part I: Almost Gran Turismo

In a post about the "innovations" of Parallel Studio XE 2015, I promised to write about an interesting technology from Intel - Graphics Technology. Actually, this is what I am going to do now. The essence of Intel Graphics Technology is to use the integrated graphics core in the processor to perform calculations on it. This is an offload on the schedule, which, of course, gives a performance boost. Is the integrated graphics so powerful that this growth will be really large?
Let's look at the family of new graphics cores GT1, GT2 and GT3 / GT3e, integrated into the processors of the 4th generation Intel Core.
Yes, the graphics were in the 3rd generation, but these are already “affairs of the past”. The GT1 core has the minimum performance, and the GT3 has the maximum:
| HD (GT) | HD 4200, HD 4400, HD 4600 (GT2) | HD 5000, Iris 5100 (GT3), Iris Pro 5200 (GT3e) | |
|---|---|---|---|
| API | DirectX 11.1, DirectX Shader Model 5.0, OpenGL 4.2, OpenCL 1.2 | ||
| The number of execution units (Execution Unit) | 10 | 20 | 40 |
| The number of FP operations per cycle | 160 | 320 | 640 |
| The number of threads on the actuator / total | 7/70 | 7/140 | 7/280 |
| L3 cache | 256 | 512 | 1024 |
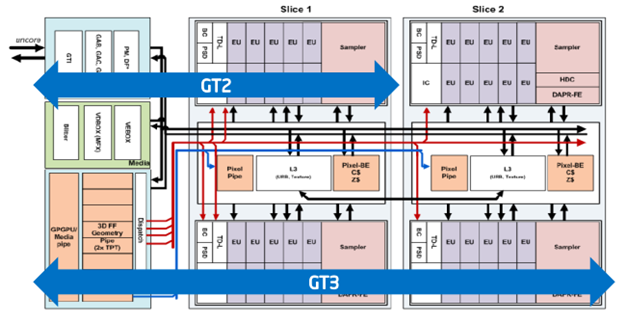
That is, for the case with GT1, everything will be almost the same, only the “layer” needs to be cut in half horizontally. We will not trifle, and dwell on the possibilities of graphics GT3e, as the most advanced example. So, we have 40 execution units with 7 threads per block. In total, we have up to 280 threads! A good increase in power for the "motor" of our system!
At the same time, each stream has 4 KB available in a register file (GRF - General Register File) - the fastest memory available for graphics to store local data. The total file size is 1120 KB.
In general, the memory model is of great interest and can be schematically represented as follows:
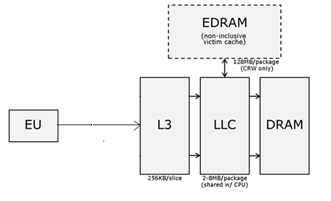
In addition to registers, the graph has its own L3 cache (256 KB for each ½ "layer"), as well as LLC (Last Level Cache), which is the L3 processor cache and, thus, common to the CPU and GPU. In terms of GPU computing, there are no L1 and L2 caches. Only in the most powerful GT3e configuration is another 128 MB of eDRAM cache available. It is located in the same case with the processor component, but is not part of the Haswell chip, and plays an important role in increasing the performance of the integrated graphics, almost eliminating the dependence on computer random access memory (DRAM), some of which can also be used as video memory.
Not all processor versions have the same integrated graphics. Server models prefer to have significantly more computing cores instead of graphics, so the cases in which Graphics Technology is possible are significantly narrowed. I finally waited for a laptop with Haswell and integrated Intel HD Graphics 4400 graphics, which means that you can play around with Intel Graphics Technology, which is supported on 64-bit Linux systems, as well as on 32 and 64 bit Windows systems.
Actually, everything is clear on the demand for hardware - without it, talking about calculations on the graphics core is pointless. The documentation (yes, yes ... I even had to read it, because it didn’t work right away) says that everything should work with these models:
- Intel Xeon Processor E3-1285 v3 and E3-1285L v3 (Intel C226 Chipset) with Intel HD Graphics P4700
- 4th generation Intel Core processors with Intel Iris Pro Graphics, Intel Iris Graphics or Intel HD Graphics 4200+ Series
- 3rd generation Intel Core processors with Intel HD Graphics 4000/2500
“The piece of iron is coming up, the GT compiler is installed. Everything should fly! ”I thought, and set about collecting the samples that came with the compiler for Graphics Technology.
From the point of view of the code, I did not notice anything extraordinary. Yes, some pragmas appeared before the cilk_for loops , like these:
void vector_add(float *a, float *b, float *c){
#pragma offload target(gfx) pin(a, b, c:length(N))
cilk_for(int i = 0; i < N; i++)
c[i] = a[i] + b[i];
return;
}
We will talk about this in detail in the next post, but for now we’ll try to collect a sample with the / Qoffload option . Everything seemed to be compiled, but the error that the linker (ld.exe) could not be found stopped me a bit. It turned out I missed one important point and not everything is so trivial. I had to delve into the documentation.
It turned out that the software stack for running an application with an offload to integrated graphics looks like this:

The compiler does not know how to generate code that can be immediately executed on the chart. He creates IR (Intermediate Representation) code for the vISA (Virtual Instruction Set Architecture) architecture. And that, in turn, can be executed (converted in runtime) on the chart using the JIT'ter, which is supplied in the installation package with drivers for Intel HD Graphics.
When compiling our code using the offload for Graphics Technology, an object collection is generated, into which the part running on the graphic core is “sewn”. This common file is called fat . When linking these “fat objects” like these, the code that runs on the chart will be in the section built into the binary on the host called .gfxobj (for Windows).
Here it becomes clear why the linker was not located. The Intel compiler does not and did not have its own linker, both on Linux and on Windows. And here in one file you need to “sew up” the object files in different formats. A simple linker from Microsoft does not know how to do this, so you need to install a special version of binutils (2.24.51.20131210), available here , and then write it to the same ld.exe (in my case C: \ Program Files (x86) \ Binutils for MinGW (64 bit) \ bin ) in PATH.
After installing everything I needed, I eventually put together a test project on Windows and got the following:
dumpbin matmult.obj
Microsoft (R) COFF/PE Dumper Version 12.00.30723.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file matmult.obj
File Type: COFF OBJECT
Summary
48 .CRT$XCU
2C .bss
5D0 .data
111C .data1
148F4 .debug$S
68 .debug$T
32F .drectve
33CF8 .gfxobj
6B5 .itt_notify_tab
8D0 .pdata
5A8 .rdata
AD10 .text
D50 .xdata
The desired object object for execution on the chart can be extracted from the fat object object using a special tool (offload_extract). If the environment for launching the Intel compiler is set in our console, it is very simple to do this:
offload_extract matmult.obj
As a result, in daddy you can find a separate object with the GFX prefix at the end, in my case - matmultGFX.o. Incidentally, it has never been in PE format, but in ELF.
By the way, if offload is not possible and the graphics core is not available during application launch, execution takes place on the host (CPU). This is achieved using compiler tools and offload runtime.
We figured out how everything should work. Further we will talk about what is available to the developer and how to write code that will eventually work on the chart.
There was so much information that everything could not fit into the framework of one post, therefore, as they say, “to be continued ...”.