Infinite localization, or how we translate the map in real time
What happens when your product starts to be sold in another country with its own language and cultural characteristics? Most likely, it is waiting for localization. In most cases, you only need to translate the resource files so that the menus and interface elements are in the language familiar to the user. But what to do if the basis of what you are selling is data, of which there are many, they come in constantly, in large volumes and require regular translation. And not in one language, but in several.
Under the cut, you will find the history, as this issue was solved in 2GIS. I will tell on the example of the last case with Dubai, but the practices are applicable for any language.
About Arabic
The whole story began with the fact that 2GIS was launched in Dubai, where two languages are used: Arabic and English.
High accuracy data - the most important value of the company. It is achieved by manual labor of cartographers and specialists in the field. In Dubai, where both local specialists and end users know English, initially data was entered only on it. In the process of growth, it was decided not to stop there and add Arabic.
Fiji
We have our own software for the work of cartographers. This thing is called Fiji and serves as a master system for collecting map data. We have already written how Fiji helps cartographers edit houses and draw roads. After processing and preparation, the data unloaded from Fiji goes to the final product to please the users. In the article, I am talking about exactly what we implemented in Fiji for editing / storing / displaying multilanguage data.
Terms
In the team, we use specific vocabulary. Below are four examples ↓
The system supports work with two types of languages:
Metadata language - a language in which all user controls are displayed: UI, metadata.
Data language is the language in which the values of attributes of geo-objects, some reference books and classifiers are displayed.
Languages are tied to territories. A territory may have two types of languages:
The main language of a territory is a language officially adopted in a given territory.
An additional language of the territory is the language in which we want to release a product. It goes in addition to the main.
Languages and dialects
Dialects adopted in different regions of the country may differ significantly. Therefore, in some systems, the core of the language (= basic variant) and dialects are stored separately, and then when unloading their merjat. We found this approach very difficult, so we decided to consider each dialect as an independent language.
The nuance associated with Arabic languages and dialects. For each language, you need to enter the carriage direction flag with two values: from left to right and from right to left. By default, the carriage should move from left to right. If the value is set from right to left, then you need to change the carriage direction for all editable, multilanguage fields. How this was done in the final products was written here . We needed to do about the same.
Binding to the territories
Our whole world is divided into certain territories - these can be countries, regions, regions. For each territory we specify several languages, one of which is considered the main one, and the rest are additional. Translation occurs from the main language to the additional.
For example, in the case of Dubai, we left English as the main language, because there was a lot of data on it. The Arabic was made optional.
Enter and change language
For comfortable work of cartographers, we reworked our interface in those places where multilingual input is implied.

In this picture you can see that we have broken the languages by tabs, where the leftmost one is the main language, and then there are additional ones.
In the tabs of additional languages, only those fields are available that have the flag of the need for translation in the database. This serves as a protective measure and helps to focus the user's attention on the translation of the necessary data. Everything else is edited in the main language.

In fact, editing data in an additional language may be needed only if the cartographer himself knows several languages and does not want to resort to the help of a translator. For everyone else there is CrowdIn.
CrowdIn, or transfer to stream
So, we have enabled our cartographers to fill in data in different languages. But it is much better to transfer the task of translation to professionals.
The first thing that comes to mind when translating an application is giving resource files to translators and loading them back after translation.
In this case, we were greatly helped by the CrowdIn platform. It allows you to redirect your files to professional translators. The matter remained for small - to integrate the translated data into our system.
The situation is complicated by the fact that the data to us comes in a continuous stream, therefore, we would like to receive transfers continuously.
We optimized the system like this: if changes are made in the main language of the territory, we upload the changes for translation into all additional languages of this territory. We make exceptions for cases when the translation was made by the cartographer himself. Here we believe that he understands what he is doing, and there is no need to connect a translator.
For each directory or map object, we have a pass-through version, which is incremented with each data update. So we can quickly receive all changes from a specific version.
The versioning system is very simple and effective, but it has a significant drawback: in fact, we have a single queue and cannot manage it in any way. Our maximum is to skip the version. There is a need to move to a normal queue, for example, RabitMQ or Kafka, but my hands have not reached it yet.
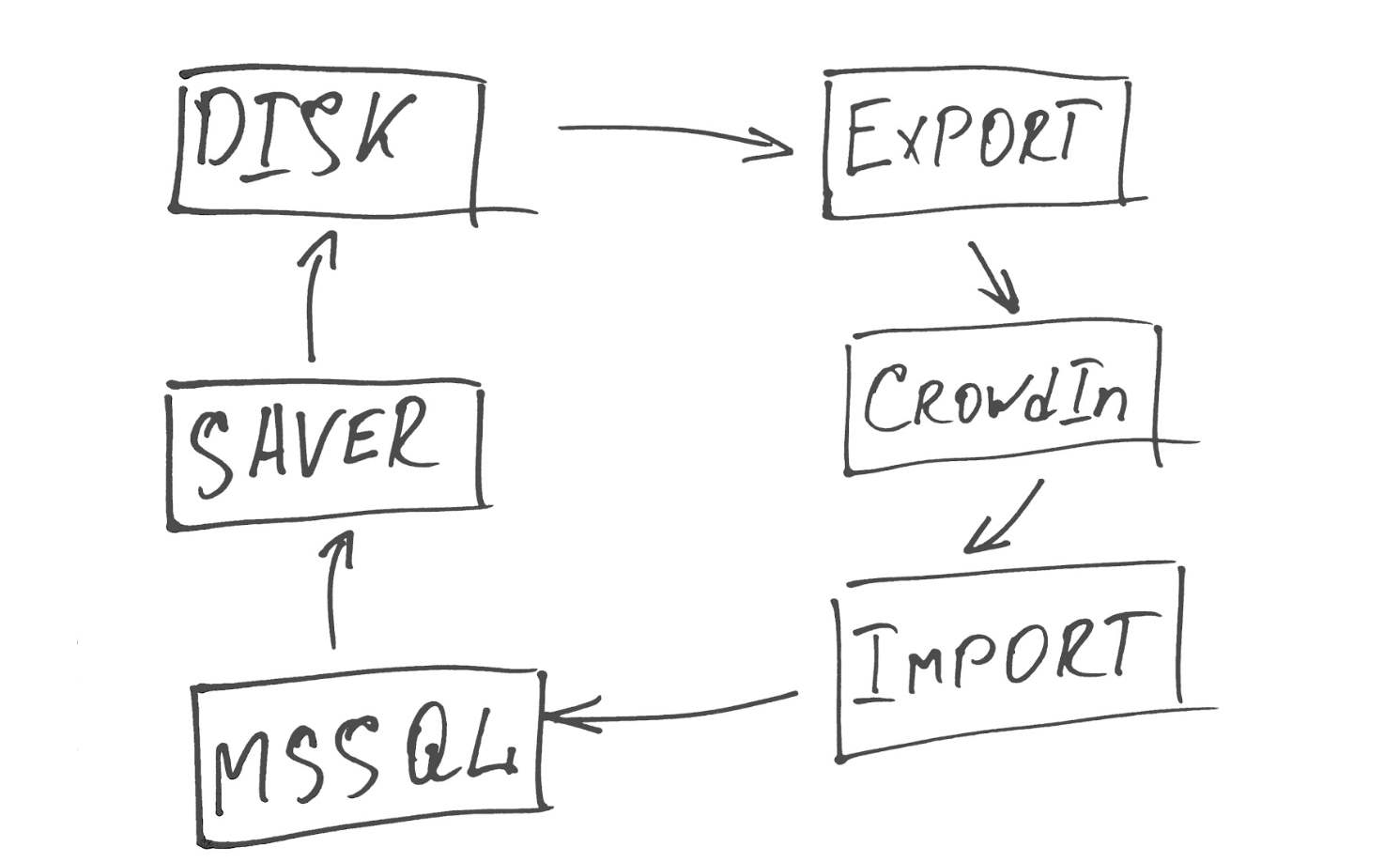
For online content update, we wrote a small service that works in three streams.
The first stream (Saver) removes all the data that needs translation, and generates xml files from it.
The second (Export) sends them to CrowdIn and adds them to the desired project, which shows the main language from which we translate, and the list of languages into which you want to translate.
The third (Import) periodically polls the CrowdIn API for files that have been translated and uploaded 100%, and imports the finished files into our database.
Without rake not done. We stumbled over our data versioning system.
When we downloaded the translation of the word, the data version was updated and the word again fell into translation.
To avoid an endless cycle of translation, we began to keep records of data. Each translated word is marked, which makes it possible to exclude its re-sending to CrowdIn.
Tutorial
Now I will tell you how the work with CrowdIn takes place. There are several ways to work with the platform, for example, you can upload files to the Git repository and CrowdIn will suck them themselves. But we thought that working through the API looks more convenient.
CrowdIn has a fairly detailed tutorial , but I’m writing below, as we did.
You need to get an API key, which we will cling to each of our requests for the system to verify us. Go to the API tab in the project settings and see what is written in the API key column.

This key must be appended at the end of each of your requests to the platform. For example:
GET:
https://api.crowdin.com/api/project/{myLitleProject}/download/all.zip?key={project-key}2. Create a folder where we will upload files inside the project.
var uri = $"project/{_projectName}/add-directory?key={apiKey}";
var content = new MultipartFormDataContent { { new StringContent(crowdInDirectoryPath), "name" } };
return PostAsync(uri, content);
There is a bit clumsy moment. We are writing a service, it would be nice if he first checked whether the folder we need is present before trying to create it. CrowdIn has no normal way to check for a folder, so we send a creation request. If it does not exist, CrowdIn will create it and return code 200. If the folder was, it will not create anything and return code 500.
3. Export files. The add-file function has a lot of options and parameters, how to read and from where. Below is an example of how we load data with xml files.
Example
All the data that we have gathered to translate, we add in the xml-files with the following structure.
In order for CrowdIn to parse what data from the file needs to be translated, it needs to indicate this. To do this, you need to write in the content an array of translatable_elements parameters with paths to the desired document elements. In our case, it looked like this:
<LocalizableDocument><LocalizableValues><LocalizableValue>
…
<Attributes><LocalizableAttributeValue><AttributeName/><Value/></LocalizableAttributeValue></Attributes></LocalizableValue></LocalizableValues></LocalizableDocument>In order for CrowdIn to parse what data from the file needs to be translated, it needs to indicate this. To do this, you need to write in the content an array of translatable_elements parameters with paths to the desired document elements. In our case, it looked like this:
var uri = $"project/{_projectName}/add-file?key={apiKey}";
var content = new MultipartFormDataContent { { new StringContent("/LocalizableDocument/LocalizableValues/LocalizableValue/Attributes/LocalizableAttributeValue/Value"), "translatable_elements[0]" } };
foreach (var filePath in filePaths)
{
var fileName = Path.GetFileName(filePath);
var fileStream = File.OpenRead(filePath);
var fileContent = new StreamContent(fileStream);
content.Add(fileContent, $"files[{_crowdInDirectoryPath}/{fileName}]", fileName);
}
return PostAsync(uri, content);
Please note: the documentation states that CrowdIn can chew a maximum of 20 files at a time, and the size of one file should not exceed 100 MB.
4. Find out which files we have fully translated. We do this with a command for a specific language.
var uri = $"project/{_projectName}/language-status?key={apiKey}";
var content = new MultipartFormDataContent {{ new StringContent(langCode), "language" } };
return PostAsync(uri, content);
The platform will return something to us:
<item><node_type>directory</node_type><id>29812</id><name>Version 1.0</name><files><item><node_type>file</node_type><id>29827</id><name>strings.xml</name><node_type>file</node_type><phrases>7</phrases><translated>0</translated><approved>0</approved><words>32</words><words_translated>0</words_translated><words_approved>0</words_approved></item></files></item>Here we are interested in the values of <translated /> and <approved />. The first one shows the percentage of translated lines in this file, the second - the percentage of approved values, if in vlkflou, in addition to the translator, the revier is also involved. Depending on our workflow, for example, at 100, we consider the document translated and approved. Now this file can be imported back to us.
5. Import the file back to our system.
This is done using a simple GET request.
https://api.crowdin.com/api/project/{_projectName}/export-file?file={_crowdInDirectoryPath}/{fileName}&language={langCode}&key={project-key}The resulting file is deserialized and the data is imported into our system.
Instead of conclusion
In general, that's all. Of course, we also needed to refine the display of the signatures on the Fiji map so that they appear in the correct language depending on what territory the cartographer is now ruling. It was necessary to agree with other systems, how we will supply them with multilingual data, but this is another story.
As a result, we received a service in the spirit of "included and forgotten." Cartographers enter data, translators translate, the sheikh is satisfied, the service fills in the data where necessary, and we solve more urgent tasks without thinking about how our system works in several languages.