Hedgehog with a snake in one basket, as well as a little about the lack of a scheme
Recently, I often see articles about why you should use nosql or that you should never use it and rely only on relational storage. However, in my opinion, these excellent tools can coexist perfectly, allowing you to use their common advantages and avoid their shortcomings.

About a year ago, our team got a great opportunity to work on the site of one new English television channel. Like most such projects, it focuses on entertainment and information programs, news, and also interacts with visitors through social networks.
The customer had two critical requirements, which guided us in choosing the technologies used to implement the project:
To guarantee the integrity of the data, we decided to store them in a relational form in MS SQL, and to ensure the speed of the user part of the site, we took mongodb. For each type of page has been created its own, denormalized collection of documents. Thus, the data is first stored in MS SQL, and then from there it is published to all the necessary mongo DB collections.
And why use monga if you can do with one SQL, you ask? To justify the choice, consider a few examples.
Let's start with an example entity diagram of a television show. We have a table of programs, seasons, episodes and episode broadcast dates:
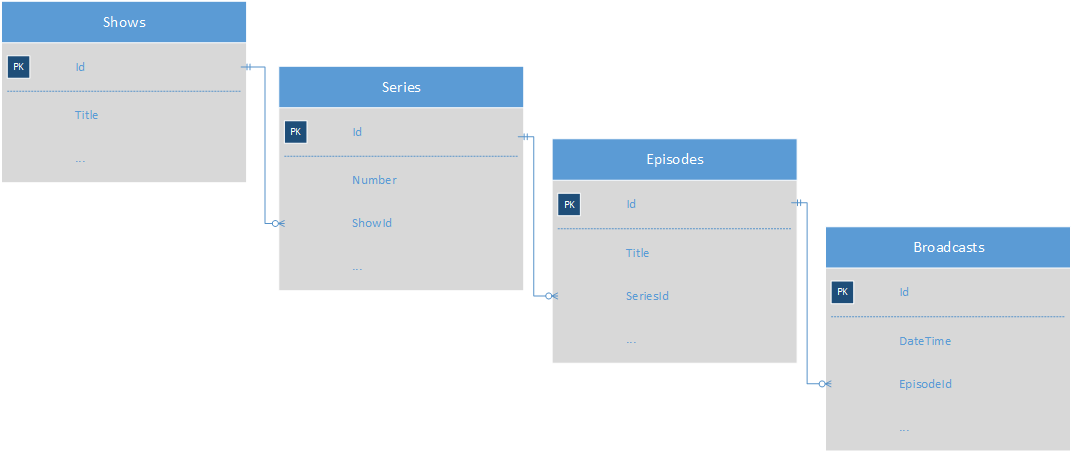
The program page contains a description of the program, a list of program seasons, a list of episodes with a brief description of the episode, the episode release date, and a link to its page. We have 3 options for obtaining the necessary data from a relational database:
In general, everything looks pretty good, but when using a denormalized collection of TV programs in Mong you don’t need to think up anything - just make one request that pulls out the data by identifier - and that’s all.
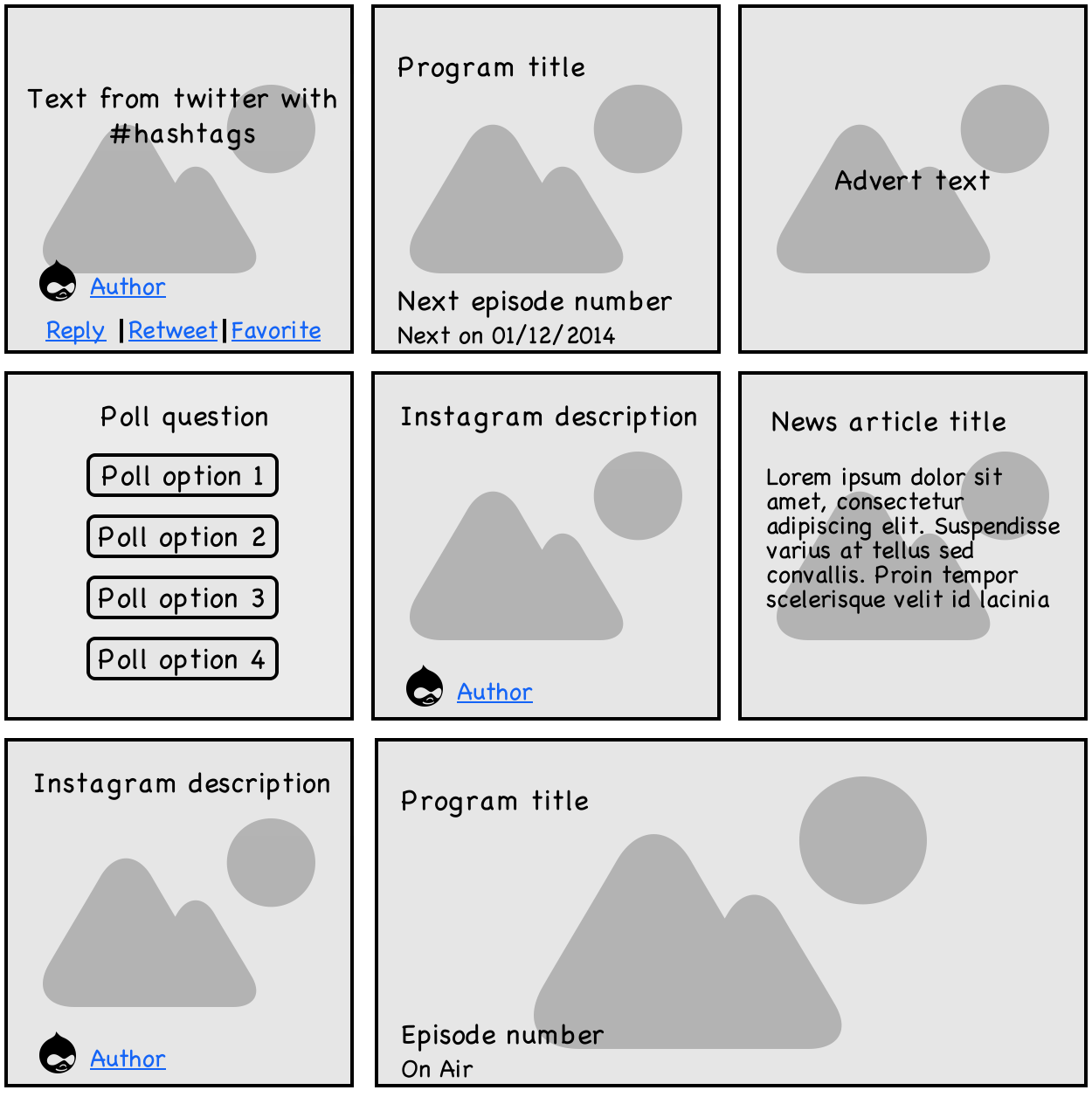
The site has several pages displaying the latest information - news, programs, posts from instagram and twitter, weather, advertising, information about interruptions in the subway, etc.
These data, which are very fragmented in structure, have a common nature and are displayed on the same pages - the latest information is displayed on the main page, only events related to it are displayed on the page of a region, only articles are displayed on the news page. In SQL, each type of tile is stored in a separate table, since their structure can seriously differ. Such a sample from a relational database turns into a small local hell - the number of queries to the database grows with each type of tile added, and this is not taking into account the complexity of writing such a sample directly in the code. In order to make life easier, one could use a table and metadata, data filtering is simplified, but the need to glue them into an object on the application side is added. And for this situation, any nosql repository like monga becomes an ideal solution to the problem. In earlier articles about mong on Habré, any mention of the absence of a scheme raised questions: “how so? There is always a scheme. ” Questions of this type are perfectly reasonable, but a little about that. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application.
Using sql and nosql in conjunction looks very attractive and convenient. However, as we know, for convenience it is necessary to pay for something. In our case, this is the need to write functionality for publishing data from sql to mongodb. In our opinion, this is an affordable price.
I tried not to get attached to the language in which the application is written and to sql and nosql tools. Instead of monga, you can substitute any other non-relational storage.
As a preface
About a year ago, our team got a great opportunity to work on the site of one new English television channel. Like most such projects, it focuses on entertainment and information programs, news, and also interacts with visitors through social networks.
The customer had two critical requirements, which guided us in choosing the technologies used to implement the project:
- It is very important that the data is consistent;
- The site should work with a sufficiently large number of simultaneous users.
To guarantee the integrity of the data, we decided to store them in a relational form in MS SQL, and to ensure the speed of the user part of the site, we took mongodb. For each type of page has been created its own, denormalized collection of documents. Thus, the data is first stored in MS SQL, and then from there it is published to all the necessary mongo DB collections.
And why use monga if you can do with one SQL, you ask? To justify the choice, consider a few examples.
First example
Let's start with an example entity diagram of a television show. We have a table of programs, seasons, episodes and episode broadcast dates:
The program page contains a description of the program, a list of program seasons, a list of episodes with a brief description of the episode, the episode release date, and a link to its page. We have 3 options for obtaining the necessary data from a relational database:
- One big request with joins. Good - one page request. Bad - a large amount of duplicated data and as a serious increase in the load on the database server;
- Four queries from ORM, one for each table. Good - no extra information is retrieved or returned in any request. Bad - actually four queries, for each of which it executes unit of work, which means that the context of connecting to the database is created and deleted four times. The option is quite traditional and even quite good; cons are solved by screwing the cache;
- A stored procedure that executes four queries and returns four datasets. Good - no extra data, one database request from the client. Bad - it is quite difficult to find an ORM for .net, in which such an opportunity is implemented in some kind of digestible form.
In general, everything looks pretty good, but when using a denormalized collection of TV programs in Mong you don’t need to think up anything - just make one request that pulls out the data by identifier - and that’s all.
Second example
The site has several pages displaying the latest information - news, programs, posts from instagram and twitter, weather, advertising, information about interruptions in the subway, etc.
These data, which are very fragmented in structure, have a common nature and are displayed on the same pages - the latest information is displayed on the main page, only events related to it are displayed on the page of a region, only articles are displayed on the news page. In SQL, each type of tile is stored in a separate table, since their structure can seriously differ. Such a sample from a relational database turns into a small local hell - the number of queries to the database grows with each type of tile added, and this is not taking into account the complexity of writing such a sample directly in the code. In order to make life easier, one could use a table and metadata, data filtering is simplified, but the need to glue them into an object on the application side is added. And for this situation, any nosql repository like monga becomes an ideal solution to the problem. In earlier articles about mong on Habré, any mention of the absence of a scheme raised questions: “how so? There is always a scheme. ” Questions of this type are perfectly reasonable, but a little about that. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application. The absence of a scheme in this context is the ability to save data with a different scheme, but of the same nature within the same collection. Using them, you can build indexes and filter data, as well as easily deserialize them into an object with the correct and desired type, which is easy to work with in the application.
How to pay?
Using sql and nosql in conjunction looks very attractive and convenient. However, as we know, for convenience it is necessary to pay for something. In our case, this is the need to write functionality for publishing data from sql to mongodb. In our opinion, this is an affordable price.
Instead of a conclusion
I tried not to get attached to the language in which the application is written and to sql and nosql tools. Instead of monga, you can substitute any other non-relational storage.