Node.js on fire
- Transfer
We are creating a new generation of Netflix.com web application using node.js. You can learn more about our trip from the presentation that we presented at NodeConf.eu a few months ago. Today I want to share my experience in tuning the performance of the new stack of our application.
We first encountered problems when we noticed that the request delay in our node.js application increases over time. In addition, it used more processor resources than we expected, and this correlated with the delay time. We had to use rebooting as a temporary solution while we searched for the cause using new tools and performance analytics techniques in our Linux EC2 environment.
We noticed that the request delay in our node.js application increases over time. So, on some of our servers, the delay grew from 1 millisecond to 10 milliseconds every hour. We also saw a dependency on increased CPU utilization.
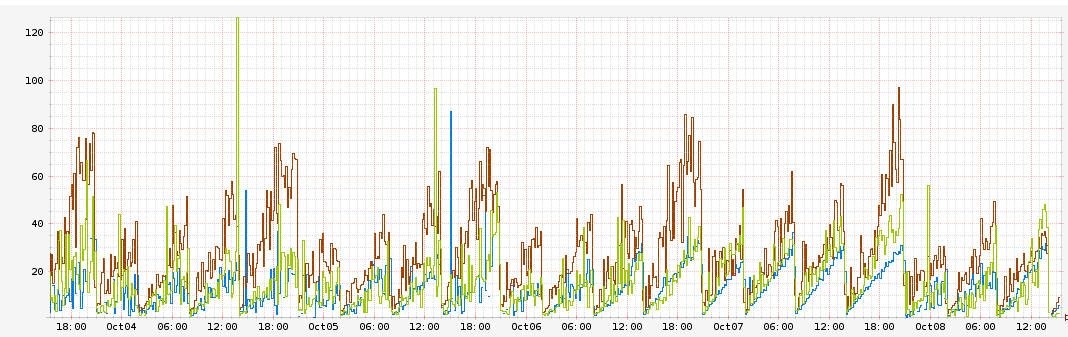
This graph shows the duration of the request delay in milliseconds relative to time. Each color represents a different instance of AWS AZ. You can see that the delay is constantly increasing by 10 milliseconds per hour and reaches 60 milliseconds before rebooting.
We initially suggested that these might be memory leaks in our own request handlers, which in turn caused delays. We tested this assumption by using load testing of an isolated application by adding metrics to measure latencies only on our request handlers and the total duration of the request delay, also increasing the size of used memory in node.js to 32 gigabytes.
We found out that the delay in our handlers remains constant and equals 1 millisecond. We also found that the amount of memory used by the process also remains unchanged, reaching approximately 1.2 gigabytes. However, overall latency and processor usage continued to grow. This meant that our handlers had nothing to do with it, and the problems were deeper on the stack.
Something added an extra 60 milliseconds to serving the request. We needed a way to profile the use of the processor by the application and visualize the received data. Linux Perf Events and flame graphs processor came to the rescue .
If you are not familiar with flame graphs, then I advise you to read Brendan Gregg's excellent article , in which he explains everything in detail. Here is a summary of it (directly from the article):
Previously, node.js flame graphs could only be used on systems with DTrace together with jstack () from Dave Pacheco. However, the Google V8 team recently added perf_events support to the V8 engine, which allows you to profile JavaScript on Linux. In this article, Brendan described the use of a new feature that appeared in node.js 0.11.13 to create flame graphs on Linux.
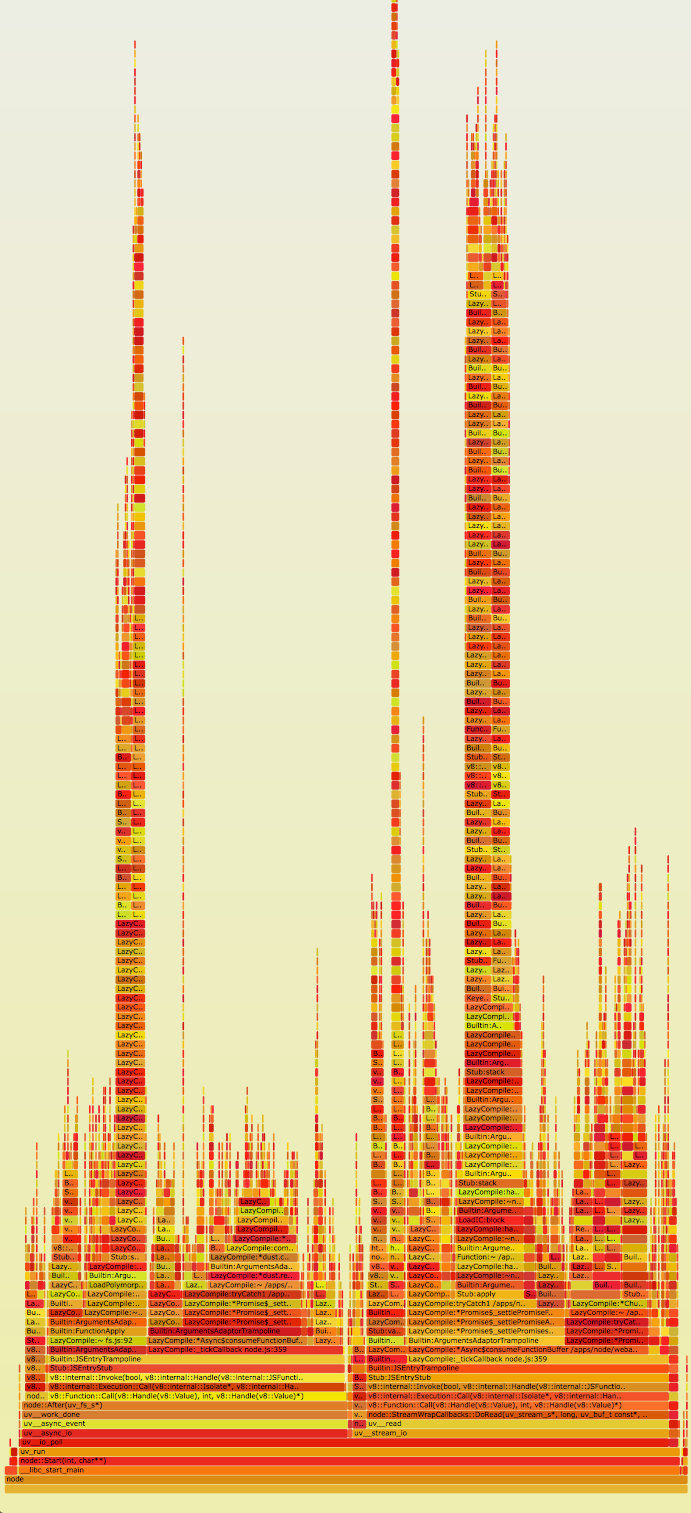
By this link you can see the original interactive flame graph of our application in SVG.
Immediately you can note the incredibly large stacks in the application (Y axis). It is also obvious that they take a lot of time (X axis). On closer inspection, it turns out that these stack frames are full of function references
We found two interesting points 1 in the Express source code :
A global array is not the most suitable data structure in this case, since in order to find a route, on average, O (n) operations are required . It is not clear why the Express developers decided not to use a permanent data structure, for example, a hash table for storing handlers. The situation is aggravated by the fact that the array is bypassed recursively. This explains why we saw such high stacks in flame graphs. It is also interesting that Express allows you to set multiple handlers for one route.
In this case, the search for the route
After starting the application displays these handlers:
Note that there are two identical handlers for the route
Now our assumption was that delays occurred due to the constant increase in the array with handlers. Most likely, handlers were duplicated somewhere in our code. We added additional logging, which displayed an array of request handlers, and noticed that it was growing at 10 elements per hour. These handlers were identical to each other, as in the example above.
Something added 10 identical handlers for static routes per hour to the application. Further, we found that when iterating through these handlers, the cost of calling each of them takes about 1 millisecond. This correlates with what we saw before, when the response delay grew by 10 milliseconds per hour.
It turned out that this was caused by periodic (10 times per hour) updating of handlers in our code from an external source. We implemented this by removing old handlers and adding new ones to the array. Unfortunately, also during this operation, we always added a handler for the static route. Since Express allows you to add multiple handlers for the same route, all these duplicates were added to the array. Worst of all, they were all added before the rest, which meant that before Express found the API handler for our service, it would call the handler for the static route several times.
This fully explains why request delays grew by 10 milliseconds per hour. In fact, after we fixed the error in our code, the constant increase in the delay time and the increase in CPU usage stopped.
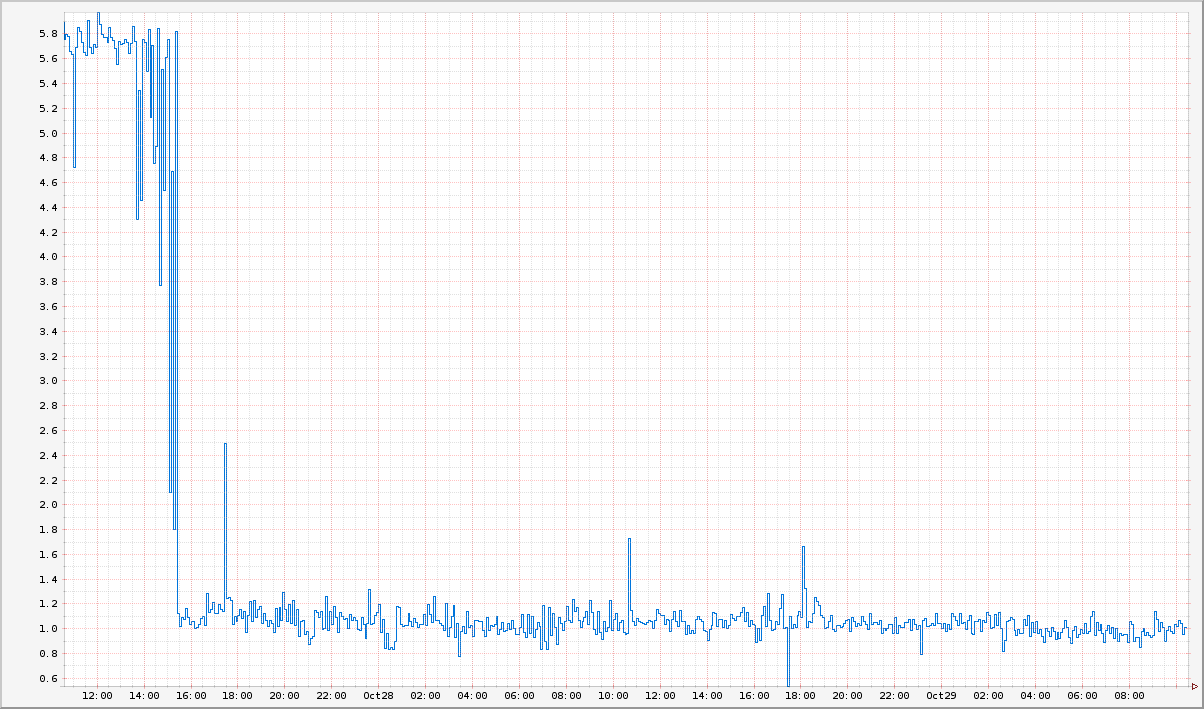
This graph shows that the delay time was reduced to one millisecond after updating the code.
What experience have we got? First, we need to fully understand how dependencies work in our code before using it in production. We made the wrong assumption that the Express API works without examining its code. Misuse of the Express API is the ultimate cause of our performance issues.
Secondly, in solving performance problems, visibility is of utmost importance. Flame graphs gave us a great understanding of where our application spends the most time and CPU resources. I cannot imagine how we could solve this problem by not being able to get the node.js stacks and visualize them using flame graphs.
Wanting to improve visibility, we are migrating to Restify, which will allow us to improve control over our application 2 . This is beyond the scope of this article, so read our blog post about how we use node.js on Netflix.
Want to solve such problems with us? Our team is looking for an engineer to work with the node.js stack.
Posted by Yunun Xiao @yunongx
Notes:
Translator Notes:
Comments and comments regarding the translation are welcome in private messages.
UPD : attentive readers have noticed that the translator incorrectly transcribed the name of the author of the original article. Thanks for the hints of domix32 and lany .
We first encountered problems when we noticed that the request delay in our node.js application increases over time. In addition, it used more processor resources than we expected, and this correlated with the delay time. We had to use rebooting as a temporary solution while we searched for the cause using new tools and performance analytics techniques in our Linux EC2 environment.
Fire flares up
We noticed that the request delay in our node.js application increases over time. So, on some of our servers, the delay grew from 1 millisecond to 10 milliseconds every hour. We also saw a dependency on increased CPU utilization.
This graph shows the duration of the request delay in milliseconds relative to time. Each color represents a different instance of AWS AZ. You can see that the delay is constantly increasing by 10 milliseconds per hour and reaches 60 milliseconds before rebooting.
Fire extinguishing
We initially suggested that these might be memory leaks in our own request handlers, which in turn caused delays. We tested this assumption by using load testing of an isolated application by adding metrics to measure latencies only on our request handlers and the total duration of the request delay, also increasing the size of used memory in node.js to 32 gigabytes.
We found out that the delay in our handlers remains constant and equals 1 millisecond. We also found that the amount of memory used by the process also remains unchanged, reaching approximately 1.2 gigabytes. However, overall latency and processor usage continued to grow. This meant that our handlers had nothing to do with it, and the problems were deeper on the stack.
Something added an extra 60 milliseconds to serving the request. We needed a way to profile the use of the processor by the application and visualize the received data. Linux Perf Events and flame graphs processor came to the rescue .
If you are not familiar with flame graphs, then I advise you to read Brendan Gregg's excellent article , in which he explains everything in detail. Here is a summary of it (directly from the article):
- Each block denotes a function on the stack (stack frame)
- The Y axis indicates the depth of the stack (the number of frames in the stack). The upper block denotes the function that the processor performed, all that is lower is the stack of its call.
- The X axis indicates the number of function calls. It does not show the amount of time spent by the function, as on most graphs. The order does not matter, the blocks are simply sorted in lexicographical order.
- The width of the block indicates the total execution time of the function by the processor or part of the execution time of the function that called it. Wide blocks of functions can be performed more slowly than narrow ones, or they can simply be called more often.
- The number of calls may exceed the time if the function was executed in several threads.
- Colors have no special meaning and are determined in an arbitrary order from “warm” tones. Flame graphs [literally "flame graphics"; approx. translator] are called so because they show the “hottest” places in the application code.
Previously, node.js flame graphs could only be used on systems with DTrace together with jstack () from Dave Pacheco. However, the Google V8 team recently added perf_events support to the V8 engine, which allows you to profile JavaScript on Linux. In this article, Brendan described the use of a new feature that appeared in node.js 0.11.13 to create flame graphs on Linux.
By this link you can see the original interactive flame graph of our application in SVG.
{kind=link}
Immediately you can note the incredibly large stacks in the application (Y axis). It is also obvious that they take a lot of time (X axis). On closer inspection, it turns out that these stack frames are full of function references
route.handleand route.handle.nextfromExpress . We found two interesting points 1 in the Express source code :
- Route handlers for all paths are stored in one global array
- Express recursively iterates and calls all the handlers until it finds a suitable route
A global array is not the most suitable data structure in this case, since in order to find a route, on average, O (n) operations are required . It is not clear why the Express developers decided not to use a permanent data structure, for example, a hash table for storing handlers. The situation is aggravated by the fact that the array is bypassed recursively. This explains why we saw such high stacks in flame graphs. It is also interesting that Express allows you to set multiple handlers for one route.
[a, b, c, c, c, c, d, e, f, g, h]
In this case, the search for the route
cwould be stopped when the first suitable handler was found (position 2 in the array). However, in order to find the route handler d(position 6 in the array), it would be necessary to spend extra time on calling several instances c. We tested this with a simple Express application:var express = require('express');
var app = express();
app.get('/foo', function (req, res) {
res.send('hi');
});
// добавляем еще один обработчик на тот же маршрут
app.get('/foo', function (req, res) {
res.send('hi2');
});
console.log('stack', app._router.stack);
app.listen(3000);
After starting the application displays these handlers:
stack [ { keys: [], regexp: /^\/?(?=/|$)/i, handle: [Function: query] },
{ keys: [],
regexp: /^\/?(?=/|$)/i,
handle: [Function: expressInit] },
{ keys: [],
regexp: /^\/foo\/?$/i,
handle: [Function],
route: { path: '/foo', stack: [Object], methods: [Object] } },
{ keys: [],
regexp: /^\/foo\/?$/i,
handle: [Function],
route: { path: '/foo', stack: [Object], methods: [Object] } } ]
Note that there are two identical handlers for the route
/foo. It would be nice if Express would throw an error every time when one route has several handlers. Now our assumption was that delays occurred due to the constant increase in the array with handlers. Most likely, handlers were duplicated somewhere in our code. We added additional logging, which displayed an array of request handlers, and noticed that it was growing at 10 elements per hour. These handlers were identical to each other, as in the example above.
Something added 10 identical handlers for static routes per hour to the application. Further, we found that when iterating through these handlers, the cost of calling each of them takes about 1 millisecond. This correlates with what we saw before, when the response delay grew by 10 milliseconds per hour.
It turned out that this was caused by periodic (10 times per hour) updating of handlers in our code from an external source. We implemented this by removing old handlers and adding new ones to the array. Unfortunately, also during this operation, we always added a handler for the static route. Since Express allows you to add multiple handlers for the same route, all these duplicates were added to the array. Worst of all, they were all added before the rest, which meant that before Express found the API handler for our service, it would call the handler for the static route several times.
This fully explains why request delays grew by 10 milliseconds per hour. In fact, after we fixed the error in our code, the constant increase in the delay time and the increase in CPU usage stopped.
This graph shows that the delay time was reduced to one millisecond after updating the code.
When the smoke cleared
What experience have we got? First, we need to fully understand how dependencies work in our code before using it in production. We made the wrong assumption that the Express API works without examining its code. Misuse of the Express API is the ultimate cause of our performance issues.
Secondly, in solving performance problems, visibility is of utmost importance. Flame graphs gave us a great understanding of where our application spends the most time and CPU resources. I cannot imagine how we could solve this problem by not being able to get the node.js stacks and visualize them using flame graphs.
Wanting to improve visibility, we are migrating to Restify, which will allow us to improve control over our application 2 . This is beyond the scope of this article, so read our blog post about how we use node.js on Netflix.
Want to solve such problems with us? Our team is looking for an engineer to work with the node.js stack.
Posted by Yunun Xiao @yunongx
Notes:
- In particular, this piece of code . Note that the function
next()is called recursively to iterate over the array of handlers. - Restify provides many mechanisms for getting better visibility of our application, from DTrace support to integration with node-bunyan .
Translator Notes:
- I have nothing to do with Netflix. But I left the link to the vacancy intentionally, I will be sincerely glad if it is useful to anyone.
- The comments on the original article explain why Express does not use hash tables as a data structure for storing handlers. The reason is that the regular expression used to select the necessary handler cannot be the key in the hash table. And if you store it as a string, then you will also have to compare all the keys from the hash table (although this does not cancel the fact that when you add a second handler to the route, you could throw at least a warning).
- You can also read the detailed answer by Eran Hammer (one of the hapi contributors ) and the discussion that followed.
Comments and comments regarding the translation are welcome in private messages.
UPD : attentive readers have noticed that the translator incorrectly transcribed the name of the author of the original article. Thanks for the hints of domix32 and lany .