CERN plans to increase its computing capabilities to 150,000 cores
Paris, 1989 - the beginning of the creation of one of the greatest and most expensive creations of our time, the Large Hadron Collider. This event can undoubtedly be called a feat, but the installation, which formed an almost 27-kilometer ring, dug more than 90 meters underground at the Franco-Swiss border, is useless without huge computing power and no less huge data storage.

Such computing power for the European Organization for Nuclear Research (CERN) is supplied by an IT team of 4 cloud environments based on OpenStack open source software, which is quickly becoming the industry standard for creating the cloud. CERN currently has four OpenStack clouds located in two data centers: one in Meyran, Switzerland, and the second in Budapest, Hungary.
The largest cloud located in Meyran contains about 70,000 cores on 3,000 servers, the other three clouds contain a total of 45,000 cores. In addition, the CERN unit in Budapest will be connected to the headquarters in Geneva by two communication lines with a bandwidth of 100 Gb / s.

CERN began building its cloud environment back in 2011 with the help of Cactus (open source cloud software). Clouds saw the light with the release of the OpenStack Grizzly interface in July 2013. Today, all four clouds work on the ninth release of OpenStack platforms, called Icehouse. At the moment, CERN is preparing to activate about 2,000 additional servers, which will increase the computing power of the cloud by an order of magnitude. An increase in the collision energy of particles in the collider from 8 TeV (tera-electron-volt) to 13-14 TeV will lead to the fact that it will generate more data than it currently generates. Over the entire period of the experiments, more than 100 petabytes of data were collected, of which 27 only this year. In the first quarter of 2015, this figure will increase, according to plans, to 400 petabytes per year,

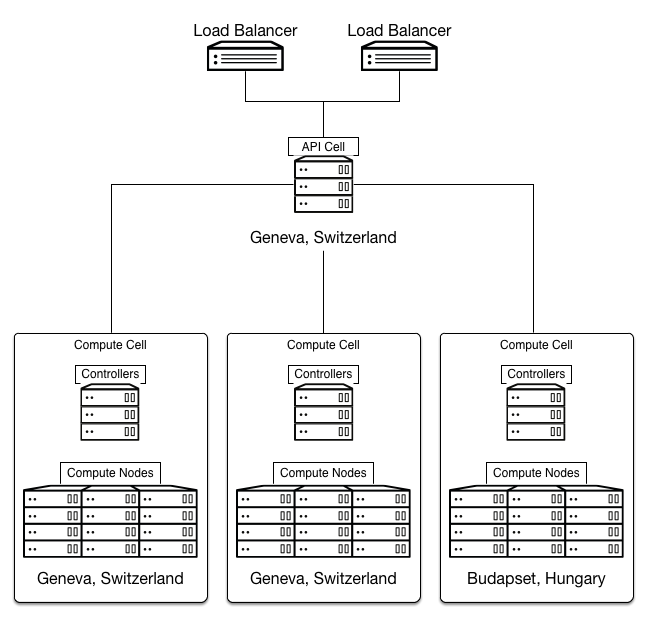
The CERN cloud architecture is a single system located in two data centers. Each data center, in Switzerland and Hungary, has clusters, compute nodes, and controllers for these clusters. Cluster controllers turn to the main controller in Switzerland, which in turn distributes the data flow between the two balancers.
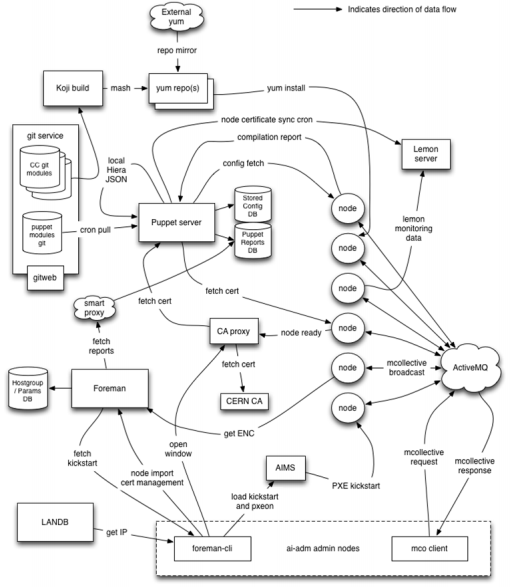
An OpenStack cloud is never created using just the components of the OpenStack suite, and the CERN cloud is no exception. Other open source components are used in conjunction with it:
The choice was between the Chef and Puppet utilities, both tools are mature, well integrated with other developments. However, Puppet's rigorous declarative approach was deemed more appropriate for this kind of work.
The current system architecture is demonstrated by the following diagram:
The OpenStack CERN environment is already quite massive, but this is not the limit. In the not so distant future, it is planned to increase at least twice that will be associated with the update of the collider itself.
According to plans, this will happen in the first quarter of 2015, since at this stage physicists no longer have the collider power to search for answers to the fundamental question of the universe.
Ps Peaceful to all elementary particles.
Such computing power for the European Organization for Nuclear Research (CERN) is supplied by an IT team of 4 cloud environments based on OpenStack open source software, which is quickly becoming the industry standard for creating the cloud. CERN currently has four OpenStack clouds located in two data centers: one in Meyran, Switzerland, and the second in Budapest, Hungary.
The largest cloud located in Meyran contains about 70,000 cores on 3,000 servers, the other three clouds contain a total of 45,000 cores. In addition, the CERN unit in Budapest will be connected to the headquarters in Geneva by two communication lines with a bandwidth of 100 Gb / s.
CERN began building its cloud environment back in 2011 with the help of Cactus (open source cloud software). Clouds saw the light with the release of the OpenStack Grizzly interface in July 2013. Today, all four clouds work on the ninth release of OpenStack platforms, called Icehouse. At the moment, CERN is preparing to activate about 2,000 additional servers, which will increase the computing power of the cloud by an order of magnitude. An increase in the collision energy of particles in the collider from 8 TeV (tera-electron-volt) to 13-14 TeV will lead to the fact that it will generate more data than it currently generates. Over the entire period of the experiments, more than 100 petabytes of data were collected, of which 27 only this year. In the first quarter of 2015, this figure will increase, according to plans, to 400 petabytes per year,
The CERN cloud architecture is a single system located in two data centers. Each data center, in Switzerland and Hungary, has clusters, compute nodes, and controllers for these clusters. Cluster controllers turn to the main controller in Switzerland, which in turn distributes the data flow between the two balancers.
An OpenStack cloud is never created using just the components of the OpenStack suite, and the CERN cloud is no exception. Other open source components are used in conjunction with it:
- Git: software version control system.
- Ceph: Distributed object storage that runs on handler servers.
- Elasticsearch: real-time distributed search and analytics system.
- Kibana: visualization engine for Elasticsearch.
- Puppet: configuration management utility.
- Foreman: a tool to configure and control server resources.
- Hadoop: A computing distribution architecture used to analyze large amounts of data on cluster servers.
- Rundeck: task scheduler.
- RDO: An OpenStack cloud deployment software package on the Linux Red Hat distribution.
- Jenkins: a continuous integration tool.
The choice was between the Chef and Puppet utilities, both tools are mature, well integrated with other developments. However, Puppet's rigorous declarative approach was deemed more appropriate for this kind of work.
The current system architecture is demonstrated by the following diagram:
The OpenStack CERN environment is already quite massive, but this is not the limit. In the not so distant future, it is planned to increase at least twice that will be associated with the update of the collider itself.
According to plans, this will happen in the first quarter of 2015, since at this stage physicists no longer have the collider power to search for answers to the fundamental question of the universe.
Ps Peaceful to all elementary particles.