About Nutanix, Web-Scale, Converged Platforms, and Paradigm Changes in Building IT Infrastructures
You may have heard a new term for the non-online project market - Web-Scale IT , which according to Gartner in 2017 will occupy at least 50% of the corporate IT market.
This year is one of the main fashion terms.
The situation in corporate markets is now actively reminiscent of the phrase about teenage sex - everyone says that they had (= they can), but really - things are sad.
Literally every vendor talks about BigData, converged solutions, prospects and more.
We, in turn, dare to hope that this is really pretty good with us , but here it is always more visible from the outside and your opinion may not coincide with ours.
Nevertheless, we will try to talk about how we are trying to change the market, which in the near future will amount to tens of billions of dollars annually and why we believe that the time for traditional solutions for storing and processing data is approaching its dusk.

The prerequisites for this hope are our story , about which we will not remember more on the blog, but will avoid unnecessary discussions about the “next pioneers of bicycle builders”.
The company was founded in Silicon Valley in 2009 by key engineers of Google (developers of Google Filesystem), Facebook, Amazon and other global projects, and since 2012 it has expanded to Europe and connects engineers from key European teams (for example, Badoo).
Named the fastest growing technology startup in the last 10 years, they have already entered the Gartner rating as visionaries (technology leaders) of the convergent solutions industry.
According to Forbes, we are the best “cloud-based” startup for work in the world.
Yes, we have engineers in Russia, and there will be much more. We are growing.
Actually, in our DNA there are the world's largest Internet projects, with the main idea - to work always and for any scale / volume of data.
We are based on open-source components brought to mind with the help of a large file - Cassandra for storing file system metadata (with the maneuver of circumventing the CAP theorem on the principle of “smart one won’t go uphill” and refinement to the CA side),Apache Zookeper for storing cluster configurations, Centos Linux, and the EXT4 file system.
Active use of BigData technologies inside (for real, not marketing).
In general, we can .
Remarque - a request to understand and not make much noise, if the terms seem poorly translated - dictionaries have not yet been published on this topic, many concepts have already been established (although they are unambiguous Anglicisms). We are always happy if you suggest a more adequate terminology - in the end, we plan to write many interesting articles.
The article is accompanied by illustrations (of how Nutanix works), and a detailed technical description will be in subsequent articles (you don’t want to read the article all night?)
So, let's go!(c) Gagarin .
...
To begin with, it’s worth trying to generally decide what is meant by such an odious term, and preferably without marketing idle talk.

In a simplified sense, the native association of two or more different components (network, virtualization, etc.) into one unit.
Nativeness is the key word in this case, because we are not just talking about packing various components in a single package, but we mean full and initial integration.
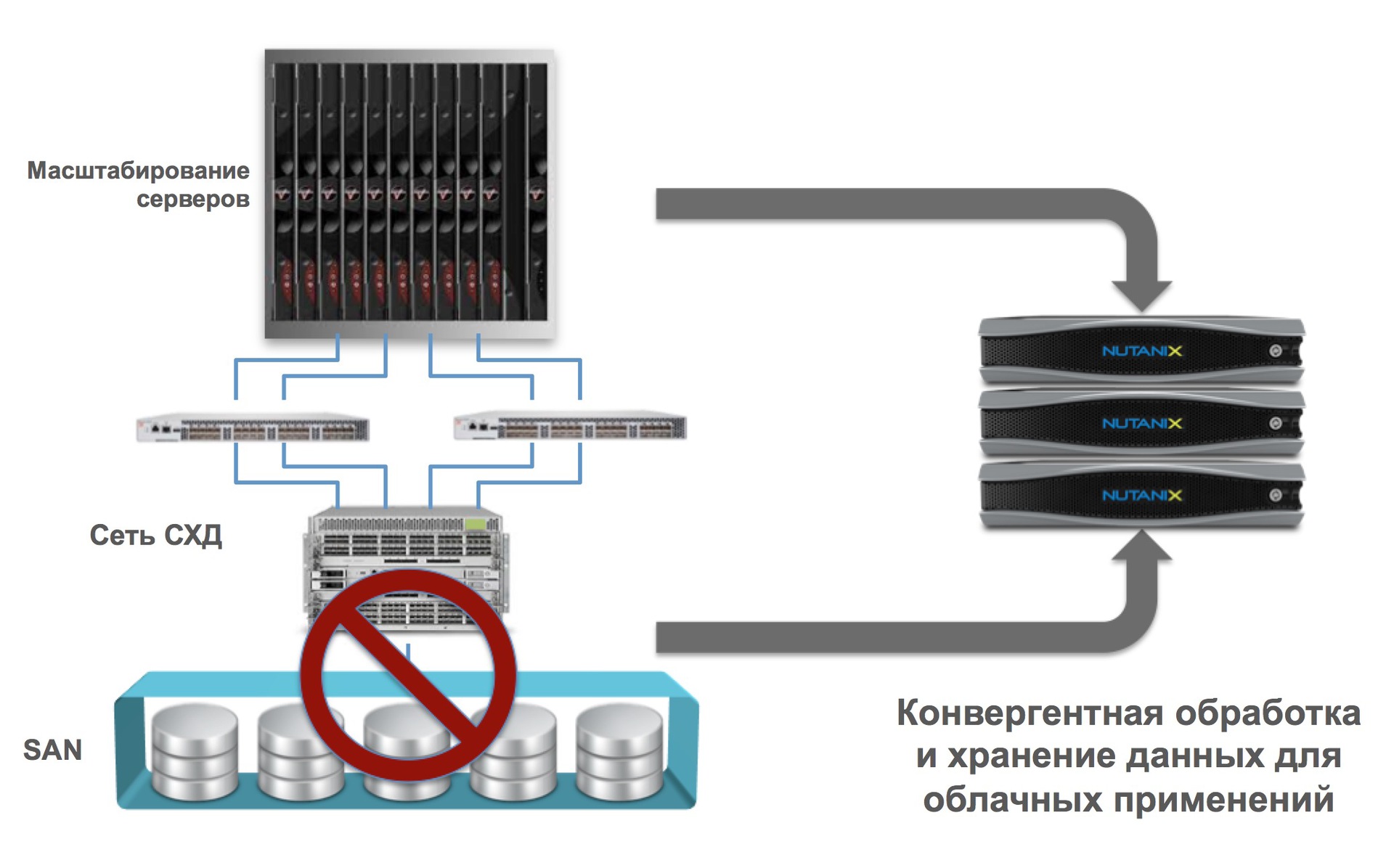
In the case of Nutanix, we are talking about the fact that our platform combines computing and data storage. Other companies may, for example, say (and this will also be hyper-convergent) that they combine storage systems (data storage system) with a network, or many other options.
Native integration of two or more components in the case of Web-scale gives linear (horizontal) scaling without any limits.
As a result, we get significant advantages:
Transferring all logic from (extremely complex) propietal equipment (special processors, ASIC / FPGA) to 100% software implementation.
As an example, in Nutanix we perform any (and often unique - such as deduplication of the RAM cache, distributed map / reduce, delayed data deduplication on the cluster, etc.) operations programmatically.
Many will ask - should this wildly “slow down”? No way.
Modern Intel processors can do a lot, and very quickly.
As an example, instead of using hardware specials. adapters for compression and deduplication (as some archaic vendors do) - we just use the Intel processor hardware instructions to calculate the sha1 checksums.
Data compression (delayed and on the fly)?
Easy, free snappy algorithm used by Google.
Data backup?
RAID is an outdated and dead technology (which many vendors are trying to make powerful facelift, with horse doses of Botox), has long been not used by large online projects. Read for example this: why RAID is dead for big data .
In short, the RAID problem is not only its speed, but the recovery time after hardware failures (disks, shelves, controllers). For example, in the case of Nutanix, after a 4TB hard drive fails, restoring system integrity (the number of data replicas) for 32 nodes in a cluster under heavy load takes only 28 minutes.
How long will a large array be rebuilt (say hundreds of terabytes) and RAID 6 - we think you yourself are in the know (for many hours, sometimes a day).
Considering that 10TB helium disks are already ready , very difficult times are beginning for traditional storage systems.

In fact, "everything ingenious is simple." Instead of using complex and slow RAID systems, the data should be divided into blocks (the so-called extent groups in our case) and simply “spread out” across the cluster with the required number of copies, and in peer to peer mode (in the Russian-speaking space, the example of torrents is immediately clear to everyone) .
By the way, this leads to a new term for many (but not for the market) - RAIN ( R edundant / Reliable Aof Inexpensive rray / I ndependent N odes) - redundant / reliable array of inexpensive / independent nodes.
A striking representative of this architecture is Nutanix.
Sounds complicated? We shorten: we take out all the logic of work from iron to a purely software implementation on standard X86-64 hardware.
Exactly the same as does Google / Facebook / Amazon and others.
What are the benefits?
The idea is simple and lies on the surface - we are moving away from the concept of dedicated control systems (controllers, central metadata nodes, the human brain, etc.) to the concept of uniform distribution of identical roles between many elements (each node is its own controller, there are no selected elements, swarm of bees).
Paraphrasing is a purely distributed system.
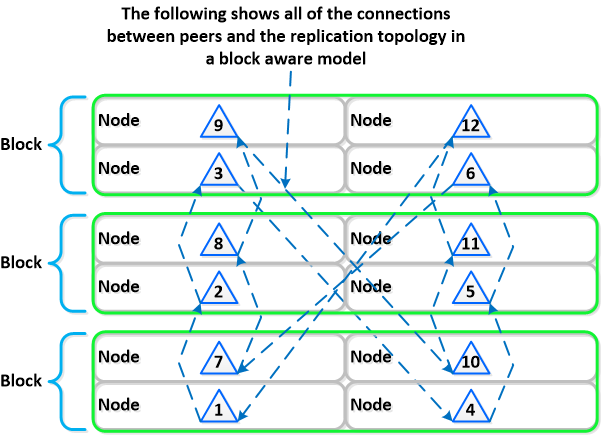
Traditional manufacturers always assume that equipment must be reliable, which in general is generally possible (but at what cost?).
Meanwhile, as for distributed systems, the approach is fundamentally different - it is always assumed that any equipment will eventually fail and the processing of this situation should be fully automatic, without affecting the viability of the system.
We are talking about "self-healing" systems, and the cure should occur as quickly as possible.

If the control logic requires coordination (the so-called "master" nodes), then the choice of these should be fully automatic and any member of the cluster can become such a master.
What does all this mean in reality?
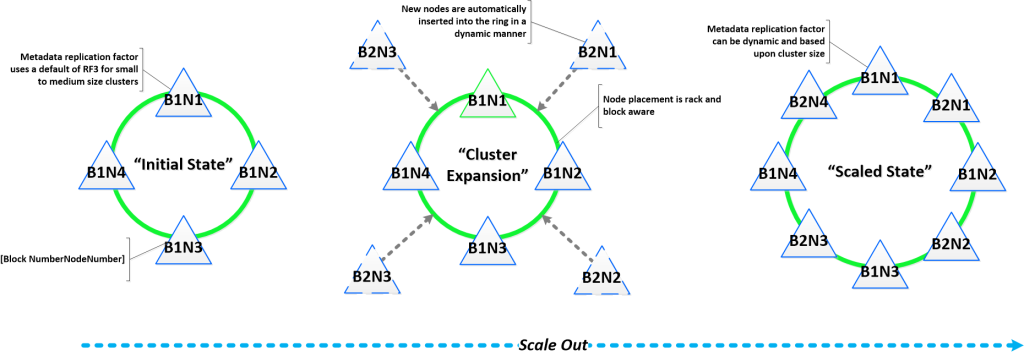
Sequential and linear (horizontal) expansion means the ability to start from a certain amount of resources (in our case, 3 nodes / node / server) and scale linearly to obtain a linear performance gain. All the points that we discussed above are critical to this opportunity.
As an example, usually you have a three-tier architecture (server, storage, network), each element of which is scaled independently. If you increase the number of servers, then the storage and network are still old.
With a hyper-converged platform like Nutanix, when you add each node, you get an increase:
Difficult? Simplify:
Benefits:
...

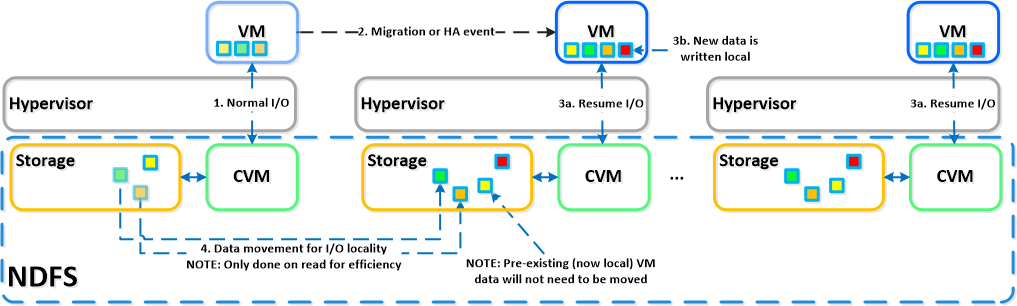
In the following articles we will give more technical details and tell you, for starters, how our NDFS works - a new generation distributed file system built on ext4 + NoSQL.
Of the additional announcements - our KVM management system , which works on the same principles, is unlimitedly scalable and has no points of failure.
We will speak at Highload 2014 , show our solutions “live”. Come.
Have a nice day!
ps yes, yes, we will definitely tell you what we chose from CAP and how we solved the issue of Convergence-Accessibility-Partitioning
pps (if someone read up to this place) for those who are attentive - a competition, guess the name of our solution for managing KVM and get a prize ( in Moscow).
This year is one of the main fashion terms.
The situation in corporate markets is now actively reminiscent of the phrase about teenage sex - everyone says that they had (= they can), but really - things are sad.
Literally every vendor talks about BigData, converged solutions, prospects and more.
We, in turn, dare to hope that this is really pretty good with us , but here it is always more visible from the outside and your opinion may not coincide with ours.
Nevertheless, we will try to talk about how we are trying to change the market, which in the near future will amount to tens of billions of dollars annually and why we believe that the time for traditional solutions for storing and processing data is approaching its dusk.
The prerequisites for this hope are our story , about which we will not remember more on the blog, but will avoid unnecessary discussions about the “next pioneers of bicycle builders”.
The company was founded in Silicon Valley in 2009 by key engineers of Google (developers of Google Filesystem), Facebook, Amazon and other global projects, and since 2012 it has expanded to Europe and connects engineers from key European teams (for example, Badoo).
Named the fastest growing technology startup in the last 10 years, they have already entered the Gartner rating as visionaries (technology leaders) of the convergent solutions industry.
According to Forbes, we are the best “cloud-based” startup for work in the world.
Yes, we have engineers in Russia, and there will be much more. We are growing.
Actually, in our DNA there are the world's largest Internet projects, with the main idea - to work always and for any scale / volume of data.
We are based on open-source components brought to mind with the help of a large file - Cassandra for storing file system metadata (with the maneuver of circumventing the CAP theorem on the principle of “smart one won’t go uphill” and refinement to the CA side),Apache Zookeper for storing cluster configurations, Centos Linux, and the EXT4 file system.
Active use of BigData technologies inside (for real, not marketing).
In general, we can .
Remarque - a request to understand and not make much noise, if the terms seem poorly translated - dictionaries have not yet been published on this topic, many concepts have already been established (although they are unambiguous Anglicisms). We are always happy if you suggest a more adequate terminology - in the end, we plan to write many interesting articles.
The article is accompanied by illustrations (of how Nutanix works), and a detailed technical description will be in subsequent articles (you don’t want to read the article all night?)
So, let's go!(c) Gagarin .
...
Web scale
To begin with, it’s worth trying to generally decide what is meant by such an odious term, and preferably without marketing idle talk.
Basic principles:
Hyper convergence
Purely software implementation (Software Defined)
Distributed and fully self-contained systems
Linear expansion with very fine granularity
Additionally:
Powerful automation and analytics with API
Self-healing after equipment and data center failures (disaster tolerance).
Reveal the meaning?
Hyper convergence
In a simplified sense, the native association of two or more different components (network, virtualization, etc.) into one unit.
Nativeness is the key word in this case, because we are not just talking about packing various components in a single package, but we mean full and initial integration.
In the case of Nutanix, we are talking about the fact that our platform combines computing and data storage. Other companies may, for example, say (and this will also be hyper-convergent) that they combine storage systems (data storage system) with a network, or many other options.
Native integration of two or more components in the case of Web-scale gives linear (horizontal) scaling without any limits.
As a result, we get significant advantages:
- Scaling by one solution unit (like Lego cubes)
- Localization of input-output (extremely important for massive acceleration of I / O operations)
- Elimination of traditional storage systems as rudimentary, with integration into a single solution (no storage - no problems associated with it)
- Support for all major virtualization technologies on the market, including open-source (ESXi, HyperV, KVM).
Purely software implementation
Transferring all logic from (extremely complex) propietal equipment (special processors, ASIC / FPGA) to 100% software implementation.
As an example, in Nutanix we perform any (and often unique - such as deduplication of the RAM cache, distributed map / reduce, delayed data deduplication on the cluster, etc.) operations programmatically.
Many will ask - should this wildly “slow down”? No way.
Modern Intel processors can do a lot, and very quickly.
As an example, instead of using hardware specials. adapters for compression and deduplication (as some archaic vendors do) - we just use the Intel processor hardware instructions to calculate the sha1 checksums.
Data compression (delayed and on the fly)?
Easy, free snappy algorithm used by Google.
Data backup?
RAID is an outdated and dead technology (which many vendors are trying to make powerful facelift, with horse doses of Botox), has long been not used by large online projects. Read for example this: why RAID is dead for big data .
In short, the RAID problem is not only its speed, but the recovery time after hardware failures (disks, shelves, controllers). For example, in the case of Nutanix, after a 4TB hard drive fails, restoring system integrity (the number of data replicas) for 32 nodes in a cluster under heavy load takes only 28 minutes.
How long will a large array be rebuilt (say hundreds of terabytes) and RAID 6 - we think you yourself are in the know (for many hours, sometimes a day).
Considering that 10TB helium disks are already ready , very difficult times are beginning for traditional storage systems.
In fact, "everything ingenious is simple." Instead of using complex and slow RAID systems, the data should be divided into blocks (the so-called extent groups in our case) and simply “spread out” across the cluster with the required number of copies, and in peer to peer mode (in the Russian-speaking space, the example of torrents is immediately clear to everyone) .
By the way, this leads to a new term for many (but not for the market) - RAIN ( R edundant / Reliable Aof Inexpensive rray / I ndependent N odes) - redundant / reliable array of inexpensive / independent nodes.
A striking representative of this architecture is Nutanix.
Sounds complicated? We shorten: we take out all the logic of work from iron to a purely software implementation on standard X86-64 hardware.
Exactly the same as does Google / Facebook / Amazon and others.
What are the benefits?
- Fast (very fast) development and update cycle
- Linking dependencies to propietary equipment
- Using standard (“consumer goods”) equipment to solve problems of any scale.
Distributed and fully self-contained systems
The idea is simple and lies on the surface - we are moving away from the concept of dedicated control systems (controllers, central metadata nodes, the human brain, etc.) to the concept of uniform distribution of identical roles between many elements (each node is its own controller, there are no selected elements, swarm of bees).
Paraphrasing is a purely distributed system.
Traditional manufacturers always assume that equipment must be reliable, which in general is generally possible (but at what cost?).
Meanwhile, as for distributed systems, the approach is fundamentally different - it is always assumed that any equipment will eventually fail and the processing of this situation should be fully automatic, without affecting the viability of the system.
We are talking about "self-healing" systems, and the cure should occur as quickly as possible.
If the control logic requires coordination (the so-called "master" nodes), then the choice of these should be fully automatic and any member of the cluster can become such a master.
What does all this mean in reality?
- The distribution of roles and responsibilities within the system (cluster)
- Using BigData principles (such as MapReduce) to distribute tasks
- The process of "public election" to designate the current master
Linear expansion with very fine granularity
Sequential and linear (horizontal) expansion means the ability to start from a certain amount of resources (in our case, 3 nodes / node / server) and scale linearly to obtain a linear performance gain. All the points that we discussed above are critical to this opportunity.
As an example, usually you have a three-tier architecture (server, storage, network), each element of which is scaled independently. If you increase the number of servers, then the storage and network are still old.
With a hyper-converged platform like Nutanix, when you add each node, you get an increase:
- Number of Hypervisors / Computing Nodes
- The number of storage controllers (3 nodes = 3 controllers, 300 nodes = 300 controllers, etc.)
- CPU power and storage capacity
- The number of nodes involved in solving cluster problems
Difficult? Simplify:
- The ability to scale the server and storage on a single micro-node with a corresponding linear increase in performance, starting from 3 to infinity.
Benefits:
- Ability to start with a minimum size
- Elimination of any “bottlenecks” and points of failure (yes, SLA is 100% real)
- Consistent and guaranteed performance while expanding.
...
In the following articles we will give more technical details and tell you, for starters, how our NDFS works - a new generation distributed file system built on ext4 + NoSQL.
Of the additional announcements - our KVM management system , which works on the same principles, is unlimitedly scalable and has no points of failure.
We will speak at Highload 2014 , show our solutions “live”. Come.
Have a nice day!
ps yes, yes, we will definitely tell you what we chose from CAP and how we solved the issue of Convergence-Accessibility-Partitioning
pps (if someone read up to this place) for those who are attentive - a competition, guess the name of our solution for managing KVM and get a prize ( in Moscow).