Superfluous elements or how we balance between servers
Hello, Habr! Some time ago, people realized that it is simply impossible to increase the power of the server in accordance with the increase in load. Then we learned the word "cluster". But no matter how beautiful this word may sound, you still have to technically combine disparate servers into a single whole - that same cluster. In cities and villages we reached our nodes in my previous opus. And today my story will be about how system integrators share the load between cluster members, and how we did it.
Inside the publication, you will also receive a bonus in the form of three certificates for a monthly ivi + subscription .

What are the challenges for the cluster?
1. A lot of traffic
2. High reliability
03d63a0996fb
How to achieve this? The easiest way to share the load between servers is to not share it. Or rather: let’s give a complete list of servers - let the clients themselves understand. How? Yes, just by registering all the IP addresses of the servers in DNS for the given name. Ancient and famous round-robin DNS balancing . And in general, it works pretty well until there is a need to add a host - I already wrote about the inertness of DNS caches. DNS balancing looks like this:
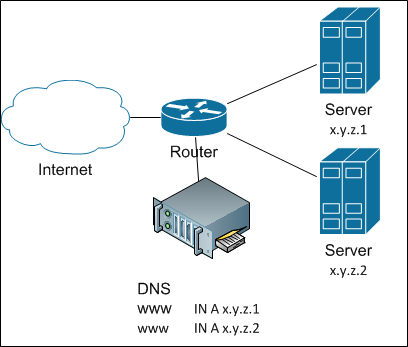
And if you need to remove the server from the cluster (well, it broke), the kayuk comes. To prevent the kayak from stepping on us, we need to quickly hang up the IP of a broken server somewhere. Where to? Well, let's say a neighbor. Okay, how can we automate this? For this, a bunch of protocols have been invented like VRRP , CARP with their own advantages and disadvantages.
The first thing that usually rests on is the ARP cache on the router, which does not want to understand that the IP address has moved to another MAC. However, modern implementations either “ping” the router from the new MAC (updating the cache in this way), or even use the virtual MAC, which does not change during operation.
The second thing that hits the head is server resources. We will not keep one server out of two in a hot standby? The server should work! Therefore, we will reserve two addresses on each server via VRRP: one - primary and one backup. If one of the pair’s servers breaks down, the second will take on all its load ... maybe ... if it does. And such “pairing” will be the main drawback, because it is not always possible or advisable to keep a double supply of server power.
Also, one cannot fail to notice that each server requires its own, globally routable IP address. In our difficult times, this can be a big problem.
In general, I rather do not like this method of balancing and reservation, but it is good for a number of tasks and volumes of traffic. Simple It does not require additional equipment - everything is done by server software.
Continuing with the enumeration of simple solutions, or maybe you just need to hang the same IP address on several servers? Well, in IPv6 there is the possibility of making anycast in one domain (and then balancing there will only be for hosts inside it, but for external hosts it will not be at all), but in IPv4 such a thing will simply create an ARP conflict (better known as address conflict) . But this is if "on the forehead."
And if you use a small twist under the code name “shared address” (shared address), then this is possible. The gist of the trick is to first turn the incoming uniqueness into a Broadcast (okay, if anyone wants to, let them make a multicast), and then only one of the servers responds to packets from this client. How is the transformation carried out? Very simple: all cluster servers in response to an ARP request return the same MAC: either non-existent on the network or multicast. After that, the network itself will multiply incoming packets by all members of the cluster. And how do the servers agree on who is responsible? For simplicity, let's say this: the remainder of dividing srcIP by the number of servers in the cluster. Next is a matter of technology.
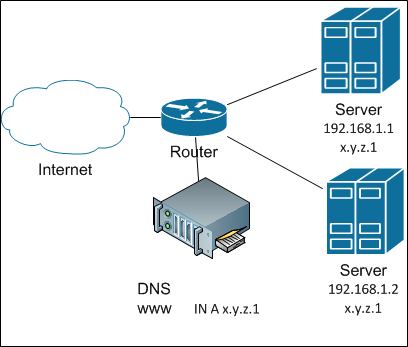
Balancing with a shared address
This technique is implemented by different modules and different protocols. For FreeBSD, this feature is implemented in CARP . For Linux in a past life, I used to use ClusterIP . Now, apparently, it is not developing. But I'm sure there are other implementations. For Windows, such a thing is in the built-in clustering tools. In general, there is a choice.
The advantage of such balancing is still a purely server implementation: no special configuration from the network side is required. There is only one public address. Adding or disconnecting a single server in a cluster is quick.
The drawbacks are, firstly, that there is a need for additional verification at the application level, and secondly (and even “in the main”) there is a restriction on the incoming band: the amount of incoming traffic cannot exceed the band in the physical connection of the servers. And this is obvious: after all, incoming traffic goes to all servers simultaneously.
So in general, this is a good way to balance traffic if you have a bit of incoming traffic, but you should use it wisely. And here I will modestly say that now we do not use this method. Just because of the problem of incoming traffic.
For some reason, it seems to me that the task of balancing between servers should be typical. And for a typical problem there should be standard solutions. And who sells typical solutions well? Integrators! And we asked ...
Do I need to say that we were offered solutions from the wagons of a wide variety of equipment? From Cisco ACE to all sorts of F5 BigIP LTM . Expensive. But is it good? Well, there is an excellent free a soft-L7-balancer haproxy .
What is the meaning of these things? The point is that they do the balancing at the application level - Layer 7. In fact, such balancers are full proxies: they establish a connection with the client and the server on their behalf. In theory, this is good because they can stick the client to a specific server (server affinity) and even choose a backend depending on the requested content (an extremely useful thing for a resource like ivi.ru ). And with a certain setting - and filter requests by URL, protecting yourself from various kinds of attacks. The main advantage is that such balancers can determine the viability of each node in the cluster independently.
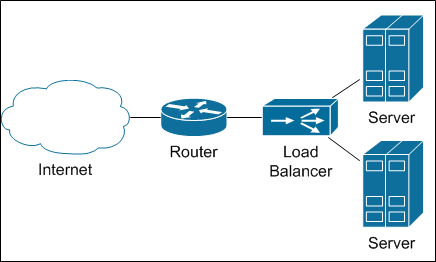
Balancers are connected to the network something like this
I admit, my past experience shouted "Without balancers, nothing can be done." We counted ... And were horrified.
The most productive balancers that we were offered had a bandwidth of 10 Gbit / s. By our standards, it’s not funny (servers with heavy content connect 2 * 10 Gbit / s). Accordingly, in order to get the right lane, it would be necessary to fill the whole rack with such balancers, taking into account the reservation. Take a look at this diagram:
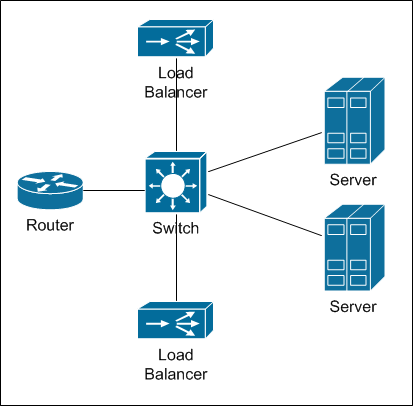
This is the physical connection of the balancer.
Of course, there is also a partial proxy mode (half-proxy), when only half of the traffic passes through the balancer: from the client to the server, and back from the server - it goes directly. But this mode disables L7 functionality, and the balancer becomes L3-L4, which dramatically reduces its value. And then two problems subsequently arise: first you need to make enough network power (first of all, by ports, then - by reliability). Then the question arises: how to balance the load between balancers? In Moscow, to put up a rack with equipment for balancing, in theory, probably, you can. But in regions where our nodes are minimalistic (servers and a tsiska), adding a few balancers is already somehow not funny. In addition, the longer the chain, the lower the reliability. Do we need it?
The solution was googled almost by accident. It turns out that a modern router itself can balance traffic. If you think about it, this is reasonable: after all, the same subnet can be accessed through different channels with the same quality. This feature is called ECMP - Equal Cost Multiple Paths. Seeing the routes identical in their metrics (in the general sense of the word), the router simply divides the packets between these routes.
OK, the idea is interesting, but will it work? We carried out a test launch, registering static routes from the router to the side of several servers. The concept turned out to be workable, but additional work was required.
At first, you must ensure that all IP packets belonging to the same TCP session get to the same server. Indeed, otherwise the TCP session simply will not take place. This is the so-called "per-flow" (or "per-destination") mode, and it seems to be turned on by default on Cisco routers.
Secondly , static routes are not suitable - because we need to be able to automatically remove the broken server from the cluster. Those. You must use some kind of dynamic routing protocol. For consistency, we chose BGP . A software router is installed on the servers (now it is quagga , but in the near future we will switch to BIRD), which announces the "server" network on the router. As soon as the server stops sending announcements, the router stops distributing traffic. Accordingly, for balancing on the router, a value is set
But BGP itself guarantees only the network availability of the server, but not the application. To check the functionality of application software, a script is launched on the server that performs a series of checks, and if something went wrong, it simply extinguishes BGP. Then the router’s business is to stop sending packets to this server.
Thirdly, heterogeneity of distribution of requests between servers was noticed. Small, and compensated by our clustering software, But I wanted some uniformity. It turned out that by default the router balances packets based on the addresses of the sender and receiver of the packet, that is, L3-balancing. Based on the fact that the recipient (server) address is always the same, this indicates heterogeneity in the source addresses. Given the massive NATization of the Internet, this is not surprising. The solution turned out to be simple - to force the router to take into account the receiver and source ports (L4-balancing) using a command like
or
depending on iOS. The main thing is that you do not have such a command:
The final diagram looks like this:
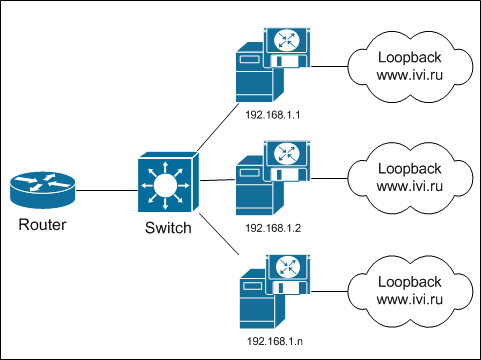
Did you notice anything familiar? Well there, that it’s actually anycast, not only between regions, but inside one node? So this is it!
The advantages of L3-L4 balancing include efficiency: a router should be, without it, nothing. Reliability is also up to the mark - if the router suddenly breaks, then it doesn’t matter any further. Additional equipment is not purchased - this is good. Public addresses are also not consumed - the same IP is served by several servers at once.
Alas, there are disadvantages.
1. You have to install additional software on the server, configure it, etc. True, this software is quite modest, and does not consume server resources. So - bearable.
2.Transients of one server (inclusion in a cluster or exclusion) affect the entire cluster. After all, the router does not know anything about servers - it thinks that it is dealing with routers and channels. Accordingly, all connections are distributed on all available channels. No server-affinity. As a result, when you turn off the server, all connections are shuffled between all remaining servers. And all active TCP sessions break (strictly speaking - not all, there is a chance that some will return to the same server). This is bad, but given our protection from such situations (the player re-requests the content when the connection is broken) and some feints with my ears (which I will talk about later), you can live.
3.There are restrictions on how many equal routes the router can share traffic: on cisco 3750X and 4500-X it is 8, on 6500 + Sup2T it is 32 (but there is one joke). In general, this is enough, in addition there are tricks that allow you to unwind this limitation.
4. With this scheme, the load on all servers is distributed evenly, which imposes the requirement of uniformity on all servers. And if you add a more modern, powerful server to the cluster, the load on it will be no more than on the neighbor. Fortunately, our clustering software eliminates this problem to a large extent. In addition, the routers still have the unequal cost multiple paths function , which we have not yet used.
5.Typical BGP timeouts can lead to situations where the server is no longer available, and the balancing router still distributes the load on it. But the BFD will help us with this . Read more about the protocol - read wikipedia. Actually, it was because of BFD that we decided to switch to BIRD.
The exclusion of balancers from the traffic flow chain allowed us to save on equipment, increase the reliability of the system and maintain the minimalism of our regional nodes. We had to apply several tricks to compensate for the shortcomings of such a balancing scheme (I hope I will still have a chance to talk about these tricks). But there is still an extra element in the existing circuit. And I really hope to remove it this year and tell us how we did it.
By the way, while I was writing (more precisely, a draft lay out) this article, colleagues on Habré wrote a very good article about balancing algorithms . I recommend reading it!
PS Certificates are one-time, so "whoever got up first, he and thePOS got into the shower."
Our previous publications:
» Blowfish on guard ivi
» Non-personalized recommendations: association method
» By city and by weight or how we balance between CDN nodes
» I am Groot. We do our analytics on events
» All for one or how we built CDN
Do as everyone
What are the challenges for the cluster?
1. A lot of traffic
2. High reliability
03d63a0996fb
How to achieve this? The easiest way to share the load between servers is to not share it. Or rather: let’s give a complete list of servers - let the clients themselves understand. How? Yes, just by registering all the IP addresses of the servers in DNS for the given name. Ancient and famous round-robin DNS balancing . And in general, it works pretty well until there is a need to add a host - I already wrote about the inertness of DNS caches. DNS balancing looks like this:
And if you need to remove the server from the cluster (well, it broke), the kayuk comes. To prevent the kayak from stepping on us, we need to quickly hang up the IP of a broken server somewhere. Where to? Well, let's say a neighbor. Okay, how can we automate this? For this, a bunch of protocols have been invented like VRRP , CARP with their own advantages and disadvantages.
The first thing that usually rests on is the ARP cache on the router, which does not want to understand that the IP address has moved to another MAC. However, modern implementations either “ping” the router from the new MAC (updating the cache in this way), or even use the virtual MAC, which does not change during operation.
The second thing that hits the head is server resources. We will not keep one server out of two in a hot standby? The server should work! Therefore, we will reserve two addresses on each server via VRRP: one - primary and one backup. If one of the pair’s servers breaks down, the second will take on all its load ... maybe ... if it does. And such “pairing” will be the main drawback, because it is not always possible or advisable to keep a double supply of server power.
Also, one cannot fail to notice that each server requires its own, globally routable IP address. In our difficult times, this can be a big problem.
In general, I rather do not like this method of balancing and reservation, but it is good for a number of tasks and volumes of traffic. Simple It does not require additional equipment - everything is done by server software.
On the ball
Continuing with the enumeration of simple solutions, or maybe you just need to hang the same IP address on several servers? Well, in IPv6 there is the possibility of making anycast in one domain (and then balancing there will only be for hosts inside it, but for external hosts it will not be at all), but in IPv4 such a thing will simply create an ARP conflict (better known as address conflict) . But this is if "on the forehead."
And if you use a small twist under the code name “shared address” (shared address), then this is possible. The gist of the trick is to first turn the incoming uniqueness into a Broadcast (okay, if anyone wants to, let them make a multicast), and then only one of the servers responds to packets from this client. How is the transformation carried out? Very simple: all cluster servers in response to an ARP request return the same MAC: either non-existent on the network or multicast. After that, the network itself will multiply incoming packets by all members of the cluster. And how do the servers agree on who is responsible? For simplicity, let's say this: the remainder of dividing srcIP by the number of servers in the cluster. Next is a matter of technology.
Balancing with a shared address
This technique is implemented by different modules and different protocols. For FreeBSD, this feature is implemented in CARP . For Linux in a past life, I used to use ClusterIP . Now, apparently, it is not developing. But I'm sure there are other implementations. For Windows, such a thing is in the built-in clustering tools. In general, there is a choice.
The advantage of such balancing is still a purely server implementation: no special configuration from the network side is required. There is only one public address. Adding or disconnecting a single server in a cluster is quick.
The drawbacks are, firstly, that there is a need for additional verification at the application level, and secondly (and even “in the main”) there is a restriction on the incoming band: the amount of incoming traffic cannot exceed the band in the physical connection of the servers. And this is obvious: after all, incoming traffic goes to all servers simultaneously.
So in general, this is a good way to balance traffic if you have a bit of incoming traffic, but you should use it wisely. And here I will modestly say that now we do not use this method. Just because of the problem of incoming traffic.
Never speak with integrators
For some reason, it seems to me that the task of balancing between servers should be typical. And for a typical problem there should be standard solutions. And who sells typical solutions well? Integrators! And we asked ...
Do I need to say that we were offered solutions from the wagons of a wide variety of equipment? From Cisco ACE to all sorts of F5 BigIP LTM . Expensive. But is it good? Well, there is an excellent free a soft-L7-balancer haproxy .
What is the meaning of these things? The point is that they do the balancing at the application level - Layer 7. In fact, such balancers are full proxies: they establish a connection with the client and the server on their behalf. In theory, this is good because they can stick the client to a specific server (server affinity) and even choose a backend depending on the requested content (an extremely useful thing for a resource like ivi.ru ). And with a certain setting - and filter requests by URL, protecting yourself from various kinds of attacks. The main advantage is that such balancers can determine the viability of each node in the cluster independently.
Balancers are connected to the network something like this
I admit, my past experience shouted "Without balancers, nothing can be done." We counted ... And were horrified.
The most productive balancers that we were offered had a bandwidth of 10 Gbit / s. By our standards, it’s not funny (servers with heavy content connect 2 * 10 Gbit / s). Accordingly, in order to get the right lane, it would be necessary to fill the whole rack with such balancers, taking into account the reservation. Take a look at this diagram:
This is the physical connection of the balancer.
Of course, there is also a partial proxy mode (half-proxy), when only half of the traffic passes through the balancer: from the client to the server, and back from the server - it goes directly. But this mode disables L7 functionality, and the balancer becomes L3-L4, which dramatically reduces its value. And then two problems subsequently arise: first you need to make enough network power (first of all, by ports, then - by reliability). Then the question arises: how to balance the load between balancers? In Moscow, to put up a rack with equipment for balancing, in theory, probably, you can. But in regions where our nodes are minimalistic (servers and a tsiska), adding a few balancers is already somehow not funny. In addition, the longer the chain, the lower the reliability. Do we need it?
ECMP or nothing more
The solution was googled almost by accident. It turns out that a modern router itself can balance traffic. If you think about it, this is reasonable: after all, the same subnet can be accessed through different channels with the same quality. This feature is called ECMP - Equal Cost Multiple Paths. Seeing the routes identical in their metrics (in the general sense of the word), the router simply divides the packets between these routes.
OK, the idea is interesting, but will it work? We carried out a test launch, registering static routes from the router to the side of several servers. The concept turned out to be workable, but additional work was required.
At first, you must ensure that all IP packets belonging to the same TCP session get to the same server. Indeed, otherwise the TCP session simply will not take place. This is the so-called "per-flow" (or "per-destination") mode, and it seems to be turned on by default on Cisco routers.
Secondly , static routes are not suitable - because we need to be able to automatically remove the broken server from the cluster. Those. You must use some kind of dynamic routing protocol. For consistency, we chose BGP . A software router is installed on the servers (now it is quagga , but in the near future we will switch to BIRD), which announces the "server" network on the router. As soon as the server stops sending announcements, the router stops distributing traffic. Accordingly, for balancing on the router, a value is set
maximum-paths ibgpequal to the number of servers in the cluster (with some reservations): router bgp 57629
address-family ipv4
maximum-paths ibgp 24
But BGP itself guarantees only the network availability of the server, but not the application. To check the functionality of application software, a script is launched on the server that performs a series of checks, and if something went wrong, it simply extinguishes BGP. Then the router’s business is to stop sending packets to this server.
Thirdly, heterogeneity of distribution of requests between servers was noticed. Small, and compensated by our clustering software, But I wanted some uniformity. It turned out that by default the router balances packets based on the addresses of the sender and receiver of the packet, that is, L3-balancing. Based on the fact that the recipient (server) address is always the same, this indicates heterogeneity in the source addresses. Given the massive NATization of the Internet, this is not surprising. The solution turned out to be simple - to force the router to take into account the receiver and source ports (L4-balancing) using a command like
platform ip cef load-sharing full
or
ip cef load-sharing algorithm include-ports source destination
depending on iOS. The main thing is that you do not have such a command:
ip load-sharing per-packet
The final diagram looks like this:
Did you notice anything familiar? Well there, that it’s actually anycast, not only between regions, but inside one node? So this is it!
The advantages of L3-L4 balancing include efficiency: a router should be, without it, nothing. Reliability is also up to the mark - if the router suddenly breaks, then it doesn’t matter any further. Additional equipment is not purchased - this is good. Public addresses are also not consumed - the same IP is served by several servers at once.
Alas, there are disadvantages.
1. You have to install additional software on the server, configure it, etc. True, this software is quite modest, and does not consume server resources. So - bearable.
2.Transients of one server (inclusion in a cluster or exclusion) affect the entire cluster. After all, the router does not know anything about servers - it thinks that it is dealing with routers and channels. Accordingly, all connections are distributed on all available channels. No server-affinity. As a result, when you turn off the server, all connections are shuffled between all remaining servers. And all active TCP sessions break (strictly speaking - not all, there is a chance that some will return to the same server). This is bad, but given our protection from such situations (the player re-requests the content when the connection is broken) and some feints with my ears (which I will talk about later), you can live.
3.There are restrictions on how many equal routes the router can share traffic: on cisco 3750X and 4500-X it is 8, on 6500 + Sup2T it is 32 (but there is one joke). In general, this is enough, in addition there are tricks that allow you to unwind this limitation.
4. With this scheme, the load on all servers is distributed evenly, which imposes the requirement of uniformity on all servers. And if you add a more modern, powerful server to the cluster, the load on it will be no more than on the neighbor. Fortunately, our clustering software eliminates this problem to a large extent. In addition, the routers still have the unequal cost multiple paths function , which we have not yet used.
5.Typical BGP timeouts can lead to situations where the server is no longer available, and the balancing router still distributes the load on it. But the BFD will help us with this . Read more about the protocol - read wikipedia. Actually, it was because of BFD that we decided to switch to BIRD.
Subtotal
The exclusion of balancers from the traffic flow chain allowed us to save on equipment, increase the reliability of the system and maintain the minimalism of our regional nodes. We had to apply several tricks to compensate for the shortcomings of such a balancing scheme (I hope I will still have a chance to talk about these tricks). But there is still an extra element in the existing circuit. And I really hope to remove it this year and tell us how we did it.
By the way, while I was writing (more precisely, a draft lay out) this article, colleagues on Habré wrote a very good article about balancing algorithms . I recommend reading it!
PS Certificates are one-time, so "whoever got up first, he and the
Our previous publications:
» Blowfish on guard ivi
» Non-personalized recommendations: association method
» By city and by weight or how we balance between CDN nodes
» I am Groot. We do our analytics on events
» All for one or how we built CDN