Storage systems: how to choose ?!
 A project of any complexity, whatever one may say, is faced with the task of storing data. Different systems can be such storage: Block storage, File storage, Object storage and Key-value storage. In any sane project, before buying a storage solution, tests are carried out to check certain parameters in certain conditions. Recalling how many good projects made by the right growing hands have pierced the fact that they forgot about scalability, we decided to figure out:
A project of any complexity, whatever one may say, is faced with the task of storing data. Different systems can be such storage: Block storage, File storage, Object storage and Key-value storage. In any sane project, before buying a storage solution, tests are carried out to check certain parameters in certain conditions. Recalling how many good projects made by the right growing hands have pierced the fact that they forgot about scalability, we decided to figure out:- What characteristics of Block storage and File storage should be considered if you want the storage system to grow after it grows
- Why fault tolerance at the software level is more reliable and cheaper than at the hardware level
- How to conduct testing in order to compare "apples to apples"
- How to get an order of magnitude more / less IOPS by changing just one parameter
During testing, we used RAID systems and Parallels Cloud Storage (PStorage) distributed storage . PStorage is included with Parallels Cloud Server .
To begin with, we define the main characteristics that you need to pay attention to when choosing a storage system. They will determine the structure of the post.
- fault tolerance
- Data recovery speed
- Performance tailored to your needs.
- Data consistency
fault tolerance
The most important property of a data storage system is that the system is designed to SAVE data without any compromises, that is, to ensure maximum availability and in no case to lose even a small part of them. For some reason, very many people think about performance, price, but pay little attention to the reliability of data storage.
To ensure fault tolerance in the event of a failure, there is only one technique - redundancy. The question is at what level redundancy is applied. With some crude simplification, we can say that there are two levels: Hardware and Software.
 Hardware-level redundancy has long been established in enterprise systems. SAN / NAS boxes have double redundancy for all modules (two, or even three power supplies, a couple of “brain” boards) and store data simultaneously on several disks inside one box. Personally, I metaphorically imagine this as a very safe mug: the most reliable to keep the fluid inside, with thick walls and always with two handles in case one of them breaks.
Hardware-level redundancy has long been established in enterprise systems. SAN / NAS boxes have double redundancy for all modules (two, or even three power supplies, a couple of “brain” boards) and store data simultaneously on several disks inside one box. Personally, I metaphorically imagine this as a very safe mug: the most reliable to keep the fluid inside, with thick walls and always with two handles in case one of them breaks. Software-level redundancy is just beginning to penetrate Enterprise systems, but every year it eats away a larger and larger chunk of HW solutions. The principle is simple. Such systems do not rely on the reliability of iron. They believe that it is a priori unreliable, and solve backup tasks at the software level by creating copies (replicas) of data and storing them on physically different hardware. Continuing the analogy with cups, this is when there are several completely ordinary cups, and you poured tea into both, suddenly one will break.
Software-level redundancy is just beginning to penetrate Enterprise systems, but every year it eats away a larger and larger chunk of HW solutions. The principle is simple. Such systems do not rely on the reliability of iron. They believe that it is a priori unreliable, and solve backup tasks at the software level by creating copies (replicas) of data and storing them on physically different hardware. Continuing the analogy with cups, this is when there are several completely ordinary cups, and you poured tea into both, suddenly one will break.Thus, SW solutions do not require expensive equipment, as a rule, are more profitable, but at the same time provide exactly the same fault tolerance, although at a different level. They are also easier to optimize, for example, distribute data to different sites, perform balancing, change the level of fault tolerance, and scale linearly with the growth of the cluster.
I’ll tell you how to solve the backup issue using the example of Parallels Cloud Storage (PStorage). PStorage is not tied to any vendor of iron and is able to work on completely ordinary machines, up to desktop PCs. We do not trust the hardware, so the PStorage architecture is designed to lose any physical server as a whole (and not just a separate disk). All data in Parallels Cloud Storage is stored in multiple copies (replicas). At the same time, PStorage never stores more than one copy on a physical server / rack / room (as you wish). We recommend storing 3 copies of data in order to be protected from the simultaneous failure of two servers / racks at once.
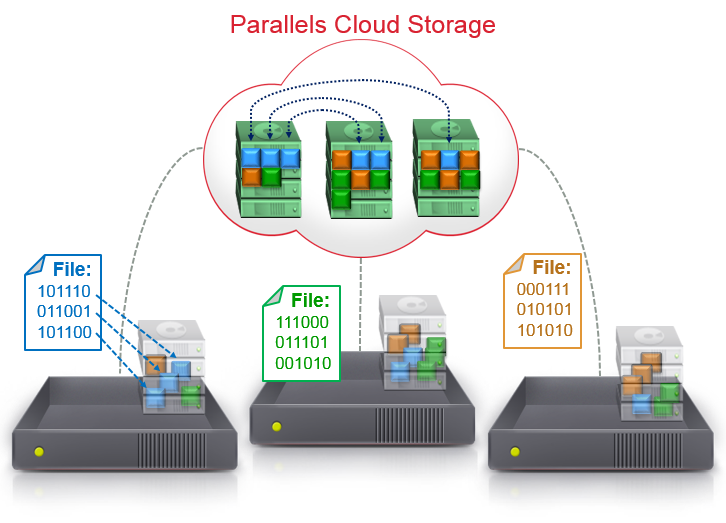
Comment: the figure shows an example of a cluster that stores data in two copies.
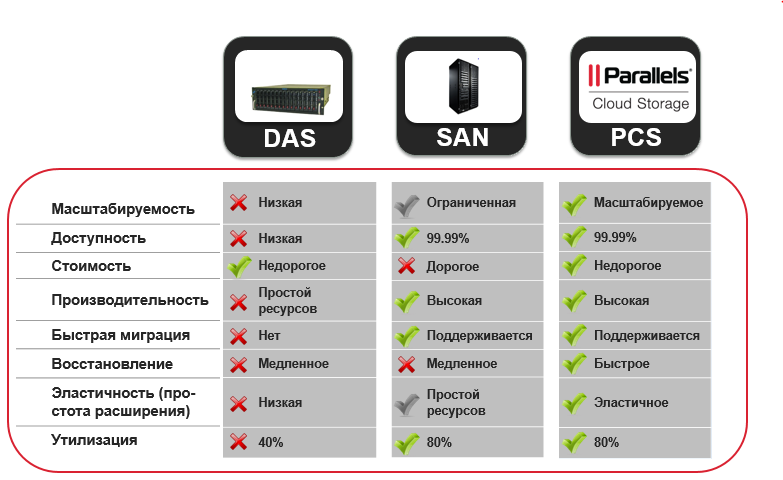
Data recovery speed
What happens if one of the drives fails?
To begin, consider the usual HW RAID1 (mirror) of two disks. In the event of a single drive falling out, the RAID continues to work with the remaining one, waiting for the moment of replacing the failed drive. Those. RAID is vulnerable at this time: the remaining disk stores a single copy of the data. One of our clients had a case when they carried out repairs and sawed metal in their data center. Shavings flew directly to running servers, and within a few hours, the disks in them began to fly out one after another. Then the system was organized on ordinary RAID, and as a result, the provider lost some of the data.
How long the system is in a vulnerable state depends on the recovery time. This dependence is described by the following formula:
MTTDL ~ = 1 / T ^ 2 * C , where T is the recovery time, and the mean time to data loss ( MTTDL ) is the average time between data loss and C is a certain coefficient.So, the faster the system recovers the required number of copies of data, the less likely it is to lose data. Here we even omit the fact that to start the HW RAID recovery process, the administrator needs to replace the dead disk with a new one, and this also takes time, especially if the disk needs to be ordered.
For RAID1, the recovery time is the time it takes for the RAID controller to transfer data from the working disk to a new one. As you might guess, the copy speed will be equal to the read / write speed of the HDD, i.e. approximately 100 MB / s, if the RAID controller is completely unloaded. And if at this time the RAID controller is loaded from the outside, then the speed will be several times lower. A thoughtful reader will perform similar calculations for RAID10, RAID5, RAID6 and come to the conclusion that any HW RAID is restored at a speed not higher than the speed of a single disk.
SAN / NAS systems almost always use the same conventional RAID approach. They group disks and collect RAID from them. Actually, the recovery speed is the same.
At the Software level, there are much more opportunities for optimization. For example, in PStorage, data is distributed across the entire cluster and across all disks in the cluster, and if one of the disks fails, replication starts automatically. There is no need to wait for the administrator to replace the disk. In addition, all cluster disks participate in replication, so the data recovery speed is much higher. We recorded data in the cluster, disconnected one server from the cluster and measured the time during which the cluster will restore the missing number of replicas. The graph shows the result for a cluster of 7/14/21 physical nodes with two 1TB SATA disks. The cluster is assembled on a 1GB network.
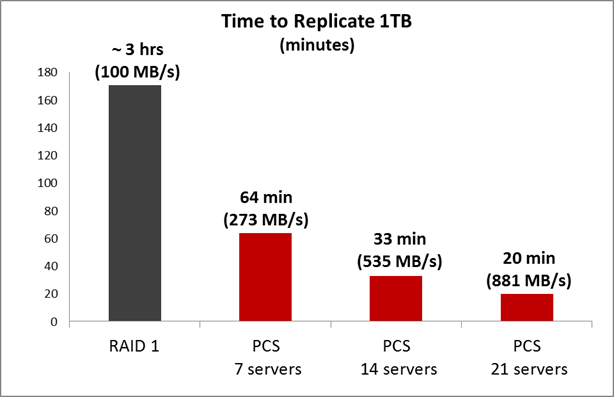
If you use a 10Gbit network, then the speed will be even higher.
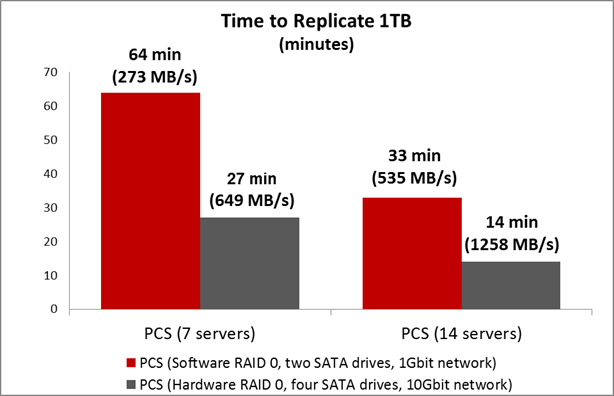
Comment: There is no error here that on a 1Gbit network, the recovery speed of a cluster of 21 servers is almost gigabytes per second. The fact is that the data stored in Parallels Cloud Storage is distributed across the cluster disks (a certain stripe on a cluster scale), so we get the ability to simultaneously copy data from different disks to different ones. That is, there is no single point of data ownership that could be the bottleneck of the test.
The full test scenario can be found in this document, if you wish, you can repeat it yourself.
How to test performance correctly - tips
Based on our experience in testing storage systems, I would highlight the basic rules:
- It is necessary to "decide on the Wishlist." What exactly do you want to get from the system and how much. Our customers in most cases use Parallels Cloud Storage to build a high-availability cluster for virtual machines and containers. That is, each of the cluster machines simultaneously provides storage and runs virtual machines. Thus, the cluster does not require a dedicated external “data storage”. In terms of performance, this means that the cluster is receiving load from each server. Therefore, in the example, we will always load the cluster in parallel from all physical servers in the cluster.
- No need to use well-compressible data patterns. Many HDDs / SSDs, storage systems, and virtual machines sometimes have special Low-level optimizations for processing zero-data. In such situations, it is easy to notice that writing zeros to disk is somewhat faster than writing random data. A typical example of such an error is the well-known test:
dd if=/dev/zero of=/dev/sda size=1Mdd if=/dev/random of=/dev/sda size=1M - Consider the distance between components spaced apart. Naturally, communication between distributed components may contain delays. It is worth remembering about this possible bottleneck under loads. Especially network latency and network bandwidth.
- Allow at least a minute to conduct the test. The test time should be long.
- Perform one test several times to smooth out deviations.
- Use a large amount of data for the load (working set). Working set is a very important parameter, as it greatly affects performance. It is he who can change the test result dozens of times. For example, with an Adaptec 71605 RAID controller, random I / O on a 512M file shows 100K iops, and on a 2GB file it shows only 3K IOPS. The difference in performance is 30 times due to the RAID cache (hit and miss hit the cache depending on the amount of load). If you are going to work with data more than the cache size of your storage system (in this example, 512M), then use exactly such volumes. For virtual machines we use 16GB.
- And of course, always compare only apples to apples. It is necessary to compare systems with the same fault tolerance on the same hardware. For example, you cannot compare RAID0 with PStorage, since PStorage provides fault tolerance when disks / servers depart, but RAID0 does not. Correctly in this case will compare RAID1 / 6/10 with PStorage.
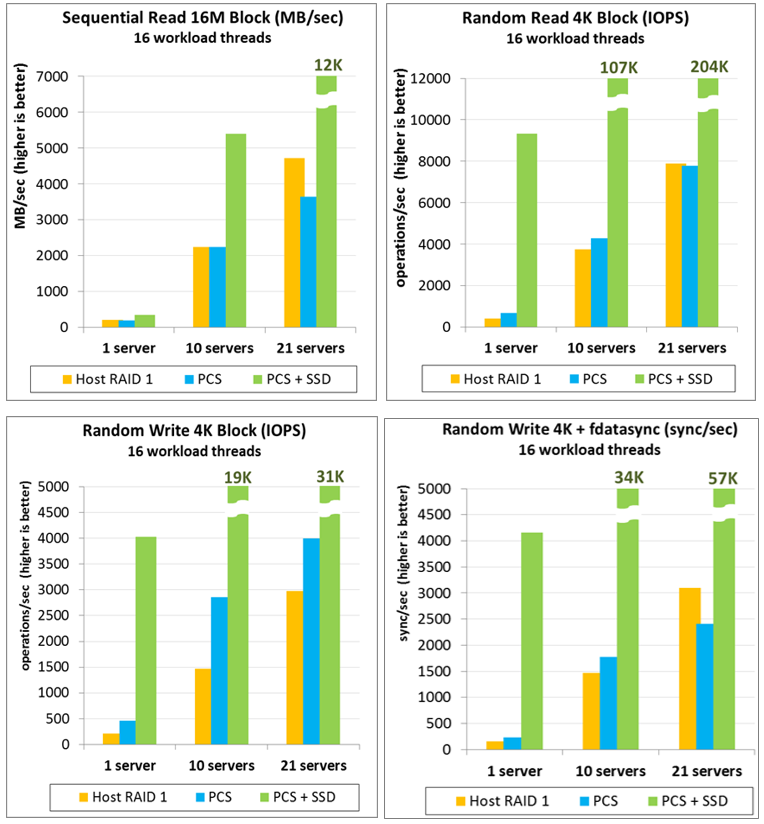
Below are the test results for the described methodology. We compare the performance of local RAID1 (“ host RAID 1 ”) with a PStorage cluster (“ PCS"). Those same "apples with apples." It should be noted that it is necessary to compare systems with the same level of redundancy. PStorage in these tests stored information in two copies (replicas = 2) instead of the recommended three so that the fault tolerance level would be the same for both systems. Otherwise, the comparison would be unfair: PStorage (replicas = 3) allows you to lose 2 of any disks / servers simultaneously, when RAID1 of 2 disks is only 1. We use the same hardware for all tests: 1,10,21 identical physical servers with two 1TB SATA drives, 1Gbit network, core i5 CPU, 16GB RAM. If the cluster consists of 21 servers, then its performance is compared with the total performance of 21 local RAID. The load was performed in 16 threads on each physical node simultaneously. Each node had a working set of 16GB, that is, for example, for the RANDOM 4K test as a whole on the cluster, the loaders accidentally walked on 336GB data. Load time - 1 minute, each test was carried out 3 times.
The “ PCS + SSD ” columns show the performance of the same cluster, but with SSD caching. PStorage has the built-in ability to use local SSDs for write-journaling, read-caching, which allows you to several times exceed the performance of local rotating disks. Also, SSDs can be used to create a separate layer (tier) with greater performance.
findings
Briefly summarized:
- Choosing the type of backup, we are inclined to the "software level". Software level provides more opportunities for optimization and allows you to reduce hardware requirements and reduce the cost of the system as a whole.
- We carry out tests on certain conditions (see our tips)
- We pay attention to the speed of recovery - a very important parameter, which, with insufficient efficiency, can simply destroy part of the business.
You can also test our own solution, especially since we let you do it for free. At least in our own tests, Parallels Cloud Storage shows the highest data recovery speed in case of disk loss (more than in RAID systems, including SAN) and performance is at least not worse than local RAID, and with SSD caching - even higher.
We plan to talk more about data consistency in a separate post.
How to try Parallels Cloud Storage
The official product page is here . To try for free, fill out the form . PStorage is
also available for the OpenVZ project .
You can read about how PCS works in FastVPS in this post .
What your tests show, the pros and cons - we can discuss in detail in the comments.