Data Mining Hub, through the eyes of scientists
Hello, Habr!
We launched the Data Mining Hub and want to tell you what it is and why it may be useful to you.
The Data Mining Hub (DMH) is an iterative approach to the development of algorithms for Data Mining and Machine Learning, as well as a business tool to help analyze large amounts of data and extract from This data is useful and necessary information.
The difference between DMH and similar resources, such as kaggle and algomost:
There are two sides to DMH. The first is the customer who describes the task, and the second is the scientist who is trying to solve this problem.
DMH scientists provide an opportunity to participate in solving interesting problems, compete with other participants and, of course, get paid if their algorithm was chosen by the Customer. If he was not selected at this iteration, then he can always be selected at the next. DMH will automatically transfer the results from the last iteration to the new one, if the original data has not changed. But there is also the opportunity to improve your algorithm and get paid due to the improved algorithm in the next iteration.
For the customer, DMH is a single point of integration with a large number of scientists and an easy way to use different algorithms on the same data.
Briefly, the principle of DMH can be described as follows:
Anyone can click on the link www.datamininghub.com/invite/me and ask DMH to invite them simply by entering an email.
Consider what a scientist needs to do to take part in solving the task. In principle, everything is quite simple. He needs to select a task, create an algorithm for it, test it on the source data. If a satisfactory result is obtained, then you can already specify the cost of using the algorithm.
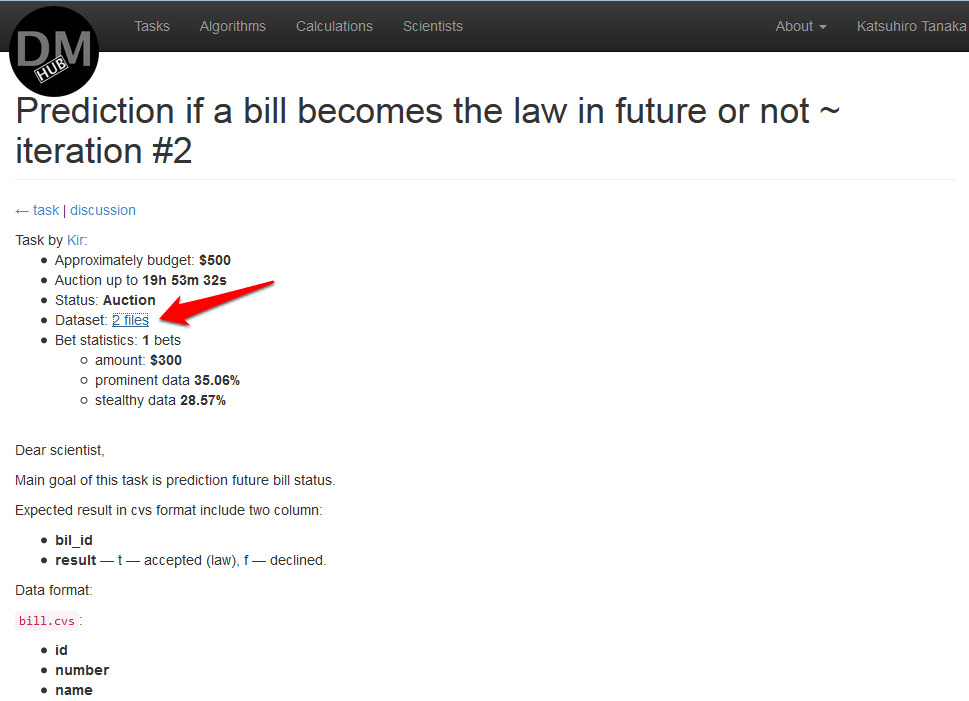
After authentication on datamininghub.com, a page opens, listing all tasks that need to be solved. You must select your favorite task and download the source data in the Data Set section.
Next, you need to develop an algorithm using any development tools. The main thing is that the algorithm be a jar file (or several), which could be run as a job on hadoop.
A small example of an algorithm on Scala is available at: github.com/datamininghub/example-algorithm A
real example of solving an existing problem is available at www.datamininghub.com/task/1 or on the same Scala is available here: github.com/datamininghub/example -bill-status-prediction
In order to load your algorithm you need:
It is possible to check the algorithm for any data before setting the cost of using this algorithm by clicking on try it in the navigation panel on the Algorithm details page . The edit calculations page will appear , in the Mappings section of which you will need to load the data for the calculations and click on calculate in the navigation panel.
ps - special thanks to Eugenia for her invaluable contribution to this text!
We launched the Data Mining Hub and want to tell you what it is and why it may be useful to you.
The Data Mining Hub (DMH) is an iterative approach to the development of algorithms for Data Mining and Machine Learning, as well as a business tool to help analyze large amounts of data and extract from This data is useful and necessary information.
The difference between DMH and similar resources, such as kaggle and algomost:
- the task is divided into iterations;
- the algorithm code remains with the author, the Customer takes it only for rent;
- DMH manages, calculates, evaluates, and manipulates money;
- participation does not require verification and confirmation of qualifications.
There are two sides to DMH. The first is the customer who describes the task, and the second is the scientist who is trying to solve this problem.
DMH scientists provide an opportunity to participate in solving interesting problems, compete with other participants and, of course, get paid if their algorithm was chosen by the Customer. If he was not selected at this iteration, then he can always be selected at the next. DMH will automatically transfer the results from the last iteration to the new one, if the original data has not changed. But there is also the opportunity to improve your algorithm and get paid due to the improved algorithm in the next iteration.
For the customer, DMH is a single point of integration with a large number of scientists and an easy way to use different algorithms on the same data.
Briefly, the principle of DMH can be described as follows:
- The customer creates the task, gives a description, determines the approximate budget, duration and period of the decision for each iteration.
- The customer uploads the data, which scientists will then work with.
- The customer confirms the task, after which the data becomes available to scientists.
- Based on the data, scientists create their own algorithms, load them into DMH and indicate the cost of using the algorithm.
- The customer selects the algorithm he likes, and then the payment to the Scientist is transferred.
Anyone can click on the link www.datamininghub.com/invite/me and ask DMH to invite them simply by entering an email.
Consider what a scientist needs to do to take part in solving the task. In principle, everything is quite simple. He needs to select a task, create an algorithm for it, test it on the source data. If a satisfactory result is obtained, then you can already specify the cost of using the algorithm.
Let's consider in more detail
After authentication on datamininghub.com, a page opens, listing all tasks that need to be solved. You must select your favorite task and download the source data in the Data Set section.
Next, you need to develop an algorithm using any development tools. The main thing is that the algorithm be a jar file (or several), which could be run as a job on hadoop.
A small example of an algorithm on Scala is available at: github.com/datamininghub/example-algorithm A
real example of solving an existing problem is available at www.datamininghub.com/task/1 or on the same Scala is available here: github.com/datamininghub/example -bill-status-prediction
In order to load your algorithm you need:
- Go to the DMH.
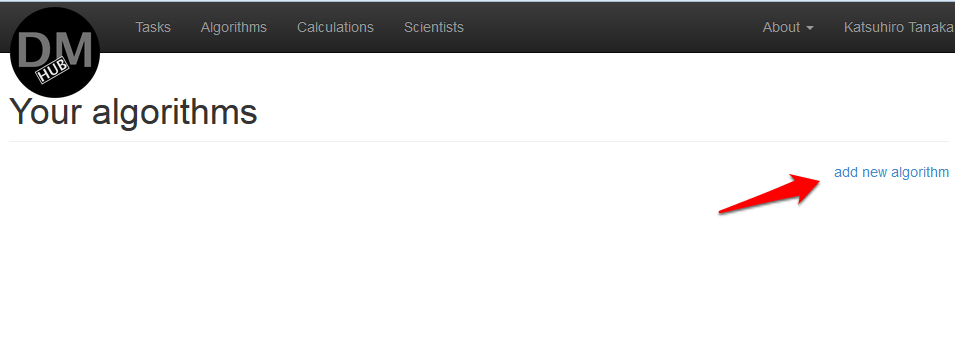
- In the menu, select Algorithms , after which a page will open where all the created algorithms for this user will be listed.
- Click add new algorithm
- If an AWS account has not been linked to the user profile before, the system will ask you to do this at this stage:
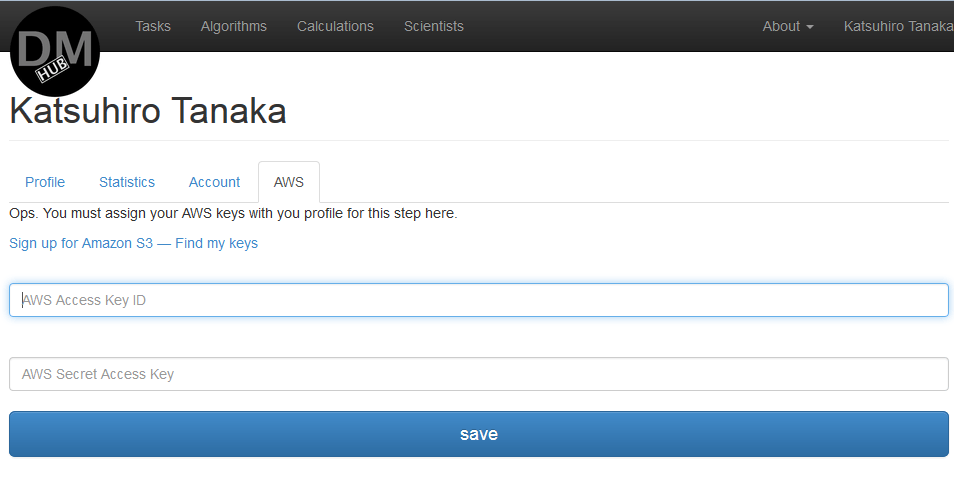
If there is no AWS account, you will need to register it.
By following the link http://aws.amazon.com/free/ it is possible to register a new account and use free limits for a year.
After that, you will need to follow the link Sign up for Amazon S3 - Find my keys and create the keys that you need to enter further in DMH. - After the AWS account is linked, the Algorithm details page appears, which displays the default name of the DataMiningHub algorithm N for Hadoop 1.0.3 and where you need to click on Edit :

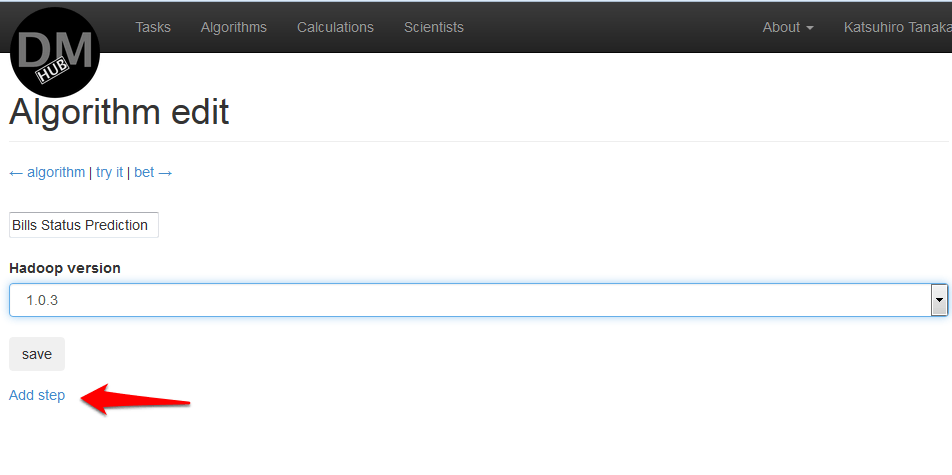
- On the Algorithm edit page that appears, it is possible to change the name of the algorithm to something else, change the version of Hadoop used. Then you need to click on Add step to add a step, which is adding a jar file containing the algorithm code, and determine the arguments with which this file will be launched:
- On the Add file page that appears , select the jar file to download and click the Upload button or specify an S3 link to this file.

For example, a file named bill-status-prediction.jar is taken
Note: downloading a file may take some time! - Now you need to set the arguments on the Step algorithm edit page with which the given jar file will be launched, and click the Save button :

For the example, the following arguments are used:-o {output} --events {events} --bill_deputy {bill_deputy} -f - After the arguments have been set, the Algorithm edit page appears again , but with information about the already entered step. If necessary, you can download other jar files by clicking Add step and repeating steps 6 to 8.
- Now, on the Algorithm details page, you need to click bet on the navigation panel to determine the cost of using the algorithm and perform calculations:
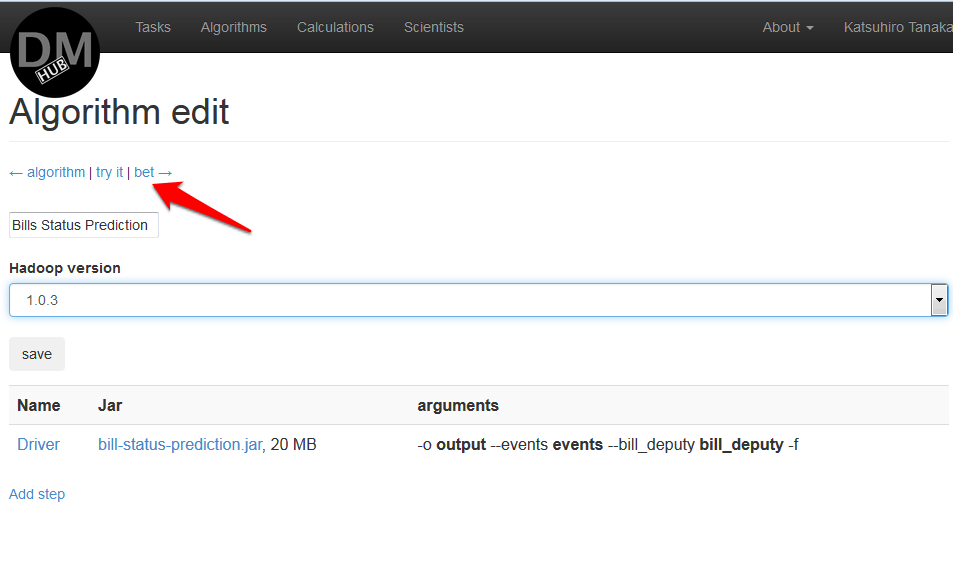
- On the Algorithm bet page, you must select the task in which the algorithm will be used:
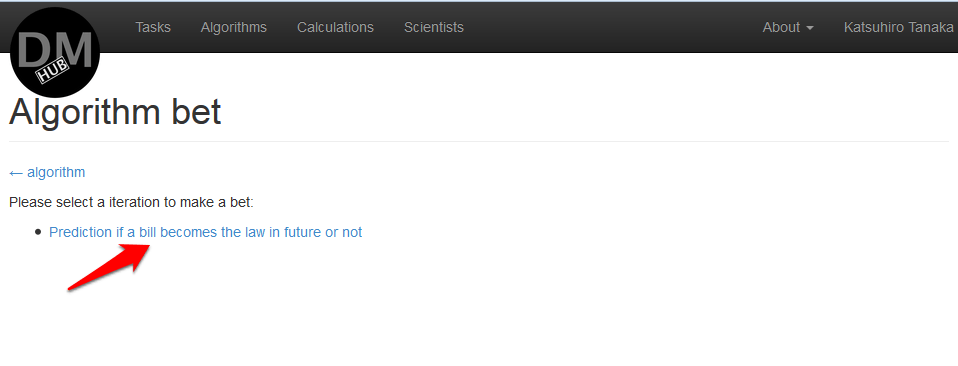
In this example, only one iteration is available Prediction if a bill becomes the law in future or not. - On the Add new bet use algorithm% algorithm_name% page that appears, you need to determine the cost of using the algorithm and click the bet it button :
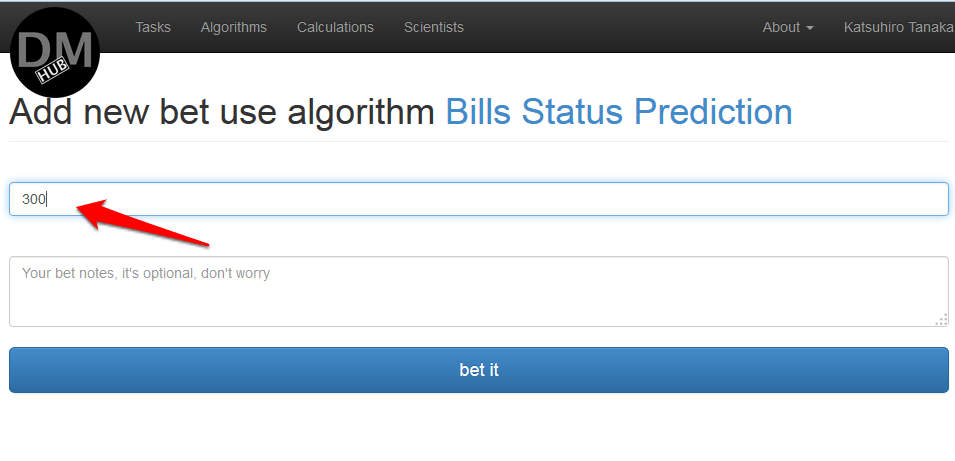
- On the page that appears, Edit calculation is necessary in the section Mappings make mapping the names of all the arguments of all the steps ( steps ) c source data by clicking on a assign opposite each argument name and selecting the desired data source, and press the calculate :
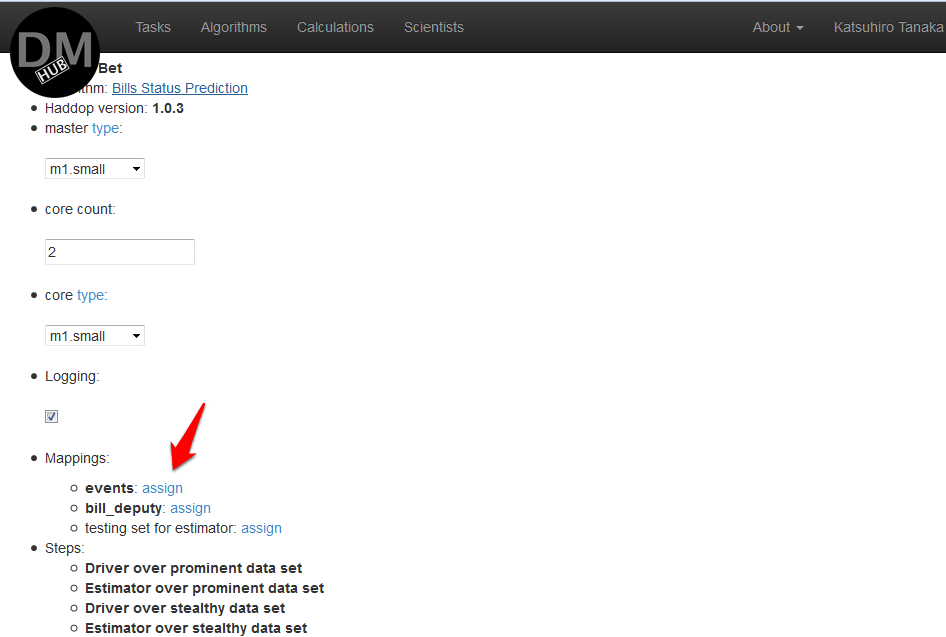
If necessary, this calculation can be saved by pressing the button Save - After all the manipulations, the Calculation details page appears , which displays the status of this calculation. After the calculation is completed, its result will be sent to the mailing address associated with this profile.
Example calculation during processing:
Example completed calculation: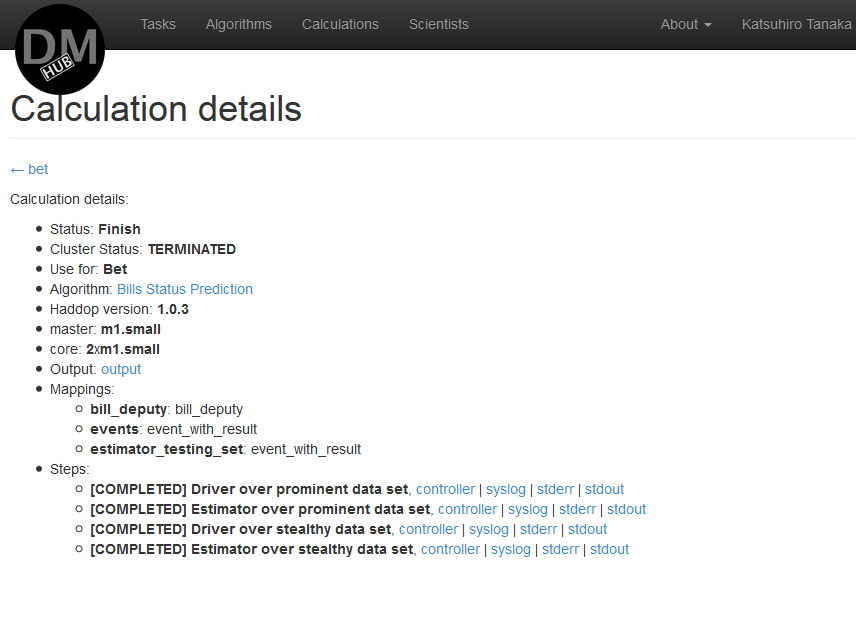
- When the calculation is completed, its result will appear in the description of the task, as well as the cost of using the algorithm, and the Customer will be able to choose this algorithm as a solution to the task:
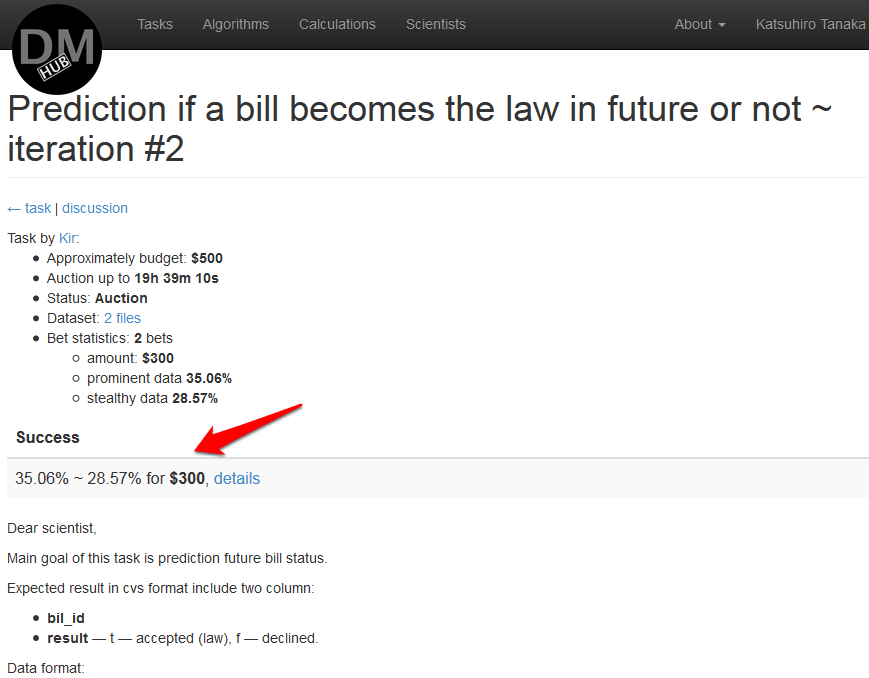
It is possible to check the algorithm for any data before setting the cost of using this algorithm by clicking on try it in the navigation panel on the Algorithm details page . The edit calculations page will appear , in the Mappings section of which you will need to load the data for the calculations and click on calculate in the navigation panel.
ps - special thanks to Eugenia for her invaluable contribution to this text!