JSOC: How to Measure the Availability of a Security Operation Center?
Good afternoon. We continue the series of articles “Behind the Scenes” of the Jet Security Operation Center. When it comes to a “cloud” service, the question always arises of the number of “9 after the decimal point” in terms of its availability. I would like to talk about what the availability of SOC is made of in terms of hardware and software, and by what means we control this availability. The article will be much more technical, so I will ask readers to be patient.
The final goal of our service (JSOC) is the identification and operational analysis of information security incidents arising from customers. This creates three basic requirements for its availability:
These requirements spawn three different levels of JSOC service availability monitoring.
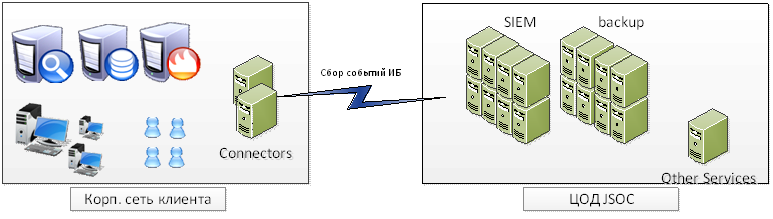
Everything here is quite simple and does not differ from deep monitoring of any other IT application. Consider a typical connection scheme of our client:
With this scheme, availability monitoring controls:
These indicators are fully monitored through Zabbix. For each indicator, statistics are collected and triggers are configured for the specified threshold values: warning - 20% of the maximum value, critical - 2−5% of the maximum value. In general, there is nothing unusual here, and there is probably no need to describe it again.
The result of this model is the ability to quickly obtain information about external and internal problems in the service, potentially "bottlenecks" from the point of view of infrastructure. But all these parameters do not give us an understanding of the integrity of the information we have and whether we see everything that is required in the customer’s network and whether we can quickly respond to the incident.
This leads us to the second task: it is necessary to control what information comes to us from the source systems, how complete and relevant it is, how correctly it is understood by the system. In the case of a SIEM system, the following parameters become critical:
It is clear that the task of monitoring the incoming data and analyzing them for completeness and integrity is primarily the task of SIEM itself. Unfortunately, out of the box it’s not always possible to get acceptable results.
But, as noted earlier, HP ArcSight is primarily a framework. And when we created JSOC, we began to tinker with our model for controlling incoming information. Here's what happened in the end.
The last measurement indicator remained - the system’s speed when reporting and investigating the incident by the analyst. In our case, potential delays entail a violation of the SLA, so we, of course, could not leave this issue aside.
In this case, as a rule, it is enough to determine the set of operations and reports necessary to investigate the most critical or frequency incidents and measure the time of their execution on the customer’s weighted average case. We take information about the speed of execution from two sources at once.
The first one is reports and scheduled operations that show us “reference” performance indicators. In this case, we made two types of reports that are run according to a schedule: a report on a deliberately empty filter and a report on typical events (the same source monitoring) with summation over fields. Based on the results of the work of these reports, we also collect statistics and look at the dynamics of changes:

Second - information on the time the current reports were completed by employees.
For this, I would like to finish the story about what, in our opinion, ensures the availability of the JSOC core and how we solve the problem of controlling it. Thanks for attention.
The final goal of our service (JSOC) is the identification and operational analysis of information security incidents arising from customers. This creates three basic requirements for its availability:
- The platform for collecting and processing information should be accessible and operational. If information about events and incidents has nowhere to go, there can be no talk of any identification of incidents.
- Information from IS events sources should be as complete as possible: we should receive all the required audit events, on the basis of which our scenarios for identifying incidents are built.
- At the moment when the system recorded the incident, we should be able to quickly collect and analyze all the information necessary for its investigation.
These requirements spawn three different levels of JSOC service availability monitoring.
Level 1. JSOC Infrastructure
Everything here is quite simple and does not differ from deep monitoring of any other IT application. Consider a typical connection scheme of our client:
With this scheme, availability monitoring controls:
- Network Availability Components:
- Availability of the core of the SIEM system from the VDI platform, and, accordingly, the ability to work with the system of monitoring engineers;
- operability of the channel between the sites: the presence of network connectivity between the connector servers and the core of the system;
- Communication between connector servers and key client sources that are connected for event collection
- access from the SIEM system core to additional event processing and analysis servers
- Availability of the core of the SIEM system from the VDI platform, and, accordingly, the ability to work with the system of monitoring engineers;
- Hardware and OS level performance indicators:
- processor load and performance;
- the use and distribution of RAM;
- free space in file partitions;
- overall performance of the disk subsystem.
- processor load and performance;
- Analysis of the status of network components:
- the number of packet processing errors on network equipment;
- information on the quality of the site-2-site tunnel between sites (session status, loss percentage, etc.);
- utilization of network interfaces on all intermediate equipment;
- load on the Internet channel created by the transfer of traffic.
- the number of packet processing errors on network equipment;
- Monitoring the status of key system and application services at the OS level:
- state of OS services required for JSOC to function;
- Status and key metrics (uptime, resource usage) for ArcSight processes.
- state of OS services required for JSOC to function;
- Check for system log errors:
- network equipment and firewalls;
- virtualization tools;
- OS on kernel components and connector servers.
- network equipment and firewalls;
- Monitor connector logs and ArcSight core logs for errors.
These indicators are fully monitored through Zabbix. For each indicator, statistics are collected and triggers are configured for the specified threshold values: warning - 20% of the maximum value, critical - 2−5% of the maximum value. In general, there is nothing unusual here, and there is probably no need to describe it again.
The result of this model is the ability to quickly obtain information about external and internal problems in the service, potentially "bottlenecks" from the point of view of infrastructure. But all these parameters do not give us an understanding of the integrity of the information we have and whether we see everything that is required in the customer’s network and whether we can quickly respond to the incident.
Level 2. Integrity of information from sources
This leads us to the second task: it is necessary to control what information comes to us from the source systems, how complete and relevant it is, how correctly it is understood by the system. In the case of a SIEM system, the following parameters become critical:
- monitoring not only the state of sources, but also incoming types of events;
- All received events must be correctly parsed by the system. We need to clearly understand that events are processed correctly and our rules will work;
- the event stream sent by the source system should be delivered to the JSOC with minimal loss. We collect data in a mode close to real-time.
It is clear that the task of monitoring the incoming data and analyzing them for completeness and integrity is primarily the task of SIEM itself. Unfortunately, out of the box it’s not always possible to get acceptable results.
- ArcSight has a fairly high-quality mechanism for determining the status of connected systems. In the event of a fall in connectors, problems with the availability of end sources, the presence of a cache on the connector, the built-in correlation rules + visualization work.
The main problem here is that the standard content does not take into account the possibility of connecting multiple customers to the same system. As a result, all the default rules and dashboards are not suitable for our tasks. - There is also basic functionality for determining the fact of the lack of information from the source of events according to the principle: “there have been no events in the last N hours”.
But at the same time, all control goes entirely to the source (Microsoft Windows, Cisco ASA, etc.) and does not take into account the different type of events. Moreover, for all systems, only the total monitoring time can be included; there is no audit of changes in the number of events compared to “normal” operation.
Consider, for example, collecting events from the Cisco ASA firewall with the required audit level. One of the most important tasks in controlling this equipment for us is the identification and processing of remote access VPN sessions terminated by the firewall. Moreover, in the total flow of events they make up less than 1%. And their “disappearance” (for example, an accidental change in the audit settings by the customer) in the total volume of events may go unnoticed. - There is a built-in mechanism for parsing events and evaluating the success of its normalization, which can signal that the received event did not match the predefined format and did not fit into the format.
This event is called an “unparsed event” and notification of it can be delivered either by mail or by creating a case directly in the ArcSight console. Thus, it helps to successfully solve problem number 2. - There is a built-in notification mechanism in cases where the time difference between the label on the source and on the connector reaches a certain threshold.
And here everything is fine. Except that these events are not displayed in any way in the general dashboards and there are no alerts on them. Along with defining event caching on the connector, this is an almost ready-made solution to Problem 3.
But, as noted earlier, HP ArcSight is primarily a framework. And when we created JSOC, we began to tinker with our model for controlling incoming information. Here's what happened in the end.
- For starters, we “slightly” changed the logic of determining the source. For each type of source, we determined the categories of events that are important for us and identified the most frequent ones, the presence of which can be taken as a basis.
For example, for Windows you can write such a “mapping”:
4624, Logon / Logoff: Logon
4768, Account Logon: Kerberos Ticket Events
4663, Object Access: File System
4688, Detailed Tracking: Process Creation
4689, Detailed Tracking: Process Termination
4672, Logon / Logoff: Special Logon
5140, Object Access: File Share
, etc.
For Cisco ASA:
602303,602304,713228,713050, VPN Connection
302013-302016, SessionStatistic
106023, AccessDenied
, etc.
ArcSight makes it easy enough to do such mapping through configuration files. As a result, before the source status event looked like this (using Windows as an example):Timestamp CustomerName ConnectorName Eventname Devicename Event count DeviceVendor DeviceProduct Sep 2, 2014 5:37:29 p.m. MSK Jet infosystems Jet_windows Connector Device Status arc-srv1 - 10.31.120.25 thirteen Microsoft Microsoft Windows
Now, in JSOC, for each of our event categories, its status is:Timestamp CustomerName ConnectorName Eventname Devicename Event count DeviceVendor DeviceProduct Sep 2, 2014 5:37:29 p.m. MSK Jet infosystems Jet_windows Connector Device Status arc-srv1 - 10.31.120.24 126 Microsoft Object Access: File Share Sep 2, 2014 5:37:29 p.m. MSK Jet infosystems Jet_windows Connector Device Status arc-srv1 - 10.31.120.24 24 Microsoft Logon / Logoff: Logon Sep 2, 2014 5:37:29 p.m. MSK Jet infosystems Jet_windows Connector Device Status arc-srv1 - 10.31.120.24 53 Microsoft Microsoft Windows - For each "new type" of the source, a long-term dynamic profiling is carried out according to the volume and number of events received from it in ArcSight. As a rule, the unit of measurement of the profile is 1 hour, the duration of the profiling is 1 month. The main purpose of profiling is to determine the average and maximum values of the number of events from sources at different time intervals (working day, night, weekend, etc.)
After the profile has been built, we can already evaluate the “integrity” of the information received. Individual monitoring rules in ArcSight are configured as follows:- the absence of events is determined not by a given interval, but by comparison with a profile (if there really should not be any events from this source during this period of time, for example, events on a change in the configuration of a network device);
- by deviations: if the number of events over the past hour is 20% less / more than baseline at similar intervals in our profile - this is an occasion to understand the situation in more detail;
- definition of new sources (there are events, but this source is not in the profile).
Thus, the implemented “long” dynamic profiling allows us to quickly monitor problems in data transfer and control the integrity of the information that comes to us.
An example of such a status for one of the sources (proxy server):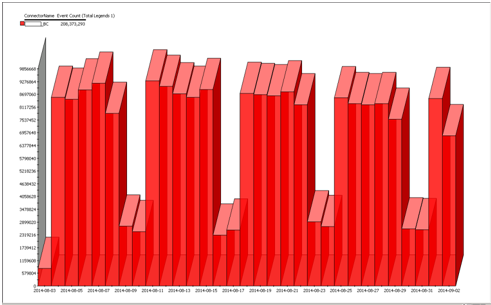
- Improved standard rules and dashboards. We added information about customers, added two separate profiles for tracking statuses for connectors and connected devices. As a result, all the rules are integrated into a single structure for generating incidents, and a case is created for each of them (just like when monitoring system components).
It turned out something like this: next two dashboards from the same ESM (one standard, the other ours). There is no problem with standard monitoring. And in our version - there are obvious problems with connecting to sources, the absence of events of a certain category and an increased flow of events from one of the devices.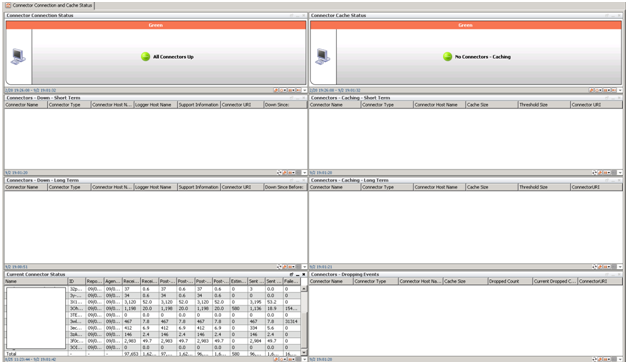

- There remains one very small but important problem: some audit events on target systems are very rare. For example, adding a user to a group of domain administrators in Active Directory or events on a change in the configuration of a network device (collected via tacacs-server Cisco ACS), etc. Moreover, the very fact of the occurrence of such an event is often already an IS incident even without additional correlation of the construction of complex chains of events.
And here the "old argument of the kings" remains the old and familiar scripting technique: as agreed with the customer, we emulate a test event on the target system with a certain frequency and thereby make sure that random errors in working with the audit will not cause the incident to not be detected.
It is worth noting that, despite the high level of control over the events built within the framework of the model described above, we nevertheless conduct combat tests of the audit system and our incident analysis team on a regular basis (at least once a month). In this case, the methodology is as follows: the customer independently (or with our help) performs a set of actions involving the identification of an incident. For our part, firstly, we record the fact of obtaining all the initial information in the JSOC, and secondly, once again we confirm the correctness of the correlation rules, and finally, we check the reaction and the level of analysis of the incident by the first line of our JSOC team.
Level 3. Performance
The last measurement indicator remained - the system’s speed when reporting and investigating the incident by the analyst. In our case, potential delays entail a violation of the SLA, so we, of course, could not leave this issue aside.
In this case, as a rule, it is enough to determine the set of operations and reports necessary to investigate the most critical or frequency incidents and measure the time of their execution on the customer’s weighted average case. We take information about the speed of execution from two sources at once.
The first one is reports and scheduled operations that show us “reference” performance indicators. In this case, we made two types of reports that are run according to a schedule: a report on a deliberately empty filter and a report on typical events (the same source monitoring) with summation over fields. Based on the results of the work of these reports, we also collect statistics and look at the dynamics of changes:
Second - information on the time the current reports were completed by employees.
For this, I would like to finish the story about what, in our opinion, ensures the availability of the JSOC core and how we solve the problem of controlling it. Thanks for attention.