RabbitMQ tutorial 6 - Remote Procedure Call
- Transfer
- Tutorial
In continuation of the fifth lesson on the study of the basics of RabbitMQ, I am publishing a translation of the sixth lesson from the official site . All examples are written in python (using pika version 0.9.8), but they can still be implemented on most popular languages .
In the second lesson, we examined the use of task queues to distribute resource-intensive tasks among multiple subscribers.
But what if we want to run the function on a remote machine and wait for the result? Well, that’s a completely different story. This pattern is commonly known as Remote Procedure Call (RPC, hereinafter referred to as RPC).
In this guide, we will build, using RabbitMQ, an RPC system that will include a client and a scalable RPC server. Since we do not have a real time-consuming task requiring distribution, we will create a simple RPC server that returns Fibonacci numbers.
To illustrate the use of the RPC service, create a simple client class. This class will contain a call method that will send RPC requests and block until a response is received:
In general, it is easy to perform RPC through RabbitMQ. The client sends the request and the server responds to the request. To receive a response, the client must pass a queue to post the results with the request. Let's see how it looks in the code:
AMQP has 14 predefined message properties. Most of them are used extremely rarely, with the exception of the following:
In the method presented above, we proposed creating a response queue for each RPC request. This is somewhat redundant, but, fortunately, there is a better way - let's create a common result queue for each client.
This raises a new question, having received an answer from this queue, it is not clear what request this answer matches. And here the correlation_id property comes in handy . We will assign a unique value to this property for every request. Later, when we extract the received response from the response queue, based on the value of this property, we can unambiguously match the request with the response. If we meet an unknown value in the correlation_id property , we can safely ignore this message, since it does not match any of our requests.
You might wonder why we plan to simply ignore unknown messages from the response queue, instead of interrupting the script? This is due to the likelihood of a server-side race condition. Although this is unlikely, a scenario is possible in which the RPC server sends us a response, but does not have time to send confirmation of request processing. If this happens, a restarted RPC server will again process this request. That is why on the client we must correctly handle repeated responses. In addition, RPC, ideally, should be idempotent.
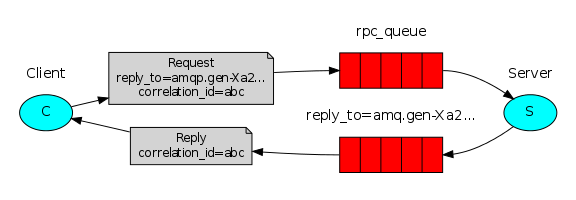
Our RPC will work as follows:
- When the Client starts, he creates an anonymous unique queue of results;
- To make an RPC request, the Client sends a message with two properties: reply_to , where the value is the result queue and correlation_id , set to a unique value for each request.
- The request is sent to the rpc_queue queue ;
- The server is waiting for requests from this queue. When the request is received, the Server performs its task and sends a message with the result back to the Client using the queue from the reply_to property ;
- The client expects the result from the result queue. When a message is received, the Client checks the correlation_id property . If it matches the value from the request, then the result is sent to the application.
Rpc_server.py server code:
Server code is pretty simple:
Client code rpc_client.py:
Client code is a bit more complicated:
Our RPC service is ready. We can start the server:
To get the Fibonacci numbers, run the Client:
The presented RPC implementation option is not the only possible one, but it has the following advantages:
Our code, however, is simplified and does not even try to solve more complex (but, of course, important) problems like these:
RabbitMQ tutorial 1 - Hello World (python)
RabbitMQ tutorial 2 - Task Queue (python)
RabbitMQ tutorial 3 - Publish / Subscribe (php)
RabbitMQ tutorial 4 - Routing (php)
RabbitMQ tutorial 5 - Topics (php)
RabbitMQ tutorial 6 - Remote call procedures (this article, python)
In the second lesson, we examined the use of task queues to distribute resource-intensive tasks among multiple subscribers.
But what if we want to run the function on a remote machine and wait for the result? Well, that’s a completely different story. This pattern is commonly known as Remote Procedure Call (RPC, hereinafter referred to as RPC).
In this guide, we will build, using RabbitMQ, an RPC system that will include a client and a scalable RPC server. Since we do not have a real time-consuming task requiring distribution, we will create a simple RPC server that returns Fibonacci numbers.
Customer interface
To illustrate the use of the RPC service, create a simple client class. This class will contain a call method that will send RPC requests and block until a response is received:
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print "fib(4) is %r" % (result,)
RPC Note
Although RPC is a fairly common pattern, it is often criticized. Problems usually arise when the developer does not know exactly what function he is using: local or slow, performed through RPC. A mess like this can result in unpredictability of the system’s behavior, and also introduces unnecessary complexity into the debugging process. Thus, instead of simplifying the software, improper use of RPC can lead to unattended and unreadable code.
Based on the foregoing, the following recommendations can be made:
- Make sure that it is obvious which function is called in each case: local or remote;
- Document your system. Make dependencies between components explicit;
- Handle the bugs. How should the client respond if the RPC server does not respond for a long period of time?
- If in doubt, do not use RPC. If possible, use an asynchronous pipeline instead of a blocking RPC when results are asynchronously passed to the next processing level.
Results Queue
In general, it is easy to perform RPC through RabbitMQ. The client sends the request and the server responds to the request. To receive a response, the client must pass a queue to post the results with the request. Let's see how it looks in the code:
result = channel.queue_declare(exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ...какой-то код для чтения ответного сообщения из callback_queue ...
Message Properties
AMQP has 14 predefined message properties. Most of them are used extremely rarely, with the exception of the following:
- delivery_mode : marks the message as “persistent” (with a value of 2) or “temporary” (any other value). You must remember this property in the second lesson ;
- content_type : used to describe the presentation format of the data (mime). For example, for the frequently used JSON format, it’s good practice to set this property to application / json;
- reply_to : usually used to indicate the result queue;
- correlation_id : The property is used to map RPC responses to requests.
Correlation id
In the method presented above, we proposed creating a response queue for each RPC request. This is somewhat redundant, but, fortunately, there is a better way - let's create a common result queue for each client.
This raises a new question, having received an answer from this queue, it is not clear what request this answer matches. And here the correlation_id property comes in handy . We will assign a unique value to this property for every request. Later, when we extract the received response from the response queue, based on the value of this property, we can unambiguously match the request with the response. If we meet an unknown value in the correlation_id property , we can safely ignore this message, since it does not match any of our requests.
You might wonder why we plan to simply ignore unknown messages from the response queue, instead of interrupting the script? This is due to the likelihood of a server-side race condition. Although this is unlikely, a scenario is possible in which the RPC server sends us a response, but does not have time to send confirmation of request processing. If this happens, a restarted RPC server will again process this request. That is why on the client we must correctly handle repeated responses. In addition, RPC, ideally, should be idempotent.
Summary
Our RPC will work as follows:
- When the Client starts, he creates an anonymous unique queue of results;
- To make an RPC request, the Client sends a message with two properties: reply_to , where the value is the result queue and correlation_id , set to a unique value for each request.
- The request is sent to the rpc_queue queue ;
- The server is waiting for requests from this queue. When the request is received, the Server performs its task and sends a message with the result back to the Client using the queue from the reply_to property ;
- The client expects the result from the result queue. When a message is received, the Client checks the correlation_id property . If it matches the value from the request, then the result is sent to the application.
Putting it all together
Rpc_server.py server code:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print " [.] fib(%s)" % (n,)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print " [x] Awaiting RPC requests"
channel.start_consuming()
Server code is pretty simple:
- (4) As usual, we establish a connection and declare a queue;
- (11) We declare our function that returns Fibonacci numbers, which takes as an argument only integer positive numbers (this function is unlikely to work with large numbers, most likely this is the slowest possible implementation);
- (19) We declare the on_request callback function for basic_consume , which is the core of the RPC server. It is executed when the request is received. Having completed the work, the function sends the result back;
- (32) Probably we will someday want to start more than one server. To evenly distribute the load across multiple servers, we set prefetch_count .
Client code rpc_client.py:
#!/usr/bin/env python
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print " [x] Requesting fib(30)"
response = fibonacci_rpc.call(30)
print " [.] Got %r" % (response,)
Client code is a bit more complicated:
- (7) We establish a connection, a channel and announce a unique queue of results for the responses received;
- (16) We subscribe to the results queue to receive responses from the RPC;
- (18) The callback function ' on_response ', executed upon receipt of each response, performs a rather trivial task - for each received response it checks whether correlation_id corresponds to what we expect. If so, it saves the response in self.response and breaks the loop;
- (23) Next, we define our call method , which, in fact, performs an RPC request;
- (24) In this method, we first generate a unique correlation_id and save it - the on_response callback function will use this value to track the desired response;
- (25) Next, we put the request with the reply_to and correlation_id properties in the queue;
- (32) Next, the process of waiting for a response begins;
- (33) And, at the end, we return the result back to the user.
Our RPC service is ready. We can start the server:
$ python rpc_server.py
[x] Awaiting RPC requests
To get the Fibonacci numbers, run the Client:
$ python rpc_client.py
[x] Requesting fib(30)
The presented RPC implementation option is not the only possible one, but it has the following advantages:
- If the RPC server is too slow, you can easily add another one. Try running the second rpc_server.py in the new console;
- On the Client side, RPC requires sending and receiving only one message. No synchronous call to queue_declare required . As a result, the RPC client manages one request-response cycle for one RPC request.
Our code, however, is simplified and does not even try to solve more complex (but, of course, important) problems like these:
- How should the client respond if the server is not running?
- Should the Client have a timeout for RPC?
- If the Server at some point “breaks” and throws an exception, should it be passed to the Client?
- Protection against invalid incoming messages (for example, checking acceptable boundaries) before processing.
All management articles
RabbitMQ tutorial 1 - Hello World (python)
RabbitMQ tutorial 2 - Task Queue (python)
RabbitMQ tutorial 3 - Publish / Subscribe (php)
RabbitMQ tutorial 4 - Routing (php)
RabbitMQ tutorial 5 - Topics (php)
RabbitMQ tutorial 6 - Remote call procedures (this article, python)