A few words about pipelines in FPGA
Hello!
Many people know that in all modern processors there is a computing pipeline. There is a misconception that the pipeline is some kind of processor chip, but this is not in the chips for other applications (for example, network). In fact, pipelining (or pipelining) is the key to creating high-performance ASIC / FPGA-based applications.
Very often, to achieve high performance, they choose algorithms that are easily pipelined in the chip. If you are interested in learning about low-level details, welcome to cut!
Consider the following example: you need to add four unsigned eight-bit numbers. As part of this task, I neglected the fact that the result of summing 8-bit numbers can be greater than 255. The
quite obvious code in the SystemVerilog language for this task is:
Let's take a look at the resulting circuit from registers and adders. We use the RTL Viewer in Quartus for this. (Tools -> Netlist Viewer -> RTL Viewer). For the purposes of this article, the words “register” and “trigger” are full synonyms.

What happened?
Add registers between the adders Add0 / Add1 and Add2 .

In order to see the difference in the behavior of the no_pipe_example and pipe_example modules, combine them into one and simulate them.

On the positive edge (the so-called posedge) clk_i, 4 numbers were sent to the input of the module: 4, 8, 15 and 23. The next positive edge in the no_pipe_res_o register was answered 50, and in the registers s1 and s2 the values were half-sums of 12 and 38. The next posedge register pipe_res_o appeared response 50, and in no_pipe_res_o appeared 0, which is not surprising, because four zeros were given as input values and the circuit honestly added them.
It is immediately noticeable that the result in pipe_res_o is lagging by one beat than in no_pipe_res_o , because registers s1 and s2 were added .
Consider what happens if we each time submit a new array of numbers for summing: It is easy to see that both branches (with or without a pipeline) are ready to receive a new chunk of data every time. A fair question arises: why use the pipeline if more time (clocks) is spent on computing and this takes more triggers (resources)?

The performance of this circuit is determined by the number of 8-bit fours, which it can receive and process per second. The circuit is ready for a new chunk of data every cycle, therefore, the higher the value of the frequency clk_i , the higher the performance of the circuit.
There is a formula that calculates the maximum allowable frequency between two triggers. Its simplified version:

Legend :
Under the spoiler is the full formula, the explanation of which can be found in the list of literature, which is given at the end of the article.
To estimate the maximum frequency, we consider the paths between all the triggers within the same block domain: that is, only those triggers that work from the block of interest to us. Then the longest path is determined, which shows the maximum frequency at which the circuit will work without errors.
The more logic elements there are in the signal path from one trigger to another, the greater the value of Tlogic . If we want to increase the frequency, then we need to reduce this value! How to do this?
Adding registers - this is pipelining! Pipelined circuits in most cases can be used to work at a lshih frequencies than those without conveyor.
Consider the following example:
There are two triggers, A and B , the signal between them overcomes two “clouds” of logic, one of which takes 4 ns, the other 7 ns. If it is easier, imagine that the green cloud is the adder, and the orange is the multiplexer. Examples and numbers are taken from the head.

What will be Fmax ? Sum of 4 and 7 ns will display the value Tlogic : Fmax ~ 91 MHz.
Add register C between the combination:

Fmaxestimated by the worst path, whose time is now 7 ns, or ~ 142 MHz. Of course, you don’t have to rush and add registers to increase the frequency anywhere, because you can easily run into the most common mistake (in my experience), that somewhere around one clock cycle went circuit, because somewhere they added a register, but somewhere not. It happens that the circuit was not ready for conveyorization, because there is feedback, due to the delay on the beat (s), it began to work incorrectly.
To summarize:
I note that sometimes there is no goal to achieve the maximum frequency, most often the opposite: the frequency to which we must strive is known. For example, the standard 10G MAC core frequency is 156.25 MHz. It may be convenient for the entire circuit to operate on this frequency. There are requirements that are not directly related to the clock frequency: for example, there is a task for some kind of search system to do 10 million searches per second. On the one hand, you can make a conveyor at a frequency of 10 MHz, and prepare a circuit to receive data every cycle. On the other hand, it might turn out to be more profitable: increase the frequency to 100 MHz and make a pipeline that is ready to receive data every 10th clock cycle.
Of course, this example is very childish, but it is the key to creating circuits with very high performance.
In a previous article, I mentioned that I am developing high-speed FPGA-based Ethernet applications. The main foundation of such applications is pipelines that grind packets. It so happened that during the preparation of this article I gave a short lecture on pipelining in FPGA to trainee students who are gaining experience in this craft. I thought that these tips would be appropriate here, and perhaps cause some discussion. Experienced developers, most likely, will not find something new or original)
Sometimes novice FPGA developers make the following mistake: they determine the fact of the arrival of new data from the data itself. For example, they check the data for zero: if not zero, then the new data has arrived, otherwise we do nothing. Also, instead of zero, they use some other “forbidden” combination (all units).
This is not a very good approach, since:
By introducing validity signals, we inform the module of the fact of the presence of valid data at the input, and it, in turn, shows when the data at the output is correct. These signals can be used by the next module, which is in the conveyor chain.
Add the validity signals x_val_i and pipe_res_val_o to the example above:
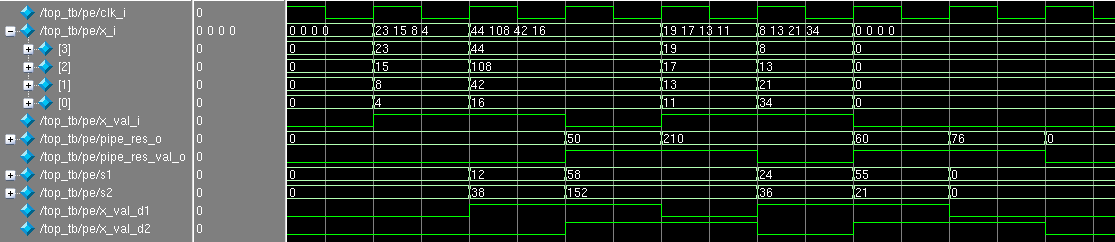
You must admit that it immediately became clear what is happening here: at what clock do the data at the input and output turn out to be valid?
A couple of comments:
Most often during development it is immediately clear that it is necessary to build a conveyor to achieve the desired frequency. When a pipeline is written from scratch, you need to think about the architecture, for example, decide when you can send data to the pipeline. As an illustration, I will give a typical architecture of an Ethernet packet processing pipeline.

Legend:
In this example, fifo_0 is the sender of the data, and fifo_1 is the receiver. Suppose that for some reason data is not always read from fifo_1 or the data reading speed is less than the write speed, as a result, this FIFO can overflow. You don’t need to write in full fifos, because at least you will break the package (some data set may disappear from the package) and transfer it incorrectly.
What can fifo say?
In order not to break the data, we need sometime not to read the packet data from fifo_0 and to suspend the operation of the pipeline. How to do it?
Let's say we allocated fifo_1 for MTU, for example, 1500 bytes. Before starting to read a packet from fifo_0, arb looks at the number of free bytes in fifo_1 . If it is larger than the size of the current package, then set rd_req and do not remove until the end of the package. Otherwise, we wait until Fifo is free.
Pros:
Minuses:
Note:
When calculating free space, you need to make a margin on the length of the conveyor. For example, right now at fifo_1 there are 100 bytes free, a packet of 95 bytes has come to us. We look that 100 is more than 95 and we begin to forward a packet. This is not entirely true, because we don’t know the current state of the pipeline - if we process the previous packet, then in the worst case, fifo_1 will additionally record additional words in the amount of pipeline length (in ticks). If the pipeline runs 10 clock cycles, then another 10 words will fall into fifo_1 , and Fifo can overflow when we write a packet of 95 bytes.
We reserve in fifo_1 the number of words equal to the length of the assembly line. We use the signal almost_full .
The arbiter looks at this signal every beat. If it is 0, then we subtract one word of the package, otherwise - no.
Pros:
Minuses:
The previous options have a common feature: if the packet word got to the beginning of the pipeline, then there’s nothing to be done: after a constant number of ticks this word (or its modification) will fall into fifo_1 .
An alternative is that the conveyor can be stopped during operation. For each stage with the number M, the ready input appears , which indicates whether stage M + 1 is ready to receive data or not. The inversion of full or almost_full (if you want to play it safe a bit) is started at the entrance of the very last stage .

Pros :
Minuses:
The above problems can be resolved using interfaces that already have auxiliary signals. Altera for data streams suggests using the Avalon Streaming interface ( Avalon-ST ). A detailed description can be found here . By the way, it is this interface that is used in the Alterov 10G / 40G / 100G Ethernet MAC cores.

The presence of valid and ready signals , which we spoke about earlier, attracts attention immediately . The empty signal indicates the number of free (unused) bytes in the last word of the packet. Signals startofpacket and endofpacketdetermine the beginning and end of the package: it is convenient to use these signals to reset various counters, which count offsets to extract the necessary data.
Xilinx suggests using AXI4-Stream for these purposes.

In general, the set of signals is similar (in this picture, not all signals that are possible in this standard). To be honest, I never used AXI4-Stream. If someone used both interfaces, I would be grateful if you share the comparison and impressions.
I think the advantages of using standard interfaces do not need to be mentioned. Well, the cons are obvious: you must comply with the standard, which is expressed in b aboutwith more code, resources, tests, etc. Of course, you can make your own bikes, but in the long run on a large project (and top-end chips) it can come out sideways.
As an example, more complicated than a couple of adders, I propose to make a module that swaps the source and destination MAC addresses ( mac_src and mac_dst ) in an Ethernet packet . This can be useful if there is a desire to send all the traffic that comes to the device back (the so-called traffic inversion / loopback or loopback). The implementation, of course, must be done by the conveyor.
We use the Avalon-ST interface with a 64-bit data bus (for 10G) without ready and error signals . As a test package, take the one that looked at xgmii in a previous article . Then:
Code on SystemVerilog under the spoiler:
Not everything is as scary as it might have seemed: most of the lines went into the description of the module I / O and the delay line. By startofpacket we determine in which word we are and what data should be substituted into the combination new_data_c , which then latches into data_o . The signals startofpacket , endofpacket , empty , valid are delayed by the required number of clock cycles.
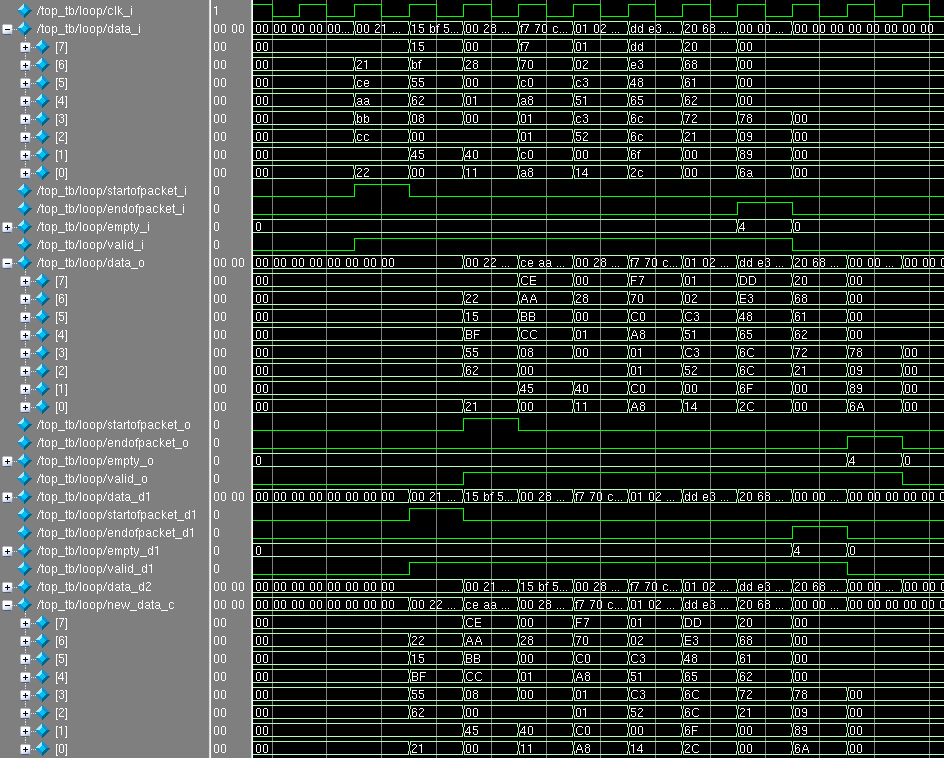
Module simulation: As you can see, the MAC addresses are reversed, and all other data in the packet has not changed. In the next article we will analyze the quad tree
: a more serious example of pipelining, where we use one of the architectural features of FPGA - block memory.
Thank you for your time and attention! If you have questions, ask without a doubt.
PS Thanks to des333 for constructive criticism and advice.
Many people know that in all modern processors there is a computing pipeline. There is a misconception that the pipeline is some kind of processor chip, but this is not in the chips for other applications (for example, network). In fact, pipelining (or pipelining) is the key to creating high-performance ASIC / FPGA-based applications.
Very often, to achieve high performance, they choose algorithms that are easily pipelined in the chip. If you are interested in learning about low-level details, welcome to cut!
Simple example
Consider the following example: you need to add four unsigned eight-bit numbers. As part of this task, I neglected the fact that the result of summing 8-bit numbers can be greater than 255. The
quite obvious code in the SystemVerilog language for this task is:
module no_pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] no_pipe_res_o
);
// no pipeline
always_ff @( posedge clk_i )
begin
no_pipe_res_o <= ( x_i[0] + x_i[1] ) +
( x_i[2] + x_i[3] );
end
endmodule
Let's take a look at the resulting circuit from registers and adders. We use the RTL Viewer in Quartus for this. (Tools -> Netlist Viewer -> RTL Viewer). For the purposes of this article, the words “register” and “trigger” are full synonyms.

What happened?
- Inputs x_i [0] and x_i [1] are supplied to the adder Add0 , and x_i [2] and x_i [3] to Add1 .
- The outputs c Add0 and Add1 are fed to the adder Add2 .
- The output from the Add2 adder is latched into the no_pipe_res_o trigger .
Add registers between the adders Add0 / Add1 and Add2 .
module pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] pipe_res_o
);
// pipeline
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
endmodule

- Inputs x_i [0] and x_i [1] are supplied to the adder Add0 , and x_i [2] and x_i [3] to Add1 .
- After summing, the result is placed in the registers s1 and s2 .
- Data from registers s1 and s2 are fed to Add2 , the result of the summation is latched into pipe_res_o .
In order to see the difference in the behavior of the no_pipe_example and pipe_example modules, combine them into one and simulate them.
Hidden text
module pipe_and_no_pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] no_pipe_res_o,
output logic [7:0] pipe_res_o
);
// no pipeline
always_ff @( posedge clk_i )
begin
no_pipe_res_o <= ( x_i[0] + x_i[1] ) +
( x_i[2] + x_i[3] );
end
// pipeline
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
endmodule

On the positive edge (the so-called posedge) clk_i, 4 numbers were sent to the input of the module: 4, 8, 15 and 23. The next positive edge in the no_pipe_res_o register was answered 50, and in the registers s1 and s2 the values were half-sums of 12 and 38. The next posedge register pipe_res_o appeared response 50, and in no_pipe_res_o appeared 0, which is not surprising, because four zeros were given as input values and the circuit honestly added them.
It is immediately noticeable that the result in pipe_res_o is lagging by one beat than in no_pipe_res_o , because registers s1 and s2 were added .
Consider what happens if we each time submit a new array of numbers for summing: It is easy to see that both branches (with or without a pipeline) are ready to receive a new chunk of data every time. A fair question arises: why use the pipeline if more time (clocks) is spent on computing and this takes more triggers (resources)?

Conveyor performance
The performance of this circuit is determined by the number of 8-bit fours, which it can receive and process per second. The circuit is ready for a new chunk of data every cycle, therefore, the higher the value of the frequency clk_i , the higher the performance of the circuit.
There is a formula that calculates the maximum allowable frequency between two triggers. Its simplified version:

Legend :
- Fmax - maximum clock speed.
- Tlogic - delay when a signal passes through logic elements.
Under the spoiler is the full formula, the explanation of which can be found in the list of literature, which is given at the end of the article.
Hidden text

To estimate the maximum frequency, we consider the paths between all the triggers within the same block domain: that is, only those triggers that work from the block of interest to us. Then the longest path is determined, which shows the maximum frequency at which the circuit will work without errors.
The more logic elements there are in the signal path from one trigger to another, the greater the value of Tlogic . If we want to increase the frequency, then we need to reduce this value! How to do this?
- Optimize the code. Sometimes newcomers (and experienced developers, it’s a sin to hide!) Write such constructions that turn into very long chains of logic: this should be avoided with various tricks. Sometimes it is necessary to optimize the circuit for a specific FPGA architecture.
- Add register (s). Just cut the logic into pieces.
Adding registers - this is pipelining! Pipelined circuits in most cases can be used to work at a lshih frequencies than those without conveyor.
Consider the following example:
There are two triggers, A and B , the signal between them overcomes two “clouds” of logic, one of which takes 4 ns, the other 7 ns. If it is easier, imagine that the green cloud is the adder, and the orange is the multiplexer. Examples and numbers are taken from the head.

What will be Fmax ? Sum of 4 and 7 ns will display the value Tlogic : Fmax ~ 91 MHz.
Add register C between the combination:

Fmaxestimated by the worst path, whose time is now 7 ns, or ~ 142 MHz. Of course, you don’t have to rush and add registers to increase the frequency anywhere, because you can easily run into the most common mistake (in my experience), that somewhere around one clock cycle went circuit, because somewhere they added a register, but somewhere not. It happens that the circuit was not ready for conveyorization, because there is feedback, due to the delay on the beat (s), it began to work incorrectly.
To summarize:
- Thanks to pipelining, you can increase the throughput of the circuit, sacrificing processing time and resources.
- It is necessary to break the logic as evenly as possible, because The maximum frequency of the circuit depends on the worst path. By breaking 11 ns in half, you could get 182 MHz.
- Of course, infinity cannot be increased infinitely, because the time parameters that we have now closed our eyes cannot be neglected. First of all, Trouting .
I note that sometimes there is no goal to achieve the maximum frequency, most often the opposite: the frequency to which we must strive is known. For example, the standard 10G MAC core frequency is 156.25 MHz. It may be convenient for the entire circuit to operate on this frequency. There are requirements that are not directly related to the clock frequency: for example, there is a task for some kind of search system to do 10 million searches per second. On the one hand, you can make a conveyor at a frequency of 10 MHz, and prepare a circuit to receive data every cycle. On the other hand, it might turn out to be more profitable: increase the frequency to 100 MHz and make a pipeline that is ready to receive data every 10th clock cycle.
Of course, this example is very childish, but it is the key to creating circuits with very high performance.
Tips and personal experience
In a previous article, I mentioned that I am developing high-speed FPGA-based Ethernet applications. The main foundation of such applications is pipelines that grind packets. It so happened that during the preparation of this article I gave a short lecture on pipelining in FPGA to trainee students who are gaining experience in this craft. I thought that these tips would be appropriate here, and perhaps cause some discussion. Experienced developers, most likely, will not find something new or original)
Use validity signals
Sometimes novice FPGA developers make the following mistake: they determine the fact of the arrival of new data from the data itself. For example, they check the data for zero: if not zero, then the new data has arrived, otherwise we do nothing. Also, instead of zero, they use some other “forbidden” combination (all units).
This is not a very good approach, since:
- Resources are spent on grounding and checking. On large data buses, this can be very expensive.
- It may not be obvious to other developers what is happening here (WTF code).
- Some forbidden combination may not be. As in the example with the adder above: all values from 0 to 255 are valid and can be fed to the adder.
By introducing validity signals, we inform the module of the fact of the presence of valid data at the input, and it, in turn, shows when the data at the output is correct. These signals can be used by the next module, which is in the conveyor chain.
Add the validity signals x_val_i and pipe_res_val_o to the example above:
Hidden text
module pipe_with_val_example(
input clk_i,
input [7:0] x_i [3:0],
input x_val_i,
output logic [7:0] pipe_res_o,
output logic pipe_res_val_o
);
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
logic x_val_d1 = 1'b0;
logic x_val_d2 = 1'b0;
always_ff @( posedge clk_i )
begin
x_val_d1 <= x_val_i;
x_val_d2 <= x_val_d1;
end
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
assign pipe_res_val_o = x_val_d2;
endmodule

You must admit that it immediately became clear what is happening here: at what clock do the data at the input and output turn out to be valid?
A couple of comments:
- It would be nice to add reset to this example so that it resets x_val_d1 / d2 .
- Despite the fact that the data is invalid, their adders still add and put the data into registers. On the other hand, it could be allowed to save to registers only when the data is valid. In this example, saving invalid data does not lead to anything bad: I did not add work permission. However, if there is a need to optimize for power consumption, then you will have to add such signals and simply do not drive current :).
Think about the sender and receiver of data
Most often during development it is immediately clear that it is necessary to build a conveyor to achieve the desired frequency. When a pipeline is written from scratch, you need to think about the architecture, for example, decide when you can send data to the pipeline. As an illustration, I will give a typical architecture of an Ethernet packet processing pipeline.

Legend:
- fifo_0 , fifo_1 - fifos for placing the packet data. This example assumes that before starting to read from fifo_0, the entire packet is already placed there, and the logic behind fifo_1 does not require a whole packet to start processing.
- arb - arbiter that decides when to read data from fifo_0 and input the module A . Subtraction is done by setting the rd_req signal (read request).
- A , B , C - abstract modules that form a conveyor chain. It is not necessary at all that each module processes the data in one clock cycle. Modules inside can also be pipelined. They do some processing of the packet, for example, form a parser system or modify the packet (for example, they substitute the source or destination MAC addresses).
In this example, fifo_0 is the sender of the data, and fifo_1 is the receiver. Suppose that for some reason data is not always read from fifo_1 or the data reading speed is less than the write speed, as a result, this FIFO can overflow. You don’t need to write in full fifos, because at least you will break the package (some data set may disappear from the package) and transfer it incorrectly.
What can fifo say?
- used_words - the number of words used. Knowing the size of Fifoshka, you can calculate the number of free words. In this example, we assume that one word is equal to one byte.
- full and almost_full - signals that the Fifo is already full, or “almost” is full . “Almost” is determined by the custom border of the words used.
In order not to break the data, we need sometime not to read the packet data from fifo_0 and to suspend the operation of the pipeline. How to do it?
Forehead algorithm
Let's say we allocated fifo_1 for MTU, for example, 1500 bytes. Before starting to read a packet from fifo_0, arb looks at the number of free bytes in fifo_1 . If it is larger than the size of the current package, then set rd_req and do not remove until the end of the package. Otherwise, we wait until Fifo is free.
Pros:
- Arbitration is relatively simple and quick.
- Less boundary conditions for verification.
Minuses:
- fifo_1 must be allocated under MTU. And if you have MTU 64K, then a couple of such Fifo will eat half-FPGA for you) Sometimes you can’t do without Fifo for a package, but it’s better to save resources.
- If the conveyor is idle, because Since there is not enough space for the whole package, we lose performance. More precisely, the worst case (overflow of fifo_0 , in which someone puts packets too) comes faster.
Note:
When calculating free space, you need to make a margin on the length of the conveyor. For example, right now at fifo_1 there are 100 bytes free, a packet of 95 bytes has come to us. We look that 100 is more than 95 and we begin to forward a packet. This is not entirely true, because we don’t know the current state of the pipeline - if we process the previous packet, then in the worst case, fifo_1 will additionally record additional words in the amount of pipeline length (in ticks). If the pipeline runs 10 clock cycles, then another 10 words will fall into fifo_1 , and Fifo can overflow when we write a packet of 95 bytes.
Improving the "forehead algorithm"
We reserve in fifo_1 the number of words equal to the length of the assembly line. We use the signal almost_full .
The arbiter looks at this signal every beat. If it is 0, then we subtract one word of the package, otherwise - no.
Pros:
- fifo_1 may not be very large, for example, a couple of dozen words.
Minuses:
- Modules A , B , C should be prepared for the fact that the packet will arrive not every step, but in parts. More formally: the validity signal inside the packet may be interrupted.
- More boundary conditions need to be checked.
- If new stages of the pipeline are added (therefore, its length increases), then you can forget to reduce the upper limit to fifo_1 . Or it is necessary to somehow calculate this boundary as a parameter, which can be nontrivial.
Stop conveyor during operation
The previous options have a common feature: if the packet word got to the beginning of the pipeline, then there’s nothing to be done: after a constant number of ticks this word (or its modification) will fall into fifo_1 .
An alternative is that the conveyor can be stopped during operation. For each stage with the number M, the ready input appears , which indicates whether stage M + 1 is ready to receive data or not. The inversion of full or almost_full (if you want to play it safe a bit) is started at the entrance of the very last stage .

Pros :
- You can safely add new conveyor stages.
- Each stage may now have nuances in the work, but there is no need to redo the architecture. For example: we wanted to add some kind of VLAN-tag to the package before putting the package in fifo_1 . The VLAN tag is 4 bytes, in our case 4 words. If the packets go one after another, then in the first two cases, arb should have understood that after the end of the packet it is necessary to pause 4 measures, because the package will increase by 4 words. In this case, everything will be adjusted by itself and the module that inserts the VLAN at the time of its insertion will set ready , equal to zero, to the stage of the pipeline that stands in front of it.
Minuses:
- The code is getting more complicated.
- During verification, it is necessary to check even more boundary conditions.
- Most likely it takes more resources than previous options.
Use standardized interfaces
The above problems can be resolved using interfaces that already have auxiliary signals. Altera for data streams suggests using the Avalon Streaming interface ( Avalon-ST ). A detailed description can be found here . By the way, it is this interface that is used in the Alterov 10G / 40G / 100G Ethernet MAC cores.

The presence of valid and ready signals , which we spoke about earlier, attracts attention immediately . The empty signal indicates the number of free (unused) bytes in the last word of the packet. Signals startofpacket and endofpacketdetermine the beginning and end of the package: it is convenient to use these signals to reset various counters, which count offsets to extract the necessary data.
Xilinx suggests using AXI4-Stream for these purposes.

In general, the set of signals is similar (in this picture, not all signals that are possible in this standard). To be honest, I never used AXI4-Stream. If someone used both interfaces, I would be grateful if you share the comparison and impressions.
I think the advantages of using standard interfaces do not need to be mentioned. Well, the cons are obvious: you must comply with the standard, which is expressed in b aboutwith more code, resources, tests, etc. Of course, you can make your own bikes, but in the long run on a large project (and top-end chips) it can come out sideways.
Bonus
As an example, more complicated than a couple of adders, I propose to make a module that swaps the source and destination MAC addresses ( mac_src and mac_dst ) in an Ethernet packet . This can be useful if there is a desire to send all the traffic that comes to the device back (the so-called traffic inversion / loopback or loopback). The implementation, of course, must be done by the conveyor.
We use the Avalon-ST interface with a 64-bit data bus (for 10G) without ready and error signals . As a test package, take the one that looked at xgmii in a previous article . Then:
- mac_dst - 00: 21: CE: AA: BB: CC (bytes 0 through 5). Located in 0 word in bytes 7: 2.
- mac_src - 00: 22: 15: BF: 55: 62 (bytes 6 through 11). It is located in 0 word in bytes 1: 0 and in 1 word in bytes 7: 4.
Code on SystemVerilog under the spoiler:
Hidden text
module loop_l2(
input clk_i,
input rst_i,
input [7:0][7:0] data_i,
input startofpacket_i,
input endofpacket_i,
input [2:0] empty_i,
input valid_i,
output logic [7:0][7:0] data_o,
output logic startofpacket_o,
output logic endofpacket_o,
output logic [2:0] empty_o,
output logic valid_o
);
logic [7:0][7:0] data_d1;
logic startofpacket_d1;
logic endofpacket_d1;
logic [2:0] empty_d1;
logic valid_d1;
logic [7:0][7:0] data_d2;
logic [7:0][7:0] new_data_c;
always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
begin
data_d1 <= '0;
startofpacket_d1 <= '0;
endofpacket_d1 <= '0;
empty_d1 <= '0;
valid_d1 <= '0;
data_o <= '0;
startofpacket_o <= '0;
endofpacket_o <= '0;
empty_o <= '0;
valid_o <= '0;
data_d2 <= '0;
end
else
begin
data_d1 <= data_i;
startofpacket_d1 <= startofpacket_i;
endofpacket_d1 <= endofpacket_i;
empty_d1 <= empty_i;
valid_d1 <= valid_i;
data_o <= new_data_c;
startofpacket_o <= startofpacket_d1;
endofpacket_o <= endofpacket_d1;
empty_o <= empty_d1;
valid_o <= valid_d1;
data_d2 <= data_d1;
end
always_comb
begin
new_data_c = data_d1;
if( startofpacket_d1 )
begin
new_data_c = { data_d1[1:0], data_i[7:4], data_d1[7:6] };
end
else
if( startofpacket_o )
begin
new_data_c[7:4] = data_d2[5:2];
end
end
endmodule
Not everything is as scary as it might have seemed: most of the lines went into the description of the module I / O and the delay line. By startofpacket we determine in which word we are and what data should be substituted into the combination new_data_c , which then latches into data_o . The signals startofpacket , endofpacket , empty , valid are delayed by the required number of clock cycles.
Module simulation: As you can see, the MAC addresses are reversed, and all other data in the packet has not changed. In the next article we will analyze the quad tree

: a more serious example of pipelining, where we use one of the architectural features of FPGA - block memory.
Thank you for your time and attention! If you have questions, ask without a doubt.
List of references
- Advanced FPGA Design is one of the best FPGA books I've seen. Chapter 1 describes in detail pipelining. IMHO, a book for those who have already gained some experience in FPGA development and want to systematize their knowledge or some kind of intuitive guesses.
- TimeQuest Timing Analyzer is an application for evaluating the value of timings (including Fmax ) for Altera FPGAs.
PS Thanks to des333 for constructive criticism and advice.