Talk for Hadoop
- Tutorial

Introduction
As a person with a not very stable psyche, I just need one look at a picture like this to start a panic attack. But I decided that I would suffer only myself. The goal of the article is to make Hadoop not look so scary.
What will be in this article:
- We will analyze what the framework consists of and why it is needed;
- Let us examine the issue of painless cluster deployment;
- look at a specific example;
- a little touch on the new features of Hadoop 2 (Namenode Federation, Map / Reduce v2).
What will not be in this article:
- in general, the review article, therefore, without difficulties;
- let's not go into the subtleties of the ecosystem;
- Let's not dig deep into the jungle of the API;
- we will not consider everything about devops problems.
What is Hadoop and why is it needed
Hadoop is not so complicated, the kernel consists of an HDFS file system and a MapReduce framework for processing data from this file system.
If you look at the question “why do we need Hadoop?” from the point of view of use in a large enterprise, there are a lot of answers, and they vary from “strongly for” to “very against”. I recommend viewing the ThoughtWorks article .
If you look at the same question from a technical point of view - for what tasks we need to use Hadoop - here, too, is not so simple. In the manuals, first of all, two main examples are understood: word count and log analysis. Well, what if I don't have a word count or log analysis?
It would be nice to determine the answer somehow simply. For example, SQL - you need to use it if you have a lot of structured data and you really want to talk to the data. Ask as many questions as possible in advance of an unknown nature and format.
The long answer is to look at a number of existing solutions and collect implicitly in the subcortex the conditions for which Hadoop is needed. You can poke around on blogs, I can also advise you to read the book by Mahmoud Parsian "Data Algorithms: Recipes for Scaling up with Hadoop and Spark" .
I’ll try to answer in short. Hadoop should be used if:
- Computations must be composable, in other words, you should be able to run the calculations on a subset of the data, and then merge the results.
- You plan to process a large amount of unstructured data - more than you can fit on one machine (> several terabytes of data). A plus here will be the ability to use commodity hardware for the cluster in the case of Hadoop.
Hadoop should not be used:
- For noncomponent tasks - for example, for recurrent tasks.
- If the entire amount of data fits on one machine. Save significant time and resources.
- Hadoop as a whole is a system for batch processing and is not suitable for real-time analysis (the Storm system comes to the rescue here ).
HDFS architecture and typical Hadoop cluster
HDFS is similar to other traditional file systems: files are stored in blocks, there is mapping between blocks and file names, a tree structure is supported, a rights-based file access model is supported, etc.
HDFS differences:
- Designed to store a large number of huge (> 10GB) files. One consequence is the large block size compared to other file systems (> 64MB)
- Optimized to support streaming data access (high-streaming read), respectively, the performance of random data read operations begins to limp.
- It is focused on the use of a large number of inexpensive servers. In particular, servers use the JBOB structure (Just a bunch of disk) instead of RAID - mirroring and replication are performed at the cluster level, and not at the level of an individual machine.
- Many of the traditional problems of distributed systems are embedded in the design - by default, all the failure of individual nodes is completely normal and natural operation, and not something out of the ordinary.
A Hadoop cluster consists of three types of nodes: NameNode, Secondary NameNode, Datanode.
Namenode is the brain of the system. As a rule, one node per cluster (more in the case of Namenode Federation, but we leave this case overboard). It stores all the system metadata - directly mapping between files and blocks. If node 1 then it is also Single Point of Failure. This issue was resolved in the second version of Hadoop using Namenode Federation .
Secondary NameNode- 1 node per cluster. It is customary to say that “Secondary NameNode” is one of the most unfortunate names in the history of programs. Indeed, Secondary NameNode is not a replica of NameNode. The state of the file system is stored directly in the fsimage file and in the edits log file containing the latest changes to the file system (similar to the transaction log in the RDBMS world). Secondary NameNode works by periodically merging fsimage and edits - Secondary NameNode maintains the size of edits within reasonable limits. Secondary NameNode is necessary for quick manual recovery of NameNode in case of failure of NameNode.
In a real cluster, NameNode and Secondary NameNode are separate servers that require memory and hard disk. And the claimed “commodity hardware” is already a case of DataNode.
Datanode- There are a lot of such nodes in the cluster. They store blocks of files directly. The node regularly sends NameNode its status (indicates that it is still alive) and hourly - a report, information about all the blocks stored on this node. This is necessary to maintain the desired level of replication.
Let's see how data is recorded in HDFS:
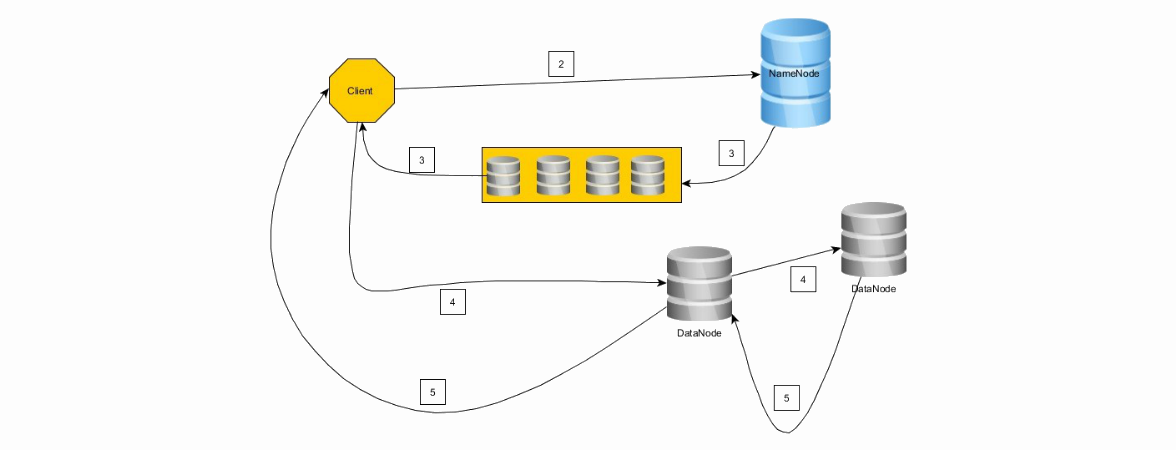
1. The client cuts the file into block-size chains.
2. The client connects to the NameNode and requests a write operation, sending the number of blocks and the required replication level
3. NameNode responds with a chain of DataNode.
4. The client connects to the first node from the chain (if it did not work out with the first, the second one, etc. did not work out at all - rollback). The client records the first block on the first note, the first note on the second, etc.
5. Upon completion of the recording in the reverse order (4 -> 3, 3 -> 2, 2 -> 1, 1 -> the client) messages are sent about the successful recording.
6. As soon as the client receives confirmation of the successful recording of the block, it notifies the NameNode of the recording of the block, then receives a chain of DataNode for writing the second block, etc.
The client continues to write blocks if it succeeds in successfully writing a block to at least one node, that is, replication will work according to the well-known principle of “eventual”, in the future NameNode will compensate and achieve the desired level of replication.
Concluding our review of HDFS and the cluster, we’ll look at another great feature of Hadoop, rack awareness. The cluster can be configured so that NameNode has an idea which nodes are on which racks.protection against failures .
Mapreduce
The unit of work is a set of map (parallel data processing) and reduce (combining conclusions from map) tasks. Map tasks are performed by mappers, reduce by reducers. Job consists of at least one mapper, reducers are optional. Here the question of splitting the task into maps and reduce is discussed. If the words “map” and “reduce” are completely incomprehensible to you, you can see a classic article on this topic.
MapReduce Model
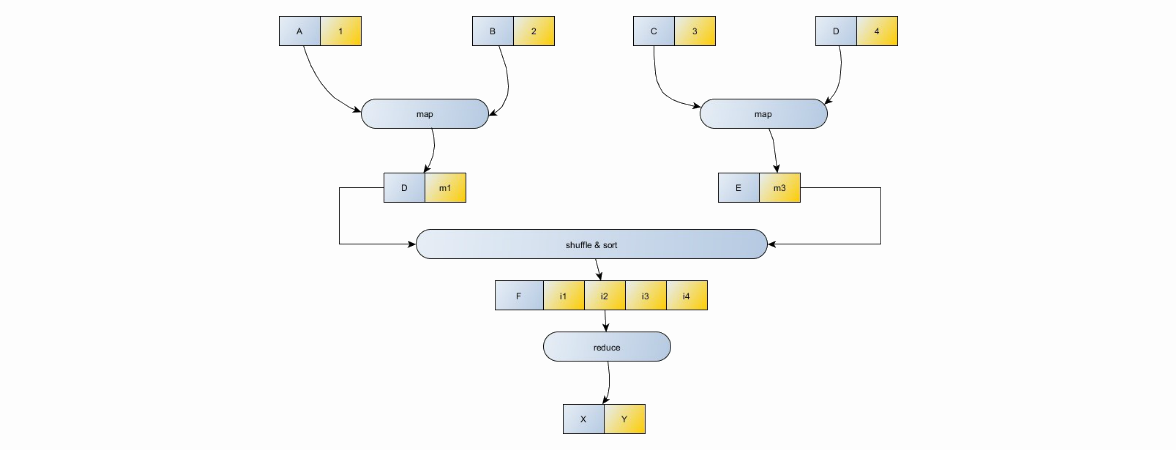
- Data input / output occurs in the form of pairs (key, value)
- Two map functions are used: (K1, V1) -> ((K2, V2), (K3, V3), ...) - mapping a key-value pair to a certain set of intermediate pairs of keys and values, as well as reduce: (K1 , (V2, V3, V4, VN)) -> (K1, V1), which maps a certain set of values, having a common key to a smaller set of values.
- Shuffle and sort is needed to sort input in reducer by key, in other words, it makes no sense to send the value (K1, V1) and (K1, V2) to two different reducers. They must be processed together.
Let's look at the architecture of MapReduce 1. To begin with, let's expand the idea of a hadoop cluster by adding two new elements to the cluster - JobTracker and TaskTracker. JobTracker directly requests from clients and manages map / reduce tasks on TaskTrackers. JobTracker and NameNode are distributed on different machines, while DataNode and TaskTracker are on the same machine.
The interaction between the client and the cluster is as follows:
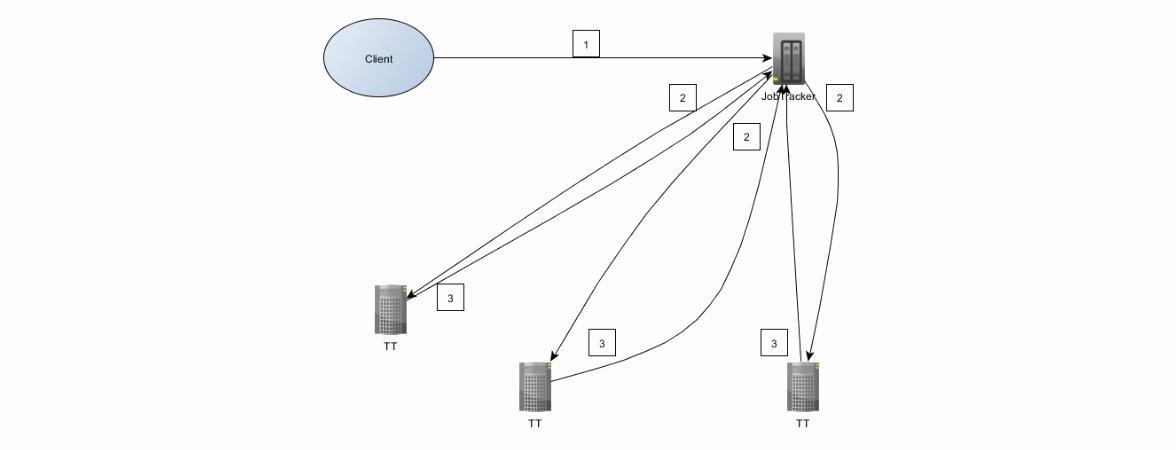
1. The client sends the job to JobTracker. Job is a jar file.
2. JobTracker searches for TaskTrackers taking into account the locality of the data, i.e. preferring those that already store data from HDFS. JobTracker assigns map and reduce tasks to TaskTrackers
3. TaskTrackers send a progress report to JobTrackers.
Unsuccessful task execution - expected behavior, failed tasks will automatically restart on other machines.
Map / Reduce 2 (Apache YARN) no longer uses JobTracker / TaskTracker terminology. JobTracker is divided into ResourceManager - resource management and Application Master - application management (one of which is MapReduce directly). MapReduce v2 uses the new API
Environment setting
There are several different Hadoop distributions on the market: Cloudera, HortonWorks, MapR - in order of popularity. However, we will not focus on the choice of a particular distribution. A detailed analysis of distributions can be found here .
There are two ways to try Hadoop painlessly and with minimal labor:
1. Amazon Cluster is a full-fledged cluster, but this option will cost money.
2. Download the virtual machine ( manual number 1 or manual number 2 ). In this case, the minus will be that all cluster servers are spinning on the same machine.
Let's move on to painful methods. Hadoop first version on Windows will require the installation of Cygwin. A plus here will be excellent integration with development environments (IntellijIDEA and Eclipse). More in this wonderful manual .
Starting with the second version, Hadoop also supports Windows server editions. However, I would not advise trying to use Hadoop and Windows not only in production, but generally somewhere outside the developer's computer, although there are special distributions for this . Windows 7 and 8 currently do not support vendors, but people who love the challenge can try to do it by hand .
I also note that for fans of Spring there is a framework for Spring for Apache Hadoop .
We will go easy and install Hadoop on a virtual machine. To get started, download the CDH-5.1 distribution kit for the virtual machine (VMWare or VirtualBox). The size of the distribution is about 3.5 GB. Download, unpack, load into VM and that’s all. We have everything. It's time to write your favorite WordCount!
Specific example
We will need a data sample. I suggest downloading any dictionary for bruteforce'a passwords. My file will be called john.txt.
Now open Eclipse, and we already have a pre-created training project. The project already contains all the necessary libraries for development. Let's throw out all the code carefully laid out by the guys from Clouder and copy-paste the following:
package com.hadoop.wordcount;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
We get something like this:
At the root of the training project, add the john.txt mail via the File -> New File menu. Result:
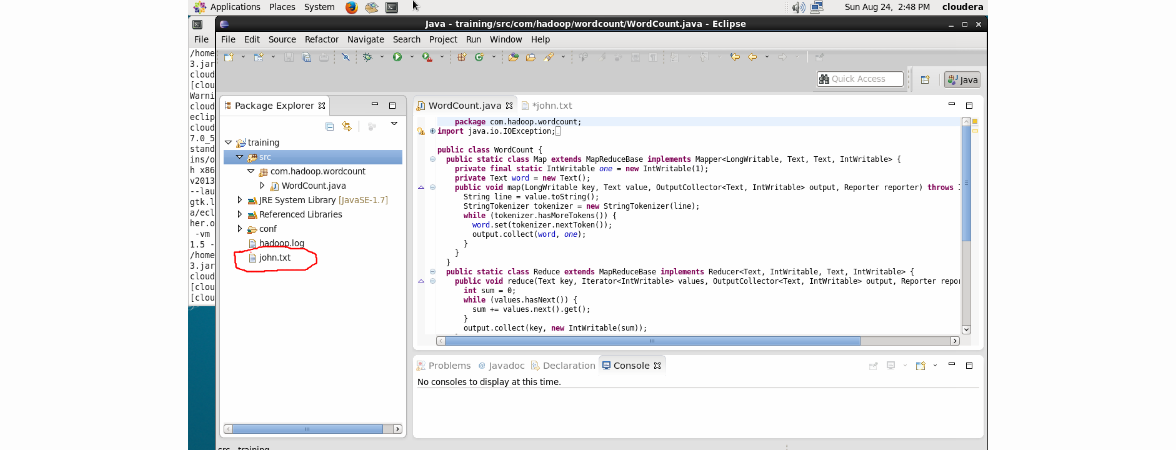
Click Run -> Edit Configurations and enter input.txt and output respectively as Program Arguments.
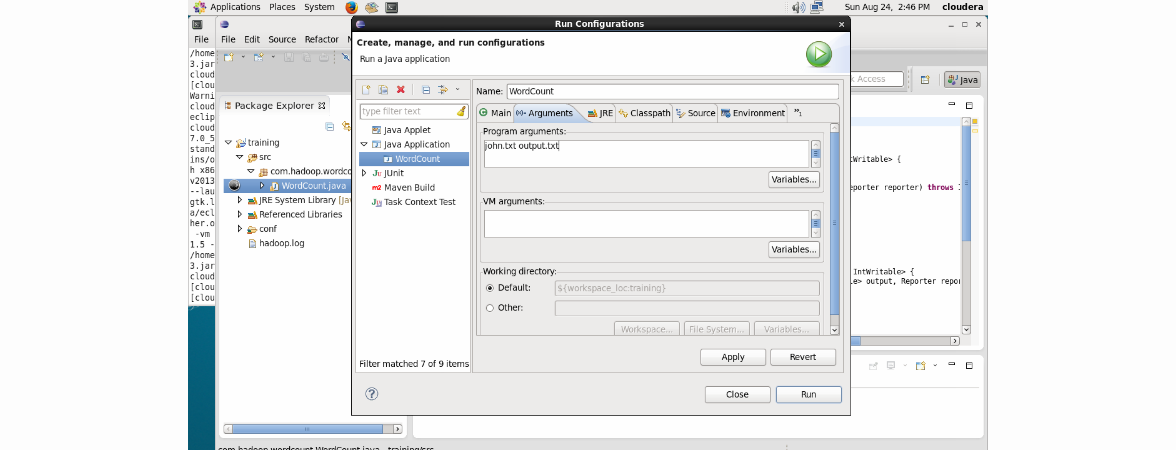
Click Apply and then Run. The work will be successfully completed:
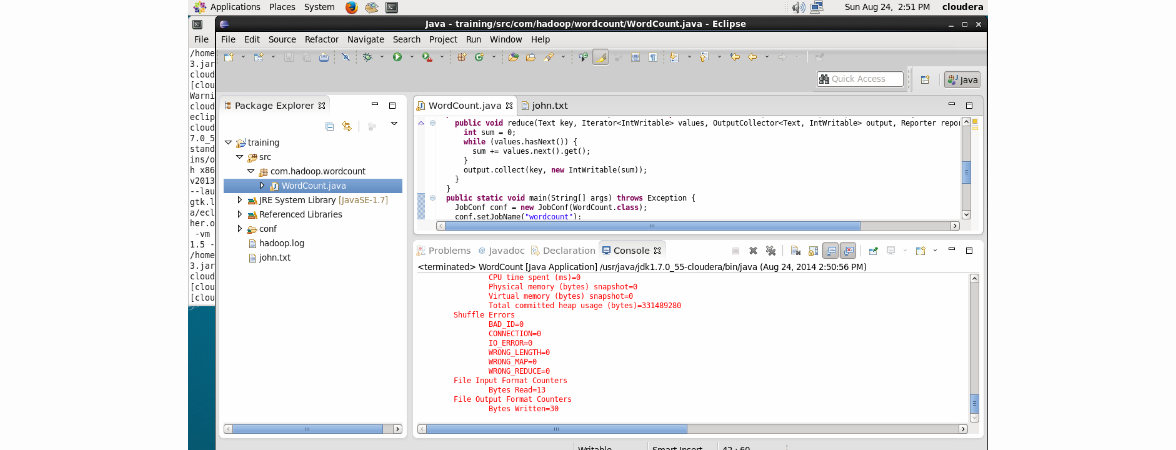
And where are the results? To do this, we update the project in Eclipse (using the F5 button):
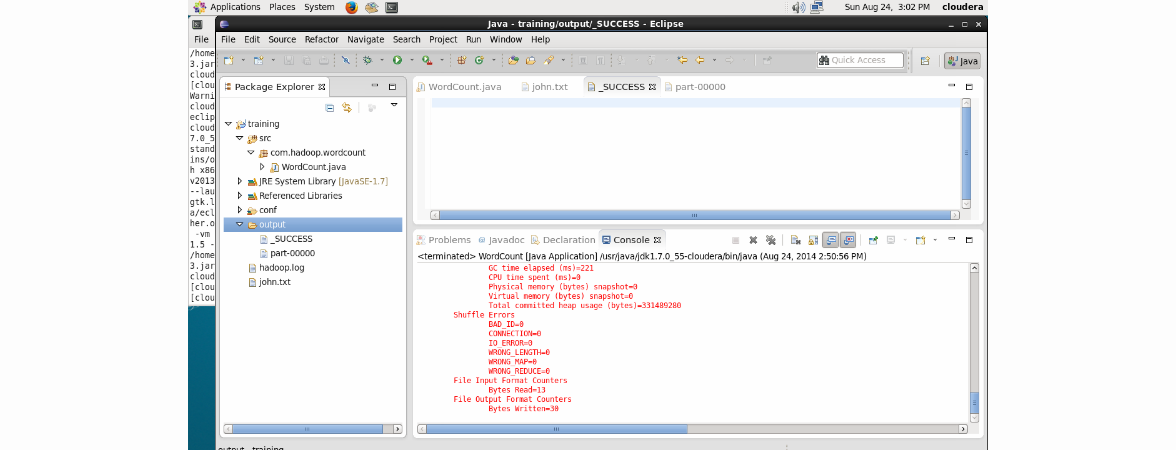
In the output folder, you can see two files: _SUCCESS, which says that the work was successful, and part-00000 directly with the results.
This code, of course, can be debited, etc. We conclude the conversation with a review of unit tests. Actually, while for writing unit tests in Hadoop there is only the MRUnit framework (https://mrunit.apache.org/), it is late for Hadoop: versions up to 2.3.0 are now supported, although the latest stable version of Hadoop is 2.5.0
Ecosystem Blitz: Hive, Pig, Oozie, Sqoop, Flume
In a nutshell and about everything.
Hive & Pig . In most cases, writing Map / Reduce jobs in pure Java is too time-consuming and unbearable, meaningful, as a rule, only to pull out all the possible performance. Hive and Pig are two tools for this case. Hive love on Facebook, Pig love Yahoo. Hive has an SQL-like syntax ( similarities and differences with SQL-92 ). Many people with experience in business analysis and DBA have moved to Big Data camp - for them, Hive is often a tool of choice. Pig focuses on ETL.
Oozie is a workflow engine for jobs. Allows you to build jobs on different platforms: Java, Hive, Pig, etc.
Finally, frameworks that provide direct data entry into the system. Quite short. Sqoop- integration with structured data (RDBMS), Flume - with unstructured.
Review of literature and video courses
There are not so many literature on Hadoop yet. As for the second version, I came across only one book that would concentrate specifically on it - Hadoop 2 Essentials: An End-to-End Approach . Unfortunately, the book did not get in electronic format, and it did not work out.
I do not consider literature on the individual components of the ecosystem - Hive, Pig, Sqoop - because it is somewhat outdated, and most importantly, such books are unlikely to be read from cover to cover, rather, they will be used as a reference guide. And even then you can always get by with the documentation.
Hadoop: The Definitive Guide- The book is in the top of Amazon and has many positive reviews. The material is obsolete: 2012 and describes Hadoop 1. There are many positive reviews and a fairly wide coverage of the entire ecosystem.
Lublinskiy B. Professional Hadoop Solution is a book from which much material has been taken for this article. Somewhat complicated, but a lot of real practical examples — attention is paid to the specific nuances of constructing solutions. Much nicer than just reading the product features description.
Sammer E. Hadoop Operations- About half of the book is dedicated to the description of the Hadoop configuration. Given the 2012 book, it will become obsolete very soon. It is intended primarily, of course, for devOps. But I am of the opinion that it is impossible to understand and feel the system if it is only developed and not exploited. The book seemed useful to me due to the fact that the standard problems of backup, monitoring and cluster benchmarking were reviewed.
Parsian M. “Data Algorithms: Recipes for Scaling up with Hadoop and Spark” - the main focus is on the design of Map-Reduce applications. Strong bias in the scientific direction. Useful for a comprehensive and deep understanding and application of MapReduce.
Owens J. Hadoop Real World Solutions Cookbook- Like many other Packt books with the word “Cookbook” in the title, this is technical documentation that has been cut into questions and answers. This is also not so simple. Try it yourself. It is worth reading for a broad overview, well, and used as a reference.
It is worth paying attention to two video courses from O'Reilly.
Learning Hadoop - 8 hours. It seemed too superficial. But for me, some added value. materials, because I want to play with Hadoop, but I need some live data. And here he is - a wonderful data source.
Building Hadoop Clusters - 2.5 hours. As you can see from the title, here is the emphasis on building clusters on Amazon. I really liked the course - short and clear.
I hope that my modest contribution will help those who are just starting to learn Hadoop.