How to make binary classifier work a little better
Disclaimer: a post written based on this . I suspect that most readers are well aware of how the Naive Bayes classifier works, so I suggest that you only glimpse at least what it says before moving on to Cat.
Solving problems using machine learning algorithms has long and firmly entered our lives. This happened for all obvious and objective reasons: cheaper, easier, faster than explicitly encoding an algorithm for solving each individual problem. Usually, “black boxes” of classifiers reach us (it is unlikely that the same VK will offer you its corpus of marked-up names), which does not allow them to be fully managed.
Here I would like to talk about how to try to achieve the “best” results of the binary classifier, what characteristics the binary classifier has, how to measure them, and how to determine that the result of the work has become “better”.
Theory. Short course
1. Binary classification
Let be a set of objects,
a set of objects, 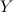 a finite set of classes. Classify object - use mapping
a finite set of classes. Classify object - use mapping  . When
. When  , such a classification is called binary , because we have only 2 options at the output. For simplicity, we will continue to assume that
, such a classification is called binary , because we have only 2 options at the output. For simplicity, we will continue to assume that  , since absolutely any binary classification problem can be brought to this. Usually , the result of mapping an object to a class is a real number, and if it is above a given threshold , then the object is classified as positive , and its class is 1.
, since absolutely any binary classification problem can be brought to this. Usually , the result of mapping an object to a class is a real number, and if it is above a given threshold , then the object is classified as positive , and its class is 1.2. The contingency table of the binary classifier
Obviously, the predicted class of the object obtained as a result of the mapping can either coincide in the real class or not. Total 4 options in total. This is very clearly demonstrated by this plate:
can either coincide in the real class or not. Total 4 options in total. This is very clearly demonstrated by this plate: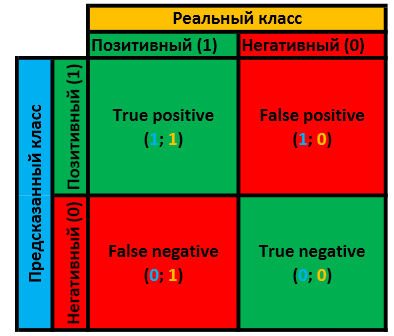
If we know the quantitative values of each of the estimates, we know everything that can be about this classifier and we can dig further.
(I intentionally do not use terms such as “error of the first kind”, because it seems to me unobvious and unnecessary)
Next, we will use the following notation:
 - the number of True Positive results in this sample.
- the number of True Positive results in this sample. - the number of True Negative results in this sample.
- the number of True Negative results in this sample. - the number of False Positive results in this sample.
- the number of False Positive results in this sample. - the number of False Negative results in this sample.
- the number of False Negative results in this sample.
3. Characteristics of the binary classifier
Precision - shows how many of the predicted positive objects turned out to be really positive.
Completeness (recall) - shows how much of the total number of real positive objects was predicted as a positive class.

These two characteristics are fundamental to any binary classifier. Which of the characteristics is more important - it all depends on the task. For example, if we want to create a “school search engine”, then it will be in our interests to remove “non-childish” content from the content, and here completeness is more important than accuracy. In the case of determining the gender of a name, accuracy rather than completeness is more interesting to us.
F-measure (F-measure) - a characteristic that allows you to give an assessment at the same time for accuracy and completeness.
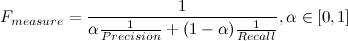
Coefficient
 sets the ratio of precision and completeness weights. When
sets the ratio of precision and completeness weights. When  , the F-measure gives equal weight to both characteristics. Such an F-measure is called balanced, or
, the F-measure gives equal weight to both characteristics. Such an F-measure is called balanced, or 

False Positive Rate (
 ) - shows how many of the total number of real negative objects turned out to be incorrectly predicted.
) - shows how many of the total number of real negative objects turned out to be incorrectly predicted.
4. ROC curve and its AUC
ROC-curve - a graph that allows you to evaluate the quality of the binary classification. The graph shows the dependence of TPR (completeness) on FPR when varying the threshold. At the point (0,0), the threshold is minimal, and so are TPR and FPR . An ideal case for the classifier is the passage of the graph through the point (0,1). Obviously, the graph of this function always does not decrease monotonously.
AUC (Area Under Curve) - this term (the area under the graph) gives a quantitative characteristic of the ROC curve: the more the better. AUC - equivalent to the probability that the classifier assigns a greater value to a randomly selected positive object than a randomly selected negative object. That is why it was previously said that, usually , the positive class is rated higher than the negative.
When AUC = 0.5 , then this classifier is equal to random. If AUC <0.5 , then you can simply flip the returned values by the classifier.
Cross validation
There are many cross validation methods (evaluating the quality of a binary classifier), and this is a topic for a separate article. Here, I just want to consider one of the most popular methods to understand how this thing generally works, and why it is needed.You can, of course, build a ROC curve from any sample. However, the ROC curve constructed from the training set will be shifted left-up due to overfitting. To avoid this and get the most objective assessment, cross validation is used.
K-fold cross validation - the pool is divided into k folds, then each fold is used for the test, while the remaining k-1 folds are used for training. K valuemay be arbitrary. In this case, I used it equal to 10. For the given classifier of the name gender, the following AUC results were obtained (get_features_simple - one significant letter, get_features_complex - 3 significant letters)
| fold | get_features_simple | get_features_complex |
| 0 | 0.978011 | 0.962733 |
| 1 | 0.96791 | 0.944097 |
| 2 | 0.963462 | 0.966129 |
| 3 | 0.966339 | 0.948452 |
| 4 | 0.946586 | 0.945479 |
| 5 | 0.949849 | 0.989648 |
| 6 | 0.959984 | 0.943266 |
| 7 | 0.979036 | 0.958863 |
| 8 | 0.986469 | 0.951975 |
| 9 | 0.962057 | 0.980921 |
| avg | 0.9659703 | 0.9591563 |
Practice
1. Preparation
The whole repository is here .I took the same marked-up file and replaced “m” with 1 in it, “f” - 0. We will use this pool for training, like the author of the previous article. Armed with the first page of issuing my favorite search engine and awk, I riveted a list of names that were not in the original. This pool will be used for the test.
Changed the classification function so that it returns the probabilities of the positive and negative classes, and not the logarithmic indicators.
Classification function
def classify2(classifier, feats):
classes, prob = classifier
class_res = dict()
for i, item in enumerate(classes.keys()):
value = -log(classes[item]) + sum(-log(prob.get((item, feat), 10**(-7))) for feat in feats)
if (item is not None):
class_res[item] = value
eps = 709.0
posVal = '1'
negVal = '0'
posProb = negProb = 0
if (abs(class_res[posVal] - class_res[negVal]) < eps):
posProb = 1.0 / (1.0 + exp(class_res[posVal] - class_res[negVal]))
negProb = 1.0 / (1.0 + exp(class_res[negVal] - class_res[posVal]))
else:
if class_res[posVal] > class_res[negVal]:
posProb = 0.0
negProb = 1.0
else:
posProb = 1.0
negProb = 0.0
return str(posProb) + '\t' + str(negProb)
2. Implementation and use
As the title says, my task was to make the binary classifier work better than it works by default. In this case, we want to learn how to determine the gender of a name, better than the probability of Naive Bayes 0.5. For this, this simplest utility was written. It is written in C ++, because gcc is everywhere. The implementation itself does not seem to be anything interesting. With the key -? or --help you can read the help, I tried to describe it as detailed as possible.Well, now, in fact, what we were going to: the assessment of the classifier and its tuning. The output of nbc.pycreates a sheet from files with classification results, I use them directly later. For our purposes, we will clearly see graphs of accuracy from the threshold, completeness from the threshold and F-measures from the threshold. They can be constructed as follows:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y prc -p plot_test_thr_prc_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y tpr -p plot_test_thr_tpr_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_simple.txt
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple -x thr -y fms -p plot_test_thr_fms_0.7_simple.txt -a 0.7For educational purposes, I made 2 F-measure graphs from the threshold, with different weights. The second weight was chosen 0.7, because in our problem we are more interested in accuracy than completeness. The default chart is based on 10,000 different points, this is a lot for such simple data, but these are uninteresting subtleties of optimization. In the same way, having plotted the graph data for get_features_complex, we get the following results:




From the graphs, it becomes obvious that the classifier does not show the best results at a threshold of 0.5. The graph of the F-measure clearly demonstrates that the “complex feature” gives the best result on the entire variation of the threshold. This is quite logical, considering that it’s “difficult”. We obtain the threshold values at which the F-measure reaches a maximum:
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_simple --target fms --argument thr --argval 0
Optimal threshold = 0.8 Target function = 0.911937 Argument = 0.8
$ ./OptimalThresholdFinder -A 3 -P 1 < names_test_pool.txt_complex --target fms --argument thr --argval 0
Optimal threshold = 0.716068 Target function = 0.908738 Argument = 0.716068Conclusion
With these simple manipulations, we were able to select the optimal Naive Bayes threshold to determine the gender of the name, which works better than the default threshold. This raises the reasonable question, how did we determine that it works “better”? I have mentioned more than once that accuracy is more important to us in this task than completeness, but the question of how important it is is very, very difficult, so a balanced F-measure was used to evaluate the classifier, which in this case can be an objective indicator quality.What is much more interesting, the results of the binary classifier based on the “simple” and “complex” features turned out to be approximately the same, differing in the value of the optimal threshold.