Page cache, or how RAM and files are related
- Transfer
- Recovery mode

Earlier, we got acquainted with how the kernel manages the virtual memory of the process, but we omitted the work with files and input / output. In this article, we will consider an important and often misleading question about what is the relationship between RAM and file operations, and how it affects system performance.
As for working with files, here the operating system should solve two important problems. The first problem is the surprisingly low speed of hard drives ( especially search operations ) compared to the speed of RAM. The second problem is the ability to share once a file loaded into RAM by different programs. Taking a look at processes using Process Explorer, we will see that about 15 MB of RAM in each process is spent on shared DLLs. There are currently 100 processes running on my computer, and if there wasn’t the possibility of sharing files in memory, about 1.5 GB of memory would be spent only on shared DLLs . This, of course, is unacceptable. On Linux, programs also use shared libraries like ld.so, libc, and others.
Fortunately, both problems can be solved, as they say, in one fell swoop - using the page cache . The page cache is used by the kernel to store fragments of files, each fragment being one page in size. In order to better illustrate the idea of a page cache, I came up with a program called render, which opens the scene.dat file , reads it in portions of 512 bytes and copies them to the allocated space on the heap. The first read operation will be performed as shown in the figure above.
After 12 KB has been read, a bunch of the render process and related physical pages will look like this:

It seems that everything is simple, but in reality everything, a lot of things are happening. Firstly, even though our program uses the usual read () calls, as a result of their execution, the page cache will contain three 4-kilobyte pages with the contents of the scene.dat file. Many are surprised, but all standard file I / O operations work through the page cache.. On Linux on the x86 platform, the kernel presents the file as a sequence of 4 kilobyte fragments. If you request to read only one byte from the file, this will lead to the fact that the 4-kilobyte fragment containing this byte will be completely read from disk and placed in the page cache. Generally speaking, this makes sense, because, firstly, the sustained disk throughput performance is quite high, and secondly, programs usually read more than one byte from a certain area of the file. The page cache knows how much space each cached fragment occupies in the file; it is pictured as # 0, # 1, etc. Windows uses 256 kilobyte fragments (called “ view ””), Which in their purpose are similar to the pages in the Linux page cache.
When using normal read operations, the data first goes to the page cache. The programmer can access the data portionwise through the buffer, and from it he copies it (in our example) to the area on the heap. This approach to business is extremely inefficient - not only the processor’s computing resources are wasted and there is a negative impact on processor caches , but there is also a waste of RAM for storing copies of the same data. If you look at the previous figure, you will see that the contents of the scene.dat file are stored in two copies at once; any new process working with this file will copy this data again. Thus, this is what we achieved - somewhat reduced the problem of latency when reading from disk, but otherwise failed completely. However, a solution to the problem exists - this is “memory-mapped files” :

When a programmer uses mapping files to memory, the kernel maps virtual pages directly to physical pages in the page cache. This allows for significant performance gains - in Windows System ProgrammingThey write about accelerating the execution time of the program by 30% or more compared to standard file I / O operations. Similar numbers, only now for Linux and Solaris, are provided in the book Advanced Programming in the Unix Environment . Using this mechanism, you can write programs that will use significantly less RAM (although much here also depends on the features of the program itself).
As always, the key to performance matters is measurement and visual results.. But even without this, mapping files to memory pays for itself. The programming interface is quite pleasant and allows you to read files like regular bytes in memory. For the sake of all the advantages of this mechanism, you don’t have to sacrifice anything special, for example, the readability of the code will not suffer in any way. As the saying goes, the flag is in your hands - don't be afraid to experiment with your address space and calling mmap on Unix-like systems, calling CreateFileMapping on Windows, as well as various wrapping functions available in high-level programming languages.
When a file is mapped to memory, its contents do not get there immediately, but gradually - as the processor catches page faultscaused by accessing fragments of the file that are not yet loaded. The handler for such a page fault will find the desired page frame in the page cache and map the virtual page into the given page frame. If the necessary data had not been cached in the page cache before, a disk read operation will be initiated.
And now, the question. Imagine that the render program completed execution, and there were no child processes left. Will pages in the page cache that contain fragments of the scene.dat file be immediately released? Many people think so - but that would be ineffective. In general, if you try to analyze the situation, this is what comes to mind: quite often we create a file in one program, it completes its execution, then the file is used in another program. The page cache should allow for such situations. And in general , why should the kernel in principle get rid of the contents of the page cache? We remember that the speed of a hard drive is five orders of magnitude slower than RAM. And if it happens that the data has already been cached, then we are very lucky. That is why nothing is deleted from the page cache, at least as long as there is free RAM. Page cache notdepends on a particular process, on the contrary - this is such a resource that the whole system shares. A week later, run render again, and if the scene.dat file is still in the page cache - well, we're in luck! This is why the size of the page cache is gradually growing, and then its growth suddenly stops. No, not because the operating system is complete garbage that eats up the entire operative. But because it should be so. Unused RAM is also a kind of wasted resource. It is better to use as much RAM as possible for the page cache than not to use it at all.
When a program makes a call to write (), the data is simply copied to the corresponding page in the page cache, and it is marked with the “dirty” flag. Recording directly to the hard disk itself does not occur immediately, and there is no point in blocking the program while waiting for the disk subsystem to become available. This behavior also has its drawback - if the computer falls into the blue screen, then the data may not get to the disk. That is why critical files, such as database transaction log files, need to be synchronized with a special call to fsync ()(but in general, there is also a cache of the hard disk controller, so here you can not be absolutely sure of the success of the write operation). The read () call, on the contrary, blocks the program until the disk is accessible and data is not read. In order to somewhat mitigate this problem, operating systems use the so-called. “Eager loading method ” , and an example of this method is “read ahead”. When read-ahead is enabled, the kernel proactively loads a certain number of file fragments into the page cache, thereby anticipating subsequent read requests. You can help the kernel with choosing the optimal parameters for read-ahead by choosing a parameter depending on how you are going to read the file - sequentially or in random order (calls madvise () , readahead () , in Windows - cache hints ). Linux uses read-ahead for memory-reflected files; I'm not sure about Windows. Finally, it is possible not to use the page cache - for it is the responsibility of flag O_DIRECT in Linux and NO_BUFFERINGon Windows databases do this quite often.
Mapping a file into memory can be of two types - either private or shared . These terms indicate only how the system will respond to data changes in RAM: in the case of shared mappings, any data changes will be flushed to disk or will be visible in other processes; in the case of private-mapping this will not happen. To implement private-mapping, the kernel relies on the copy-on-write mechanism, which is based on the specific use of records in page tables. In the following example, our render program, as well as the render3d program (and I have a talent for inventing program names!) Create private mapping for the scene.dat file. Then, render writes to the virtual memory area, which is mapped to the file:
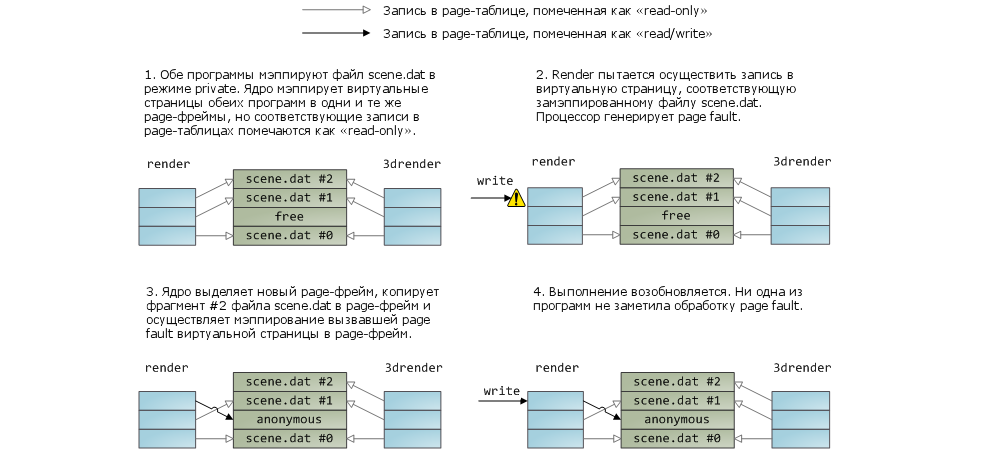
That the entries in the page tables are read-only (see the figure) should not confuse us; and this is not yetmeans that mapping will be read-only. This is just such a technique by which the kernel ensures that the page is shared between different processes and delays the need to create a copy of the page until the very last moment. Looking at the figure, you understand that the term “private” is probably not the most successful, but if you remember that it describes only the behavior when changingdata, then everything is fine. The mapping mechanism has another feature. Suppose there are two programs that are not connected by the relationship “parent process - child process”. Programs work with the same file, but they map it in different ways - in one program it is private mapping, in another it is shared mapping. So, a program with private mapping (let's call it the "first program") will see all the changes made by the second program to some page, until the first program itself tries to write something to this page(which will lead to a separate copy of the page for the first program). Those. as soon as the copy-on-write mechanism works, the changes made by other programs will not be visible. The kernel does not guarantee this behavior, but this is the case with x86 processors; and this makes some sense, even from the point of view of the same API.
As for shared mappings, things are as follows. Read / write permissions are set to pages, and they are simply mapped to the page cache. Thus, whoever makes changes to the page, all processes will see this. In addition, data is flushed to the hard drive. And finally, if the pages in the previous figure were really read-only, then the page fault caught when accessing them would entail a segmentation fault, and not a copy-on-write logic.
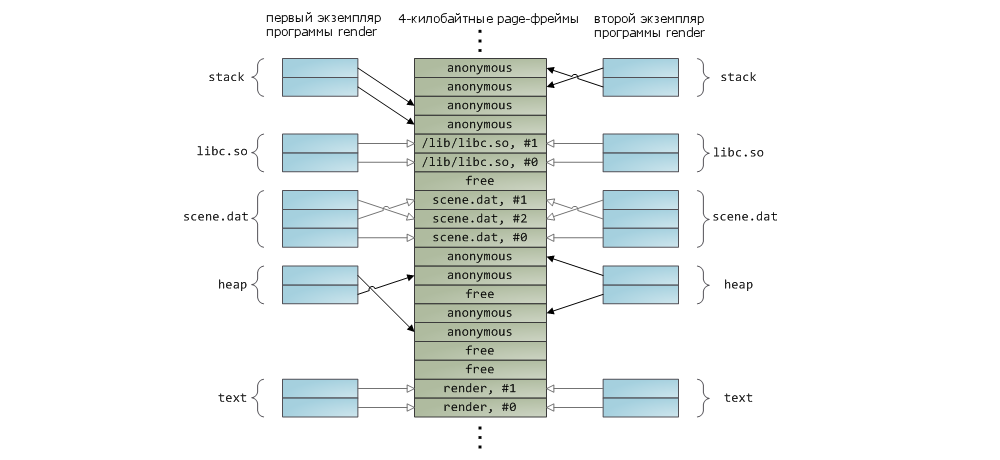
Shared libraries are also mapped to memory like any other files. This is nothing special - the same private mapping available to the programmer through an API call. The following is an example showing part of the address space of two instances of the render program using a file-to-memory mapping mechanism. In addition, the corresponding areas of physical memory are shown. Thus, we can link together those concepts that we met in this article:
This concludes our series of three articles on the basics of memory. I hope the information was useful to you and allowed me to create a general idea on this topic.
Links to articles in the series:
- Organization of process memory
habrahabr.ru/company/smart_soft/blog/185226
duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory - How the kernel manages memory
habrahabr.ru/company/smart_soft/blog/226315
duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory - Page cache, or how are RAM and files connected
habrahabr.ru/company/smart_soft/blog/227905
duartes.org/gustavo/blog/post/page-cache-the-affair-between-memory-and-files
The material was prepared by Smart-Soft employees - smart-soft.ru .