How to reduce downtime of critical systems

Work with the database: a list of JDBC connections with the connection parameters.
A company from TOP-5 in Russia earns an average of $ 7 to $ 9 million per hour. Accordingly, a technical simple two-hour length, which was reduced to one hour by an inhuman effort of will, is worth exactly this amount.
BSM is a class of systems designed specifically for those who suddenly realized that one minute in our current program is equal in price to an apartment in Moscow. And he really wants to have no downtime.
Now I’ll tell you how we implemented such systems.
An example of a purely software solution
In oil companies, for example, there is a set of software for accounting for supplies, which, in essence, is ERP. Without this component, the company’s work rises until the “underground gnomes” fix everything back.
In one such company, each technological link had its own monitoring system, and if something happened somewhere, the first interesting quest was to find a problem. He took up to half the time from each downtime. We deployed a monitoring system that made it possible to clearly find the problem. And if earlier it could take from several hours to several days to find and fix problems in the software, then the new solution significantly reduced the time to determine the root cause of the problem. The number of failures is now much smaller, the recovery time of the system also decreased.
Now the system simply shows where and what is wrong. Most often, we are talking about a specific non-responding or incorrectly responding service, which is enough to restart to continue working. I want to emphasize that in similar cases, the entire “butt-off” disappears with the search for who is responsible for the problem — instead of solving the question on which side the plug is (and this happens with many departments and contractors), you can immediately run and eliminate.
Integration with Iron
BSM systems can integrate with hardware as well. In order to illustrate the work in this case, I will talk about how BSM is installed at the airport.
So there is an airport. The critical objects in it are servers, storage systems, and in general everything that can be attributed to the class of “IT-solutions of the local data center”. But there is also, for example, a navigation system that almost with the voice of GladOS from time to time tells you where and which passenger to go to. In the event of its fall, of course, you can declare it with the voice of a living person, but it is better, of course, to avoid it - reputation, excessive panic ... Another critical system is the baggage management system. If she gets up or starts to issue baggage in the opposite direction, the entire terminal ceases to serve passengers.
Accordingly, we approach as follows:
- We carry out a full system criticality survey.
- We are looking for bottlenecks.
- We are designing a solution. In our case, for each system we need to come up with a metric that checks its operation. For example, in the case of baggage - we can connect to the baggage distribution management system and track metrics indicating interruptions or deterioration in the quality of service. In the case of working with storage systems - we just use the level of load on it for each process.
- Expand the solution itself. This is a database with patterns of “good” and “bad” behavior, a set of sensors and information collectors (both in the form of hardware and software agents), an application server, a processing server, and an alert system.
- If necessary, we configure automation at the event-response level. For example, if one of the applications stops responding, we can conduct automated diagnostics of the application and either restore the work automatically, or if the restoration of work cannot be formalized as an executable algorithm, automatically switch to another instance of the application if necessary. If the luggage tape is broken and information about this can be obtained from the appropriate control system, you can automatically call the repairman via SMS notification, initiate an incident in the HelpDesk class system and notify those who participate in the support process via e-mail.
Quality control
So, BSM can reduce the time to determine the place of failure. Able to track both software and hardware. And inside BSM systems there are usually user simulators - these are dumb “robots” that can check, for example, the availability of a TCP port or the presence of a GET response for a web page. In a more complex implementation, robots can emulate a sequence of user actions with the application interface, and you can record these operations and translate into scripting languages in an interactive visual mode. There are also modules that, with the help of traffic assembly up to the application level, can isolate the main operations and sequences of related user operations and collect statistics on them on the delays and availability of operations for each real user.
Now a little digression. Each time, introducing an IT system, you need to think about what tasks it solves. For example, if customer service without an IT system lasted 12 minutes, and an automation system was introduced that allowed you to not fill part of the paper with your hands, you would like to believe that the service will now take a maximum of 10 minutes, right? And if it takes 14 minutes instead of the old 12, then somewhere there is a problem.
So, one of the tasks of BSM is to monitor the quality of service. Not only its availability, but also the search for problems with inhibitory interfaces, delayed decision-making by users, extra links in the chains.
If we take as a basis a situation where a developer faithfully and efficiently performs the development and testing of applications and new releases, all the same, independent control by the customer of the qualitative performance indicators of the applications is necessary, since the reason is obvious - nobody except the consumers of the application and the customer needs high-quality application operation . And the quality level can only be determined by the customer.
But in practice, it happens more likely that one fine morning after the next release of the application is put into commercial operation, users come to the office and realize that everything is slowing down. We had an example when BSM was just collecting information on the quality indicators of the system. After implementation, the third-party system worked like a clock. But with an increase in the number of users, surprises began with the fact that for some operations, users observed significant delays in the response of the application. BSM ran as a user, repeating the basic patterns behind living people - and caught a couple of “bottlenecks”, where the interface response could, under a number of conditions, be up to 12 seconds.
Such a solution can be built, for example, on HP Business Service Management (BSM) - this is an example of a couple of my recent projects. And if you also integrate the HP Executive Scorecard (XS) here, you can correlate business operations with monitoring with metrics for managing IT assets and customer service.
Code review
The same HP BSM does not know how to “look out of the box” where the problem is in the code. Nevertheless, quite a lot of tasks to solve the downtime problem rests precisely on this. And therefore, it has convenient integration with products for working at the code level. In this case, screenshots from HP Diagnostics:
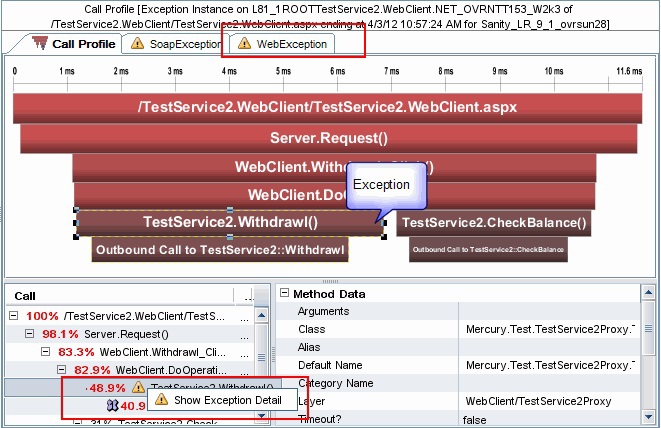
Horizontal bars indicate calls in the application, their length shows the execution time of each call, and their sequence is shown below in the tree.
The same screenshot shows the ability to track exceptions.
Call viewing allows you to understand due to what procedure the application slows down.
By analyzing data flows and detected components, Diagnostics builds the topology of the application components between themselves and the client:
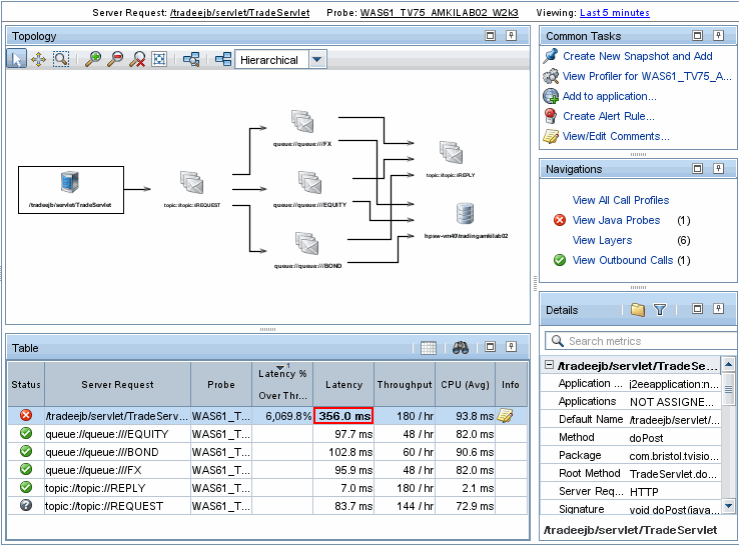
It is useful to know where and what
Summary
Despite the rather simple description, BSM is an expensive and complex toy that, in fact, deploys a whole network of accompanying processes that collect data for everything that is running in the IT infrastructure.
In general, BSM is implemented in about a month or two at least, and allows in practice to reduce the downtime of critical services. More precisely, given that there is no 100% reliable service, turn the inevitable downtime into a shorter one.