In-Memory OLTP in SQL Server 2014. Part II
In the first part, we briefly examined the main capabilities of SQL Server in in-memory processing in relation to analytical and transactional and applications, concentrating on the latter, since in-memory OLTP (Hekaton) is the most significant innovation in SQL Server 2014. In this article, we continue the overview Hekaton functionality on the example of a previously created database.
Since we are talking about transactional processing in memory, it would be useful to recall the acronym ACID: atomicity, integrity, isolation, and residualness (effect), specifically, letter I. Since it is unprofitable to achieve complete isolation, the DBMS supports isolation levels that allow some degree of compromise . This is a classic of the genre. As it approaches the ideal, SQL Server supports: dirty reading (violations of the type are allowed: the first transaction changes data, the second reads the changes, the first rolls back, it turns out that the second reads nonexistent), read committed (possibly non-repeating reading: the first transaction can change the data in reading scale the second, and the second time the second transaction will read the data already changed), repeatable read (the first transaction cannot change the records on the second scale, but can insert new ones - phantoms), serializable (the most severe - phantoms do not pass). Once upon a time, when pages in SQL Server were 2 kilobyte, only page locks were supported, so the last two levels were synonymous. Full support for recording locks appeared in 7.0 (1998). In 2005, snapshot Isolation was added to these levels, which, strictly speaking, is not an isolation level, but turns SQL Server from a locker into a versioned version. Just a snapshot is the main one for the Hecaton, because optimistic concurrency is the most natural approach when working with objects in memory. I mean - in essence, because versions of entries in this case are not stored in tempdb. Each write operation has a continuously increasing transaction number, which is used for subsequent readings. Uncommitted records are stored in memory, but are not visible until a commit, so there are no dirty reads. Old records are deleted during the garbage collection process and free up memory.
Hecaton also supports Repeatable Read, which (unlike the disk version) does not block anyone. When re-reading occurs somewhere at the end of the transaction, then if the records have changed, the transaction is canceled with error 41305 “The current transaction failed to commit due to a repeatable read validation failure on table [name]”. Serializable works the same way - in case of phantoms, the transaction is canceled.
The isolation level is set in the ATOMIC block of the natively compiled stored procedure (see below) or in the table hint of the T-SQL query. As an option - using the database option MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT, which, when accessing tables in memory, raises Read UnCommitted / Committed to Snapshot. If it’s customary to write
there will be an error Msg 41333, Level 16, State 1, Line 3
The following transactions must access memory optimized tables and natively compiled stored procedures under snapshot isolation: RepeatableRead transactions, Serializable transactions, and transactions that access tables that are not memory optimized in RepeatableRead or Serializable isolation.
In a T-SQL script, the isolation level is set by hint:
Theoretically, Read Committed for memory optimized tables is also supported, but only in the case of autocommit (single statement) transactions.
At the same time, the costs of blocking are minimal, for which, in fact, everything was started.
Note that the Hecaton "hangs" the lock only Schema Stability on the table. There are no X and IX in sight:

Fig . 1
For comparison, let us recall what happens in the case of traditional tables. Create a similar disk table, insert the same set of rows as prefill and repeat the transaction:
What is called, feel the difference:
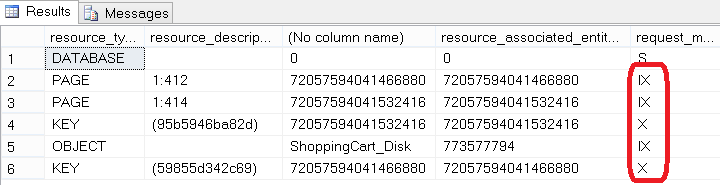
Fig . 2
Minimal blocking is one of the clear advantages of the Hecaton. An application will benefit from a transfer to memory if it is executed in the OLTP style, i.e. characterized by relatively short transactions with a high percentage of competition from multiple connections, and the problem is that locks or physical latches hang for a long time and do not release resources. Porting will be easier if stored procedures are used, and performance problems can be distinguished into a relatively small subset of tables / stored procedures. Of course, not all scenarios win. The limiting case is one table from one record, which everyone updates with a new value. The desire at all costs to push everything and everything into memory will lead to the fact that it will end stupidly. By the way, quite often they ask what will happen, if Hekaton eats all the memory allocated to him? In general, it’s clear that there’s nothing good: Msg 701, Level 17, State 103. There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on the release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite a special thread for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low and on the release I still couldn’t drive him into a stupor, which is treated only by restart (as opposed to CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low and on the release I still couldn’t drive him into a stupor, which is treated only by restart (as opposed to CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low
How to avoid overflow during work? Obviously, it’s correct to evaluate reality when transferring tables to memory, especially since no one canceled sp_spaceused.
You can use the Memory Optimization Advisor, which conducts a static analysis of the schema, indexes, etc. for potential problems, and the more intelligent AMR (Analysis, Migrate and Report) for dynamic analysis by the nature of use (it takes statistics from the
Performance Data Warehouse). You can proactively limit the hecaton using the resource controller:
The influence of Resource Governor applies only to memory allocated by In-Memory OLTP allocators, i.e. if there are no objects optimized for memory in the database, memory is not removed from the resource pool. The in-memory OLTP engine is integrated into the general SQL Server Memory Manager, as you can see by running
The first comrade will be the memory allocated by the system, the last (memory_node = 64) is a dedicated administrative connection, and between them are user databases with MEMORY_OPTIMIZED_DATA.
As noted in the first part, it is completely optional to put the entire base into memory. Combined queries are possible between tables in memory and familiar tables, for example,
Script 1
In addition to tables, stored procedures can be stored in memory. Such procedures can only work with in-memory tables. A procedure is necessarily created with the SCHEMABINDING option, which means that the tables referenced by the procedure cannot be modified or deleted before it. Traditional default procedures are executed with the EXECUTE AS CALLER option. For procedures in memory, it is not supported. The options are: EXECUTE AS OWNER, EXECUTE AS 'user_name' or EXECUTE AS SELF (creator). There are other limitations - see BOL , “Stored Procedures Compiled in Native Code”.
The body of the procedure is the BEGIN ATOMIC block from the ANSI SQL standard, and at the moment this is its only application in T-SQL. It differs from BEGIN TRAN in that it automatically rolls back when an error occurs, while in a transaction it is necessary to use TRY / CATCH and ROLLBACK, because There are nuances about SET XACT_ABORT ON. The design options are TRANSACTION ISOLATION LEVEL = SNAPSHOT | REPEATABLEREAD | SERIALIZABLE and LANGUAGE, which can use any language from sys.languages. It defines the date | time format and system message language.
Script 2
As in the case of tables, native compilation occurs for the procedures, which turns the interpreted T-SQL commands into C code and then into machine code, so if we repeat the request for Script 4 from the previous part , we will see that 3 dll corresponding to the freshly created procedure.
The key to using objects in memory is performance. For comparison, we will create a similar stored procedure of the traditional storage method, which will insert the specified number of records in exactly the same way, but already in the disk table:
Script 3
And insert one and a million records:
As the saying goes, the difference is obvious:
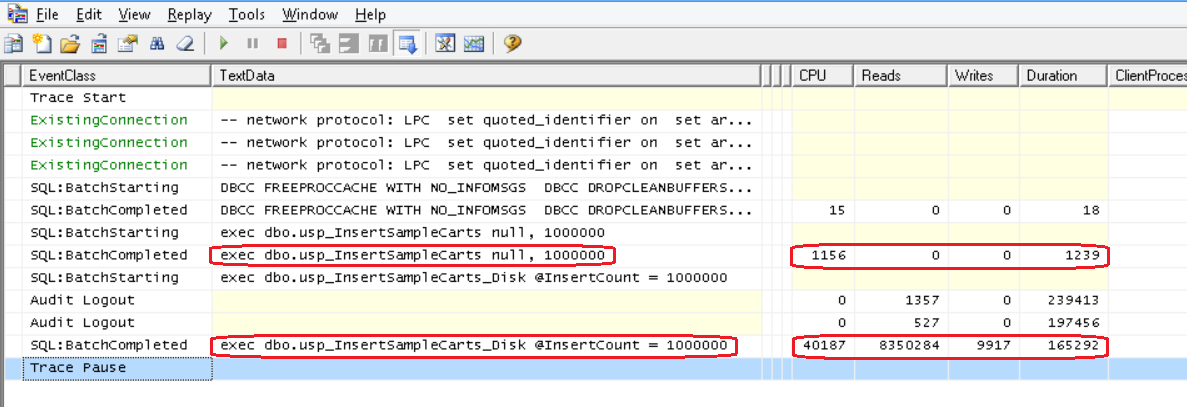
Fig . 3
Of the features, it should be noted that SQL Server 2014 does not support the automatic recompilation of native stored procedures. The plan is fixed. Parameter sniffing is not used, all parameters rely unknown. Instead of recompiling, you may have to delete and re-create the procedure when the data changes (to generate a new plan). Perhaps the recompilation that occurs when the server starts, moves to the backup node, etc. is enough. It is clear that the fresher the statistics on the tables, the more correctly the plan will be built, and the statistics, as we recall from the first part, is not automatically updated. Must be done manually using UPDATE STATISTICS or sp_updatestats. The latter always updates statistics for memory-optimized tables (for regular tables, as needed).
Of the good things, let's see the difference in logging. In the classic version, if we write a million records to a table with a non-clustered index (and updates touch some column of this index), we will get two million records to the log, which, of course, affects performance. In addition (write-ahead logging), all this is placed in the log buffer immediately and in loaded systems leads to high competition for the buffer. In the case of Hekaton, uncommitted transactions are not flushed to disk at all, so you do not need to store undo information or aggressively insert them into the log buffer. Operations on indexes are not logged - they are not stored between restarts. Only one consolidated journal entry is generated during the commit, which contains the necessary information about all the details of the changes, for all entries, affected by the transaction. We look.
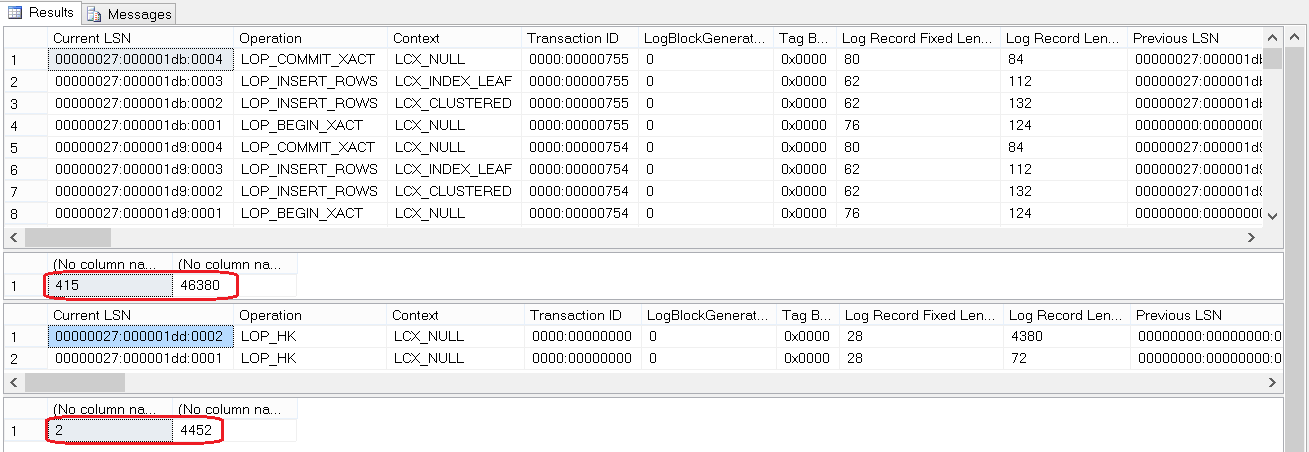
Fig. 4
And we see that the insertion of 100 entries in the case of an in-memory table is logged as just two entries in a log of the LOP_HK type (Log Operation Hekaton). As noted, these entries are consolidated. You can see what they actually reveal by using the new undocumented function that I borrowed from Kalen Delaney. As Current LSN, we set the values from the corresponding column of the third result set in Fig. 4:
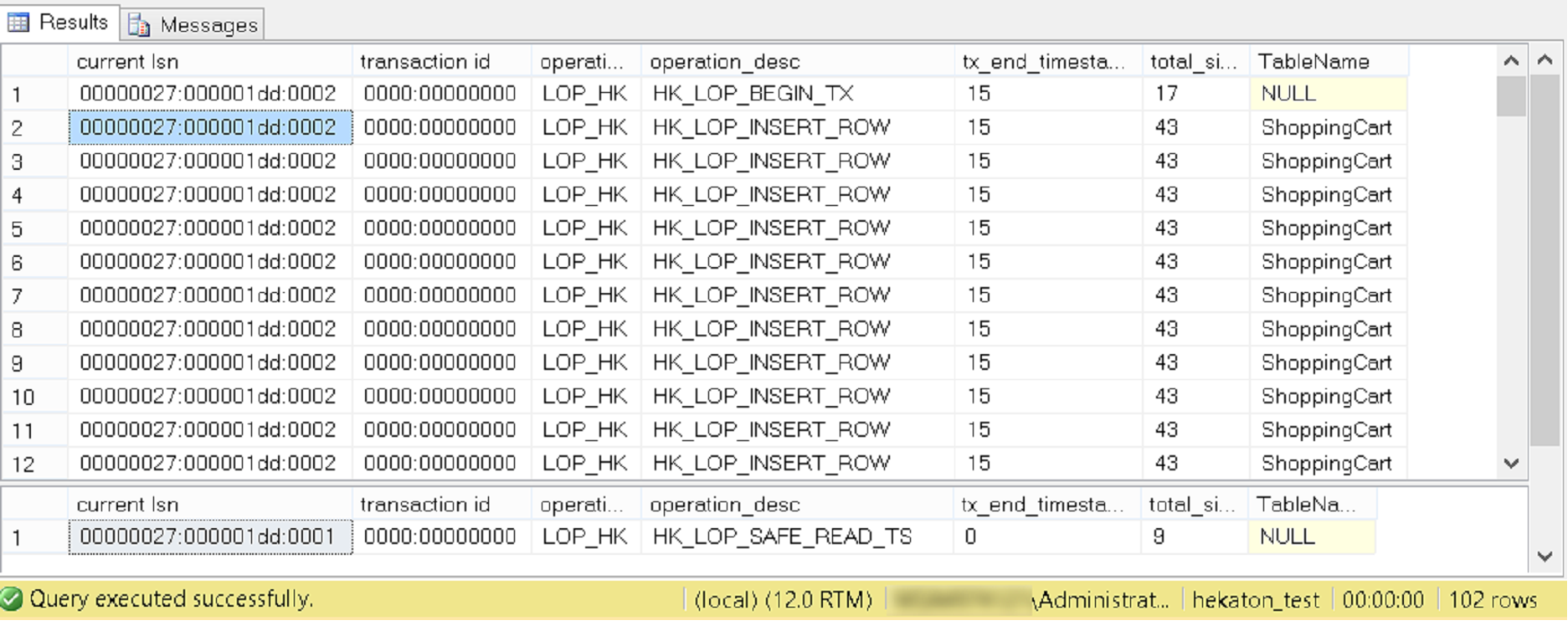
Fig. 5
The first record, as we see, consists of 102 records: begin tx, 100 inserts, commit. Despite this, their total volume (see the second and fourth result of Fig. 4) is> 10 times more compact than in the case of a disk table. If we take a non-durable table (DURABILITY = SCHEMA_ONLY), there will be no journaling at all.
Since we are talking about transactional processing in memory, it would be useful to recall the acronym ACID: atomicity, integrity, isolation, and residualness (effect), specifically, letter I. Since it is unprofitable to achieve complete isolation, the DBMS supports isolation levels that allow some degree of compromise . This is a classic of the genre. As it approaches the ideal, SQL Server supports: dirty reading (violations of the type are allowed: the first transaction changes data, the second reads the changes, the first rolls back, it turns out that the second reads nonexistent), read committed (possibly non-repeating reading: the first transaction can change the data in reading scale the second, and the second time the second transaction will read the data already changed), repeatable read (the first transaction cannot change the records on the second scale, but can insert new ones - phantoms), serializable (the most severe - phantoms do not pass). Once upon a time, when pages in SQL Server were 2 kilobyte, only page locks were supported, so the last two levels were synonymous. Full support for recording locks appeared in 7.0 (1998). In 2005, snapshot Isolation was added to these levels, which, strictly speaking, is not an isolation level, but turns SQL Server from a locker into a versioned version. Just a snapshot is the main one for the Hecaton, because optimistic concurrency is the most natural approach when working with objects in memory. I mean - in essence, because versions of entries in this case are not stored in tempdb. Each write operation has a continuously increasing transaction number, which is used for subsequent readings. Uncommitted records are stored in memory, but are not visible until a commit, so there are no dirty reads. Old records are deleted during the garbage collection process and free up memory.
Hecaton also supports Repeatable Read, which (unlike the disk version) does not block anyone. When re-reading occurs somewhere at the end of the transaction, then if the records have changed, the transaction is canceled with error 41305 “The current transaction failed to commit due to a repeatable read validation failure on table [name]”. Serializable works the same way - in case of phantoms, the transaction is canceled.
The isolation level is set in the ATOMIC block of the natively compiled stored procedure (see below) or in the table hint of the T-SQL query. As an option - using the database option MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT, which, when accessing tables in memory, raises Read UnCommitted / Committed to Snapshot. If it’s customary to write
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRAN
UPDATE dbo.UserSession SET ShoppingCartId=3 WHERE SessionId=4
there will be an error Msg 41333, Level 16, State 1, Line 3
The following transactions must access memory optimized tables and natively compiled stored procedures under snapshot isolation: RepeatableRead transactions, Serializable transactions, and transactions that access tables that are not memory optimized in RepeatableRead or Serializable isolation.
In a T-SQL script, the isolation level is set by hint:
BEGIN TRAN
UPDATE dbo.UserSession WITH (SNAPSHOT) SET ShoppingCartId=3 WHERE SessionId=4
UPDATE dbo.ShoppingCart WITH (SNAPSHOT) SET TotalPrice=100.00 WHERE ShoppingCartId=3
COMMIT
(1 row(s) affected)
(1 row(s) affected)
Theoretically, Read Committed for memory optimized tables is also supported, but only in the case of autocommit (single statement) transactions.
At the same time, the costs of blocking are minimal, for which, in fact, everything was started.
BEGIN TRAN
INSERT dbo.ShoppingCart VALUES (5,500,GETUTCDATE(),50.5)
SELECT resource_type, resource_description, object_name(resource_associated_entity_id), request_mode, request_type, request_status FROM sys.dm_tran_locks WHERE request_session_id = @@SPID
Note that the Hecaton "hangs" the lock only Schema Stability on the table. There are no X and IX in sight:
Fig . 1
For comparison, let us recall what happens in the case of traditional tables. Create a similar disk table, insert the same set of rows as prefill and repeat the transaction:
CREATE TABLE dbo.ShoppingCart_Disk (
ShoppingCartId int not null
primary key,
UserId int not null,
CreatedDate datetime2 not null,
TotalPrice money,
INDEX ixUserid nonclustered (UserId))
...
BEGIN TRAN
INSERT dbo.ShoppingCart_Disk VALUES (5,500,GETUTCDATE(),50.5)
SELECT resource_type, resource_description, case resource_type when 'object' then object_name(resource_associated_entity_id) else cast(resource_associated_entity_id as sysname) end, resource_associated_entity_id, request_mode, request_type, request_status FROM sys.dm_tran_locks WHERE request_session_id = @@SPID
What is called, feel the difference:
Fig . 2
Minimal blocking is one of the clear advantages of the Hecaton. An application will benefit from a transfer to memory if it is executed in the OLTP style, i.e. characterized by relatively short transactions with a high percentage of competition from multiple connections, and the problem is that locks or physical latches hang for a long time and do not release resources. Porting will be easier if stored procedures are used, and performance problems can be distinguished into a relatively small subset of tables / stored procedures. Of course, not all scenarios win. The limiting case is one table from one record, which everyone updates with a new value. The desire at all costs to push everything and everything into memory will lead to the fact that it will end stupidly. By the way, quite often they ask what will happen, if Hekaton eats all the memory allocated to him? In general, it’s clear that there’s nothing good: Msg 701, Level 17, State 103. There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on the release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite a special thread for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low There is insufficient system memory in resource pool 'default' to run this query. What to do in this case is usually nothing. SQL Server cleans up the memory quite quickly, and on release I still couldn’t drive it into a stupor, which is treated only by restart (unlike CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low and on the release I still couldn’t drive him into a stupor, which is treated only by restart (as opposed to CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low and on the release I still couldn’t drive him into a stupor, which is treated only by restart (as opposed to CTP). Garbage collection is designed as non-blocking and cooperative, which means that despite the special flow for these purposes, most of the work is done by user processes, which from time to time check and mark records for subsequent deletion, and then delete them. Dedicated stream is activated when user activity is very low
How to avoid overflow during work? Obviously, it’s correct to evaluate reality when transferring tables to memory, especially since no one canceled sp_spaceused.
You can use the Memory Optimization Advisor, which conducts a static analysis of the schema, indexes, etc. for potential problems, and the more intelligent AMR (Analysis, Migrate and Report) for dynamic analysis by the nature of use (it takes statistics from the
Performance Data Warehouse). You can proactively limit the hecaton using the resource controller:
CREATE RESOURCE POOL mem_optpool WITH (MAX_MEMORY_PERCENT = сколько не жалко)
EXEC sp_xtp_bind_db_resource_pool 'mydatabase', 'mem_optpool‘
The influence of Resource Governor applies only to memory allocated by In-Memory OLTP allocators, i.e. if there are no objects optimized for memory in the database, memory is not removed from the resource pool. The in-memory OLTP engine is integrated into the general SQL Server Memory Manager, as you can see by running
select type, name, memory_node_id, pages_kb/1024 as pages_MB from sys.dm_os_memory_clerks where type like '%xtp%‘
The first comrade will be the memory allocated by the system, the last (memory_node = 64) is a dedicated administrative connection, and between them are user databases with MEMORY_OPTIMIZED_DATA.
As noted in the first part, it is completely optional to put the entire base into memory. Combined queries are possible between tables in memory and familiar tables, for example,
select m1.ShoppingCartId, m2.UserId, d.CreatedDate, d.TotalPrice from ShoppingCart m1
join ShoppingCart_Disk d on m1.ShoppingCartId = d.ShoppingCartId
join UserSession m2 on d.ShoppingCartId = m2.ShoppingCartId
delete from ShoppingCart
insert ShoppingCart select * from ShoppingCart_Disk
update d set TotalPrice = m.TotalPrice from ShoppingCart_Disk d join ShoppingCart m on d.ShoppingCartId = m.ShoppingCartId where m.UserID <= 100
Script 1
In addition to tables, stored procedures can be stored in memory. Such procedures can only work with in-memory tables. A procedure is necessarily created with the SCHEMABINDING option, which means that the tables referenced by the procedure cannot be modified or deleted before it. Traditional default procedures are executed with the EXECUTE AS CALLER option. For procedures in memory, it is not supported. The options are: EXECUTE AS OWNER, EXECUTE AS 'user_name' or EXECUTE AS SELF (creator). There are other limitations - see BOL , “Stored Procedures Compiled in Native Code”.
The body of the procedure is the BEGIN ATOMIC block from the ANSI SQL standard, and at the moment this is its only application in T-SQL. It differs from BEGIN TRAN in that it automatically rolls back when an error occurs, while in a transaction it is necessary to use TRY / CATCH and ROLLBACK, because There are nuances about SET XACT_ABORT ON. The design options are TRANSACTION ISOLATION LEVEL = SNAPSHOT | REPEATABLEREAD | SERIALIZABLE and LANGUAGE, which can use any language from sys.languages. It defines the date | time format and system message language.
CREATE PROCEDURE dbo.usp_InsertSampleCarts @StartId int, @InsertCount int
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
IF @StartId is null SELECT @StartId = isnull(MAX(ShoppingCartId), 0) + 1 FROM dbo.ShoppingCart
DECLARE @i int = 0
WHILE @i < @InsertCount
BEGIN
INSERT INTO dbo.ShoppingCart VALUES (@StartId + @i, RAND() * 1000, GETUTCDATE(), NULL)
SET @i += 1
END
END
Script 2
As in the case of tables, native compilation occurs for the procedures, which turns the interpreted T-SQL commands into C code and then into machine code, so if we repeat the request for Script 4 from the previous part , we will see that 3 dll corresponding to the freshly created procedure.
The key to using objects in memory is performance. For comparison, we will create a similar stored procedure of the traditional storage method, which will insert the specified number of records in exactly the same way, but already in the disk table:
CREATE PROCEDURE dbo.usp_InsertSampleCarts_Disk @StartId int = null, @InsertCount int
AS BEGIN
IF @StartId is null SELECT @StartId = isnull(MAX(ShoppingCartId), 0) + 1 FROM dbo.ShoppingCart
DECLARE @i int = 0
WHILE @i < @InsertCount
BEGIN
INSERT INTO dbo.ShoppingCart_Disk VALUES
(@StartId + @i, RAND() * 1000, GETUTCDATE(), NULL)
SET @i += 1
END
END
Script 3
And insert one and a million records:
SET NOCOUNT ON; DBCC FREEPROCCACHE WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS
exec dbo.usp_InsertSampleCarts null, 1000000
exec dbo.usp_InsertSampleCarts_Disk @InsertCount = 1000000
As the saying goes, the difference is obvious:

Fig . 3
Of the features, it should be noted that SQL Server 2014 does not support the automatic recompilation of native stored procedures. The plan is fixed. Parameter sniffing is not used, all parameters rely unknown. Instead of recompiling, you may have to delete and re-create the procedure when the data changes (to generate a new plan). Perhaps the recompilation that occurs when the server starts, moves to the backup node, etc. is enough. It is clear that the fresher the statistics on the tables, the more correctly the plan will be built, and the statistics, as we recall from the first part, is not automatically updated. Must be done manually using UPDATE STATISTICS or sp_updatestats. The latter always updates statistics for memory-optimized tables (for regular tables, as needed).
Of the good things, let's see the difference in logging. In the classic version, if we write a million records to a table with a non-clustered index (and updates touch some column of this index), we will get two million records to the log, which, of course, affects performance. In addition (write-ahead logging), all this is placed in the log buffer immediately and in loaded systems leads to high competition for the buffer. In the case of Hekaton, uncommitted transactions are not flushed to disk at all, so you do not need to store undo information or aggressively insert them into the log buffer. Operations on indexes are not logged - they are not stored between restarts. Only one consolidated journal entry is generated during the commit, which contains the necessary information about all the details of the changes, for all entries, affected by the transaction. We look.
declare @lsn nvarchar(46) = (select max([Current LSN]) from sys.fn_dblog(null, null))
exec dbo.usp_InsertSampleCarts_Disk @InsertCount = 100
select * from sys.fn_dblog(null, NULL) where [Current LSN] > @lsn order by [Current LSN] desc
select count(1), sum([Log Record Length]) from sys.fn_dblog(null, NULL) where [Current LSN] > @lsn
set @lsn = (select max([Current LSN]) from sys.fn_dblog(null, null))
exec dbo.usp_InsertSampleCarts null, 100
select * from sys.fn_dblog(null, NULL) where [Current LSN] > @lsn order by [Current LSN] desc
select count(1), sum([Log Record Length]) from sys.fn_dblog(null, NULL) where [Current LSN] > @lsn

Fig. 4
And we see that the insertion of 100 entries in the case of an in-memory table is logged as just two entries in a log of the LOP_HK type (Log Operation Hekaton). As noted, these entries are consolidated. You can see what they actually reveal by using the new undocumented function that I borrowed from Kalen Delaney. As Current LSN, we set the values from the corresponding column of the third result set in Fig. 4:
SELECT [current lsn], [transaction id], operation, operation_desc, tx_end_timestamp, total_size, object_name(table_id) AS TableName
FROM sys.fn_dblog_xtp(null, null)
WHERE [Current LSN] = '00000027:000001dd:0002'
SELECT [current lsn], [transaction id], operation, operation_desc, tx_end_timestamp, total_size, object_name(table_id) AS TableName
FROM sys.fn_dblog_xtp(null, null)
WHERE [Current LSN] = '00000027:000001dd:0001'

Fig. 5
The first record, as we see, consists of 102 records: begin tx, 100 inserts, commit. Despite this, their total volume (see the second and fourth result of Fig. 4) is> 10 times more compact than in the case of a disk table. If we take a non-durable table (DURABILITY = SCHEMA_ONLY), there will be no journaling at all.