Backend no problem. Miracle or future?
Hello!
 Friends, it’s not for me to tell you, and you yourself know how to do backend for server / client-server applications. In our ideal world, it all starts with the design of architecture, then we select the site, then we estimate the necessary number of machines, both virtual and not. Then the process of raising the architecture for development / testing takes place. All is ready? Well, let's go write code, make the first commit, update the code on the server from the repository. Opened the console / browser checked and off. So far, everything is simple, but what's next?
Friends, it’s not for me to tell you, and you yourself know how to do backend for server / client-server applications. In our ideal world, it all starts with the design of architecture, then we select the site, then we estimate the necessary number of machines, both virtual and not. Then the process of raising the architecture for development / testing takes place. All is ready? Well, let's go write code, make the first commit, update the code on the server from the repository. Opened the console / browser checked and off. So far, everything is simple, but what's next?
Over time, architecture inevitably grows, new services, new servers appear, and now it's time to think about scalability. There are a little more than 1 servers ?, - it would be necessary to somehow collect the logs together. Immediately a thought about log aggregator comes into my head.
And when something, God forbid, falls, thoughts of monitoring immediately come. Familiar, right? So I ate this with my friends. And when you are in a team, other related problems appear.
You might immediately think that we did not hear anything about aws, jelastic, heroku, digitalocean, puppet / chief, travis, git-hooks, zabbix, datadog, loggly ... I assure you this is not so. We tried to make friends with each of these systems. More precisely, we set up each of these systems for ourselves. But they did not get the desired effect. Some pitfalls always appeared and part of the work would be desirable, at least, to automate.
Living in such a world for a rather large amount of time, we thought, “Well, we are developers, let's do something with this.” Having estimated the problems that accompany us at every stage of the creation and development of the project, we wrote them out on a separate page and turned them into features of the future service.
And 2 months later a service was born out of this - lastbackend.com :

We started from the very first problem when building a server system, namely, building a visual diagram of a project. I don’t know about you, but for me it’s amazing to see which element is connected with how the data streams flow, in comparison with the list of servers and the configured environment in the wiki or in the Google dock. But to judge you.
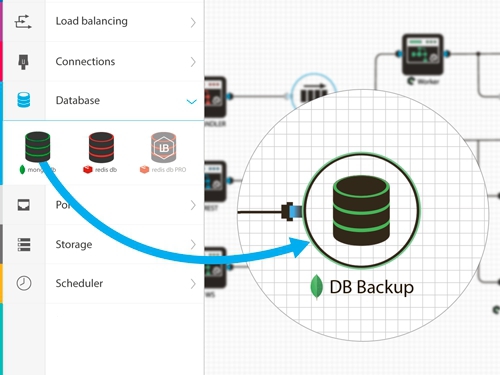
The process of designing the circuit itself is painfully simple and intuitive: on the left is a list of backend elements, on the right is a working field. Here we just take and drag. Need to enable node.js element to connect to mongodb? Please - take and use the mouse to make a connection.

Each element in the system is unique, it must be configured, and if you want to enable its auto-scaling. If the element is a load balancer, there is a place where the upstream selection rules are indicated. If the element has the source code, we indicate its repository, environment variables, dependencies. The system will download it, install it, and launch it.
And of course, we also thought about auto-deploy - the source code in a certain branch changed - cunningly and quickly updated the element. We tried to make everything convenient, because we ourselves use it and we are the first to see all the shortcomings.
And here is the most interesting moment. When the circuit is ready and configured, its deployment takes several seconds. Sometimes it’s longer, and sometimes even instantly. It all depends on the types of elements and its source code. We mainly program on node.js and our schemes are deployed in a couple of seconds. The most exciting moment is to see how all the configured elements in the diagram “come to life” and indicators light up, indicating the current state of the element.
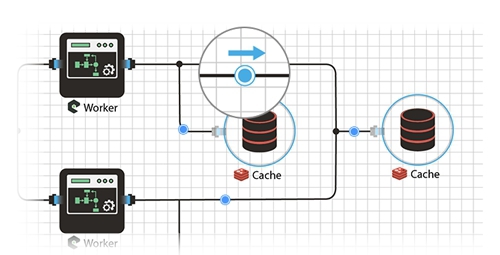
I forgot to add that we have the ability to run each item at a different host / data center. For example, to balance traffic between countries, one element can be launched in one country, the other in the second, and a database, for example, somewhere somewhere in the center. The example is certainly not very good, but in general, I think the opportunity is quite useful, especially if you know how and where to apply it.
Here, in principle, is the main part, which allows you to quickly, beautifully and without problems raise the server part of a project, but we immediately remembered about further problems, namely:
Each element aggregates the log into a single repository of logs, where you can watch and analyze them, do searches and selections. Now there is no need to connect via ssh and grep to look for any hidden information, or just analyze the data
Naturally, we and the hunt ourselves go fishing or just relax knowing that if something happens wrong, you will definitely be informed about this. So we do it so that there would be instant information about all the failures. Now my head doesn’t hurt, that you can miss something important.
Here, in principle, the main problems that we tried and are trying to solve with our service and at least somehow make life easier for the brother-developer.
Naturally, I did not manage to list all the features, I tried to highlight only the main ones, but in the comments I can answer all the questions and wishes in more detail.
Thanks for attention. I would very much like to read your opinion first, answer your questions , write down your advice and wishes , and also give everyone access to the closed beta testing of the service, which, according to preliminary plans, will begin at the May holidays.
You can get an invitation to beta right here. On the opening day of testing - a letter will come with access data.
Also, friends, if interested, we can start a series of technical articles on the stack of technologies used, namely node.js, mongodb, redis, sockets, angular, svg, etc.
Friends, it’s not for me to tell you, and you yourself know how to do backend for server / client-server applications. In our ideal world, it all starts with the design of architecture, then we select the site, then we estimate the necessary number of machines, both virtual and not. Then the process of raising the architecture for development / testing takes place. All is ready? Well, let's go write code, make the first commit, update the code on the server from the repository. Opened the console / browser checked and off. So far, everything is simple, but what's next? Over time, architecture inevitably grows, new services, new servers appear, and now it's time to think about scalability. There are a little more than 1 servers ?, - it would be necessary to somehow collect the logs together. Immediately a thought about log aggregator comes into my head.
And when something, God forbid, falls, thoughts of monitoring immediately come. Familiar, right? So I ate this with my friends. And when you are in a team, other related problems appear.
You might immediately think that we did not hear anything about aws, jelastic, heroku, digitalocean, puppet / chief, travis, git-hooks, zabbix, datadog, loggly ... I assure you this is not so. We tried to make friends with each of these systems. More precisely, we set up each of these systems for ourselves. But they did not get the desired effect. Some pitfalls always appeared and part of the work would be desirable, at least, to automate.
Living in such a world for a rather large amount of time, we thought, “Well, we are developers, let's do something with this.” Having estimated the problems that accompany us at every stage of the creation and development of the project, we wrote them out on a separate page and turned them into features of the future service.
And 2 months later a service was born out of this - lastbackend.com :
Design
We started from the very first problem when building a server system, namely, building a visual diagram of a project. I don’t know about you, but for me it’s amazing to see which element is connected with how the data streams flow, in comparison with the list of servers and the configured environment in the wiki or in the Google dock. But to judge you.
The process of designing the circuit itself is painfully simple and intuitive: on the left is a list of backend elements, on the right is a working field. Here we just take and drag. Need to enable node.js element to connect to mongodb? Please - take and use the mouse to make a connection.
Adjustment and scaling
Each element in the system is unique, it must be configured, and if you want to enable its auto-scaling. If the element is a load balancer, there is a place where the upstream selection rules are indicated. If the element has the source code, we indicate its repository, environment variables, dependencies. The system will download it, install it, and launch it.
And of course, we also thought about auto-deploy - the source code in a certain branch changed - cunningly and quickly updated the element. We tried to make everything convenient, because we ourselves use it and we are the first to see all the shortcomings.
Deployment
And here is the most interesting moment. When the circuit is ready and configured, its deployment takes several seconds. Sometimes it’s longer, and sometimes even instantly. It all depends on the types of elements and its source code. We mainly program on node.js and our schemes are deployed in a couple of seconds. The most exciting moment is to see how all the configured elements in the diagram “come to life” and indicators light up, indicating the current state of the element.
I forgot to add that we have the ability to run each item at a different host / data center. For example, to balance traffic between countries, one element can be launched in one country, the other in the second, and a database, for example, somewhere somewhere in the center. The example is certainly not very good, but in general, I think the opportunity is quite useful, especially if you know how and where to apply it.
Here, in principle, is the main part, which allows you to quickly, beautifully and without problems raise the server part of a project, but we immediately remembered about further problems, namely:
Log Aggregation
Each element aggregates the log into a single repository of logs, where you can watch and analyze them, do searches and selections. Now there is no need to connect via ssh and grep to look for any hidden information, or just analyze the data
Monitoring and warning system
Naturally, we and the hunt ourselves go fishing or just relax knowing that if something happens wrong, you will definitely be informed about this. So we do it so that there would be instant information about all the failures. Now my head doesn’t hurt, that you can miss something important.
Summary
Here, in principle, the main problems that we tried and are trying to solve with our service and at least somehow make life easier for the brother-developer.
Naturally, I did not manage to list all the features, I tried to highlight only the main ones, but in the comments I can answer all the questions and wishes in more detail.
Thanks for attention. I would very much like to read your opinion first, answer your questions , write down your advice and wishes , and also give everyone access to the closed beta testing of the service, which, according to preliminary plans, will begin at the May holidays.
You can get an invitation to beta right here. On the opening day of testing - a letter will come with access data.
PS
Also, friends, if interested, we can start a series of technical articles on the stack of technologies used, namely node.js, mongodb, redis, sockets, angular, svg, etc.