How to make TV really smart?
A few years ago, recommender systems were just beginning to conquer their consumers. Online stores are actively using algorithms of recommendations, offering their customers more and more new products based on their consumer history.
In the client service recommender systems have become relevant not so long ago. In connection with the increase in the proposed content, customers began to get lost in the information flow of what, where and when they need to look. The headache of video content lovers took pay TV operators and online movie theaters to treat.

As an effective way to solve the eternal problem of “what to see?”, Recommendation systems appeared that work on the basis of one or another mathematical model.
Two years ago, we introduced a recommendation system, later supplemented it with editorials and felt a noticeable effect both in sales and in the duration of using our service.
The recommendation system is when you want to watch something, but you don’t know what it is, and the TV guesses your preferences very well. This content filtering, which selects movies and TV shows based on preferences and analysis of user behavior. The system used by the operator must predict the reaction of the viewer to one or another element and offer content that he might like.
When programming recommender systems, three main methods are used: collaborative filtering, content-based filtering and knowledge-based systems.
Collaborative filteringbased on three stages: collecting user information, building a matrix for calculating associations and issuing a reliable recommendation.
A good example of using collaborative filtering is the Cinematch system that Netflix uses. Users explicitly or implicitly give marks to watched films, and recommendations are formed taking into account both their own user ratings and the ratings of other viewers. To do this, the system selects users with similar preferences, whose ratings are close to their own. Based on the opinions of this circle of people, the viewer is automatically given a recommendation: watch a particular film.
For the most correct operation of the recommendation system, of course, the fundamental role is played by the accumulated and collected data. The more data is accumulated about the consumption profile of a subscriber, the more accurate the recommendations are given to him.
Content recommendation system are formulated based on the attributes assigned to each element. If you watch movies of a certain genre, the system will automatically offer you content that is close to your genre in certain positions. It is on the basis of such a recommendation system that the Pandora site works.
Expert recommendation systemsThey offer recommendations not on the basis of ratings, but on the basis of similarities between user requirements and product description, or depending on the restrictions set by the user when specifying the desired product. Therefore, this type of system turns out to be unique, because it allows the client to clearly indicate what he wants.
Expert systems are most effective in contexts where the amount of available data is limited, and collaborative filtering works best in environments where there are large data arrays. But when the data is diversified, it is possible to solve the same problem by different methods. So, it will be optimal to combine the recommendations obtained in several ways, thereby increasing the quality of the system as a whole.
It is a similar hybrid system from the company E-Contenta works in our service WiFire TV . It was launched into operation and debugging in December 2016 and works according to the following principle: if the system knows enough about the user or about the content, then the collaborative filtering algorithms prevail. If the content is new, or not enough information has been collected on user interaction with it, then content algorithms are used to evaluate content similarity based on the available metadata.
In order to build a personalized collection in E-Contenta, it was necessary to rank all available content according to the likelihood that a particular user would be interested in this content.
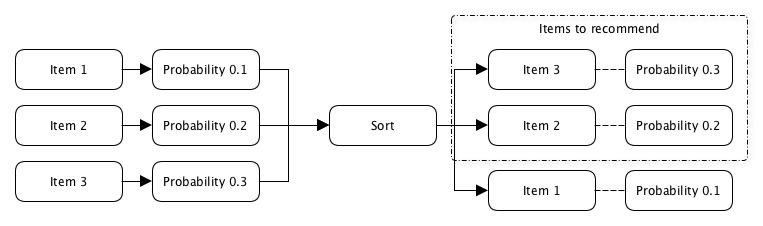
User interest is primarily determined at the moment when he clicks on the content recommended to him, and probability is defined as the ratio of the number of clicks to the number of times this content was recommended to this user.
p (click) = Nklikov / Npokazov
The difficulty lies in the fact that you need to recommend something that he has never seen, and therefore data on the number of clicks or impressions to calculate this probability is simply not there.
Therefore, instead of the actual probability, it was decided to use an estimate of this probability, in other words, the predicted value.
The idea of a collaborative filter is simple:
Thus, users are jointly involved in the content selection process.
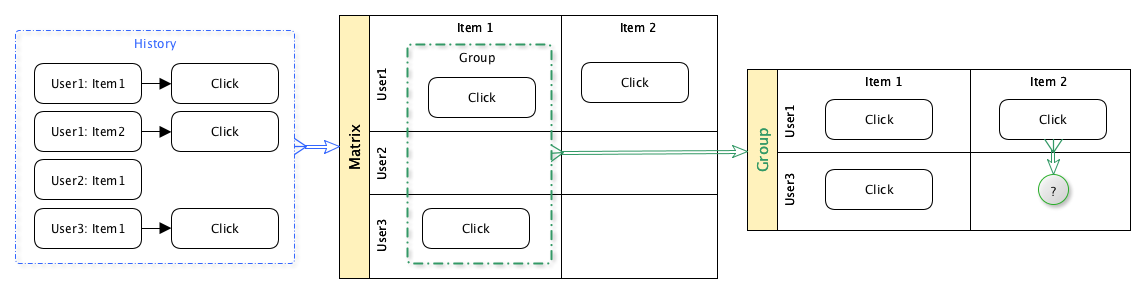
There are many different options for implementing this approach:
1. Build a model using directly identifiers of content units:
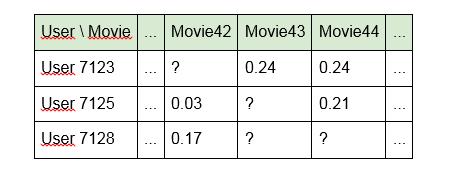
The disadvantage of this approach is that the model does not “see” any links between content items . For example, "Terminator" and "Terminator 2" for her will be as far from each other as "Alien" and "Good night, Kids!". In addition, the matrix itself is very sparse (many empty cells and few filled).
2. Instead of identifiers, use the words included in the title of articles, programs or films:
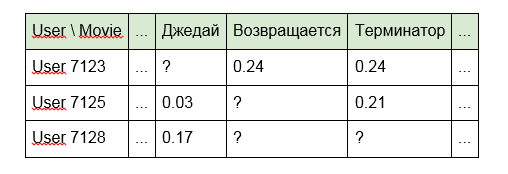
3. For films, the names of actors, directors or data from IMDb:
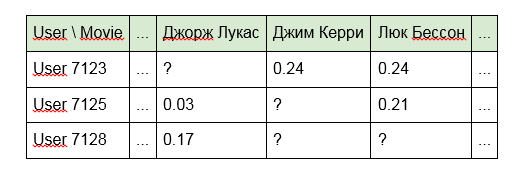
The second and third options partially eliminate the disadvantages of the first approach, taking into account the connection of content that has common features (of the same director or the same words in the title). However, the sparsity of the matrix also decreases, but, as they say, there is no limit to perfection.
Keeping a complete set of user ratings in memory is quite expensive. Taking a rough estimate of the number of Runet users of 80 million people and the size of the IMDb base of 370 thousand films, we get the required size of 27 Terabytes. Singular decomposition is a method of reducing the dimensionality of the matrix.
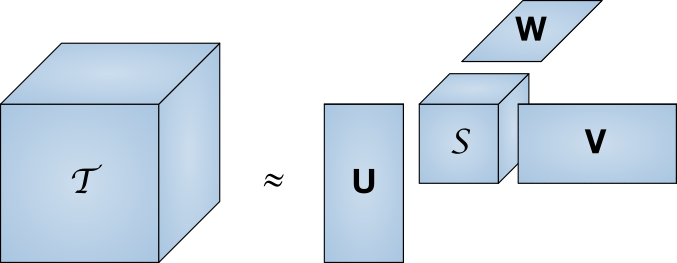
A large matrix T is represented as a product of a set of smaller matrices.
In other words, the search for the "core" of the matrix, which has the same properties as the full matrix, but much smaller. Along with a decrease in the dimension decreases the discharge. In this article we will not go into the subtleties of implementation, especially since ready-made libraries already exist for a number of programming languages.
Cold start
The situation when the lack of data for a new content or user does not allow to give high-quality recommendations, also known as “Cold Start”, is a typical problem for collaborative filtering.
One solution is to mix in the recommendations of several pieces of content for which not enough data is collected. The new user will be recommended the most popular content.
Most popular
Using the above approach, it is important not to forget that its consequence will be a systematic increase in the frequency of the “most popular” in the list of recommended. By learning from the behavior of users who are often offered the “most popular”, the recommender system risks learning to recommend only the most popular content.
The main difference of personal recommendations from the banal recommendations of the most popular content is that they take into account individual tastes, which can differ significantly from the "average".
Thus, the sampling of user reactions to the content used to train the recommender model should be normalized.
Availability, resiliency and scalability
The number of users of the resource can create a load of hundreds and thousands of requests to the recommender system per second. However, the failure of one or several servers should not lead to a denial of service.
The classic solution in this case is to use a load balancer that sends a request to one of the cluster servers. In addition, each of the servers is able to process the incoming request. In case of failure of any of the servers in the cluster, the balancer automatically switches the load to the servers remaining in service. By selecting HTTP as the transport protocol, we can use Nginx as a load balancer.
As the audience grows, the number of servers in a cluster can grow. In this case, it is important to minimize the cost of preparing a new server.
A recommender system requires the installation of a number of components on which it is functionally based. Docker is used to automate the deployment of a recommender system with all its dependencies.
Docker allows you to collect all the necessary components, “pack” them into an image and put such an image into the storage (registry), and then download and deploy it on a new server in a matter of minutes. An important advantage of Docker is that the “overhead” when using it is minimal: the time it takes to call an application in a docker container increases by a few nanoseconds compared to an application running on a regular operating system.
Another important advantage is the ability to quickly return to the previous stable version of the application in the event of a new failure (you just need to take the old version from the registry).
The second type of requests to the system, the maintenance of which must be taken care of are requests that track user actions. So that the user does not have to wait until the system fully processes the action performed by him, the processing is performed independently of the process of recording actions.
In the E-Contenta, Apache Kafka was chosen as a platform for transferring data on user actions to handlers. Kafka implements the architectural pattern Message-Oriented Middleware), which is able to provide guaranteed delivery of tens and hundreds of thousands of messages per second and act as a buffer that protects processors from excessive data at peak times.
Full autonomy of self-learning.
New content and new users regularly appear. Without regular training, the quality of the model degrades. Training should be performed on separate servers so that the learning process, which requires significant computational resources, does not affect the performance of the combat servers.
The classic solution for orchestrating regular distributed tasks is Jenkins. The scheduled service launches the acquisition and normalization of new training samples, training of the recommendatory model, delivery of new models and updating of all servers in the cluster, which allows maintaining the quality of recommendations without additional efforts. In the event of a failure in any of the steps, Jenkins automatically returns the system to the previous stable state and notifies the administrator about the failure.
In addition, in order for the system to work properly, we invited an independent television meter and invited him to measure the television viewing of subscribers. The obtained unique data is enlivened using data science algorithms. Continuously operating feedback from subscribers interacting with the recommendations fills the base of precedents of machine learning algorithms and allows the recommendations to change depending on the implicit signs of changing preferences of subscribers, such as time of year, approaching holidays or changing family composition.
In the process of testing, we had to solve the problem associated with the recommendation of television content - how to help our subscribers understand streams of broadcasts. The task is also complicated by the services of deferred viewing. We have built in a system that, instead of an endless cyclic channel switching, helps to find an interesting program already in 2-3 button presses. To this end, the recommendatory system monitors the release of a new series of programs and predicts the interest of viewers in irregular programs and broadcasts of films. In fact, machine algorithms replace the work of the responsible editor.
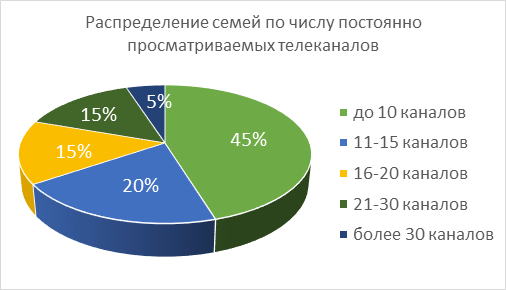
Work with streaming television has its own specifics. For example, often the same popular TV shows go on different channels. In this case, the recommender system has to understand duplication of information and choose a recommendation based on the preferences of the subscriber regarding the channels, the start time of transmission, etc. Such duplication of information also occurs when the subscriber has a subscription to the SD and HD versions of the channels.
All these two years, we experimented with different versions of recommender systems and found a middle ground that allows us to improve the audience engagement and more effectively monetize existing content. We use the automatic selection of recommendations described above with manual configuration - editorial collections.
This approach allowed significantly (10 times) to increase the monetization of VOD and SVOD services.
Editorial recommendations are collections of thematic films and serials tied to high-profile premieres, holidays, and memorable dates. It is very convenient - to notify subscribers and give them the opportunity to watch new movies, old hits or unpopular, but in our opinion very interesting films in terms of content and plot. We closely communicate with our suppliers (online cinemas and additional video services, such as ivi, megogo, amediateka) and personally select each film that will be interesting for our subscriber.
On holidays we make special selections on a certain subject. For example, for Victory Day, these are films of a military theme. On the first of September - a selection of content for children, which consists of educational programs, cartoons, and documentaries.
Manual selection perfectly increases the loyalty of our subscribers. According to our most conservative estimates, about 10% of our subscriber base watches movies every month that we recommend and this figure is constantly growing.
Currently, Wifire TV is powered by an intelligent recommendation system from E-Contenta. It is based on data science and metadata of 90% of operator’s subscribers. The algorithm takes into account hundreds of data: what the subscriber is watching, what movies and programs are popular, when he uses the service and who is now in front of the screen. We want to convey to our subscribers the value of a subscription to premium channel packages, mixing them with relevant user programs in recommendations. We also want to show what to acquire and watch legal video content - this is normal, convenient and simple.
The recommendation system will prompt the subscriber interesting films, even if they have long been out of the category of new products: thus the extensive video catalog ceases to be a dusty library, and becomes an interactive showcase that adapts flexibly to the tastes and moods of subscribers.
In the client service recommender systems have become relevant not so long ago. In connection with the increase in the proposed content, customers began to get lost in the information flow of what, where and when they need to look. The headache of video content lovers took pay TV operators and online movie theaters to treat.
As an effective way to solve the eternal problem of “what to see?”, Recommendation systems appeared that work on the basis of one or another mathematical model.
Two years ago, we introduced a recommendation system, later supplemented it with editorials and felt a noticeable effect both in sales and in the duration of using our service.
What is a recommendation system
The recommendation system is when you want to watch something, but you don’t know what it is, and the TV guesses your preferences very well. This content filtering, which selects movies and TV shows based on preferences and analysis of user behavior. The system used by the operator must predict the reaction of the viewer to one or another element and offer content that he might like.
When programming recommender systems, three main methods are used: collaborative filtering, content-based filtering and knowledge-based systems.
Collaborative filteringbased on three stages: collecting user information, building a matrix for calculating associations and issuing a reliable recommendation.
A good example of using collaborative filtering is the Cinematch system that Netflix uses. Users explicitly or implicitly give marks to watched films, and recommendations are formed taking into account both their own user ratings and the ratings of other viewers. To do this, the system selects users with similar preferences, whose ratings are close to their own. Based on the opinions of this circle of people, the viewer is automatically given a recommendation: watch a particular film.
For the most correct operation of the recommendation system, of course, the fundamental role is played by the accumulated and collected data. The more data is accumulated about the consumption profile of a subscriber, the more accurate the recommendations are given to him.
Content recommendation system are formulated based on the attributes assigned to each element. If you watch movies of a certain genre, the system will automatically offer you content that is close to your genre in certain positions. It is on the basis of such a recommendation system that the Pandora site works.
Expert recommendation systemsThey offer recommendations not on the basis of ratings, but on the basis of similarities between user requirements and product description, or depending on the restrictions set by the user when specifying the desired product. Therefore, this type of system turns out to be unique, because it allows the client to clearly indicate what he wants.
Expert systems are most effective in contexts where the amount of available data is limited, and collaborative filtering works best in environments where there are large data arrays. But when the data is diversified, it is possible to solve the same problem by different methods. So, it will be optimal to combine the recommendations obtained in several ways, thereby increasing the quality of the system as a whole.
It is a similar hybrid system from the company E-Contenta works in our service WiFire TV . It was launched into operation and debugging in December 2016 and works according to the following principle: if the system knows enough about the user or about the content, then the collaborative filtering algorithms prevail. If the content is new, or not enough information has been collected on user interaction with it, then content algorithms are used to evaluate content similarity based on the available metadata.
How did the recommendation algorithms line up?
In order to build a personalized collection in E-Contenta, it was necessary to rank all available content according to the likelihood that a particular user would be interested in this content.
User interest is primarily determined at the moment when he clicks on the content recommended to him, and probability is defined as the ratio of the number of clicks to the number of times this content was recommended to this user.
p (click) = Nklikov / Npokazov
The difficulty lies in the fact that you need to recommend something that he has never seen, and therefore data on the number of clicks or impressions to calculate this probability is simply not there.
Therefore, instead of the actual probability, it was decided to use an estimate of this probability, in other words, the predicted value.
The idea of a collaborative filter is simple:
- Take historical data viewing by users of content
- Based on this data, group users by the content they viewed.
- For a given user to predict the probability of his interest in a specific unit of content, based on historical data of other users belonging to the same group.
Thus, users are jointly involved in the content selection process.
There are many different options for implementing this approach:
1. Build a model using directly identifiers of content units:
The disadvantage of this approach is that the model does not “see” any links between content items . For example, "Terminator" and "Terminator 2" for her will be as far from each other as "Alien" and "Good night, Kids!". In addition, the matrix itself is very sparse (many empty cells and few filled).
2. Instead of identifiers, use the words included in the title of articles, programs or films:
3. For films, the names of actors, directors or data from IMDb:
The second and third options partially eliminate the disadvantages of the first approach, taking into account the connection of content that has common features (of the same director or the same words in the title). However, the sparsity of the matrix also decreases, but, as they say, there is no limit to perfection.
Keeping a complete set of user ratings in memory is quite expensive. Taking a rough estimate of the number of Runet users of 80 million people and the size of the IMDb base of 370 thousand films, we get the required size of 27 Terabytes. Singular decomposition is a method of reducing the dimensionality of the matrix.
A large matrix T is represented as a product of a set of smaller matrices.
In other words, the search for the "core" of the matrix, which has the same properties as the full matrix, but much smaller. Along with a decrease in the dimension decreases the discharge. In this article we will not go into the subtleties of implementation, especially since ready-made libraries already exist for a number of programming languages.
Technical difficulties
Cold start
The situation when the lack of data for a new content or user does not allow to give high-quality recommendations, also known as “Cold Start”, is a typical problem for collaborative filtering.
One solution is to mix in the recommendations of several pieces of content for which not enough data is collected. The new user will be recommended the most popular content.
Most popular
Using the above approach, it is important not to forget that its consequence will be a systematic increase in the frequency of the “most popular” in the list of recommended. By learning from the behavior of users who are often offered the “most popular”, the recommender system risks learning to recommend only the most popular content.
The main difference of personal recommendations from the banal recommendations of the most popular content is that they take into account individual tastes, which can differ significantly from the "average".
Thus, the sampling of user reactions to the content used to train the recommender model should be normalized.
Availability, resiliency and scalability
The number of users of the resource can create a load of hundreds and thousands of requests to the recommender system per second. However, the failure of one or several servers should not lead to a denial of service.
The classic solution in this case is to use a load balancer that sends a request to one of the cluster servers. In addition, each of the servers is able to process the incoming request. In case of failure of any of the servers in the cluster, the balancer automatically switches the load to the servers remaining in service. By selecting HTTP as the transport protocol, we can use Nginx as a load balancer.
As the audience grows, the number of servers in a cluster can grow. In this case, it is important to minimize the cost of preparing a new server.
A recommender system requires the installation of a number of components on which it is functionally based. Docker is used to automate the deployment of a recommender system with all its dependencies.
Docker allows you to collect all the necessary components, “pack” them into an image and put such an image into the storage (registry), and then download and deploy it on a new server in a matter of minutes. An important advantage of Docker is that the “overhead” when using it is minimal: the time it takes to call an application in a docker container increases by a few nanoseconds compared to an application running on a regular operating system.
Another important advantage is the ability to quickly return to the previous stable version of the application in the event of a new failure (you just need to take the old version from the registry).
The second type of requests to the system, the maintenance of which must be taken care of are requests that track user actions. So that the user does not have to wait until the system fully processes the action performed by him, the processing is performed independently of the process of recording actions.
In the E-Contenta, Apache Kafka was chosen as a platform for transferring data on user actions to handlers. Kafka implements the architectural pattern Message-Oriented Middleware), which is able to provide guaranteed delivery of tens and hundreds of thousands of messages per second and act as a buffer that protects processors from excessive data at peak times.
Full autonomy of self-learning.
New content and new users regularly appear. Without regular training, the quality of the model degrades. Training should be performed on separate servers so that the learning process, which requires significant computational resources, does not affect the performance of the combat servers.
The classic solution for orchestrating regular distributed tasks is Jenkins. The scheduled service launches the acquisition and normalization of new training samples, training of the recommendatory model, delivery of new models and updating of all servers in the cluster, which allows maintaining the quality of recommendations without additional efforts. In the event of a failure in any of the steps, Jenkins automatically returns the system to the previous stable state and notifies the administrator about the failure.
How we did it on WifireTV
In addition, in order for the system to work properly, we invited an independent television meter and invited him to measure the television viewing of subscribers. The obtained unique data is enlivened using data science algorithms. Continuously operating feedback from subscribers interacting with the recommendations fills the base of precedents of machine learning algorithms and allows the recommendations to change depending on the implicit signs of changing preferences of subscribers, such as time of year, approaching holidays or changing family composition.
In the process of testing, we had to solve the problem associated with the recommendation of television content - how to help our subscribers understand streams of broadcasts. The task is also complicated by the services of deferred viewing. We have built in a system that, instead of an endless cyclic channel switching, helps to find an interesting program already in 2-3 button presses. To this end, the recommendatory system monitors the release of a new series of programs and predicts the interest of viewers in irregular programs and broadcasts of films. In fact, machine algorithms replace the work of the responsible editor.
Work with streaming television has its own specifics. For example, often the same popular TV shows go on different channels. In this case, the recommender system has to understand duplication of information and choose a recommendation based on the preferences of the subscriber regarding the channels, the start time of transmission, etc. Such duplication of information also occurs when the subscriber has a subscription to the SD and HD versions of the channels.
All these two years, we experimented with different versions of recommender systems and found a middle ground that allows us to improve the audience engagement and more effectively monetize existing content. We use the automatic selection of recommendations described above with manual configuration - editorial collections.
This approach allowed significantly (10 times) to increase the monetization of VOD and SVOD services.
Editorial recommendations are collections of thematic films and serials tied to high-profile premieres, holidays, and memorable dates. It is very convenient - to notify subscribers and give them the opportunity to watch new movies, old hits or unpopular, but in our opinion very interesting films in terms of content and plot. We closely communicate with our suppliers (online cinemas and additional video services, such as ivi, megogo, amediateka) and personally select each film that will be interesting for our subscriber.
On holidays we make special selections on a certain subject. For example, for Victory Day, these are films of a military theme. On the first of September - a selection of content for children, which consists of educational programs, cartoons, and documentaries.
Manual selection perfectly increases the loyalty of our subscribers. According to our most conservative estimates, about 10% of our subscriber base watches movies every month that we recommend and this figure is constantly growing.
What is the result?
Currently, Wifire TV is powered by an intelligent recommendation system from E-Contenta. It is based on data science and metadata of 90% of operator’s subscribers. The algorithm takes into account hundreds of data: what the subscriber is watching, what movies and programs are popular, when he uses the service and who is now in front of the screen. We want to convey to our subscribers the value of a subscription to premium channel packages, mixing them with relevant user programs in recommendations. We also want to show what to acquire and watch legal video content - this is normal, convenient and simple.
The recommendation system will prompt the subscriber interesting films, even if they have long been out of the category of new products: thus the extensive video catalog ceases to be a dusty library, and becomes an interactive showcase that adapts flexibly to the tastes and moods of subscribers.