Task based queue systems
Hi, Habrozhiteli!
We decided to share the translation of the chapter “Systems based on queues of tasks” From the upcoming release “Distributed systems. Design patterns ”(already in a printing house).

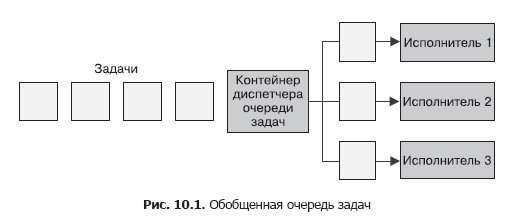
The simplest form of batch processing is the task queue. In a task queue system, there is a set of tasks that must be completed. Each task is completely independent of the others and can be processed without any interactions with them. In the general case, the goal of a system with a task queue is to ensure that each stage of work is completed within a specified period of time. The number of workflows increases or decreases according to the change in load. The scheme of the generalized task queue is shown in Fig. 10.1.
The task queue is an ideal example demonstrating the power of distributed system design patterns. Most of the logic of the work queue tasks does not depend on the type of work performed. In many cases, the same applies to the delivery of the tasks themselves.
We illustrate this statement with the help of the task queue shown in fig. 10.1. Looking at it again, determine which of its functions can be provided by a shared set of containers. It becomes obvious that most of the implementation of a containerized task queue can be used by a wide range of users.
Container-based task queue requires that the interfaces between library containers and containers are aligned with user logic. As part of a containerized task queue, there are two interfaces: the source container interface, which provides a stream of tasks that need processing, and the executing container interface, which knows how to handle them.
Any queue of tasks operates on the basis of a set of tasks that require processing. Depending on the specific application implemented on the basis of the task queue, there are many sources of tasks that fall into it. But after receiving a set of tasks, the queue operation scheme is quite simple. Consequently, we can separate the application-specific logic of the task source from the generalized task queue processing scheme. Recalling the previously discussed patterns of groups of containers, here you can see the implementation of the Ambassador pattern. The generalized task queue container is the main application container, and the application-specific source container is the ambassador broadcasting requests from the queue dispatcher container to specific task implementers. This group of containers is shown in Fig. 10.2.

By the way, although the container ambassador is application specific (which is obvious), there are also a number of generic implementations of the task source API. For example, the source could be a list of photos stored in some cloud storage, a set of files on a network drive, or even a queue on publish / subscribe systems such as Kafka or Redis. Despite the fact that users can choose the most suitable container ambassadors, they should use a generic "library" implementation of the container itself. This will minimize the amount of work and maximize code reuse.
Task Queue APIGiven the mechanism of interaction between the task queue and the application-dependent container-ambassador, we should formulate a formal definition of the interface between the two containers. There are many different protocols, but the HTTP RESTful API is simple to implement and is the de facto standard for such interfaces. The task queue expects the following URLs to be implemented in the container-after:
??????
The URL / items / <item-name> provides detailed information about a specific task:
Please note that the API does not provide any mechanisms for fixing the fact of the task. It would be possible to develop a more complex API and shift most of the implementation to the container-ambassador. Remember, however, that our goal is to concentrate as much of the overall implementation as possible within the task queue manager. In this regard, the task queue manager must monitor for itself which tasks have already been processed and which ones have yet to be processed.
From this API, we get information about a specific task, and then pass the value of the item.data field of the implementing container interface.
As soon as the queue manager received the next task, he must assign it to some performer. This is the second interface in the generalized task queue. The container itself and its interface are slightly different from the source container interface for several reasons. First, it is a “one-time” API. The job of the contractor begins with a single call, and no more calls are made during the life cycle of the container. Secondly, the executing container and the task queue manager are in different container groups. The performing container is launched through the container orchestrator API in its own group. This means that the task queue manager must make a remote call to initiate the execution container. It also means that you have to be more careful about security,
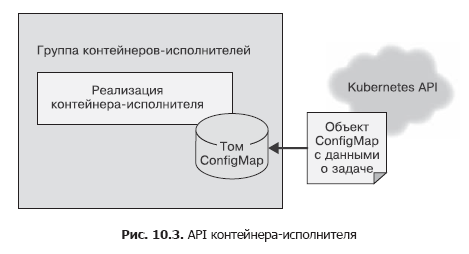
In the source container, we used a simple HTTP call to send the task list to the task manager. This was done on the assumption that this API call needs to be made several times, and security issues were not taken into account, since everything worked within localhost. The executing container API needs to be called only once and it is important to make sure that other users of the system cannot add work to the performers at least by chance, at least for malicious purposes. Therefore, we will use the file API for the executing container. When creating, we will pass to the container an environment variable called WORK_ITEM_FILE, the value of which refers to a file in the internal file system of the container. This file contains information about the task that needs to be performed. This kind of API, as shown below, can be implemented by the ConfigMap Kubernetes object.
Such a file API mechanism is easier to implement using a container. A worker in a task queue is often a simple shell script that accesses several tools. It is inappropriate to raise a whole web server for managing tasks - this leads to an increase in architecture. As in the case of task sources, most of the executing containers will be specialized containers for specific tasks, but there are also generalized executors applicable for solving several different tasks.
Consider an example of an executing container that downloads a file from the cloud storage, runs a shell script on it, and then copies the result back to the cloud storage. Such a container can be for the most part common, but as a parameter it can be passed a specific script. Thus, most of the file handling code can be reused by many users / task queues. The end user only needs to provide a script containing the specifics of processing the file.
What remains to be implemented in the reusable queue implementation, if you already have the implementations of the two previously described container interfaces? The basic algorithm for the work of the task queue is quite simple.
This algorithm is simple in words, but in reality it is not so easy to implement. Fortunately, the Kubernetes orchestrator has several features that greatly simplify its implementation. Namely: in Kubernetes there is a Job object that allows you to ensure reliable operation of the task queue. The Job object can be configured so that it runs the corresponding executable container either one-time or until the task is successfully completed. If the executing container is configured to run until the task is completed, then even when the machine in the cluster fails, the task will eventually be completed successfully.
Thus, the construction of the task queue is greatly simplified, since the orchestrator takes responsibility for the reliable execution of tasks.
In addition, Kubernetes allows you to annotate tasks, which allows us to mark each task object with the name of the processed task queue element. It becomes easier to distinguish between tasks that are processed and completed both successfully and with an error.
This means that we can implement a task queue on top of the Kubernetes orchestra, without using our own storage. All this greatly simplifies the task of building the infrastructure of the task queue.
Consequently, the detailed algorithm of the work of the container - task queue manager is as follows.
Repeat endlessly.
I'll give you a Python script that implements such a queue:
As an example of using the task queue, consider the task of generating thumbnails of video files. Based on these thumbnails, users decide which videos they want to watch.
To implement the thumbnails, you need two containers. The first is for the source of the tasks. The easiest way is to place tasks on a shared network drive connected, for example, via NFS (Network File System). The task source receives a list of files in this directory and sends them to the caller.
I will give a simple program on NodeJS:
This source defines a list of movies to be processed. To extract thumbnails, use the ffmpeg utility.
You can create a container that runs this command:
The command extracts one of every 100 frames (-frames parameter: v 100) and saves it in PNG format (for example, thumb1.png, thumb2.png, etc.).
This kind of processing can be implemented on the basis of the existing Docker image ffmpeg. Popular image jrottenberg / ffmpeg .
Having identified a simple source container and an even simpler performing container, it is easy to see what advantages a generalized, container-oriented queue management system has. It significantly reduces the time between design and implementation of the task queue.
The previously considered task queue is well suited for processing tasks as they arrive, but can lead to an abrupt load on the resources of the container orchestrator cluster. This is good when you have many different types of tasks that create load peaks at different times and thus evenly distribute the load on the cluster in time.
But if you do not have enough types of load, the “something thick, empty” approach to scaling the task queue may require reserving additional resources to support load spikes. The rest of the time the resources will be idle, emptying your wallet unnecessarily.
To solve this problem, you can limit the total number of Job objects generated by the task queue. This will naturally limit the number of tasks processed in parallel and, consequently, reduce the use of resources at peak load. On the other hand, the duration of the execution of each individual task will increase with a high load on the cluster.
If the load is intermittent, it is not a bad thing, since you can use idle intervals to perform accumulated tasks. However, if the sustained load is too high, the queue of tasks will not have time to process incoming tasks and will take more and more time to complete them.
In such a situation, you will have to dynamically adjust the maximum number of parallel tasks and, accordingly, the available computing resources to maintain the required level of performance. Fortunately, there are mathematical formulas that allow you to determine when you need to scale the queue of tasks to handle more requests.
Consider a task queue in which a new task appears on average once a minute, and its execution takes on average 30 seconds. Such a queue is able to cope with the flow of tasks coming into it. Even if a large batch of tasks comes at once, forming a mash, the mash will eventually be eliminated, since the queue has time to process an average of two tasks before the next task arrives.
If a new task arrives every minute and on average it takes 1 minute to process one task, then such a system is perfectly balanced, but it does not respond well to changes in the load. She is able to cope with surges in load, but she will need a lot of time for this. The system will not be idle, but there will be no reserve of machine time to compensate for the long-term increase in the rate of receipt of new tasks. To maintain the stability of the system, it is necessary to have a reserve in case of a long-term increase in load or unforeseen delays in processing tasks.
Finally, consider a system in which one task arrives per minute, and task processing takes two minutes. Such a system will constantly lose productivity. The length of the task queue will grow with the delay between the receipt and processing of tasks (and the degree of user irritation).
The values of these two indicators must be constantly monitored. Averaging the time between the receipt of tasks for a long period of time, for example, based on the number of tasks per day, we obtain an estimate of the intertask interval. It is also necessary to monitor the average duration of the job processing (without taking into account the time spent in the queue). In a stable task queue, the average task processing time should be less than the inter-task interval. To ensure that this condition is met, it is necessary to dynamically adjust the number of available queues of computing resources. If tasks are processed in parallel, the processing time should be divided by the number of tasks processed in parallel. For example, if one task is processed a minute, but four tasks are processed in parallel,
This approach allows you to easily create a scaling module of the task queue upwards. Scaling downward is somewhat more problematic. Nevertheless, it is possible to use the same calculations as before, additionally laying the reserve of computing resources determined by the heuristic method. For example, you can reduce the number of parallel tasks to be performed until the processing time of one task is 90% of the task interval.
One of the main topics of this book is the use of containers to encapsulate and reuse code. It is also relevant for the queuing patterns described in this chapter. In addition to the containers that control the queue itself, it is possible to reuse the groups of containers that make up the implementer implementation. Suppose you need to process each task in the queue in three different ways. For example, to find faces in a photo, compare them with specific people, and then blur the corresponding parts of the image. You can put all processing into a single performing container, but this is a one-time solution that cannot be reused. To gloss over a photo of something else, such as machines, you have to create an executing container from scratch.
Opportunities for this kind of reuse can be achieved by applying the Multi-Worker pattern, which is actually a special case of the Adapter pattern described at the beginning of the book. The Multi-Worker pattern converts a set of containers into one common container with the program interface of the executing container. This shared container delegates processing to several separate, reusable containers. This process is shown schematically in fig. 10.4.

By reusing code by combining executing containers, the labor costs of people designing distributed batch processing systems are reduced.
»For more information on the book, please refer to the publisher's website
» Table of contents
» Fragment
For Hubrozhiteley 20% discount on the coupon - Distributed systems .
We decided to share the translation of the chapter “Systems based on queues of tasks” From the upcoming release “Distributed systems. Design patterns ”(already in a printing house).
The simplest form of batch processing is the task queue. In a task queue system, there is a set of tasks that must be completed. Each task is completely independent of the others and can be processed without any interactions with them. In the general case, the goal of a system with a task queue is to ensure that each stage of work is completed within a specified period of time. The number of workflows increases or decreases according to the change in load. The scheme of the generalized task queue is shown in Fig. 10.1.
System based on generalized task queue
The task queue is an ideal example demonstrating the power of distributed system design patterns. Most of the logic of the work queue tasks does not depend on the type of work performed. In many cases, the same applies to the delivery of the tasks themselves.
We illustrate this statement with the help of the task queue shown in fig. 10.1. Looking at it again, determine which of its functions can be provided by a shared set of containers. It becomes obvious that most of the implementation of a containerized task queue can be used by a wide range of users.
Container-based task queue requires that the interfaces between library containers and containers are aligned with user logic. As part of a containerized task queue, there are two interfaces: the source container interface, which provides a stream of tasks that need processing, and the executing container interface, which knows how to handle them.
Source container interface
Any queue of tasks operates on the basis of a set of tasks that require processing. Depending on the specific application implemented on the basis of the task queue, there are many sources of tasks that fall into it. But after receiving a set of tasks, the queue operation scheme is quite simple. Consequently, we can separate the application-specific logic of the task source from the generalized task queue processing scheme. Recalling the previously discussed patterns of groups of containers, here you can see the implementation of the Ambassador pattern. The generalized task queue container is the main application container, and the application-specific source container is the ambassador broadcasting requests from the queue dispatcher container to specific task implementers. This group of containers is shown in Fig. 10.2.
By the way, although the container ambassador is application specific (which is obvious), there are also a number of generic implementations of the task source API. For example, the source could be a list of photos stored in some cloud storage, a set of files on a network drive, or even a queue on publish / subscribe systems such as Kafka or Redis. Despite the fact that users can choose the most suitable container ambassadors, they should use a generic "library" implementation of the container itself. This will minimize the amount of work and maximize code reuse.
Task Queue APIGiven the mechanism of interaction between the task queue and the application-dependent container-ambassador, we should formulate a formal definition of the interface between the two containers. There are many different protocols, but the HTTP RESTful API is simple to implement and is the de facto standard for such interfaces. The task queue expects the following URLs to be implemented in the container-after:
??????
- GET localhost / api / v1 / items;
- GET localhost / api / v1 / items <item-name>.
Why add v1 to the API definition, you ask? Will the second version of the interface ever appear? It looks illogical, but the costs of versioning the API during its initial definition are minimal. To conduct the appropriate refactoring later will be extremely expensive. Make it a rule to add versions to all APIs, even if you are not sure that they will ever change. God saves man, who save himself.URL / items / returns a list of all tasks:
{
kind: ItemList,
apiVersion: v1,
items: [
"item-1",
"item-2",
….
]
}The URL / items / <item-name> provides detailed information about a specific task:
{
kind: Item,
apiVersion: v1,
data: {
"some": "json",
"object": "here",
}
}Please note that the API does not provide any mechanisms for fixing the fact of the task. It would be possible to develop a more complex API and shift most of the implementation to the container-ambassador. Remember, however, that our goal is to concentrate as much of the overall implementation as possible within the task queue manager. In this regard, the task queue manager must monitor for itself which tasks have already been processed and which ones have yet to be processed.
From this API, we get information about a specific task, and then pass the value of the item.data field of the implementing container interface.
Executive Container Interface
As soon as the queue manager received the next task, he must assign it to some performer. This is the second interface in the generalized task queue. The container itself and its interface are slightly different from the source container interface for several reasons. First, it is a “one-time” API. The job of the contractor begins with a single call, and no more calls are made during the life cycle of the container. Secondly, the executing container and the task queue manager are in different container groups. The performing container is launched through the container orchestrator API in its own group. This means that the task queue manager must make a remote call to initiate the execution container. It also means that you have to be more careful about security,
In the source container, we used a simple HTTP call to send the task list to the task manager. This was done on the assumption that this API call needs to be made several times, and security issues were not taken into account, since everything worked within localhost. The executing container API needs to be called only once and it is important to make sure that other users of the system cannot add work to the performers at least by chance, at least for malicious purposes. Therefore, we will use the file API for the executing container. When creating, we will pass to the container an environment variable called WORK_ITEM_FILE, the value of which refers to a file in the internal file system of the container. This file contains information about the task that needs to be performed. This kind of API, as shown below, can be implemented by the ConfigMap Kubernetes object.
Such a file API mechanism is easier to implement using a container. A worker in a task queue is often a simple shell script that accesses several tools. It is inappropriate to raise a whole web server for managing tasks - this leads to an increase in architecture. As in the case of task sources, most of the executing containers will be specialized containers for specific tasks, but there are also generalized executors applicable for solving several different tasks.
Consider an example of an executing container that downloads a file from the cloud storage, runs a shell script on it, and then copies the result back to the cloud storage. Such a container can be for the most part common, but as a parameter it can be passed a specific script. Thus, most of the file handling code can be reused by many users / task queues. The end user only needs to provide a script containing the specifics of processing the file.
Common task queue infrastructure
What remains to be implemented in the reusable queue implementation, if you already have the implementations of the two previously described container interfaces? The basic algorithm for the work of the task queue is quite simple.
- Download the currently available tasks from the source container.
- Refine the status of the task queue for what tasks have already been completed or are still being performed.
- For each of the unresolved tasks, generate executing containers with an appropriate interface.
- Upon successful completion of the executive container, note that the task has been completed.
This algorithm is simple in words, but in reality it is not so easy to implement. Fortunately, the Kubernetes orchestrator has several features that greatly simplify its implementation. Namely: in Kubernetes there is a Job object that allows you to ensure reliable operation of the task queue. The Job object can be configured so that it runs the corresponding executable container either one-time or until the task is successfully completed. If the executing container is configured to run until the task is completed, then even when the machine in the cluster fails, the task will eventually be completed successfully.
Thus, the construction of the task queue is greatly simplified, since the orchestrator takes responsibility for the reliable execution of tasks.
In addition, Kubernetes allows you to annotate tasks, which allows us to mark each task object with the name of the processed task queue element. It becomes easier to distinguish between tasks that are processed and completed both successfully and with an error.
This means that we can implement a task queue on top of the Kubernetes orchestra, without using our own storage. All this greatly simplifies the task of building the infrastructure of the task queue.
Consequently, the detailed algorithm of the work of the container - task queue manager is as follows.
Repeat endlessly.
- Retrieve a list of tasks via the container interface of the task source.
- Get a list of tasks serving this task queue.
- Highlight a list of unprocessed tasks based on these lists.
- For each unprocessed task, create a Job object that spawns the corresponding executable container.
I'll give you a Python script that implements such a queue:
import requests
import json
from kubernetes import client, config
import time
namespace = "default"
def make_container(item, obj):
container = client.V1Container()
container.image = "my/worker-image"
container.name = "worker"
return container
def make_job(item):
response =
requests.get("http://localhost:8000/items/{}".format(item))
obj = json.loads(response.text)
job = client.V1Job()
job.metadata = client.V1ObjectMeta()
job.metadata.name = item
job.spec = client.V1JobSpec()
job.spec.template = client.V1PodTemplate()
job.spec.template.spec = client.V1PodTemplateSpec()
job.spec.template.spec.restart_policy = "Never"
job.spec.template.spec.containers = [
make_container(item, obj)
]
return job
def update_queue(batch):
response = requests.get("http://localhost:8000/items")
obj = json.loads(response.text)
items = obj['items']
ret = batch.list_namespaced_job(namespace, watch=False)
for item in items:
found = False
for i in ret.items:
if i.metadata.name == item:
found = True
if not found:
# Функция создает объект Job, пропущена
# для краткости
job = make_job(item)
batch.create_namespaced_job(namespace, job)
config.load_kube_config()
batch = client.BatchV1Api()
while True:
update_queue(batch)
time.sleep(10)Workshop. Implementing a video file thumbnail generator
As an example of using the task queue, consider the task of generating thumbnails of video files. Based on these thumbnails, users decide which videos they want to watch.
To implement the thumbnails, you need two containers. The first is for the source of the tasks. The easiest way is to place tasks on a shared network drive connected, for example, via NFS (Network File System). The task source receives a list of files in this directory and sends them to the caller.
I will give a simple program on NodeJS:
const http = require('http');
const fs = require('fs');
const port = 8080;
const path = process.env.MEDIA_PATH;
const requestHandler = (request, response) => {
console.log(request.url);
fs.readdir(path + '/*.mp4', (err, items) => {
var msg = {
'kind': 'ItemList',
'apiVersion': 'v1',
'items': []
};
if (!items) {
return msg;
}
for (var i = 0; i < items.length; i++) {
msg.items.push(items[i]);
}
response.end(JSON.stringify(msg));
});
}
const server = http.createServer(requestHandler);
server.listen(port, (err) => {
if (err) {
return console.log('Ошибка запуска сервера', err);
}
console.log(`сервер запущен на порте ${port}`)
});This source defines a list of movies to be processed. To extract thumbnails, use the ffmpeg utility.
You can create a container that runs this command:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.pngThe command extracts one of every 100 frames (-frames parameter: v 100) and saves it in PNG format (for example, thumb1.png, thumb2.png, etc.).
This kind of processing can be implemented on the basis of the existing Docker image ffmpeg. Popular image jrottenberg / ffmpeg .
Having identified a simple source container and an even simpler performing container, it is easy to see what advantages a generalized, container-oriented queue management system has. It significantly reduces the time between design and implementation of the task queue.
Dynamic scaling artists
The previously considered task queue is well suited for processing tasks as they arrive, but can lead to an abrupt load on the resources of the container orchestrator cluster. This is good when you have many different types of tasks that create load peaks at different times and thus evenly distribute the load on the cluster in time.
But if you do not have enough types of load, the “something thick, empty” approach to scaling the task queue may require reserving additional resources to support load spikes. The rest of the time the resources will be idle, emptying your wallet unnecessarily.
To solve this problem, you can limit the total number of Job objects generated by the task queue. This will naturally limit the number of tasks processed in parallel and, consequently, reduce the use of resources at peak load. On the other hand, the duration of the execution of each individual task will increase with a high load on the cluster.
If the load is intermittent, it is not a bad thing, since you can use idle intervals to perform accumulated tasks. However, if the sustained load is too high, the queue of tasks will not have time to process incoming tasks and will take more and more time to complete them.
In such a situation, you will have to dynamically adjust the maximum number of parallel tasks and, accordingly, the available computing resources to maintain the required level of performance. Fortunately, there are mathematical formulas that allow you to determine when you need to scale the queue of tasks to handle more requests.
Consider a task queue in which a new task appears on average once a minute, and its execution takes on average 30 seconds. Such a queue is able to cope with the flow of tasks coming into it. Even if a large batch of tasks comes at once, forming a mash, the mash will eventually be eliminated, since the queue has time to process an average of two tasks before the next task arrives.
If a new task arrives every minute and on average it takes 1 minute to process one task, then such a system is perfectly balanced, but it does not respond well to changes in the load. She is able to cope with surges in load, but she will need a lot of time for this. The system will not be idle, but there will be no reserve of machine time to compensate for the long-term increase in the rate of receipt of new tasks. To maintain the stability of the system, it is necessary to have a reserve in case of a long-term increase in load or unforeseen delays in processing tasks.
Finally, consider a system in which one task arrives per minute, and task processing takes two minutes. Such a system will constantly lose productivity. The length of the task queue will grow with the delay between the receipt and processing of tasks (and the degree of user irritation).
The values of these two indicators must be constantly monitored. Averaging the time between the receipt of tasks for a long period of time, for example, based on the number of tasks per day, we obtain an estimate of the intertask interval. It is also necessary to monitor the average duration of the job processing (without taking into account the time spent in the queue). In a stable task queue, the average task processing time should be less than the inter-task interval. To ensure that this condition is met, it is necessary to dynamically adjust the number of available queues of computing resources. If tasks are processed in parallel, the processing time should be divided by the number of tasks processed in parallel. For example, if one task is processed a minute, but four tasks are processed in parallel,
This approach allows you to easily create a scaling module of the task queue upwards. Scaling downward is somewhat more problematic. Nevertheless, it is possible to use the same calculations as before, additionally laying the reserve of computing resources determined by the heuristic method. For example, you can reduce the number of parallel tasks to be performed until the processing time of one task is 90% of the task interval.
Multi-Worker Pattern
One of the main topics of this book is the use of containers to encapsulate and reuse code. It is also relevant for the queuing patterns described in this chapter. In addition to the containers that control the queue itself, it is possible to reuse the groups of containers that make up the implementer implementation. Suppose you need to process each task in the queue in three different ways. For example, to find faces in a photo, compare them with specific people, and then blur the corresponding parts of the image. You can put all processing into a single performing container, but this is a one-time solution that cannot be reused. To gloss over a photo of something else, such as machines, you have to create an executing container from scratch.
Opportunities for this kind of reuse can be achieved by applying the Multi-Worker pattern, which is actually a special case of the Adapter pattern described at the beginning of the book. The Multi-Worker pattern converts a set of containers into one common container with the program interface of the executing container. This shared container delegates processing to several separate, reusable containers. This process is shown schematically in fig. 10.4.
By reusing code by combining executing containers, the labor costs of people designing distributed batch processing systems are reduced.
»For more information on the book, please refer to the publisher's website
» Table of contents
» Fragment
For Hubrozhiteley 20% discount on the coupon - Distributed systems .