Break me completely (ZeroNightsCrackme, Part 2)
- Tutorial
Hello again! Last time I unveiled the ZeroNightsCrackMe solution . Everyone who managed to solve it on time could receive an invitation to an excursion to one of the offices of Kaspersky Lab, as well as a gift, in the form of a license key for three devices. But, among other things, Kaspersky said that the crack was lightweight, i.e. there is a more complex version of it and it will be sent to those who wish to see it (but without gifts, for your pleasure, so to speak). Of course, I could not deny myself not to twist this version, so I confirmed my desire to participate.
February 17, a letter came with a new crack. It is about his decision (and not only) that I will tell in this article.
The parameters of the crack are the same:
Instruments:
Let's get down to the solution ...
As usual, run the experimental and conduct a surface analysis. The reaction is similar to the past crack.

Fig. 1
Knowing the principle of the work of the past with the crack, we proceed to the search for key points and find:
Then we compare all the key points with the previous version and find the differences.
First of all, we find the function of processing the entered data. This is done quite simply. Right-click in the disassembler window and select "Search for => All referenced strings" :

Fig. 2
Next, click on the line "Good work, Serial is valid !!!" and get here:
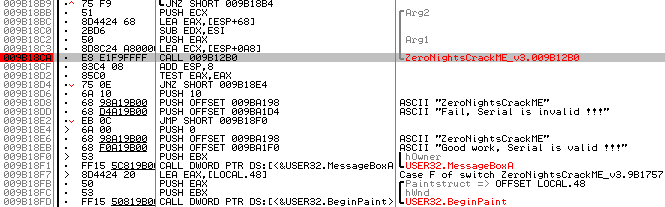
Fig. 3
Above, the desired function will be located (in my case, it is CALL 0x9b12b0 ). Three parameters are passed to her. In Arg2 , Arg1 the size of the serial code and a pointer to the serial code are transmitted, respectively, and in the ECX register a pointer to the email.
We go inside the function and turn to the very bottom, there is an algorithm for checking the validation table (identical to the old version):

Fig. 4
We set a breakpoint at the beginning of the algorithm and run the cracks to execute (of course, after entering any data and clicking the Check button ).

Fig. 5. Enter the test data
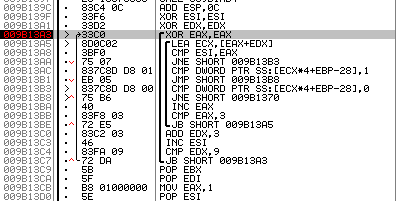
Fig. 6. Stop on the validation table
Now we determine the address of the table itself. You can do this by going to the line “CMP DWORD PTR SS: [ECX * 4 + EBP-28], 1” and looking at the destination address.
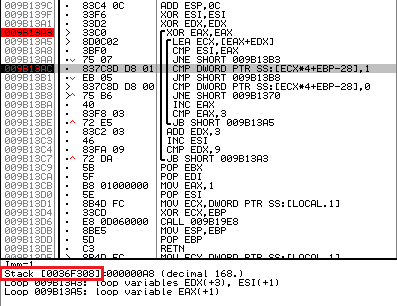
Fig. 7. Determining the address of the validation table
In my case, the address of the table is 0x36f308 (highlighted in red).

Fig. 8. Validation table dump
We search for the algorithm in the same way that was demonstrated when solving the past with the cracks, namely:
If everything was done correctly, you will find yourself here:

Fig. 9. Algorithm for filling out the validation table.
If you compare the new algorithm with the old one, you will notice that they differ:

Fig. 10. Old algorithm (screenshot from a previous article ) The
presentation of the “new algorithm” in Python is as follows:
Let's move on to finding the data that is used by this algorithm.
After analyzing the algorithm code, two places were found where the data for its operation comes from:
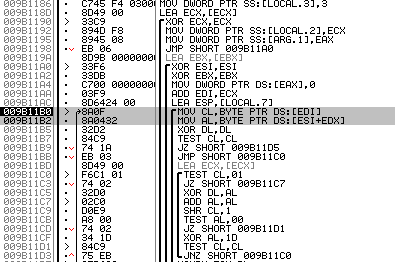
Fig. 11. Arrays with which the new algorithm operates.
Above, they are marked with a gray rectangle. In my case, at the addresses 0x9b11b0 and 0x9b11b2 , the following arrays are being accessed:

Рис. 12

Рис. 13
В каждом массиве находится 9 элементов по одному байту.
Если бы мы решали старый крякми, то мы бы сейчас перешли к поиску алгоритма превращения серийного кода во внутреннее представление, но в новом крякми было обнаружено существенное отличие от поведения старого крякми, поэтому ниже дана информация об отличиях, которые заключается вот в чём.
В старой версии крякми работа с серийным кодом происходила следующим образом:
В итоге у нас получалось что-то вроде этого:
In the new version, things got a little complicated:
As a result, we get something like this:
It follows that we have a dependency on a fixed array .
I will leave the search for the serial code converter for you and I will not give it here. You can search in the same way as in the old version.
The table and the valid range are identical to the old version.
Now that all the necessary elements have been assembled, you can proceed with the decision.
The algorithm of our actions is as follows:
If you read the first article , then probably remember that to compile the required table [1, 0, 0, 0, 1, 0, 0, 0, 1] , you must have bytes that would give either “ zeros " , or " units " .
In the old version of the crack, finding these bytes was very simple. All that had to be done was to sort through the entire available alphabet and apply a few simple operations to it.
In the new version, this is much more difficult to do (but this is only at first glance and below I will explain why). In the old version, we could iterate over one element. In the new version, we have to iterate over three elements, since they are all mutually connected.
Because in the first article I did not reveal the “magic” that was actually hidden behind the search for “zeros” and “units” (in this article it will have to be revealed, although you could not do this). In my keygen, I used a function that searches for the required “zeros” and “ones”, but not in an entirely obvious way. This helped to successfully distract the most curious and put them along the path of a single case (of which the first was the cracks), i.e. if they were given (as now) one more crack, but with a different algorithm, they would have to come up with a new way to search for "zeros" and "ones", which seems to have happened to many;)
Well, okay, less words are more work.
Here is a magical “spell” that will help you find all zero and single characters:

Fig. 14
Well, we have a group of elements giving “zeros” and “ones”. How to get the desired table [1, 0, 0, 0, 1, 0, 0, 0, 1]?
The most attentive / ingenious could notice (for example, from the comments on the previous article ) that we are dealing with matrices that, when multiplied by each other, should give a unit matrix [1, 0, 0, 0, 1, 0, 0, 0, 1]. Therefore, to obtain a unit matrix, we need either two unit matrices or two inverse ones.
To get the required unit matrix, you can use the following pattern:
Where in place of y - substitute any single character, and instead of x - any zero.
You can use other patterns, you can find them using the following "spell":

Fig. 15
After replacement, you can get, for example, the following patterns:
Now that we have figured out how to obtain the required identity matrix (i.e., validation tables), we will move on to other problems.
We know the following:
It follows that, for example, part_a depends on part_1 and salt . Which in turn narrows down possible combinations for part_a . A logical question arises.
I think many have already guessed what needs to be done? That's right, use the next "spell"!
Here is one of them:
If your “spell” is successful, you will see that for part_a and part_b only 4096 options are available (more precisely, “under options”).

Fig. 16
So, now we have all the data to generate the first valid key. Of course, do not forget that we work with bytes that have an internal representation, which means that before you enter them in the window with the cracks, they still have to be restored to their normal appearance.
If you were careful, you probably noticed that all 4096 options can be divided into two groups, those with “all elements are even” and those with “all elements are not even” .
index: 0035, table: [116, 222, 172] <= All elements are even
index: 0560, table: [172, 116, 222] <= All elements are even
index: 0770, table: [222, 172, 116] < = All elements are even
index: 0117, table: [1, 229, 111] <= All elements are even even
index: 1287, table: [229, 111, 1] <= All elements are even even
index: 1872, table: [111 , 1, 229] <= All elements are not even
However, if you look at the “patterns” available to us, you will see that they all require that in each of the “options” there are both “even” and “not even” elements, that is:
Here are two matrices, which give us one:
part_a
[176, 176, 65] <= There are even and odd
[176, 65, 176] <= There are even and odd
[65, 176, 176] <= There are even and odd
part_b
[ 176, 176, 65] <= There are even and odd
[176, 65, 176] <= There are even and odd
[65, 176, 176] <= There are even and odd
valid_table = part_a * part_a
[1, 0 , 0]
[0, 1, 0]
[0, 0, 1]
Так как «варианты» с «четными» и «не четными» элементами отсутствуют – приходим к выводу, что в крякми находится ошибка. В стает закономерный вопрос.
После быстрых размышлений приходим к выводу, что ошибка кроется в фиксированной матрице [0x3, 0x5, 0x7, 0x5, 0x7, 0x3, 0x7, 0x3, 0x5]. Для получения четных и нечетных «вариантов» необходимо заменить «0x3», «0x5» и «0x7» на «0x2», «0x3» и «0x8» соответственно, либо на другой вариант, где будет два четных и один не четный элемент, например, на такие «0x4», «0x7» и «0x8» (как вариант).
This error was reported to Kaspersky Lab. They said that the version (which we are currently investigating) is a draft. After which, on the same day, a version without error was sent to everyone. True, in the new version, there were no fixed tables and it was solved even easier than this, but I will talk about this a bit later in the bonus section :)
To make sure that you performed the correct replacement (for example, if you decided to insert other characters other than “0x2” , “0x3” and “0x8” ), the following “spell” should be used:
If the bait was chosen correctly (as in our case, “0x2, 0x3, 0x8”), then in your traps (in the “Good” field) there will be at least one beast (a group consisting of three arrays). An example of output for a fixed matrix (with elements “0x2”, “0x3” and “0x8”) is shown below:

Fig. 17
As you can see, luck smiled at us, so there were as many as three wild beasts in our traps, which of course will help to set the festive table (that is, it can be used to form part_a and part_b ).
The most attentive people have already noticed that the output in the “Good” line can be divided into groups, each of which will have three lines.
[0, 144, 81]
[81, 0, 144]
[144, 81, 0]
[144, 145, 0]
[0, 144, 145]
[145, 0, 144]
[0, 144, 209]
[209, 0, 144]
[144, 209, 0]
Even more attentive must have noticed that everyone these characters are included in the sets of “zero” and “single” characters;)
Fig. 18
Well, the most ingenious (I hope) are already feasting at the big table, since they were able to track down the big beast, luring it with a similar "spell":
This is where we will end up deciding this with the cracks ... How to convert the internal bytes to normal so that they can be entered in the window with the cracks, I think you'll figure it out for yourself.
In the meantime, you understand, we will proceed to consider the new (corrected) crack. I want to say right away that everything that we have considered for this crack is relevant for the new, so we restrict ourselves to a superficial description of the principle of its work and give a link to keygen (for the more inquisitive or vice versa lazy).
In order not to get confused with the available versions, we will introduce some clarity to their numbering:
As in all previous versions of v1 and v2 .
As in the draft version of v2 (discussed above in this article).
The principle of operation is the same as in the very first version of v1 , but other mixers are used.
As in all previous versions of v1 and v2 .
Cracks of versions v2 and v3 can be found in this thread . There you will also find keygen for the new version of v3 from me Darwin .
Password for the keygen archive: Darwin_1iOi7q7IQ1wqWiiIIw
Checking the keygen for the third version with cracks:
> keygen_v3.py habrahabr.ru> result.txt
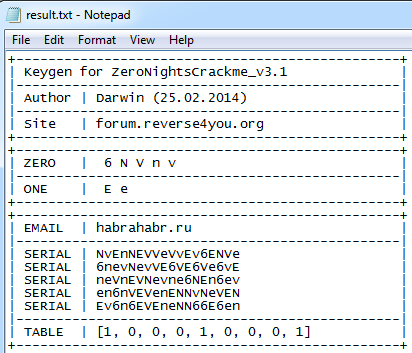
Fig. 19
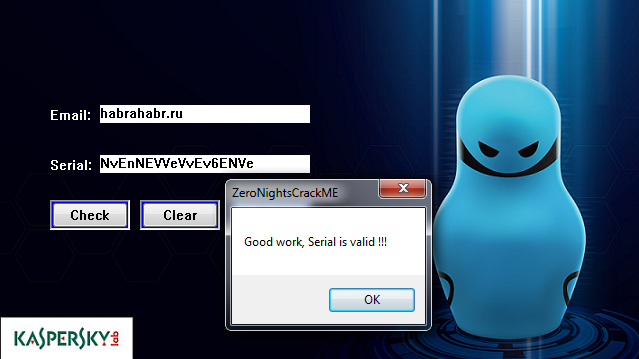
Fig. 20
Thank you all to the end! See you soon!
February 17, a letter came with a new crack. It is about his decision (and not only) that I will tell in this article.
The parameters of the crack are the same:
- File: ZeroNightsCrackMe.exe
- Platform: Windows 7 (64 bit)
- Packer: None
- Anti-debugging: Not bumped
- Solution: Mail / Serial Valid Pair
Instruments:
- OllyDbg 2.01
- Some gray matter
Let's get down to the solution ...
We go hunting
As usual, run the experimental and conduct a surface analysis. The reaction is similar to the past crack.
Fig. 1
Knowing the principle of the work of the past with the crack, we proceed to the search for key points and find:
- A function dealing with the processing of input data.
- Validation table validation algorithm.
- Validation table.
- Algorithm for filling out the validation table.
- Data for the algorithm for filling out the validation table.
- The algorithm for turning serial code into an internal representation.
- Conversion table.
- Valid character range.
Then we compare all the key points with the previous version and find the differences.
Along animal trails
Input Processing Function
First of all, we find the function of processing the entered data. This is done quite simply. Right-click in the disassembler window and select "Search for => All referenced strings" :
Fig. 2
Next, click on the line "Good work, Serial is valid !!!" and get here:
Fig. 3
Above, the desired function will be located (in my case, it is CALL 0x9b12b0 ). Three parameters are passed to her. In Arg2 , Arg1 the size of the serial code and a pointer to the serial code are transmitted, respectively, and in the ECX register a pointer to the email.
Validation Table Validation Algorithm
We go inside the function and turn to the very bottom, there is an algorithm for checking the validation table (identical to the old version):
Fig. 4
Validation Table Address
We set a breakpoint at the beginning of the algorithm and run the cracks to execute (of course, after entering any data and clicking the Check button ).
Fig. 5. Enter the test data
Fig. 6. Stop on the validation table
Now we determine the address of the table itself. You can do this by going to the line “CMP DWORD PTR SS: [ECX * 4 + EBP-28], 1” and looking at the destination address.
Fig. 7. Determining the address of the validation table
In my case, the address of the table is 0x36f308 (highlighted in red).
Fig. 8. Validation table dump
Validation table filling algorithm
We search for the algorithm in the same way that was demonstrated when solving the past with the cracks, namely:
- Continue with the crack (press F9 in Olka);
- We put the breakdown on the input data processing function, in my case it is CALL 9b12b0 (Fig. 3);
- We switch to the cracks and in the pop-up window (talking about success or failure), click "OK" (thereby continuing to work with the cracks);
- Next, click the “Check” button to start the serial number recount, after which you should stop at the call CALL 0x9b12b0;
- Standing on the call CALL 0x9b12b0, put the break on the record, at the address 0x36f308;
- And press F9 again.
If everything was done correctly, you will find yourself here:
Fig. 9. Algorithm for filling out the validation table.
If you compare the new algorithm with the old one, you will notice that they differ:
Fig. 10. Old algorithm (screenshot from a previous article ) The
presentation of the “new algorithm” in Python is as follows:
def create_table(first_part, second_part):
result = []
curr_second = 0
out_index = 0
while(out_index < 3):
inner_index = 0
while(inner_index < 3):
curr_first = 0
accumulator = 0
index = 0
while(index < 3):
first = first_part[inner_index + curr_first]
second = second_part[index + curr_second]
hash = 0
if (first != 0):
while (first != 0):
if (first & 1):
hash ^= second
second += second
first = first >> 1
accumulator ^= hash
index += 1
curr_first += 3
result.append(accumulator & 0xff)
inner_index += 1
out_index += 1
curr_second += 3
return resultLet's move on to finding the data that is used by this algorithm.
Data for the algorithm for filling out the validation table
After analyzing the algorithm code, two places were found where the data for its operation comes from:
Fig. 11. Arrays with which the new algorithm operates.
Above, they are marked with a gray rectangle. In my case, at the addresses 0x9b11b0 and 0x9b11b2 , the following arrays are being accessed:
- 0x00758628 (рис. 12)
- 0x00758908 (рис. 13)
Рис. 12
Рис. 13
В каждом массиве находится 9 элементов по одному байту.
Если бы мы решали старый крякми, то мы бы сейчас перешли к поиску алгоритма превращения серийного кода во внутреннее представление, но в новом крякми было обнаружено существенное отличие от поведения старого крякми, поэтому ниже дана информация об отличиях, которые заключается вот в чём.
Отличие старой версии от новой
В старой версии крякми работа с серийным кодом происходила следующим образом:
- Серийный код разбивался на две части.
- Каждая часть переводилась во внутреннее представление.
- Затем каждая часть микшировалась (перемешивалась).
- После чего обе части передавались алгоритму заполнения таблицы валидации.
В итоге у нас получалось что-то вроде этого:
Serial
|- part_1
|- part_2
part_1 = intermediate_view(part_1)
part_2 = intermediate_view(part_2)
part_1 = mix(part_1)
part_2 = mix(part_2)
valid_table = algo(part_1, part_2)In the new version, things got a little complicated:
- The serial code is split into two parts.
- Each part of it is translated into an internal representation.
- The first part + fixed array (3, 5, 7, 5, 7, 3, 7, 3, 5) is transferred to the algorithm.
- The second part + fixed array (3, 5, 7, 5, 7, 3, 7, 3, 5) is transferred to the algorithm.
- The result of items 3-4 is passed to the algorithm for filling out the validation table.
As a result, we get something like this:
Serial
|- part_1
|- part_2
part_1 = intermediate_view(part_1)
part_2 = intermediate_view(part_2)
part_1 = mix(part_1)
part_2 = mix(part_2)
salt = [3, 5, 7, 5, 7, 3, 7, 3, 5]
part_a = algo(part_1, salt)
part_b = algo(part_2, salt)
valid_table = algo(part_a, part_b)It follows that we have a dependency on a fixed array .
The algorithm for turning serial code into an internal representation
I will leave the search for the serial code converter for you and I will not give it here. You can search in the same way as in the old version.
Conversion table and valid range
The table and the valid range are identical to the old version.
Preparing a rookery for an ambush
Now that all the necessary elements have been assembled, you can proceed with the decision.
The algorithm of our actions is as follows:
- For algo (part_a, part_b) , find those part_a and part_b that give the result [1, 0, 0, 0, 1, 0, 0, 0, 1]
- For part_a = algo (part_1, salt) , find a part_1 that produces a result equal to part_a .
- For part_b = algo (part_2, salt) , find a part_2 that produces a result equal to part_b .
Let's start with algo (part_a, part_b)
If you read the first article , then probably remember that to compile the required table [1, 0, 0, 0, 1, 0, 0, 0, 1] , you must have bytes that would give either “ zeros " , or " units " .
In the old version of the crack, finding these bytes was very simple. All that had to be done was to sort through the entire available alphabet and apply a few simple operations to it.
In the new version, this is much more difficult to do (but this is only at first glance and below I will explain why). In the old version, we could iterate over one element. In the new version, we have to iterate over three elements, since they are all mutually connected.
And so, why does the new version seem complicated, but only at first glance?
Because in the first article I did not reveal the “magic” that was actually hidden behind the search for “zeros” and “units” (in this article it will have to be revealed, although you could not do this). In my keygen, I used a function that searches for the required “zeros” and “ones”, but not in an entirely obvious way. This helped to successfully distract the most curious and put them along the path of a single case (of which the first was the cracks), i.e. if they were given (as now) one more crack, but with a different algorithm, they would have to come up with a new way to search for "zeros" and "ones", which seems to have happened to many;)
Well, okay, less words are more work.
Here is a magical “spell” that will help you find all zero and single characters:
data_zero, data_ones = [], []
for a in range(0, 256):
part_a = [a, a, a, a, a, a, a, a, a]
part_b = [a, a, a, a, a, a, a, a, a]
result = create_table(part_a, part_b)
if result == [0, 0, 0, 0, 0, 0, 0, 0, 0]:
data_zero.append(a)
elif result == [1, 1, 1, 1, 1, 1, 1, 1, 1]:
data_ones.append(a)
print("ZERO:", data_zero)
print("ONES:", data_ones)Fig. 14
Well, we have a group of elements giving “zeros” and “ones”. How to get the desired table [1, 0, 0, 0, 1, 0, 0, 0, 1]?
The most attentive / ingenious could notice (for example, from the comments on the previous article ) that we are dealing with matrices that, when multiplied by each other, should give a unit matrix [1, 0, 0, 0, 1, 0, 0, 0, 1]. Therefore, to obtain a unit matrix, we need either two unit matrices or two inverse ones.
To get the required unit matrix, you can use the following pattern:
# Паттерн
part_a = [y, x, x, x, y, x, x, x, y]
part_b = [y, x, x, x, y, x, x, x, y]
result = algo(part_a, part_b)Where in place of y - substitute any single character, and instead of x - any zero.
You can use other patterns, you can find them using the following "spell":
happy = [1,32]
for byte_1 in happy:
for byte_2 in happy:
for byte_3 in happy:
for byte_4 in happy:
for byte_5 in happy:
for byte_6 in happy:
for byte_7 in happy:
for byte_8 in happy:
for byte_9 in happy:
part_1 = [byte_1, byte_2, byte_3, byte_4, byte_5, byte_6, byte_7, byte_8, byte_9]
part_2 = [byte_1, byte_2, byte_3, byte_4, byte_5, byte_6, byte_7, byte_8, byte_9]
result = create_table(part_1, part_2)
if result == [1, 0, 0, 0, 1, 0, 0, 0, 1]:
print("%s | %s " % (part_2, part_1))Fig. 15
After replacement, you can get, for example, the following patterns:
patterns = [
# Pattern 0
[
[y1, x1, x1, x1, y2, x1, x1, x1, y3],
[y1, x1, x1, x1, y2, x1, x1, x1, y3]
],
# Pattern 1a
[
[y1, x1, x1, x1, x1, y1, x1, y1, x1],
[y1, x1, x1, x1, x1, y1, x1, y1, x1]
],
# Pattern 1b
[
[y1, x1, x2, x3, x4, y1, x5, y1, x6],
[y1, x2, x1, x5, x6, y1, x3, y1, x4]
],
# Pattern 2a
[
[y1, x1, x1, x1, y1, x1, x1, x1, y1],
[y1, x1, x1, x1, y1, x1, x1, x1, y1]
],
# Pattern 2b
[
[y1, x1, x2, x3, y2, x4, x5, x6, y3],
[y1, x1, x2, x3, y2, x4, x5, x6, y3]
],
# Pattern 3a
[
[x1, x1, y1, x1, y1, x1, y1, x1, x1],
[x1, x1, y1, x1, y1, x1, y1, x1, x1]
],
# Pattern 3b
[
[x1, x2, y1, x3, y2, x4, y3, x5, x6],
[x6, x5, y3, x4, y2, x3, y1, x2, x1]
],
# Pattern 4a
[
[x1, y1, x1, y1, x1, x1, x1, x1, y1],
[x1, y1, x1, y1, x1, x1, x1, x1, y1]
],
# Pattern 4b
[
[x1, y1, x2, y2, x3, x4, x5, x6, y3],
[x3, y2, x4, y1, x1, x2, x6, x5, y3]
],
# Pattern 5
[
[x1, x2, y1, y2, x3, x4, x5, y3, x6],
[x4, y2, x3, x6, x5, y3, y1, x1, x2]
]
]Now that we have figured out how to obtain the required identity matrix (i.e., validation tables), we will move on to other problems.
How to choose suitable part_a and part_b?
We know the following:
part_a = algo(part_1, salt)
part_b = algo(part_2, salt)
valid_table = algo(part_a, part_b)It follows that, for example, part_a depends on part_1 and salt . Which in turn narrows down possible combinations for part_a . A logical question arises.
What combinations can we use?
I think many have already guessed what needs to be done? That's right, use the next "spell"!
Here is one of them:
# serial_data для email “support@reverse4you.org”
serial_data = [52, 233, 91, 105, 65, 15, 50, 176, 90, 40, 225, 81, 207, 79, 34, 19]
def get_items(first_part, second_part):
result = []
inner_index = 0
while(inner_index < 3):
curr_first = 0
accumulator = 0
index = 0
while(index < 3):
first = first_part[inner_index + curr_first]
second = second_part[index]
hash = 0
if (first != 0):
while (first != 0):
if (first & 1):
hash ^= second
second += second
first = first >> 1
accumulator ^= hash
index += 1
curr_first += 3
result.append(accumulator & 0xff)
inner_index += 1
return result
a = 0x3
b = 0x5
c = 0x7
first_part = [a, b, c, b, c, a, c, a, b]
second_part_new = [0, 0, 0]
count = 0
result_table = []
for byte_1 in serial_data:
second_part_new[0] = byte_1
for byte_2 in serial_data:
second_part_new[1] = byte_2
for byte_3 in serial_data:
second_part_new[2] = byte_3
res = get_items(first_part, second_part_new)
print("index: %s, table: %s" % (count, res))
count += 1
print("Count: %s" % count)If your “spell” is successful, you will see that for part_a and part_b only 4096 options are available (more precisely, “under options”).
Fig. 16
So, now we have all the data to generate the first valid key. Of course, do not forget that we work with bytes that have an internal representation, which means that before you enter them in the window with the cracks, they still have to be restored to their normal appearance.
First victim (first valid key)
If you were careful, you probably noticed that all 4096 options can be divided into two groups, those with “all elements are even” and those with “all elements are not even” .
index: 0035, table: [116, 222, 172] <= All elements are even
index: 0560, table: [172, 116, 222] <= All elements are even
index: 0770, table: [222, 172, 116] < = All elements are even
index: 0117, table: [1, 229, 111] <= All elements are even even
index: 1287, table: [229, 111, 1] <= All elements are even even
index: 1872, table: [111 , 1, 229] <= All elements are not even
However, if you look at the “patterns” available to us, you will see that they all require that in each of the “options” there are both “even” and “not even” elements, that is:
Here are two matrices, which give us one:
part_a
[176, 176, 65] <= There are even and odd
[176, 65, 176] <= There are even and odd
[65, 176, 176] <= There are even and odd
part_b
[ 176, 176, 65] <= There are even and odd
[176, 65, 176] <= There are even and odd
[65, 176, 176] <= There are even and odd
valid_table = part_a * part_a
[1, 0 , 0]
[0, 1, 0]
[0, 0, 1]
Так как «варианты» с «четными» и «не четными» элементами отсутствуют – приходим к выводу, что в крякми находится ошибка. В стает закономерный вопрос.
В чем заключается ошибка?
После быстрых размышлений приходим к выводу, что ошибка кроется в фиксированной матрице [0x3, 0x5, 0x7, 0x5, 0x7, 0x3, 0x7, 0x3, 0x5]. Для получения четных и нечетных «вариантов» необходимо заменить «0x3», «0x5» и «0x7» на «0x2», «0x3» и «0x8» соответственно, либо на другой вариант, где будет два четных и один не четный элемент, например, на такие «0x4», «0x7» и «0x8» (как вариант).
This error was reported to Kaspersky Lab. They said that the version (which we are currently investigating) is a draft. After which, on the same day, a version without error was sent to everyone. True, in the new version, there were no fixed tables and it was solved even easier than this, but I will talk about this a bit later in the bonus section :)
To make sure that you performed the correct replacement (for example, if you decided to insert other characters other than “0x2” , “0x3” and “0x8” ), the following “spell” should be used:
serial_data = [52, 233, 91, 105, 65, 15, 50, 176, 90, 40, 225, 81, 207, 79, 34, 19]
a = 0x2
b = 0x3
c = 0x8
first_part = [a, b, c, b, c, a, c, a, b]
second_part_new = [0, 0, 0]
count = 0
result_table = []
for byte_1 in serial_data:
second_part_new[0] = byte_1
for byte_2 in serial_data:
second_part_new[1] = byte_2
for byte_3 in serial_data:
second_part_new[2] = byte_3
res = get_items(first_part, second_part_new)
print("index: %s, table: %s" % (count, res))
if (res[0] % 16 == 0 and res[1] % 16 == 0 and res[2] % 16 == 1) or\
(res[0] % 16 == 1 and res[1] % 16 == 0 and res[2] % 16 == 0) or\
(res[0] % 16 == 0 and res[1] % 16 == 1 and res[2] % 16 == 0):
result_table.append(res)
count += 1
print("Count:", count)
print("Good:", result_table)If the bait was chosen correctly (as in our case, “0x2, 0x3, 0x8”), then in your traps (in the “Good” field) there will be at least one beast (a group consisting of three arrays). An example of output for a fixed matrix (with elements “0x2”, “0x3” and “0x8”) is shown below:
Fig. 17
As you can see, luck smiled at us, so there were as many as three wild beasts in our traps, which of course will help to set the festive table (that is, it can be used to form part_a and part_b ).
The most attentive people have already noticed that the output in the “Good” line can be divided into groups, each of which will have three lines.
[0, 144, 81]
[81, 0, 144]
[144, 81, 0]
[144, 145, 0]
[0, 144, 145]
[145, 0, 144]
[0, 144, 209]
[209, 0, 144]
[144, 209, 0]
Even more attentive must have noticed that everyone these characters are included in the sets of “zero” and “single” characters;)
Fig. 18
Well, the most ingenious (I hope) are already feasting at the big table, since they were able to track down the big beast, luring it with a similar "spell":
# Характеристика зверя
# [0, 144, 209]
# [209, 0, 144]
# [144, 209, 0]
a = 144
b = 209
c = 0
# Применяем один из доступных паттернов
part_a = [c, a, b, b, c, a, a, b, c]
part_b = [a, b, c, c, a, b, b, c, a]
# part_a1 = [0, 144, 209]
# part_a2 = [209, 0, 144]
# part_a3 = [144, 209, 0]
# part_a = part_a1 + part_a2 + part_a3
# part_b1 = [144, 209, 0]
# part_b2 = [0, 144, 209]
# part_b3 = [209, 0, 144]
# part_b = part_b1 + part_b2 + part_b3
result = create_table(part_a, part_b)
print(result)This is where we will end up deciding this with the cracks ... How to convert the internal bytes to normal so that they can be entered in the window with the cracks, I think you'll figure it out for yourself.
In the meantime, you understand, we will proceed to consider the new (corrected) crack. I want to say right away that everything that we have considered for this crack is relevant for the new, so we restrict ourselves to a superficial description of the principle of its work and give a link to keygen (for the more inquisitive or vice versa lazy).
Bonus (keygen + description of the new crack)
In order not to get confused with the available versions, we will introduce some clarity to their numbering:
- ZeroNightsCrackMe_v1 - reviewed here .
- ZeroNightsCrackMe_v2 - is a draft version and is described above in this article.
- ZeroNightsCrackMe_v3 - superficially reviewed below + keygen is given.
Validation table validation algorithm and validation table itself
As in all previous versions of v1 and v2 .
Validation table filling algorithm
As in the draft version of v2 (discussed above in this article).
Data for filling out the validation table
The principle of operation is the same as in the very first version of v1 , but other mixers are used.
Algorithm for converting serial code to internal representation, conversion table and valid range
As in all previous versions of v1 and v2 .
Keygen for the new version
Cracks of versions v2 and v3 can be found in this thread . There you will also find keygen for the new version of v3 from me Darwin .
Password for the keygen archive: Darwin_1iOi7q7IQ1wqWiiIIw
Checking the keygen for the third version with cracks:
> keygen_v3.py habrahabr.ru> result.txt
Fig. 19
Fig. 20
Thank you all to the end! See you soon!