40G Ethernet Performance with Intel ONS Switch

A decent number of interfaces are available today, each of which claims to be useful and necessary. Traditional Ethernet with 1G, 10G, 40G; InfiniBand FDR 56G and QDR 40G; FiberChannel 8G, 16G, promised 32G.
Everyone promises happiness and talks about their extreme need and usefulness in everyday life. What to do with it, what to choose and where are the pitfalls?
How to test:
Participated in the traditional gigabits for all, which is in every server, 40G Ethernet, QDR and FDR InfiniBand, 10G did not take. It should be noted right away that we consider FC a leaving interface, now convergence is in trend. 32G is not yet available, and 16G is out of the league of high-speed solutions.
To clarify the limits, tests were carried out to achieve minimum delays and maximum throughput, which is convenient to do using HPC methods, at the same time we tested the suitability of 40G Ethernet for HPC applications.
Invaluable assistance was provided and conducted by field tests by colleagues from the Central Control Center , to whom one Intel ONS-based switch was submitted for testing.
By the way, distribution of the switch to the most interesting project continues.
Hardware:
- 40G Ethernet Switch
- Communication adapter Mellanox ConnectX-3 VPI adapter card; single-port QSFP; FDR IB (56Gb / s) and 40GigE; PCIe3.0 x8 8GT / s
- Dual-processor system with Intel® Xeon® E5-2680 v2
- OFED-3.5 ( drivers and low-level libraries for Mellanox)
- ConnectX® EN 10 and 40 Gigabit Linux Driver
Software:
- Performance measurements were performed using the synthetic pingpong test from the Intel MPI Benchmark v3.2.3 test suite
- The version of the used MPI library S-MPI v1.1.1 is a clone of Open MPI.
In the process of preparation, the nuance of the Mellanox adapters became clear - they require a forced transfer to Ethernet mode. For some reason, the declared functionality of automatic determination of the type of connected network does not work, it can be corrected.
To evaluate the performance, “traditionally”, we look at the latency values for transmitting messages with a length of 4 bytes and the bandwidth for transmitting a message with a length of 4 MB.
Beginning of experiments:
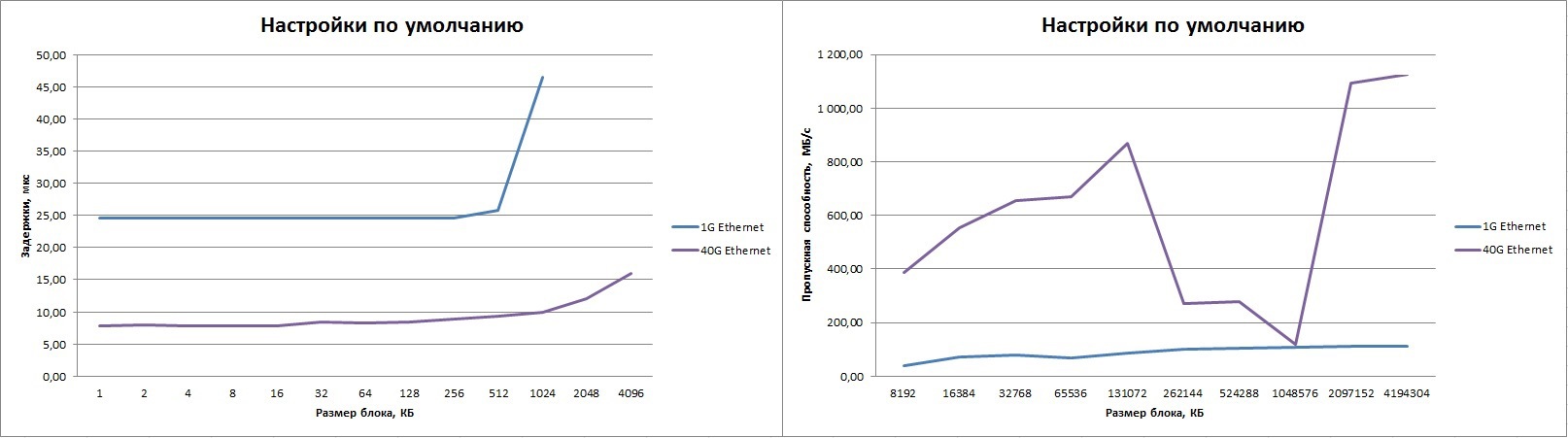
Uses the usual Ethernet mode. In our terminology, the tcp factory was used. That is, the MPI library uses a socket interface for sending messages. The default configuration of drivers, switch, and MPI.
The table on the left shows the results for 1G ethernet, on the right for 40G (with our switch). We see the “dips” in the 256K-1M message strip and the maximum result, suitable for 10G Ethernet. Obviously, you need to configure the software. The delay, of course, is very large, but when passing through the standard TCP stack, there is much to expect and is not worth it. We must pay tribute, three times better than 1G Ethernet.
Mpirun –n 2 –debug-mpi 4 –host host01,host02 –nets tcp --mca btl_tcp_if_include eth0 IMB-MPI1 PingPong | mpirun -n 2 -debug-mpi 4 -host host01,host02 -nets tcp --mca btl_tcp_if_include eth4 IMB-MPI1 PingPong |
Clickable:
Continue:
Updating the driver. We take the driver from the Mellanox website .
To reduce the "drawdown" in the range 256K-1M, increase the size of the buffers through the MPI settings: Clickable:
export S_MPI_BTL_TCP_SNDBUF=2097152
export S_MPI_BTL_TCP_RCVBUF=2097152
mpirun -n 2 -debug-mpi 4 -host host1,host2 -nets tcp --mca btl_tcp_if_include eth4 IMB-MPI1 PingPong
As a result, the improvement is one and a half times and the reduction of failures, but still small, and even the delays in small packets have grown.
Of course, to improve the bandwidth when using high-speed Ethernet interfaces, it makes sense to use extra-long Ethernet frames (Jumbo frames). We configure the switch and adapters to use the MTU 9000, and we get a noticeably higher bandwidth, which still remains at 20 Gb / s.
Clickable:
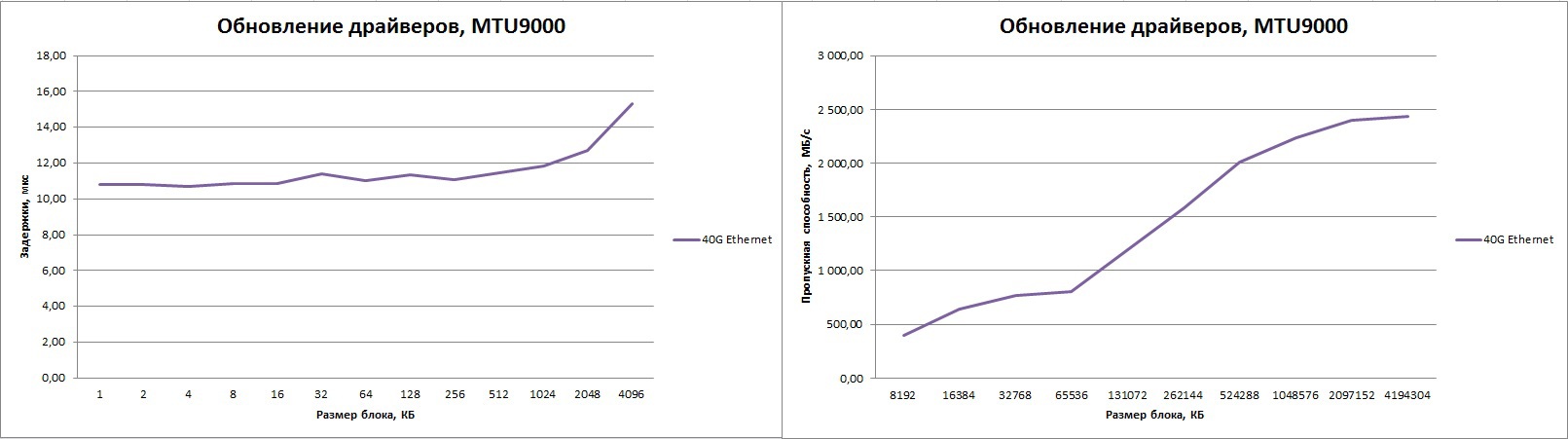
Latency on small packets is growing again.
We tried to twist other parameters, but did not receive any fundamental improvements. In general, they decided that "we don’t know how to cook them."
Which way to look?
Of course, if you look for performance, you need to do this bypassing the TCP stack. The obvious solution is to try RDMA technology.
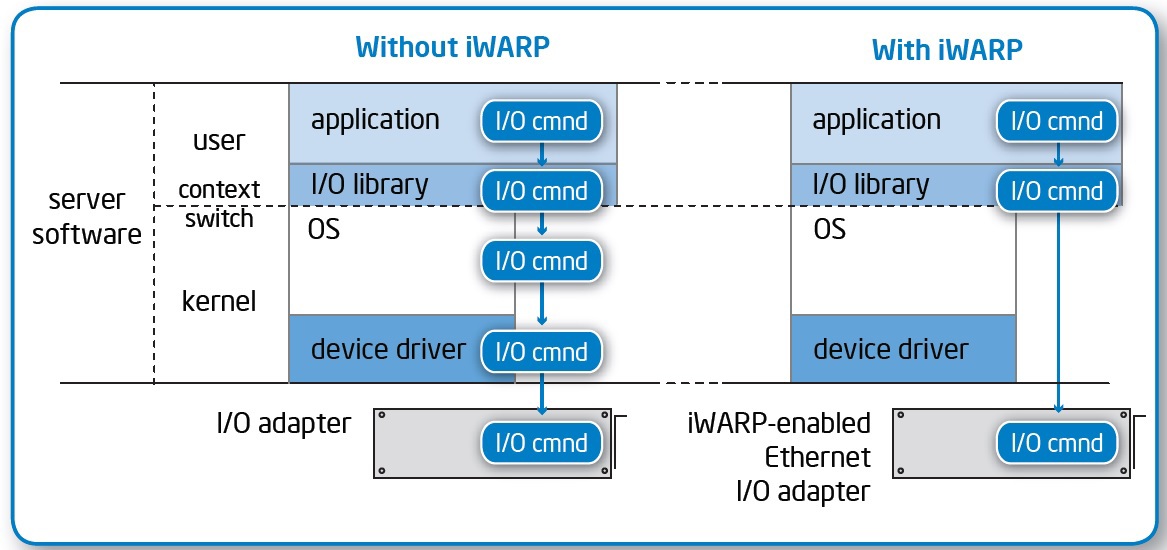
The essence of technology:
- Delivery of data directly to the user's environment, without switching the application context between the kernel and user modes.
- Data from the adapter is placed immediately in the application memory, without intermediate buffers.
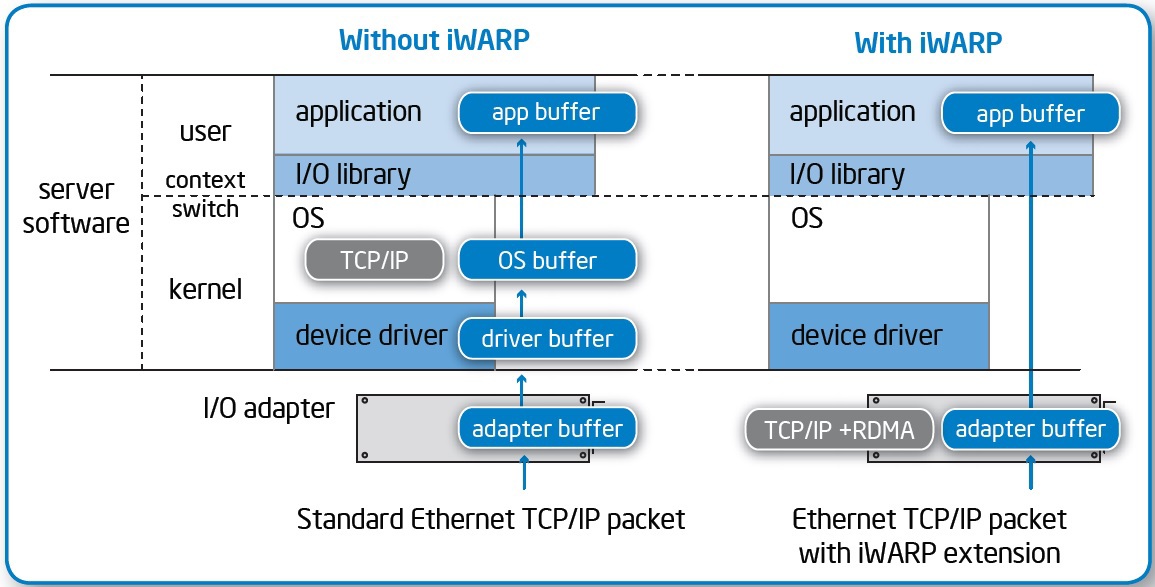
- Network controllers process the transport layer without involving a processor.
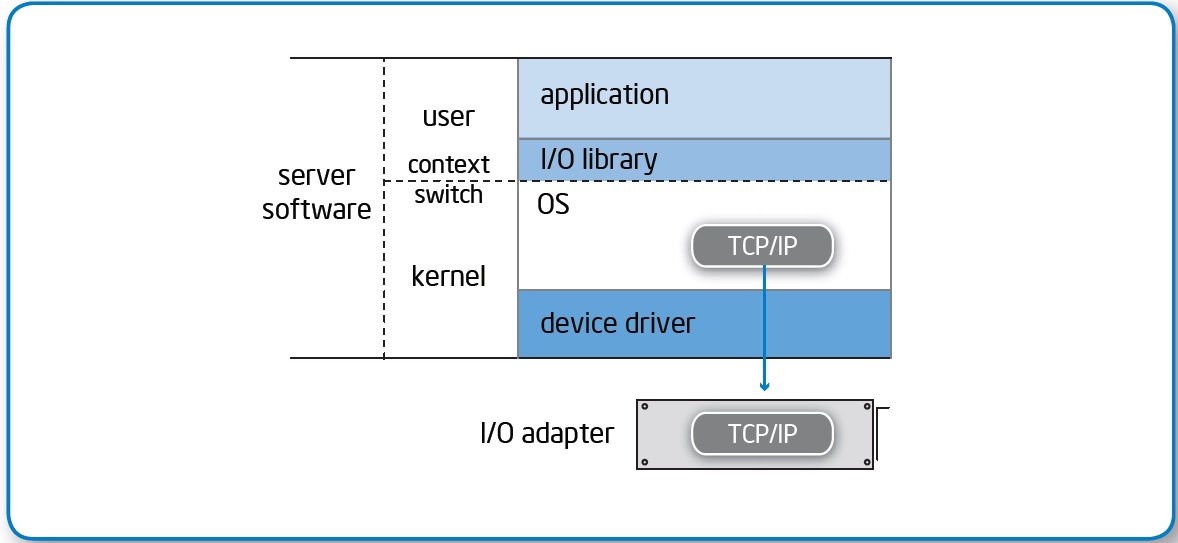
One consequence is a significant decrease in access latency.
There are two competing standards, Internet Wide Area RDMA Protocol (iWARP) and RDMA over Converged Ethernet (RoCE), their competition and the efforts of supporters to drown each other are worthy of a separate holivar and voluminous material. Pictures are for iWARP, but the essence is common.
Mellanox adapters support RDMA over Converged Ethernet (RoCE), we use OFED-3.5.2.
As a result, we got excellent numbers. The delay is 1.9 μs and the band is 4613.88 MB / s (this is 92.2% of the peak!) When using Jumbo frames. If you leave the MTU size by default, then the band will be lower, approximately 4300 MB / s.
mpirun -n 2 -debug-mpi 4 -host host1,host2 --mca btl openib,self --mca btl_openib_cpc_include rdmacm IMB-MPI1 Clickable:
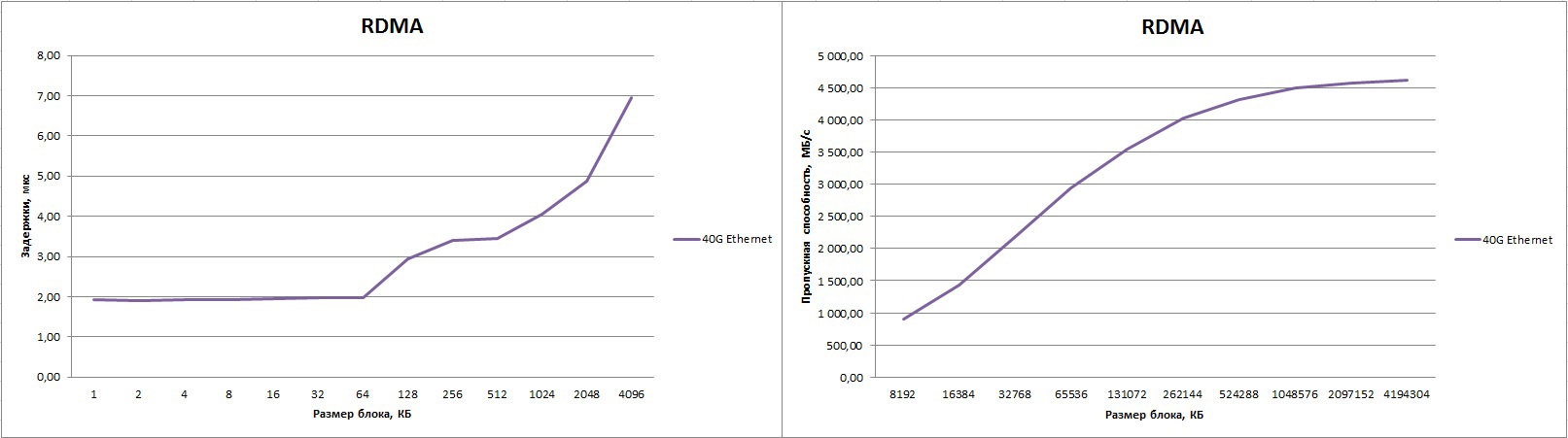
For the Pingpong test, the delay time can be improved up to 1.4 μs; for this, processes must be placed on the CPU “close” to the network adapter. What practical significance does this have in real life? Below is a small Ethernet comparative label vs InfiniBand. In principle, such a “trick” can be applied to any interconnect, so the table below shows the range of values for some network factories.
| 1G Ethernet (TCP) | 40G Ethernet (TCP) | 40G Ethernet (RDMA) | InfiniBand QDR | InfiniBand FDR | |
| Latency, usec | 24.5 | 7.8 | 1.4-1.9 | 1.5 | 0.86-1.4 |
| Bandwidth, Mbytes / s | 112 | 1126 | 4300-4613 | 3400 | 5300-6000 |
The data for 40G and FDR floats depending on the proximity of the cores on which the processes are running to the cores responsible for the network adapter, for some reason this effect was almost not visible on QDR.
40G Ethernet significantly overtook IB QDR, but before IB FDR did not catch up in absolute numbers, which is not surprising. However, 40G Ethernet is leading in efficiency.
What follows from this?
Triumph of converged Ethernet technology!
No wonder Microsoft is steadily promoting the capabilities of SMB Direct, which relies on RDMA; NFS also has RDMA support built in.
To work with block access, there are iSCSI offload technologies on network controllers and the iSCSI Extensions for RDMA (iSER) protocol, aesthetes can try FCoE :-)
When using such switches:

You can build a bunch of interesting high-performance solutions.
For example, a software-configured storage system like the FS200 G3 with a 40G interface and a server farm with 10G adapters.
With this approach, there is no need to build a dedicated network for data, significantly saving both the money for the second set of switches and the time to deploy the solution, because the cables also need to be connected and laid in half as little.
Total:
- On Ethernet, you can build a high-performance network with ultra-low latency.
- The active use of modern controllers with RDMA support significantly improves the performance of the solution.
- Intel's 400 ns cut-through latency helps get great results :-)