Event categorization architecture - Varya
The space of the surrounding World is filled with separate events and their chains - these events are reflected in the media, in the accounts of bloggers and ordinary people in social networks. One can get a picture of the surrounding reality, claiming a certain share of objectivity, only if one collects different points of view on the same problem. Event categorizer is the tool that lists the collected information: event description versions. Next, provide access to information about events to users through search tools, recommendations and visual presentation of temporal sequences of events.
Today we will tell about our system, more precisely about its software core, codenamed “Varya” - in honor of the lead developer.
We cannot yet mention the name of our startup, at the request of the Habrahabr administration, now we have submitted an application for assigning us the status of “Startup”. However, we can tell about the functionality and our ideas now. Our system ensures the up-to-date information about events for the user and proper data management - in the system, each user determines what to watch and read, manages the search and recommendations.
Our project is a startup with a team of 8 people with competencies in designing technically and algorithmically complex systems, programming, marketing and management.
Together, every day the team is working on a project - algorithms for categorizing, searching and presenting information have already been implemented. There is still the introduction of algorithms associated with recommendations for the user: based on the relationship of events, people, and analysis of user activity and interests.
What problems we solve and why talk about it? We help people get detailed information about events of any scale, regardless of where or when they happened.
The project gives users a platform for discussing events among like-minded people, allows you to share a comment or your own version of what happened. The social media platform was created for those who want to know “above average” and have a personal opinion about the main events of the past, present and future.
Users themselves find and create useful content in the media space and monitor its accuracy. We keep the memory of the events of their lives.
Now the project is at the stage of MVP, we are testing hypotheses about the functional and the work of the categorizer in order to determine the right direction for further development. In this article we will talk about the technologies with which we solve the tasks set for ourselves and share the best practices.
The task of word processing is solved by search engines: Yandex, Google, Bing, etc. The ideal system of working with information flows and highlighting events in them could look like this.
An infrastructure similar to Yandex and Google is built for the system, the entire Internet is scanned in real time for updates, and then event streams are allocated in the information flow around which the agglomerations of their versions and related content are formed. The software implementation of the service is based on a deep learning neural network and / or a solution based on the Yandex library - CatBoost.
Cool? However, we do not yet have such a volume of data, and there are no corresponding computational resources for assimilation.
Classification by topic is a popular task; there are many algorithms to solve it: naive Bayes classifiers, latent Dirichlet placement, boosting over decisive trees, and neural networks. How, probably, in all problems of machine learning, when using the described algorithms, two problems arise:
First, where to get a lot of data?
Secondly, how to place them cheap and cheerful?
Our product works with events. Events are somewhat different from ordinary articles.
To overcome the “cold start”, we decided to use two WikiMedia projects: Wikipedia and Wikinews. One Wikipedia article may describe several events (for example, the history of the development of Sun Microsystems, the biography of Mayakovsky, or the course of the Great Patriotic War).
Other sources of event information are RSS news feeds. The news is different: large analytical articles contain several events, like Wikipedia texts, and short informational messages from different sources represent the same event.
Thus, the article and the events form many-to-many links. But at the MVP stage, we make the assumption that one article is one event.
Looking at the interface of Google or Yandex, you might think that search engines are only looking for keywords. This is only for very simple online stores. Most search systems are multi-criteria, and the engine of our project is no exception. In this case, not all parameters taken into account during the search are displayed in the user interface. Our project has a list of parameters that the user chooses, such: the
subject and keywords - “what?” ; location - “where?” ; the date is “when?” ;
Those who write search engines know that keywords alone cause a lot of problems. Well, the other parameters are not so simple either.
Subject events - a very difficult thing. The human brain is designed so that he likes to categorize everything, and the real world categorically disagrees. The incoming articles want to form their own groups of topics, and they are not at all those in which we, and our enthusiastic users, distribute them.
Now we have 15 major topics of events, and this list has been revised several times, and, at a minimum, will grow.
Locations and dates are arranged a little more formally, but even here there are some pitfalls.
So, we have a set of formalized criteria and raw data that need to be mapped on these criteria. And that's how we do it.
The task of the spider is to stack the incoming articles so that they can be quickly searched. To do this, the spider must be able to attribute the topic, location and date to the articles, as well as some other parameters necessary for ranking. Our input spider receives a text model of an article built by a crawler. A text model is a list of the parts of the article and the corresponding texts. For example, almost every article has at least a heading and a main text. In fact, it still has the first paragraph, the set of categories to which this text refers its source, and the list of infobox fields (for Wikipedia and for sources that have such metadata tags). There is still a publication date. For ranking in the search engine, it will be important for us to know whether, for example, the date is found in the title or somewhere at the end of the text. A text model builds a theme model. location model and date model, and then the result is added to the index. You can write a separate article about each of these models, so here we only briefly outline the approaches.
Determining the subject matter of documents is a common task. The subject can be assigned manually by the author of the document, or it can be determined automatically. Of course, we have topics that have assigned news sources and Wikipedia to our documents, but these topics are not about events. Often you meet in the news feeds topic "Holidays"? Rather, you will meet the theme "Society." We also had this in one of the earlier editions. We could not determine what should relate to it, and were forced to remove it. And in addition, all sources have their own set of topics.
We want to manage the list of topics that we display to our users in the interface, so for us the task of defining the subject of the document is the task of fuzzy classification. The classification task requires tagged examples, that is, a list of documents to which our desired topics have already been attributed. Our list is similar to all similar lists of topics, but does not coincide with them, so we did not have a marked selection. You can also get it manually or automatically, but if our list of topics changes (and it will be!), Then manually is not an option.
If you do not have a marked selection, you can use Dirichlet's latent placement and other thematic modeling algorithms; however, the set of topics you get will be the one that turned out, not the one you wanted.
Here we must mention one more thing: our articles come from different sources. All thematic models are built one way or another on the vocabulary used. In the news and Wikipedia, it is different, even the high frequencies are different.
Thus, we faced two tasks:
1. To think of a way to quickly lay out our documents in semi-automatic mode.
2. Build on the basis of these documents an expandable model of our topics.
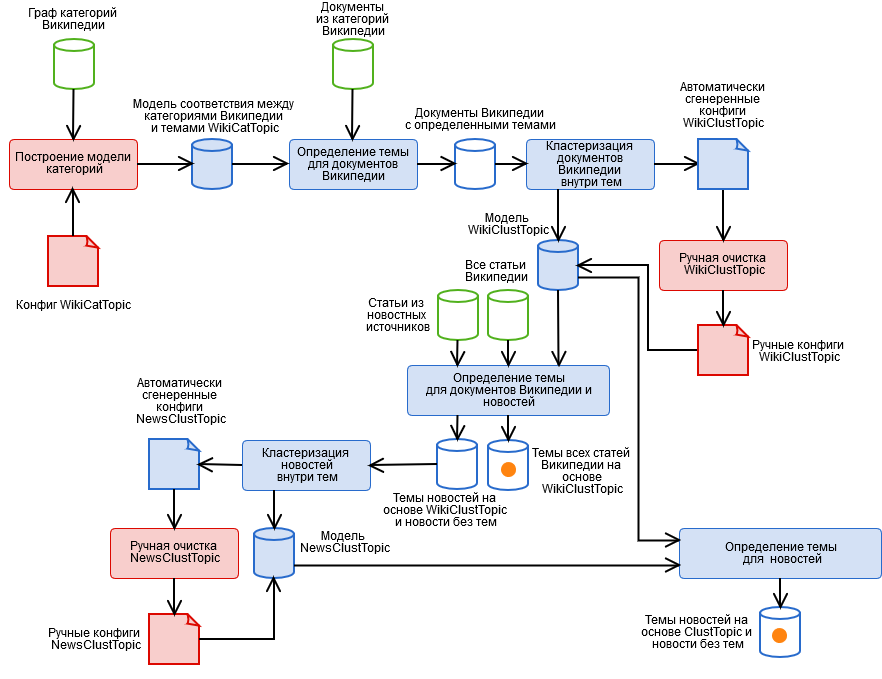
To solve them, we created a hybrid algorithm containing automated and manual stages presented in the figure.
Automatic detection of locations is a special case of the task of searching for named entities. The features of the locations are as follows:
Dates are the embodiment of formality compared to Topics and Locations. We made an expandable parser for them in regular expressions, and we can parse not only the day-month-year, but also all sorts of more interesting things, such as “the end of the winter of 1941”, “in the 90s of the XIX century” and “last month ”, Taking into account the era and the base date of the document, as well as trying to restore the missing year. About the dates you need to know that not all of them are good. For example, at the end of an article about any WWII battle there may be the opening of a memorial forty years later, in order to work with such cases, it is necessary to cut the article into events, but we are not doing it yet. So we consider only the most important dates: from the heading and the first paragraphs.
The search engine is a thing that, firstly, searches for documents on request, and secondly, orders them in descending order of relevance to the request, that is, in descending order of relevance. To calculate the relevance, we use many parameters, much more than just a trivalence: The
degree of ownership of a document to a topic.
The degree of ownership of the location document (how many times and in which parts of the document the selected location occurs).
The degree of correspondence of the document to the date (the number of days at the intersection of the interval from the request and the document dates, as well as the number of days at the intersection minus the union is taken into account).
The length of the document. Long articles should be higher.
The presence of pictures. Everyone loves pictures, there should be more!
Wikipedia article type. We are able to separate articles with descriptions of events, and they should “float” up in the sample.
The source of the article. News and custom articles should be above Wikipedia.
We use Apache Lucene as a search engine.
The task of the crawler is to collect articles for the spider. In our case, here we will assign the primary cleaning of the text, and the construction of a text model of the document. Crawler deserves a separate article.
PS We will be happy to receive any feedback, we invite you to test our project - to receive the link, write to private messages (we cannot publish here). Leave your comments under the article, or if you get to our service - right there, through the feedback form.
Today we will tell about our system, more precisely about its software core, codenamed “Varya” - in honor of the lead developer.
We cannot yet mention the name of our startup, at the request of the Habrahabr administration, now we have submitted an application for assigning us the status of “Startup”. However, we can tell about the functionality and our ideas now. Our system ensures the up-to-date information about events for the user and proper data management - in the system, each user determines what to watch and read, manages the search and recommendations.
Our project is a startup with a team of 8 people with competencies in designing technically and algorithmically complex systems, programming, marketing and management.
Together, every day the team is working on a project - algorithms for categorizing, searching and presenting information have already been implemented. There is still the introduction of algorithms associated with recommendations for the user: based on the relationship of events, people, and analysis of user activity and interests.
What problems we solve and why talk about it? We help people get detailed information about events of any scale, regardless of where or when they happened.
The project gives users a platform for discussing events among like-minded people, allows you to share a comment or your own version of what happened. The social media platform was created for those who want to know “above average” and have a personal opinion about the main events of the past, present and future.
Users themselves find and create useful content in the media space and monitor its accuracy. We keep the memory of the events of their lives.
Now the project is at the stage of MVP, we are testing hypotheses about the functional and the work of the categorizer in order to determine the right direction for further development. In this article we will talk about the technologies with which we solve the tasks set for ourselves and share the best practices.
The task of word processing is solved by search engines: Yandex, Google, Bing, etc. The ideal system of working with information flows and highlighting events in them could look like this.
An infrastructure similar to Yandex and Google is built for the system, the entire Internet is scanned in real time for updates, and then event streams are allocated in the information flow around which the agglomerations of their versions and related content are formed. The software implementation of the service is based on a deep learning neural network and / or a solution based on the Yandex library - CatBoost.
Cool? However, we do not yet have such a volume of data, and there are no corresponding computational resources for assimilation.
Classification by topic is a popular task; there are many algorithms to solve it: naive Bayes classifiers, latent Dirichlet placement, boosting over decisive trees, and neural networks. How, probably, in all problems of machine learning, when using the described algorithms, two problems arise:
First, where to get a lot of data?
Secondly, how to place them cheap and cheerful?
What approach have we chosen for an event-based system?
Our product works with events. Events are somewhat different from ordinary articles.
To overcome the “cold start”, we decided to use two WikiMedia projects: Wikipedia and Wikinews. One Wikipedia article may describe several events (for example, the history of the development of Sun Microsystems, the biography of Mayakovsky, or the course of the Great Patriotic War).
Other sources of event information are RSS news feeds. The news is different: large analytical articles contain several events, like Wikipedia texts, and short informational messages from different sources represent the same event.
Thus, the article and the events form many-to-many links. But at the MVP stage, we make the assumption that one article is one event.
Looking at the interface of Google or Yandex, you might think that search engines are only looking for keywords. This is only for very simple online stores. Most search systems are multi-criteria, and the engine of our project is no exception. In this case, not all parameters taken into account during the search are displayed in the user interface. Our project has a list of parameters that the user chooses, such: the
subject and keywords - “what?” ; location - “where?” ; the date is “when?” ;
Those who write search engines know that keywords alone cause a lot of problems. Well, the other parameters are not so simple either.
Subject events - a very difficult thing. The human brain is designed so that he likes to categorize everything, and the real world categorically disagrees. The incoming articles want to form their own groups of topics, and they are not at all those in which we, and our enthusiastic users, distribute them.
Now we have 15 major topics of events, and this list has been revised several times, and, at a minimum, will grow.
Locations and dates are arranged a little more formally, but even here there are some pitfalls.
So, we have a set of formalized criteria and raw data that need to be mapped on these criteria. And that's how we do it.
Spider
The task of the spider is to stack the incoming articles so that they can be quickly searched. To do this, the spider must be able to attribute the topic, location and date to the articles, as well as some other parameters necessary for ranking. Our input spider receives a text model of an article built by a crawler. A text model is a list of the parts of the article and the corresponding texts. For example, almost every article has at least a heading and a main text. In fact, it still has the first paragraph, the set of categories to which this text refers its source, and the list of infobox fields (for Wikipedia and for sources that have such metadata tags). There is still a publication date. For ranking in the search engine, it will be important for us to know whether, for example, the date is found in the title or somewhere at the end of the text. A text model builds a theme model. location model and date model, and then the result is added to the index. You can write a separate article about each of these models, so here we only briefly outline the approaches.
Theme
Determining the subject matter of documents is a common task. The subject can be assigned manually by the author of the document, or it can be determined automatically. Of course, we have topics that have assigned news sources and Wikipedia to our documents, but these topics are not about events. Often you meet in the news feeds topic "Holidays"? Rather, you will meet the theme "Society." We also had this in one of the earlier editions. We could not determine what should relate to it, and were forced to remove it. And in addition, all sources have their own set of topics.
We want to manage the list of topics that we display to our users in the interface, so for us the task of defining the subject of the document is the task of fuzzy classification. The classification task requires tagged examples, that is, a list of documents to which our desired topics have already been attributed. Our list is similar to all similar lists of topics, but does not coincide with them, so we did not have a marked selection. You can also get it manually or automatically, but if our list of topics changes (and it will be!), Then manually is not an option.
If you do not have a marked selection, you can use Dirichlet's latent placement and other thematic modeling algorithms; however, the set of topics you get will be the one that turned out, not the one you wanted.
Here we must mention one more thing: our articles come from different sources. All thematic models are built one way or another on the vocabulary used. In the news and Wikipedia, it is different, even the high frequencies are different.
Thus, we faced two tasks:
1. To think of a way to quickly lay out our documents in semi-automatic mode.
2. Build on the basis of these documents an expandable model of our topics.
To solve them, we created a hybrid algorithm containing automated and manual stages presented in the figure.
- Manual layout of Wikipedia categories and getting a categorical model of the WikiCatTopic theme. At this stage, the config is built, which T assigns to each of our themes the subgraph CT of the Wikipedia categories. Wikipedia is a pseudo-ontology. This means that if something is included in the “Science” category, it may not be about science at all, for example, from the innocuous subcategory “Information Technologies” you can actually come to any Wikipedia article. About how to live with it, we need a separate article.
- Automatic topic detection for Wikipedia documents based on WikiCatTopic. The document is assigned the theme T, if it is included in one of the categories of the graph CT. Note that this method is applicable only for Wikipedia articles. In order to generalize the definition of themes to arbitrary text, it was possible to build bag-of-words on each topic, and consider the cosine distance to the topic (and we tried, nothing good), but here we must take into account three points.
- Such topics contain very diverse articles, so the image of the topic in the space of words will not be coherent, which means that the “confidence” of such a model is very low in the definition of the topic (because the article is similar to one small set of articles, but not to the others).
- Any text, first of all, news, differs in its lexical structure from Wikipedia, it also does not add a model of “confidence”. In addition, some topics cannot be built based on Wikipedia.
- Stage 1 is a very painstaking job, and everyone is too lazy to do it.
- Clustering documents within topics based on the results of point 2 using the k-means method and obtaining a cluster model of the WikiClustTopic topic. A fairly simple move that allowed us to largely solve two of the three problems from paragraph 2. For clusters, build bag-of-words, and belonging to a topic is defined as the maximum cosine distance to its clusters. The model is described in our configuration files of correspondence between clusters and Wikipedia documents.
- Manual cleaning of the WikiClustTopic model, on-off-transfer of clusters. Here we also returned to stage 1, when completely incorrect clusters were found.
- Automatic detection of Wikipedia document themes and news based on WikiClustTopic.
- Clustering news within topics based on the results of point 5 using the k-means method, as well as news that did not receive the topic, and obtaining a cluster model of the NewsClustTopic topic. Now we have a theme model that takes into account the specifics of the news (as well as invaluable information about the quality of the crawler’s work).
- Manual cleaning of the NewsClustTopic model.
- Reassign news topics based on the combined model ClustTopic = WikiClustTopic + NewsClustTopic. Based on this model, the themes of the new documents are determined.
Locations
Automatic detection of locations is a special case of the task of searching for named entities. The features of the locations are as follows:
- All lists of locations are different and do not fit well together. We built our own hybrid, which takes into account not only the hierarchy (Russia includes the Novosibirsk region), but also historical changes of names (for example, the RSFSR has become Russia) based on: Geonames, Wikidata and other open sources. However, we still had to write a geotag converter with Google Maps :)
- Some locations consist of several words, for example, Nizhny Novgorod, and you must be able to collect them.
- Locations are similar to other words, especially to the names of those named after them: Kirov, Zhukov, Vladimir. This is homonymy. To cure this, we collected statistics on Wikipedia articles describing localities, in what contexts exactly the names of locations occur, and also tried to build a list of such homonyms using Open Corpora dictionaries.
- Humanity is not much strained the imagination, and very many places are named the same. Our favorite example: Karasuk in Kazakhstan and in Russia, near Novosibirsk. This is homonymy inside the class of locations. We allow it, considering what other locations are found together with this one, and whether they are parent or child for one of the homonyms. This heuristics is not universal, but it works well.
Dates
Dates are the embodiment of formality compared to Topics and Locations. We made an expandable parser for them in regular expressions, and we can parse not only the day-month-year, but also all sorts of more interesting things, such as “the end of the winter of 1941”, “in the 90s of the XIX century” and “last month ”, Taking into account the era and the base date of the document, as well as trying to restore the missing year. About the dates you need to know that not all of them are good. For example, at the end of an article about any WWII battle there may be the opening of a memorial forty years later, in order to work with such cases, it is necessary to cut the article into events, but we are not doing it yet. So we consider only the most important dates: from the heading and the first paragraphs.
Search engine
The search engine is a thing that, firstly, searches for documents on request, and secondly, orders them in descending order of relevance to the request, that is, in descending order of relevance. To calculate the relevance, we use many parameters, much more than just a trivalence: The
degree of ownership of a document to a topic.
The degree of ownership of the location document (how many times and in which parts of the document the selected location occurs).
The degree of correspondence of the document to the date (the number of days at the intersection of the interval from the request and the document dates, as well as the number of days at the intersection minus the union is taken into account).
The length of the document. Long articles should be higher.
The presence of pictures. Everyone loves pictures, there should be more!
Wikipedia article type. We are able to separate articles with descriptions of events, and they should “float” up in the sample.
The source of the article. News and custom articles should be above Wikipedia.
We use Apache Lucene as a search engine.
Crawler
The task of the crawler is to collect articles for the spider. In our case, here we will assign the primary cleaning of the text, and the construction of a text model of the document. Crawler deserves a separate article.
PS We will be happy to receive any feedback, we invite you to test our project - to receive the link, write to private messages (we cannot publish here). Leave your comments under the article, or if you get to our service - right there, through the feedback form.