Bonsai: family wiki engine
Lyrical introduction
One evening, putting things in order in the closet, I came across a large cardboard box. She survived two moves and had not opened for so many years that I completely forgot what was stored in her. It turned out that there were photos — in albums, in envelopes from a photo studio, and some were just like that.
Many photos were taken more than seventy years ago. On one was a grandfather - in his student years, still young and stately, in absolutely lamely glasses. “Wow, my grandfather wore hipster clothes even before it became mainstream,” I thought, and involuntarily smiled. I recognized him right away, but then photographs of people went on about whom I do not remember anything. In the facial features you can vaguely guess the relationship - that's all.

When I was fifteen, my grandmother repeatedly showed these cards and told about those who are depicted on them. Unfortunately, you understand the value of such stories only when there is no one to tell them. At that time, it was absolutely uninteresting for me for the tenth time to listen to some mossy stories about the pre-war years, I brushed them off and let it go. Now, suddenly having fully realized that part of the family history was irretrievably lost, I set about trying to systematize and preserve what was left.
The ideal solution for storing family data seemed to me to be a hybrid of a wiki engine and a photo album. There were no ready-made solutions, so I had to write my own. He is called Bonsaiand is open source under MIT license. Next will be the story of how it works and how to use it, as well as the history of its development and a little drama .

Another bike?
Today there are a lot of tools that allow you to make family trees and catalog information about relatives. They are conventionally divided into two large categories - online services and desktop applications.
In the case of a desktop application, the database is usually stored as a file on disk. You open the app and replenish it in single user mode. If necessary, data can be exported for backup or transfer to another system (for example, in GEDCOM format ). Of those that I watched, Gramps (free) and the native Tree of Life (requires a one-time purchase) seemed the most enjoyable to use .
The opposite side of the spectrum is web services. They store your data on remote servers and charge for periodic usage. Since this is a commercial product with a centralized base and a good monetization, services of such a plan give you the opportunity, for example, to search for lost relatives by DNA test or archival records.
The pros and cons of both options are pretty obvious. In the first case, you store the database locally and fully control access to it and the creation of backups. If the application is open source, with great need you can even add additional functionality to it. However, working with such a database together or viewing data from another device will be difficult. In the second, on the contrary, there is access from any device, but you give your data to third parties and hope for their honesty. In the history of my family there is no compromising and terrible secrets, however, I still consider this information as purely personal and in principle do not want anyone else to store or analyze it.
If we take into account the shortcomings of both these approaches, we can formulate a list of requirements for an “ideal” engine:
- Web application hosted on own server
- Create articles about people, pets, places, events, etc. like a wiki
- Download media files
- Mark people in the photo and video
- Generating a family tree automatically
- Calendar with all important dates
- Tools for co-editing and shading
To be fair, I managed to find several projects with a self-hosted implementation, but they were in a deplorable state: the appearance froze at the middle of the two thousandths, there is no complete set of the necessary functionality, and I didn’t want to dig into legacy scripts in PHP. In addition, the previous pet project was over and there was a desire to take on something new.
The golden rule says: if you want to do well, do it yourself!
The technologies used were chosen according to three criteria: my experience with them, popularity and openness-free. Here is the result:
- Runtime : .NET Core 2.1
- Backend : ASP.NET Core MVC
- Database : PostgreSQL
- Frontend logic : partly Vue, partly jQuery.
- Frontend styles : Bootstrap + Sass
In secondary roles - Elasticsearch for full-text search and ffmpeg to get screenshots from the video.
Data schema
The main objects in the Bonsai database are the page and the media file . They are linked by a many-to-many relationship through the marks . A mark may have a title without a link - for example, if you need to mark someone in a photo, but there is no information on a full page about it.
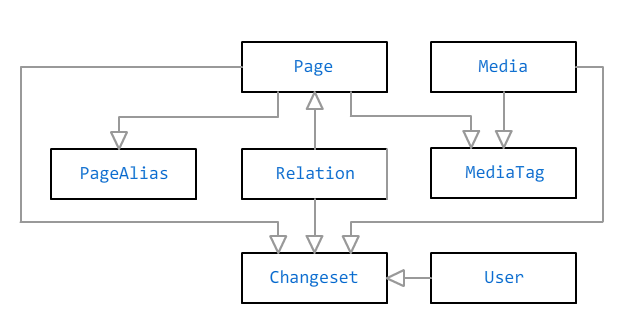
In addition to free-form text, facts may be indicated on the page.which are entered into special fields in the admin panel. Facts are used to calculate additional data: for example, if you specify the date of birth of a person, then it will be marked in the calendar, and on its page you will see the current age (or life expectancy, if the date of death is also indicated), by gender you can determine the correct name of the relationship "Or" mother "instead of the general" parents "), and so on. The facts are stored in the database as a JSON document.
There are five types of pages available to choose from: person, pet, event, location, and other. The list of available facts depends on the type of page: for example, “education” is relevant only for a person, “date of birth” for a person and an animal, and “address” only for a place.
Pages linked by relationship: "Parent", "spouse", "friend", "owner", "resident" and many others. Some relationships may be limited in time (spouse, owner, resident), others are considered permanent.
When saving any page or relationship, the resulting model is checked for consistency. For example, years of spouses' life must intersect , a person cannot have more than one biological parent of each sex, and it is also impossible to become your own dad . Same-sex marriage, however, is permissible.
Editing a page, media file or relationship saves the change to the base . This allows you to store the history of edits and roll back them, if necessary.
Relations
Relationship is one of the most ancient concepts in society. Already in the Proto-Indo-European language, there were many names for them, which, in a slightly modified form, migrated to the modern languages of various groups: the word “mother” will be understood by both Russian, Englishman, and Chinese.
There are a lot of relationship options, but three of them are basic: parent , child and spouse. They allow you to build a directed graph from a family, where these relationships are edges, and people are nodes. On this column, you can express any other relationship, knowing the path between the participants and their gender: for example, to determine someone's grandfather, you must first find his parent (of any gender), and then the parent of this parent (male), and so on.
In the Bonsai admin panel, you can enter the relationships of these three basic types. For each relationship, the opposite will be automatically created - the parent for the child, the spouse for the spouse, the owner for the pet. All additional relationships are calculated by the engine and shown on the sidebar on the page:
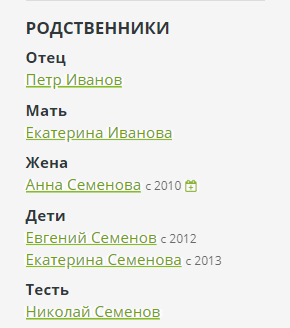
To calculate relationships, an elementary bypass of the graph is used, and the relationship names are specified as a special DSL:
publicstatic RelationDefinition[] ParentRelations =
{
new RelationDefinition("Parent:m", "Отец"),
new RelationDefinition("Parent:f", "Мать"),
new RelationDefinition("Parent Child:m", "Брат", "Братья"),
new RelationDefinition("Parent Child:f", "Сестра", "Сестры"),
new RelationDefinition("Parent Parent:m", "Дедушка", "Дедушки"),
new RelationDefinition("Parent Parent:f", "Бабушка", "Бабушки")
};
Even a direct family member can have a lot . Bonsai divides connections into the following groups:
- The closest blood relationship is the family in which the person grew up: mother and father, grandparents, brothers and sisters. If you look at the graph, then this way is 1-2 steps up and 1 sideways.
- Own family : one group for each spouse and children from him. This also includes relatives of the spouse - mother-in-law, brother-in-law and the like.
- Other : more distant relatives (grandchildren, uncle-aunt) and non-kinship (friends, colleagues).
Sometimes one way to determine group membership is not enough. The data may be incomplete, but they still need to be shown as adequately as possible. Consider the following kindred graph:
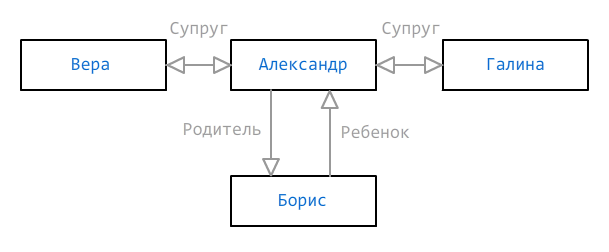
As we see, for Alexander there are two wives (Vera and Galina) and a son (Boris), but we don’t know which of the wives is the mother of the child - maybe it’s some third woman, but she’s not yet added. For such cases, several paths may be indicated, which must exist or not exist, and they are marked with signs
+and, -accordingly:new RelationDefinition("Spouse Child+Child", "Сын|Дочь|Ребенок", "Дети")
new RelationDefinition("Spouse Child-Child:m", "Пасынок")
new RelationDefinition("Spouse Child-Child:f", "Падчерица")
Genealogical tree
Any decent genealogical engine should be able to build a family tree. This is the most visual way to show general information about people and their relatives. Data is stored in the database as a directed graph and, in theory, it should be easy to visualize. In practice, it is precisely with the display of the tree that the greatest difficulties arose.
Here are some examples of how family trees might look like:

Pedigree Targaryen. Very compact because it is made by hand. It will be extremely difficult to automatically generate such a tree from arbitrary data.
Greek gods. The graphical representation is generated from the special markdown syntax.in which you still need to manually arrange all the blocks and draw the links between them. A bit like ASCII-art.

Representation of a tree in the form of a semicircular diagram. Easily generated automatically, but takes into account only direct ancestors.
I looked through many options. The most aesthetically pleasing was on the site MyHeritage:
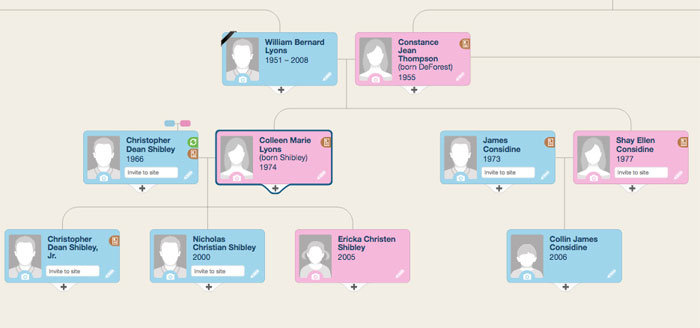
Drawing such a tree can be divided into three conditional steps: obtaining data from the database, placing blocks / connecting lines, and directly displaying them on the page. If with the first and third steps everything was trivial, then on the second I stumbled.
Attempts to sketch a self-made decision in haste ended in complete fiasco. A competent arrangement of elements of a graph is such a complex area that dissertations are written on it , andready-made components are like an apartment in Moscow. Okay, the most write will not work, but surely there are decent free solutions?
Most of all I pinned my hopes on the D3.js library . Perhaps this is the first thing that comes to mind when you need to draw a graph or chart on a web page. Alas, among more than three hundred (!) Examples on the wiki there was not one more or less similar to the tree with MyHeritage.
The next step was to dive into the libraries, which dealt not with drawing, but with the calculation of the optimal arrangement of elements in the graph. Most of them offer a so-called Force layout.. This is a very simple approach that is based on physical formulas: the nodes of the graph are represented by elastic bodies, and the connecting lines are represented by springs. It can be easily recognized by the characteristic animation - the graph seems to be “straightening out” on the go, and this is not an additional feature, but the inevitable consequence of the simulation nature of the algorithm. The force-layout approach is good for visualizing data without a clear hierarchy (for example, social networks), but the family tree in this form looks defective.
Another option considered is the Graphviz library . The result of her work can be easily recognized by the characteristic arrows. A special language DOT is used to describe the graph.. Test examples look more or less, but problems arise with real data: the arrows “break down” and connect at strange angles, the graph is spreading, and this cannot be tuned and bypassed.
Not finding the right solution on my own, I decided to order it on freelancing, and here that same DRAMA began .
The order was placed on the morning of October 22 and within an hour several responses were received. One of the respondents was named Vladislav; He sent an example of a similar solution and promised to complete the task in one day.. Such a rate seemed suspicious to me, but I hoped for his experience and to myself I gave the guy an error of a week. The first couple of days Vladislav asked additional questions, never ceasing pleasantly to surprise him with a deep immersion in the project and attentive attitude to details, and then he disappeared. He woke up on November 1, apologized for the enforced disappearance for family reasons and sent a link with a beta version that looked quite similar to what was desired if it were not for the node in the connecting lines in the center:
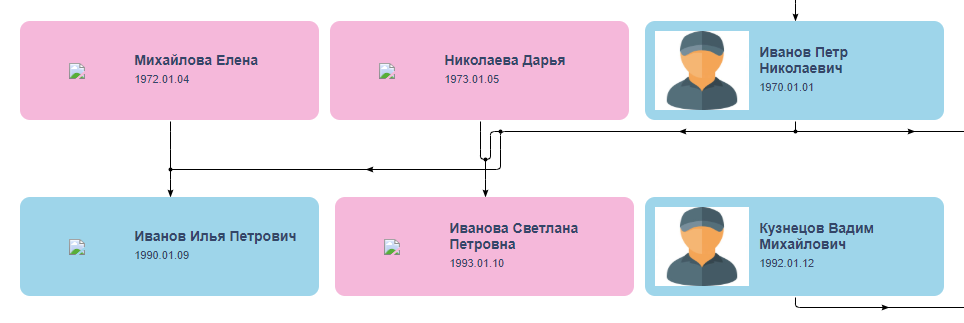
The disappearance of the performer is always a wake-up call, but anything can happen, anything happens, because he did something. Let him continue! I sent a prepayment and waited for improvements. A couple of days later, Vladislav wrote that he could not fix the problem, and then disappeared again - this time for three weeks. During this time, he did not do anything and refused to return the prepayment, because "the task was actually done by a stupid former friend who let him down and did not give the money." After a couple of clarifying questions, the pragmatic delegator stopped trying to otmazyvatsya and just stopped. So now we live - from time to time I remind him about the debt, and he responds by sending a screenshot from the banking application - they say, "there is no money, but as soon as - so immediately." I wish Vladislav success in business and get rich quicker!
Throw the kid - minus in karma!
Losing money was not so annoying, but a whole month passed, and the task did not get off the ground, and now there was nowhere to wait for help. First of all, I was angry with myself: I took the path of least resistance, broke the golden rule - and this is the result. Being filled with righteous anger, I re-sat down to study the libraries for drawing graphs and - lo and behold! - suddenly found exactly what you need.
The library was called the Eclipse Layout Kernel , abbreviated as ELK. As you might guess, it is used to display diagrams in the Eclipse IDE, but it can also be used offline. In general, it is written in Java, but there is a version translated into JS. Yes, her code is horribleand weighs one and a half megabytes, but these shortcomings can be forgiven for the fact that it simply works and does exactly that and exactly as it should. The interface is elementary: nodes, edges and settings are transmitted to the input, and at the output we get coordinates. You can draw a tree on them in any convenient way: I chose SVG for connecting lines and divs with absolute positioning for blocks.
The integration of the library and the selection of the optimal settings took two nights to do. This, of course, is not “one day”, as promised by my hapless and arrogant freelancer, but rather close. As a result, Bonsai was able to display a tree in approximately the following form:
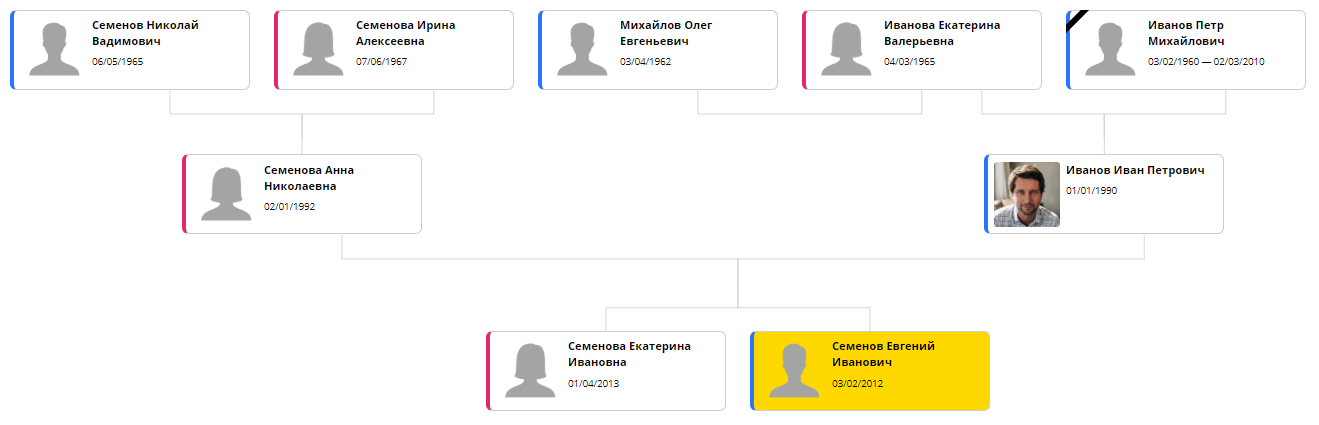
Now the only problem left is the processing time. ELK uses an iterative algorithm: you can get closer to optimal placement by spending extra time. On a tree of 20-30 elements a good result requires about 5 seconds. Because of this, the tree page every time opens for a long time, and this quickly begins to annoy. By the next version, the calculation will be transferred to the backend, so that it can be done once when the page is changed and cashed.
Full text search
A system for storing textual information would be useless without convenient full-text search. Bonsai uses the PostgreSQL database, so first of all I decided to check what it can offer out of the box. Another disappointment:
tsvectorcoping with ordinary words, but the search for the most important thing - the names and surnames - completely refuses:SELECT
to_tsvector('Проверки') @@ to_tsquery('Проверка'), -- true
to_tsvector('Иванов') @@ to_tsquery('Иван'), -- false
to_tsvector('Иванова') @@ to_tsquery('Иван'), -- false
to_tsvector('Иванова') @@ to_tsquery('Иванов'), -- false
to_tsvector('Иванов Иван Иванович') @@ to_tsquery('Иванова') -- falseTrigrams also did not give anything good. As a result, I settled on a rather expected version: ElasticSearch + Russian Morphology . It turned out to be very inconvenient to work with him from .NET, but he copes with the search for the full name on a solid top five.
Conscious imperfection
When working on a project, situations regularly arose when the perfectionist infuriated the chosen solution . The subject area is rather non-standard and the generally accepted “rules of good tone” do not always work.
For example, what happens when we open any page?
- The text of the page is compiled from Markdown to HTML. If the text contains links to other pages and media files, you will have to go to the database for more information.
- Facts are deserialized from JSON, in which they are stored in the database, in the view model.
- Kinship ties are determined. To do this, from the long-suffering base, you need to get the entire graph of links and find nodes in it according to a previously known list of paths.
At first glance it seems that this is a terribly difficult operation, but in reality this is not so because of the relatively small amount of data. How many relatives can you remember and want to record? Try to count them for the sake of interest and you will find that it will be very difficult to score at least a hundred. And how many people want to give access? Even an astronomically large number for a family - a thousand people! - By the standards of modern databases remains ridiculous.
Of course, the compiled view model of the page is still cached the first time it is opened and reused on subsequent ones - primarily because it was very easy to implement. The rule of invalidation of the cache with changes in the admin panel is also taken as simple as possible: if we change only the text and some local onesfacts (list of languages, blood type, hair color, etc.), then it is enough to reset this particular page. For any other change - the name of the page, date of birth or gender, adding or changing any connection - the cache is reset completely . Yes, this is not the smartest way to clean. Yes, for sure one could write a complex algorithm that would drop only what is needed - but for this project it would not justify the costs.
The project does not support localization and change of appearance, authorization works on OAuth on Facebook \ Google, and the admin panel is made on ordinary forms, and not on any SPA framework on the latest fashion. All this could be implemented or improved, but it would not solve any problem, and therefore time would be wasted.
Looking forward to the future
Another reason why it makes no sense to invest in the complexity of the engine device is an ephemeral implementation compared to the data it stores. Consider for a minute: the web in its current form has been around for almost twenty years, and family history implies storage for centuries . No one has yet solved this problem simply because the information technology industry itself is much smaller. What can be done?
The engine will have to be regularly rewritten from scratch - just as over the course of thousands of years, the monks diligently copied texts from dilapidated books into new ones. The only difference is that the book can lie for a hundred years with proper treatment, and the application - on the force of 15-20 years. I hope that in twenty years I will still be able to do it on my own, but in another twenty I will have to do this to my children or grandchildren. I want to leave them a simple, understandable and documented source.
At the very first stages of design, I wanted to build in a certain SQL-like language with the help of which one could get answers to specific questions: “what percentage of my ancestors with blue eyes,” “when Ivan bought the first car,” and so on. This idea had to be abandoned, because it would have required instead of the usual text to bring all the information in a kind of formalized form, and only the description of this type would take years. On the other hand, Natural Language Understanding is now gaining momentum. I would not be surprised if in a decade or two it will be possible to ask Siri to read the text for you, follow the links and finally present a squeeze from the facts. Guys, push!
How to try?
Unfortunately, I can not provide a link to the finished demo: there is no server that could withstand the habraeffect. But there are several visual screenshots (pictures are clickable). If Bonsai seemed useful to you and you want to run it yourself, the source code can be downloaded from GitHub: https://github.com/impworks/bonsai Detailed installation instructions are listed in the Readme. You will need this:



- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.x and Russian Morphology plugin
- Facebook or Google app for oAuth authorization
After the first launch, several test pages and photos are created in the database. For production this behavior is not necessary and is disabled by the flag in the settings.
Just a month ago, I launched my own instance and started testing it, getting real data. Some rough spots are found, but otherwise I’m completely satisfied with the result. Now the project will gradually develop and be finalized. The primary tasks are to speed up the display of the tree, allow downloading of documents as PDF and add fine-tuning of access rights. It would be good to improve the usability of the admin in some places or to make automatic recognition of faces in the photo - but this is not certain .