Search for solutions in logical games using the example of homoku
Introduction
In general, we are not talking about the classic homoku , but about the Russian variation “five in a row”. You have a piece of paper in the box. The rules of the game are the same as in tic-tac-toe. The only difference is that it is necessary to build a line of 5 elements.
For such a simple game, we listened to more than one lecture. I was always annoyed that my brilliant strategy is breaking up on my own carelessness. Well, nothing, I thought, I’ll write a program that will not make mistakes, then I will show them all! Time to spit! A couple of cycles, however, I have to tinker with the user interface, but I can handle it in a couple of evenings. 10 years have passed since graduation, but I still haven’t written a program.
Brute force
The idea is that we have no evaluation function, no heuristics. We simply place the elements on the field until we reach five in a line. It immediately becomes clear that such a method is not suitable. Each move generates an average of 80 new positions. By 6 moves, the number of options increases to 80 ^ 6 = 2 ^ 37 options, which is too much.
Alpha beta clipping
Alpha beta clipping is what the game theory course at the institute usually limits itself to. Applies ... honestly it's hard to come up with a game in which it can be applied. There is an idea to use the valuation function as a criterion of value. The problem is that we are only really interested in victory or defeat. And we are quite happy with the victory for a greater number of steps. An important property comes up from here: to prove victory from a certain position, it is enough to find one move, and to prove defeat, it is necessary to sort out all possible moves .
Decision from the end
The idea is to recognize patterns that lead to victory. The analogy with chess programs is the endgame base.
This can be done for the game "5 in a row"
The game always ends with a line of 5 elements. If we go back one step, we get the following combinations:

If we go back two steps, we get:

Lines can be combined:

The entire set of combinations can be assembled into a search tree that unfolds around the search point.
If we go back two steps, we get:
Lines can be combined:
The entire set of combinations can be assembled into a search tree that unfolds around the search point.
This solution was implemented, but it worked slowly. So slow that I couldn’t debug the code. The problem is a lot of combinations. Two steps back is all that can still be stored in memory.
Calculation vs. storage
After such a file, I decided not to store ready-made templates, but to find lines for one or two moves before winning “on the fly”. Surprisingly, this worked pretty well. Conclusion: sometimes it’s better to decide than to store .
For optimization purposes, I limited the number of possible moves to two adjacent cells around the existing ones. In general, it is far from the fact that effective moves are limited to these cells, but so far my assumption is in good agreement with practice.
Deep or wide
A deep search is preferable from the point of view of memory, but often goes too deep, although the victory is nearby in the next branch. A breadth-first search is devoid of this drawback, but requires a lot of memory to store already resolved positions. Usually, a forced deep search is used: the search goes down to a fixed depth, but for promising positions, the depth increases.
Evaluation function
Search speed is very sensitive to crawl order. To do this, they introduce a function that evaluates the “attractiveness” of moves and arranges them according to the criterion of such attractiveness.
Evaluation function of the game "5 in a row"
There are lines to which the adversary needs to react.
Open Four. Guaranteed victory if the opponent does not win the next turn.

Closed Four. One move to victory.

Open triple. Two moves to win.

The priority of the lines in that order. The course score increases if several lines of different directions converge at one point. Also, enemy lines and defensive moves on them are taken into account.
Open Four. Guaranteed victory if the opponent does not win the next turn.
Closed Four. One move to victory.
Open triple. Two moves to win.
The priority of the lines in that order. The course score increases if several lines of different directions converge at one point. Also, enemy lines and defensive moves on them are taken into account.
It works pretty well. The program plays at the beginner level. These are 2 levels of search in width and 3 levels of forced search in depth. Unfortunately, this is not enough to always win. On this, my ideas ended, and I already thought that nothing could be significantly improved. If I had not stumbled upon the work of a certain Louis Victor Allis .
Mr. Allis and Treat-Space search
In 1992 Mr. Allis, using 10 SUN SPARC workstations, proved for the classic homoku with a 15X15 field that crosses always win. The stations had 64 and 128MB RAM, 200MB swap. Because they used the Vrije Universiteit stations in Amsterdam, their processes started only at night. Processes that did not end in the night were killed in the morning. It took 1000 CPU / hours and a week of time.
How the hell did he do it?
A bit of theory from the original article. Gomoku is a diverging game with full information and sudden death.
The upper limit of the number of states ( state-space complexity ) 3 225 ~ = 10 105 . 10 70 - the complexity of the decision tree ( game-tree complexity ) if there is an assumption that the average game lasts 30 moves and has 225 - i possible moves on the i-th move.
Watching professional players, Alice concluded that a person is primarily looking for a chain of threats ( threat sequence ), which can lead to victory. At the same time, the enemy’s retaliatory moves are almost completely ignored. Only if a suitable chain is found is it possible to counterattack.
On this fact the heuristic Treat-Space search is built. For each attack line with an attack cell ( gain ), which is based on already existing rest squares , we respond immediately with all defensive moves ( cost squares ). After that, we check whether it is still possible to build a chain of threats that leads to victory.

The beginning of the chain of threats and its development

Analysis of the chain of threats. We respond to the first threat with three defensive moves at once. Despite the reciprocal moves, it is possible to build an open four.
Such a heuristic allows us to efficiently search for chains of threats that the adversary is no longer able to influence. The answer at the same time with all the protective moves allows you to make the search complexity almost linear, rather than combinatorial. Of course, each chain must be checked for the possibility of counterattacks.
- Divergent ( diverging ) called the game in which the number of possible positions is growing with the increase in the number of pieces on the board.
- By perfect-information is meant that both opponents are fully aware of the current state of the game. Examples of games with full information: checkers, chess. Examples of games with imperfect-information are a fool, preference.
- Sudden death ( Sudden death ) means that the game can suddenly end when there are more pieces on the board, or there is a free space. Chess is an example of a game with sudden death. A game where this does not happen is checkers.
The upper limit of the number of states ( state-space complexity ) 3 225 ~ = 10 105 . 10 70 - the complexity of the decision tree ( game-tree complexity ) if there is an assumption that the average game lasts 30 moves and has 225 - i possible moves on the i-th move.
Watching professional players, Alice concluded that a person is primarily looking for a chain of threats ( threat sequence ), which can lead to victory. At the same time, the enemy’s retaliatory moves are almost completely ignored. Only if a suitable chain is found is it possible to counterattack.
On this fact the heuristic Treat-Space search is built. For each attack line with an attack cell ( gain ), which is based on already existing rest squares , we respond immediately with all defensive moves ( cost squares ). After that, we check whether it is still possible to build a chain of threats that leads to victory.
The beginning of the chain of threats and its development
Analysis of the chain of threats. We respond to the first threat with three defensive moves at once. Despite the reciprocal moves, it is possible to build an open four.
Such a heuristic allows us to efficiently search for chains of threats that the adversary is no longer able to influence. The answer at the same time with all the protective moves allows you to make the search complexity almost linear, rather than combinatorial. Of course, each chain must be checked for the possibility of counterattacks.
Unfortunately,
Zero-stroke heuristic
Best described here .
The idea is that you skip your turn, allowing the opponent to make a move. If your position still remains strong, then this state is probably not what the enemy will allow you to fall into. This saves one move in depth when analyzing.
Unfortunately, I have not figured out how to safely and effectively apply it, so I do not apply it yet.
Crosses win and decision tree
With Treat-Space search heuristic, the program plays pretty hard, but still loses to a strong player. This is because the program is able to “see” 4 to 16 moves forward. Sometimes, especially at the beginning of a game, it’s more profitable to put moves in perspective, rather than trying to develop a local advantage. A person uses his experience to see areas that will give an advantage in the long run.
So we come to another problem of computer programs - lack of experience ( lack of experience ). To compensate for this, the chess program uses the opening base. You can make a game like "Five in a row." The problem is that
Therefore, a natural desire arises to sort out the entire decision tree in order to find the best moves. As a bonus, you can get proof that the crosses win, and the optimal sequence as a bonus. Actually, this was what Professor Alice did in his study.

The longest chain with a perfect game for a homoku with no limits

The longest chain with a perfect game for a homoku with limitations
According to theory, the field 19X19 gives crosses a greater advantage than 15X15, so everything should be even easier for an unlimited field.
Distributed computing on the knee
It immediately becomes clear that this cannot be counted on one machine. On the other hand, the task parallels very well.
So, we need to raise the infrastructure for distributed computing.
Quickly blinded a server based on nginx, php-fastcgi, wget, scripts and my programs.
I had to tinker with the base, its size was supposed to be very large and access to the elements is very common. I had significant experience with PostgreSQL, but it did not suit me, because even if the data fits in the same place on the disk, this DBMS still places them at the end of the table due to transactionality. Thus, if one element changes frequently, then the table swells quickly. It is necessary to vacuum it, but on a loaded server this is problematic. Instead, I gave birth to my bike, which used a mix of AVL-tree and directory structure as the base. When a tree exceeds a certain limit, it splits into two in different directories. It turns out such a hash tree. In practice, this turned out to be a bad decision. Firstly, the AVL tree is a bad choice for working with a disk. At the time of separation, the data arrives in a new tree in sorted order - this is the worst option for balancing. Secondly, practice has shown that accumulating such a number of computing resources so that the database becomes a bottleneck is quite problematic, and PostgeSQL would have completely suited me.
As computing nodes, I planned to use “cheap” cloud services. I used both Scalaxy and Amazon. Suddenly I realized that computing was worth the real money.. Scalaxy gave 16 cores to the server, it cost me, it seems, $ 10 / day. At the same time, 16 processes worked somehow very hard. On Amazon, I tried to launch 2 instances of 8 cores, and this also cost a significant amount. I also tried to take in quantity and use 50 micro-instances, which cost me $ 40 per day. According to my feelings, they worked worse than 2 servers with 8 cores. This made me wonder how much the calculations actually cost. At that time, I needed 10,000 cores. Let's say we got iron for free. Let's say we have 2-processor 8-core Xeon, with hyper trading. Total we need 10000 / (2 * 8 * 2) = 312.5 servers. Let's say such a server eats 200W. Total per day we need to pay 312.5 * 200W * 24h = 1.5MW * h * 0.11875 $ / (kW / h) = 178.125 $ / day.
That's why I amI wanted to get computing resources on the ball turned to the free Internet community. A year ago, thanks to the RSDN community , a trial run was launched.
As I noticed, on private machines the calculation is much faster than on virtual servers of the same configuration. So it seems that thecloud services are fooling us a bit virtualization adds its overhead.
Anticipating the question of why I did not use BOINC, I will answer this way: it’s just inconvenient for me to go there with my project. People are looking for a cure for cancer, looking for the Higgs boson, and here I am with some obscure task.
According to the theory, the number of options first expands, then begins to narrow due to cutting off the solved branches. The position from the 7th move was considered. The calculation was that by the 8th move, if the number of options does not decrease, then at least the rate of this growth will slow down.
I had to tinker with the base, its size was supposed to be very large and access to the elements is very common. I had significant experience with PostgreSQL, but it did not suit me, because even if the data fits in the same place on the disk, this DBMS still places them at the end of the table due to transactionality. Thus, if one element changes frequently, then the table swells quickly. It is necessary to vacuum it, but on a loaded server this is problematic. Instead, I gave birth to my bike, which used a mix of AVL-tree and directory structure as the base. When a tree exceeds a certain limit, it splits into two in different directories. It turns out such a hash tree. In practice, this turned out to be a bad decision. Firstly, the AVL tree is a bad choice for working with a disk. At the time of separation, the data arrives in a new tree in sorted order - this is the worst option for balancing. Secondly, practice has shown that accumulating such a number of computing resources so that the database becomes a bottleneck is quite problematic, and PostgeSQL would have completely suited me.
As computing nodes, I planned to use “cheap” cloud services. I used both Scalaxy and Amazon. Suddenly I realized that computing was worth the real money.. Scalaxy gave 16 cores to the server, it cost me, it seems, $ 10 / day. At the same time, 16 processes worked somehow very hard. On Amazon, I tried to launch 2 instances of 8 cores, and this also cost a significant amount. I also tried to take in quantity and use 50 micro-instances, which cost me $ 40 per day. According to my feelings, they worked worse than 2 servers with 8 cores. This made me wonder how much the calculations actually cost. At that time, I needed 10,000 cores. Let's say we got iron for free. Let's say we have 2-processor 8-core Xeon, with hyper trading. Total we need 10000 / (2 * 8 * 2) = 312.5 servers. Let's say such a server eats 200W. Total per day we need to pay 312.5 * 200W * 24h = 1.5MW * h * 0.11875 $ / (kW / h) = 178.125 $ / day.
That's why I am
As I noticed, on private machines the calculation is much faster than on virtual servers of the same configuration. So it seems that the
Anticipating the question of why I did not use BOINC, I will answer this way: it’s just inconvenient for me to go there with my project. People are looking for a cure for cancer, looking for the Higgs boson, and here I am with some obscure task.
According to the theory, the number of options first expands, then begins to narrow due to cutting off the solved branches. The position from the 7th move was considered. The calculation was that by the 8th move, if the number of options does not decrease, then at least the rate of this growth will slow down.
The calculation lasted about a month. Unfortunately, a miracle did not happen. The number of options has grown steadily. The calculation had to be stopped. Even on states with 17-35 moves, the decision tree is also steadily expanding.
The reason for this lies in the breadth first search. We started a breadth-first search to find unobvious solutions.

To do this, you have to bypass all the options, even the most idiotic.
Ant colony algorithm
My ideas ran out, and I abandoned the project for almost a year, until my colleague suggested that I use the ant colony algorithm .
The idea is that we randomly choose the path that we will explore from a certain state. The probability of a move depends on the ratio of the number of victories / losses of all descendants of this branch.
It works pretty well. The only problem is that we are not interested in how likely the opponent’s loss is if there is at least one position in which he can win.

Ask a neighbor about victory
Honestly, I do not know what this heuristic is called. It is based on the fact that for many cases the opponent’s retaliatory moves cannot significantly affect the win.

We make a “promising” move to zero. Soon we find that it leads to defeat in 17 moves.

We make the next “promising” move toe from the same state. We find that the crosses win again, and in the same move.
For different moves with zero, we have the same return move with a cross. You can simply increase the weight of already known winning moves in order to reduce the number of moves to be sorted.
This heuristic, combined with the ant colony algorithm, gives a huge increase in productivity. It is so effective that in a day of work it finds the solved positions, starting from the fourth move.
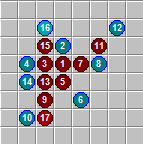
Debut base and man
If we want to prove that the crosses start and win, it’s enough for us to make one perfect move with a cross, for every possible move to zero. This is equivalent to halving the overall search depth. In some cases, as in the picture above, ideal moves are obvious to the person.
I plan to add the ability to selectively force the calculation of certain branches in the hope that this will give me a significant increase in performance.
And let's rewrite it to assembler
In no project did I try to make so many optimizations and did not feel so much disappointment.
The facts are unforgiving: the constant has no meaning compared to the overall complexity of the algorithm. Let me remind you that each position on average gives 80 new positions. To move one step deeper, we must increase the speed of the program 80 times !!!
So, a sample list of what I have undertaken:
- Incremental search for effective empty cells. When deepening the search, only empty cells are added around the last move. To do this, I had to enter the state of the field in depth and quite a lot of code to support them.
- Where possible, I made arrays of the type std :: vector <> static to avoid the constant allocation of memory for such arrays.
- To avoid constant allocation of memory for tree nodes, reference counters for shared_ptr nodes and fields inside structures that implement these nodes, I implemented a node pool. In order not to break anything, I had to use this pool of nodes very carefully. No performance gains were found at all, and with great joy I was able to mow this code.
By incredible tricks and complicating the code, I managed to increase the speed by 2.5 times. Feel the difference between acceleration 2.5 times and 80 times?
Often they propose to do the calculation on the video card using CUDA. The problem is that GPUs are built on the SIMD architecture, and they really dislike branching, and branching is, in fact, the way a tree search works. The only thing for which they can be applied is the search for threatening lines from one or several positions simultaneously. The practical effect of this is so far dubious.
Although algorithmic optimization has not yet exhausted itself. And it is quite possible that for a task of such complexity one modern smartphone is enough.
So the algorithms rule!
Acknowledgments
I am grateful to Dr. Louis Victor Allis for his ability to solve unsolvable problems.
I am immensely grateful to all those people from the RSDN community who helped and continue to help me calculate this task using my resources.
I am grateful to Rustam for the idea with the ant colony algorithm.
I am grateful to Vana for the stylistic and spelling correction of the article. I hope I haven’t missed anything from your edits.
References and literature
Computer Chess Programming Theory
Knuth DE, Moore RW An Analysis of Alpha-Beta Priming
Allis, LV (1994). Searching for solutions in games and artificial intelligence, Ph.D. Thesis, University of Limburg, Maastricht.
Allis, LV, Herik, HJ van den, and Huntjens, MPH Go-Moku and Threat-Space Search
GORKOFF About AI in
Latobco intellectual games Some ideas for writing artificial intelligence for chess
Project source code Project
site