Comparison of libraries for working with Memcached on Node.JS

I want to share the work done to study the performance of various libraries for working with memcached in Node.JS. For the study, 4 candidates were selected.
Brief descriptions are taken directly from the sources and are given in the original. Here is the resulting list with versions and links.
- mc v1.0.6 - The Memcache Client for Node.js ( mc )
- node-memcache v0.3.0 - A pure-JavaScript memcached library for node. ( node-memcache )
- node-memcached v0.2.6 - Fully featured Memcached client for Node.js ( node-memcached )
- memjs v0.8.0 - MemJS is a pure Node.js client library for using memcache. ( memjs )
There are other libraries, but these four were selected. The reason is simple: there was more information and mentions on the network about them than on the rest.
They were chosen about a year ago, and hands reached the article only now. I would be glad if you point out a couple more worthy rivals. Be sure to post tests on them.
From the backstory
I began to study Node.JS, experiment with it and actually write on it relatively recently, about a year ago. The task was set quite interesting and in fact there were no requirements for the platform. It can be said, I personally chose Node.JS then, as an alternative “far and wide” to the PHP I learned, and I have no regrets about it. In other words, I am only glad for such a choice. Now the second project has already been launched and Node.JS is justifying itself. Frankly, I got a lot of pleasure from a deeper study of the JavaScript language. It immediately became clear to me that this was not at all the language that I had seemed to know for quite some time. And how amazed I was by trying to write unit tests using nodeunit, as everything is elegant and concise, unlike the same PHP.
Slightly deviated from the topic. Of course, these are undeniable advantages, which are already described here on the Habré and on other resources. But this is not PHP, on which we have written a lot of internal libraries, and there are a lot of strangers for all occasions. After all, the experience of writing projects of varying complexity in PHP for more than 10 years. Again, I had to do everything from scratch. As once, when switching first from C ++ to pearl, and then from pearl to PHP. Then I also took a brand new, unfamiliar tool and tried to somehow customize it for myself.
It was necessary to learn how to work with many systems, whether it be working with mongoDb or RabbitMQ, or even with the same Mysql. Almost nothing standard, as in PHP was not here. It was necessary to choose the most suitable one from the mass of libraries and block the functionality I needed with my objects. So, step by step, I explored various tools and libraries and at some point I got to the memkesh.
So let's get started
For the purity of the experiment, I will envelop all of these libraries with a single interface, so that in the test script I just indicate the option I need, and the actions themselves will be the same for all subjects.
The interface will consist of 4 methods:
Init (cb) - initialization of the
Set object (key, val, cb) - setting the value of
Get (key, cb) - receiving the value of
End () - close all active connections
Example implementation of the interface for the mc library will look something like this:
impl.mc = function(){};
impl.mc.prototype = {
Init : function(cb) {
var self = this;
var Mc = require('mc');
self.mmc = new Mc.Client('<ip>:11211', Mc.Adapter.binary);
self.mmc.connect(function() {
cb(self);
});
},
Set : function(key, val, cb) { this.mmc.set(key, val, {flags: 0, exptime : 100}, cb); },
Get : function(key, cb) { this.mmc.get(key, cb); },
End : function() { this.mmc.disconnect(); }
};
We write the same implementations for the remaining 3 libraries and put them in the impl.js. I’ll make a reservation right away so as not to pile up code that is not so small, I did not add error handling to the examples. These are just tests and, of course, this is taken into account in real library wrappers.
How will the testing take place.
The first step is to write 1000 random integer values with the names of keys of the form:
__key_ [libName] _ [0 ... 999],
where libName is the name of one of the libraries under study (mc, memcached ...)
We measure time and count the number of records per second . The name of the library is added to the key so that they do not overlap in the test between different implementations.
Second step- after we recorded, we begin to read. We read 100k times with a random key from the range, again, we note the time and count the number of readings per second.
And here is the code itself, which will sequentially run all the options. I tried to minimize the code to the maximum, well, how it happened.
var cacheImpl = require('./impl');
// функция создания ключа// с учетом реализации className для того, чтобы избежать одинаковых ключей для различных библиотекfunction_key(className, i) { return'__key_' + className + '_' + i; }
// выполнить тесты для реализации className (memjs, memcached, memcache, mc)functiontestPerform(className, cb) {
var impl = new cacheImpl[className]();
impl.Init(function(pc) {
var keysCount = 1000, // кол-во ключей
getNum = 100000, // кол-во чтений
all = 0,
d1, d2;
// запуск установки значений кешаvar startSet = function (cb) {
all = keysCount;
for (var i = 0;i < keysCount;i++) {
(function(num){
setImmediate(function(){
// ~~(Math.random() * 100000) - это я так привожу к целочисленному
pc.Set(_key(className, num), ~~(Math.random() * 100000), function(err) {
if (--all === 0) return cb();
});
});
})(i);
};
};
// запуск чтений из кеша по случайному ключу из диапазонаvar startGet = function (cb) {
all = getNum;
for (var j = 0;j < getNum;j++) {
setImmediate(function(){
pc.Get(_key(className, ~~(Math.random() * 1000)), function(err, res) {
if (--all === 0) {
cb();
pc.End();
}
});
});
};
}
// запуск полследовательно всего вместеvar start = function (cb) {
d1 = Date.now();
startSet(function() {
d2 = Date.now();
console.log(className + ' Set qps: ' + Math.round(keysCount / (d2 - d1) * 1000));
d1 = Date.now();
startGet(function() {
d2 = Date.now();
console.log(className + ' Get qps: ' + Math.round(getNum / (d2 - d1) * 1000));
cb();
});
});
}
start(cb);
});
}
// вот так вот некрасиво запускаем последовательно все реализации
testPerform('memcache', function(){
testPerform('memcached', function(){
testPerform('memjs', function(){
testPerform('mc', function(){});
});
});
});
What I was primarily interested in was not the absolute values of the number of records and reads per second (although this too), namely which library would be faster in general.
Tests were carried out on a working cluster, write / read was performed on memcached on a neighboring server. Servers are loaded with real traffic, so you can not really pay attention to absolute values. The relative values are important.
Total, after running the script, we get the following result:
memcache Set qps: 8929 memcache Get qps: 19444 memcached Set qps: 6098 memcached Get qps: 8924 memjs Set qps: 8850 memjs Get qps: 12857 mc Set qps: 14286 mc get qps: 23207
Immediately we see an obvious leader, and by writing and reading, I will sign in a percentage of the leader.
Zapsi rating:
1.mc 100.00% 2. memcache 62.50% 3. memjs 61.95% 4. memcached 42.69%
Reading Rating:
1.mc 100.00% 2. memcache 83.79% 3. memjs 55.40% 4. memcached 38.45%
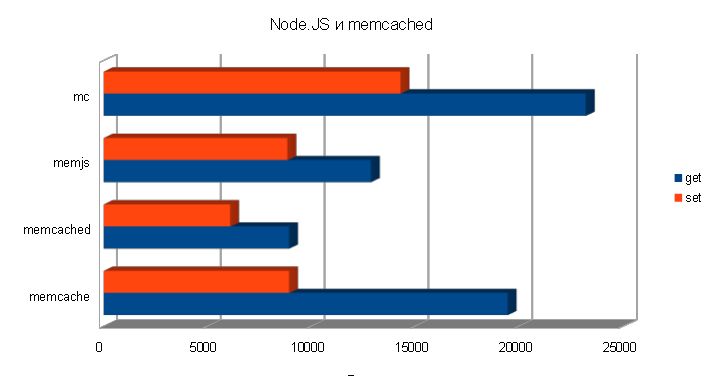
These are the interesting results. Of course, libraries are distinguished by their functionality, the convenience of working with them, the ability to work with a cluster of memcaches, a connection pool, etc. I intentionally miss these points and take the most common situation when there is one memcache server. If it works faster with one, then with several servers the relative result should not differ much.
The tests are quite synthetic, since only integers are written, reading is done only on existing keys (cases where there is no key are not taken into account), etc. But, nevertheless, all libraries are on an equal footing. Nevertheless, I hope that the results will be useful.
I would be glad if someone helped to decide on the choice of library, or at least made me think that not all libraries are equally good in terms of performance.
I would like to listen to constructive criticism of the work I have done: consistency, presentation style and all that can help make the article better. We will study together.
Here such my "debut" on a habr How successful it is for you to decide.